
En esta guía de inicio rápido, se presenta la API de Entity Reconciliation. En esta guía de inicio rápido, usarás la Google Cloud consola de para configurar tu Google Cloud proyecto y autorización, crear archivos de asignación de esquemas y, luego, hacer una solicitud a Enterprise Knowledge Graph para ejecutar un trabajo de conciliación de entidades.
Para seguir la guía paso a paso sobre esta tarea directamente en la Google Cloud consola, haz clic en Guiarme:
Identifica tu fuente de datos
La API de Entity Reconciliation solo admite tablas de BigQuery como entrada. Si tus datos no están almacenados en BigQuery, te recomendamos que los transfieras a BigQuery antes de que haya más conectores disponibles. Además, asegúrate de que la cuenta de servicio o el cliente de OAuth que configuraste tengan acceso de lectura a las tablas que planeas usar y permiso de escritura para el conjunto de datos de destino.
Crea un archivo de asignación de esquemas
Para cada una de tus fuentes de datos, debes crear un archivo de asignación de esquemas para informar a Enterprise Knowledge Graph cómo transferir los datos.
Enterprise Knowledge Graph usa un lenguaje de formato simple legible por humanos llamado
YARRRML para definir las asignaciones entre
el esquema de origen y las ontologías de gráficos comunes de destino,
schema.org.
Enterprise Knowledge Graph solo admite asignaciones simples de 1:1.
Se admiten los siguientes tipos de entidades que corresponden a los tipos de schema.org:
Ejemplos de archivos de asignación de esquemas
Organización
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
Persona
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
Para la cadena de origen example_project:example_dataset.example_table~bigquery,
~bigquery es la cadena fija que indica que la fuente de datos proviene de BigQuery.
En la lista de predicados (po), ekg:recon.source_name y ekg:recon.source_key son nombres de predicados reservados que usa el sistema y siempre deben mencionarse en el archivo de asignación. Por lo general, el predicado ekg:recon.source_name toma un valor constante para la fuente (en este ejemplo, (Patients)). El predicado ekg:recon.source_key toma la clave única de la tabla de origen (en este ejemplo, $(source_key)), que representa el valor de la variable del ID de la columna de origen).
Si tienes varias tablas o fuentes para definir en los archivos de asignación o diferentes archivos de asignación dentro de una llamada a la API, debes asegurarte de que el valor del asunto sea único en las diferentes fuentes. Puedes usar el prefijo más la clave de la columna de origen para que sea único. Por ejemplo, si tienes dos tablas de personas con
el mismo esquema, puedes asignar diferentes formatos al valor del asunto (s):
ekg:person1_$(record_id) y ekg:person2_$(record_id).
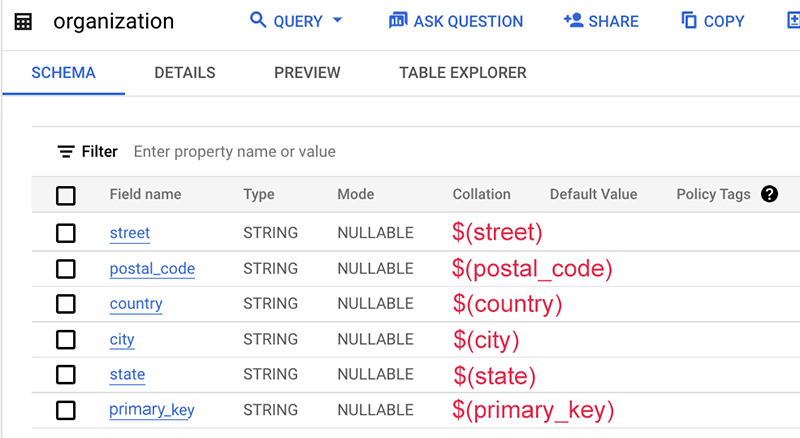
Este es un ejemplo del archivo de asignación:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
En este ejemplo, el esquema de la tabla en sí no contiene el nombre de esta fuente de datos, que suele ser el nombre de la tabla o el nombre de la base de datos. Por lo tanto, usamos una cadena estática "org" sin el signo de dólar $.
Crea un trabajo de conciliación de entidades
Usa la Google Cloud consola de para crear un trabajo de conciliación.
Abre el panel de Enterprise Knowledge Graph.
Haz clic en Asignación de esquemas para crear archivos de asignación a partir de nuestra plantilla para cada una de tus fuentes de datos y, luego, guarda el archivo de asignación en Cloud Storage.

Haz clic en Trabajo y Ejecutar un trabajo para configurar los parámetros del trabajo antes de iniciarlo.
Tipo de entidad
Valor Nombre del modelo Descripción Organizationgoogle_brasilConcilia entidades a nivel de Organization. Por ejemplo, el nombre de una corporación como empresa. Esto es diferente deLocalBusiness, que se enfoca en una sucursal, un lugar de interés o una presencia física en particular, por ejemplo, uno de los muchos campus de la empresa.LocalBusinessgoogle_cyprusConcilia la entidad en función de una sucursal, un lugar de interés o una presencia física en particular. También podría tomar coordenadas geográficas como entrada del modelo. Persongoogle_atlantisConcilia la entidad de persona en función de un conjunto de atributos predefinidos en schema.org.Fuentes de datos
Solo se admiten tablas de BigQuery.
