
このクイックスタートでは、Entity Reconciliation API について説明します。 このクイックスタートでは、 Google Cloud コンソールを使用して Google Cloud プロジェクトと承認を設定し、スキーマ マッピング ファイルを作成して、 Enterprise Knowledge Graph にエンティティ調整ジョブの実行をリクエストします。
このタスクを Google Cloud コンソールで直接行う際の順を追ったガイダンスについては、「ガイドを表示」をクリックしてください。
データソースを特定する
Entity Reconciliation API は、入力として BigQuery テーブルのみをサポートしています。 データが BigQuery に保存されていない場合は、コネクタが利用可能になる前にデータを BigQuery に転送することをおすすめします。また、構成したサービス アカウントまたは OAuth クライアントに、使用する予定のテーブルに対する読み取りアクセス権と、宛先データセットに対する書き込み権限があることを確認してください。
スキーマ マッピング ファイルを作成する
データソースごとに、スキーマ マッピング ファイルを作成して、Enterprise Knowledge Graph にデータの取り込み方法を通知する必要があります。
Enterprise Knowledge Graph は、
YARRRML という人間が読めるシンプルな形式の言語を使用して、
ソース スキーマとターゲットの共通グラフ オントロジー
schema.org の間のマッピングを定義します。
Enterprise Knowledge Graph は、1 対 1 のシンプルなマッピングのみをサポートしています。
schema.org のタイプに対応する次のエンティティ タイプがサポートされています。
スキーマ マッピング ファイルの例
組織
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
人物
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
ソース文字列 example_project:example_dataset.example_table~bigquery、
~bigquery の場合、データソースが BigQuery から取得されることを示す固定文字列です。
述語リスト(po)では、ekg:recon.source_name と ekg:recon.source_key はシステムで使用される予約済みの述語名であり、マッピング ファイルで常に言及する必要があります。通常、述語 ekg:recon.source_name はソースの定数値(この例では (Patients))を受け取ります。述語 ekg:recon.source_key はソース テーブルの一意のキー(この例では $(source_key))を受け取ります。これは、ソース列 ID からの変数値を表します。
マッピング ファイルで定義するテーブルまたはソースが複数ある場合、または 1 つの API 呼び出し内に異なるマッピング ファイルがある場合は、サブジェクト値が異なるソース間で一意であることを確認する必要があります。接頭辞とソース列キーを使用して、一意にすることができます。たとえば、同じスキーマを持つ 2 つの人物テーブルがある場合は、サブジェクト(s)値に異なる形式(ekg:person1_$(record_id) と ekg:person2_$(record_id))を割り当てることができます。
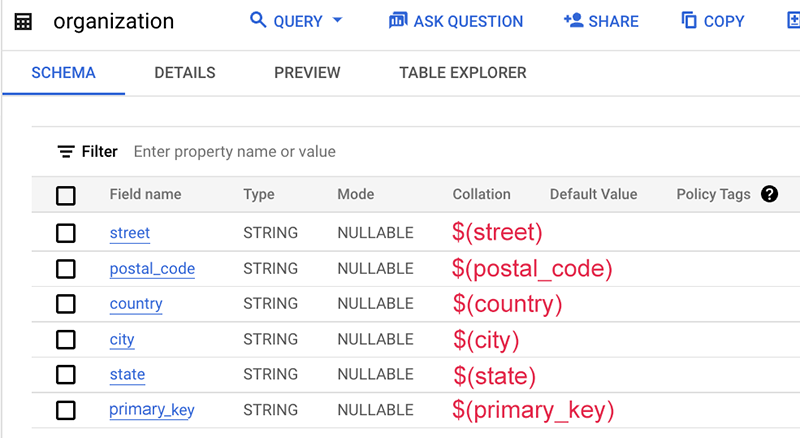
マッピング ファイルの例を次に示します。
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
この例では、テーブル スキーマ自体にこのデータソースの名前(通常はテーブル名またはデータベース名)が含まれていません。そのため、ドル記号 $ を使用せずに静的文字列「org」を使用します。
エンティティ調整ジョブを作成する
Google Cloud コンソールを使用して、調整ジョブを作成します。
Enterprise Knowledge Graph ダッシュボード を開きます。
[Schema Mapping] をクリックして、データソースごとにテンプレートからマッピング ファイルを作成し、Cloud Storage に保存します。
![UI の [Schema Mapping] オプションから](https://docs.cloud.google.com/static/enterprise-knowledge-graph/docs/images/local-business-ontology.png?hl=ja)
[Job]、[Run A Job] をクリックして、ジョブを開始する前にジョブ パラメータを構成します。