Destino
La ruta de salida debe ser un conjunto de datos de BigQuery, en el que Enterprise Knowledge Graph tenga permiso para escribir.
Para cada trabajo ejecutado, Enterprise Knowledge Graph crea una nueva tabla de BigQuery con marca de tiempo para almacenar los resultados.
Si usas la API de Entity Reconciliation, la respuesta del trabajo contiene el nombre y la ubicación completos de la tabla de salida.
Configura Opciones avanzadas si es necesario.
Para iniciar el trabajo, haz clic en Listo.
Supervisa el estado del trabajo
Puedes supervisar el estado del trabajo desde la Google Cloud consola de y la API. El trabajo puede tardar hasta 24 horas en completarse, según la cantidad de registros de tus conjuntos de datos. Haz clic en cada trabajo individual para ver la configuración detallada del trabajo.
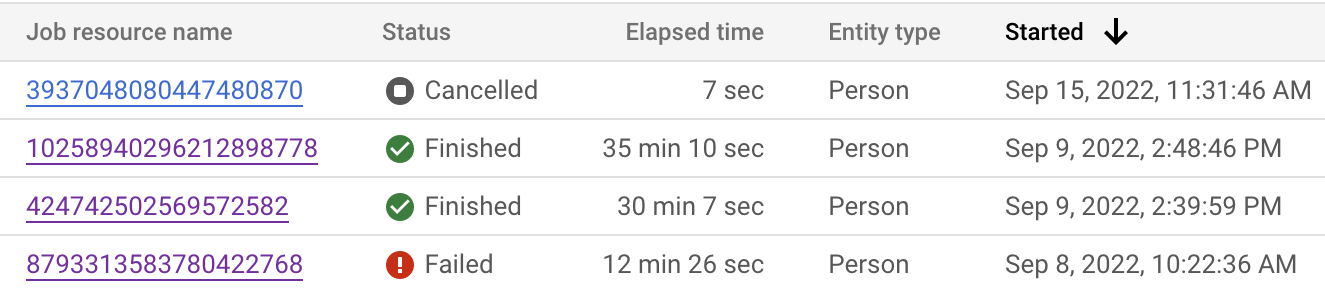
También puedes inspeccionar el estado del trabajo para ver dónde está el paso actual.
| Estado de visualización del trabajo | Estado del código | Descripción |
|---|---|---|
| En ejecución | JOB_STATE_RUNNING |
El trabajo está en ejecución. |
| Extracción de conocimiento | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph extrae datos de BigQuery y crea atributos. |
| Procesamiento previo de conciliación | JOB_STATE_RECON_PREPROCESSING |
El trabajo está en el paso de procesamiento previo de conciliación. |
| Agrupamiento en clústeres | JOB_STATE_CLUSTERING |
El trabajo está en el paso de agrupamiento en clústeres. |
| Exportando clústeres | JOB_STATE_EXPORTING_CLUSTERS |
El trabajo escribe el resultado en el conjunto de datos de destino de BigQuery. |
El tiempo de ejecución de cada trabajo varía según muchos factores, como la complejidad de los datos, el tamaño del conjunto de datos y la cantidad de otros trabajos paralelos que se ejecutan al mismo tiempo. Esta es una estimación aproximada del tiempo de ejecución del trabajo en comparación con el tamaño del conjunto de datos para tu referencia. El tiempo real de finalización del trabajo será diferente.
| Cantidad total de registros | Tiempo de ejecución |
|---|---|
| 100,000 | ~2 horas |
| 100 millones | ~16 horas |
| 300 millones | ~24 horas |
Cancela un trabajo de conciliación
Puedes cancel un trabajo en ejecución desde la Google Cloud consola (en la página de detalles del trabajo) y la API; Enterprise Knowledge Graph detiene el trabajo lo antes posible en función del mejor esfuerzo. No se garantiza el éxito del comando cancel.
Opciones avanzadas
| Configuración | Descripción |
|---|---|
| Tabla de BigQuery del resultado anterior | Especificar una tabla de resultados anterior mantiene estable el ID del clúster en diferentes trabajos. Luego, puedes usar el ID del clúster como tu ID permanente. |
| Agrupamiento en clústeres de afinidad | Opción recomendada para la mayoría de los casos. Es una versión paralela del agrupamiento en clústeres jerárquico aglomerado y se adapta muy bien. La cantidad de rondas de agrupamiento en clústeres (iteraciones) se puede especificar en el rango [1, 5]. Cuanto mayor sea el número, más tenderá el algoritmo a combinar en exceso el clúster.
|
| Agrupamiento en clústeres de componentes conectados | Opción predeterminada. Esta es una opción alternativa y heredada; prueba esta opción solo si el agrupamiento en clústeres de afinidad no funciona bien en tu conjunto de datos. El umbral de peso puede ser un número en el rango [0.6, 1]. |
| Separación de geocodificación | Esta opción garantiza que las entidades de diferentes regiones geográficas no se agrupen. |