エンティティ タイプ
値 モデル名 説明 Organizationgoogle_brasilOrganizationレベルでエンティティを調整します。たとえば、企業としての会社名です。これは、特定の支店、スポット、物理的なプレゼンスに焦点を当てたLocalBusinessとは異なります。たとえば、多くの企業のキャンパスの 1 つです。LocalBusinessgoogle_cyprus特定の支店、関心のある場所、物理的な存在に基づいてエンティティを調整します。モデル入力として地理座標を受け取ることもできます。 Persongoogle_atlantisschema.orgで事前定義された属性のセットに基づいて人物エンティティを調整します。データソース
BigQuery テーブルのみがサポートされています。
目的地
出力パスは、Enterprise Knowledge Graph に書き込み権限がある BigQuery データセットにする必要があります。
実行されるジョブごとに、Enterprise Knowledge Graph はタイムスタンプ付きの新しい BigQuery テーブルを作成して結果を保存します。
Entity Reconciliation API を使用する場合、ジョブ レスポンスには完全な出力テーブル名とロケーションが含まれます。
必要に応じて、[Advanced Options] を構成します。
ジョブを開始するには、[Done] をクリックします。
ジョブのステータスをモニタリングする
ジョブのステータスは、 Google Cloud コンソールと API の両方からモニタリングできます。データセット内のレコード数によっては、ジョブが完了するまでに最大 24 時間かかることがあります。個々のジョブをクリックすると、ジョブの詳細な構成が表示されます。
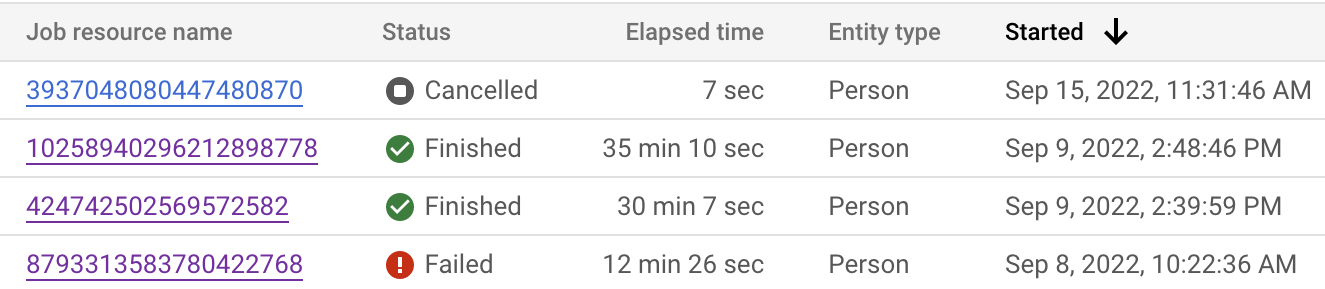
ジョブのステータスを調べて、現在のステップを確認することもできます。
| ジョブの表示状態 | コードの状態 | 説明 |
|---|---|---|
| 実行中 | JOB_STATE_RUNNING |
ジョブは進行中です。 |
| ナレッジの抽出 | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph が BigQuery からデータを抽出し、特徴を作成しています。 |
| 調整の前処理中 | JOB_STATE_RECON_PREPROCESSING |
ジョブは調整の前処理ステップにあります。 |
| クラスタリング | JOB_STATE_CLUSTERING |
ジョブはクラスタリング ステップにあります。 |
| クラスタのエクスポート中 | JOB_STATE_EXPORTING_CLUSTERS |
ジョブは BigQuery の宛先データセットに出力を書き込んでいます。 |
各ジョブの実行時間は、データの複雑さ、データセットのサイズ、同時に実行されている他の並列ジョブの数など、多くの要因によって異なります。参考までに、ジョブの実行時間とデータセット サイズの概算を次に示します。実際のジョブの完了時間は異なります。
| レコードの合計数 | 実行時間 |
|---|---|
| 10 万 | 2 時間以下 |
| 1 億 | 16 時間以下 |
| 3 億 | 24 時間以下 |
調整ジョブをキャンセルする
コンソール(ジョブの詳細ページ)と API の両方から、実行中のジョブを cancel できます。Enterprise Knowledge Graph は、ベスト エフォート方式で可能な限り早くジョブを停止します。 Google Cloud cancel コマンドが成功するとは限りません。
詳細オプション
| 構成 | 説明 |
|---|---|
| 以前の結果の BigQuery テーブル | 以前の結果テーブルを指定すると、クラスタ ID がジョブ間で安定します。その後、クラスタ ID を永続 ID として使用できます。 |
| アフィニティ クラスタリング | ほとんどの場合におすすめのオプションです。階層型凝集型クラスタリングの並列バージョンであり、非常にスケーラブルです。クラスタリング ラウンド(イテレーション)の回数は、[1, 5] の範囲で指定できます。数値が大きいほど、アルゴリズムがクラスタをオーバーマージする傾向があります。
|
| 連結成分クラスタリング | デフォルトのオプション。これは代替のレガシー オプションです。アフィニティ クラスタリングがデータセットでうまく機能しない場合にのみ、このオプションを試してください。重みしきい値は、[0.6, 1] の範囲の数値にできます。 |
| ジオコーディング分離 | このオプションを使用すると、異なる地理的リージョンのエンティティが一緒にクラスタ化されることはありません。 |