
In dieser Kurzanleitung wird die Entity Reconciliation API vorgestellt. In dieser Kurzanleitung richten Sie mit der Google Cloud Console Ihr Google Cloud Projekt und Ihre Autorisierung ein, erstellen Schemazuordnungsdateien und senden dann eine Anfrage an Enterprise Knowledge Graph, um einen Entitätsabgleichsjob auszuführen.
Eine detaillierte Anleitung dazu finden Sie direkt in der Google Cloud Console. Klicken Sie dazu einfach auf Anleitung:
Datenquelle identifizieren
Die Entity Reconciliation API unterstützt nur BigQuery-Tabellen als Eingabe. Wenn Ihre Daten nicht in BigQuery gespeichert sind, empfehlen wir Ihnen, sie dorthin zu übertragen, bevor weitere Connectors verfügbar werden. Achten Sie außerdem darauf, dass das konfigurierte Dienstkonto oder der OAuth-Client Lesezugriff auf die Tabellen und Schreibberechtigung für das Ziel-Dataset hat.
Schemazuordnungsdatei erstellen
Für jede Ihrer Datenquellen müssen Sie eine Schemazuordnungsdatei erstellen, damit Enterprise Knowledge Graph weiß, wie die Daten aufgenommen werden sollen.
Enterprise Knowledge Graph verwendet eine für Menschen lesbare einfache Formatierungssprache namens
YARRRML, um die Zuordnungen zwischen dem
Quellschema und den gemeinsamen Ziel-Graphontologien
schema.org zu definieren.
Enterprise Knowledge Graph unterstützt nur einfache 1:1-Zuordnungen.
Die folgenden Entitätstypen, die Typen in schema.org entsprechen, werden unterstützt:
Beispiel für Schemazuordnungsdateien
Organisation
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
Person
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
Für den Quellstring example_project:example_dataset.example_table~bigquery,
~bigquery ist der feste String, der angibt, dass die Datenquelle aus BigQuery stammt.
In der Prädikatliste (po) sind ekg:recon.source_name und ekg:recon.source_key reservierte Prädikatnamen, die vom System verwendet werden und immer in der Zuordnungsdatei angegeben werden müssen. Normalerweise hat das Prädikat ekg:recon.source_name einen konstanten Wert für die Quelle (in diesem Beispiel (Patients)). Das Prädikat ekg:recon.source_key verwendet den eindeutigen Schlüssel aus der Quelltabelle (in diesem Beispiel $(source_key)), der den variablen Wert aus der Quellspalten-ID darstellt.
Wenn Sie mehrere Tabellen oder Quellen in den Zuordnungsdateien definieren oder verschiedene Zuordnungsdateien in einem API-Aufruf verwenden möchten, muss der Wert für das Subjekt für alle Quellen eindeutig sein. Sie können ein Präfix und den Quellspaltenschlüssel verwenden, um den Wert eindeutig zu machen. Wenn Sie beispielsweise zwei Personentabellen mit
demselben Schema haben, können Sie dem Wert für das Subjekt (s) verschiedene Formate zuweisen:
ekg:person1_$(record_id) und ekg:person2_$(record_id).
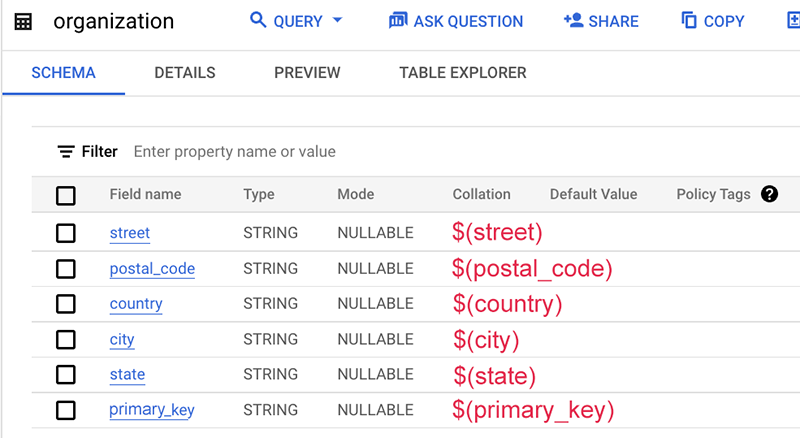
Hier sehen Sie ein Beispiel für die Zuordnungsdatei:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
In diesem Beispiel enthält das Tabellenschema selbst nicht den Namen dieser Datenquelle, der normalerweise der Tabellenname oder der Datenbankname ist. Daher verwenden wir den statischen String „org“ ohne das Dollarzeichen $.
Entitätsabgleichsjob erstellen
Verwenden Sie die Google Cloud Console, um einen Abgleichsjob zu erstellen.
Öffnen Sie das Enterprise Knowledge Graph-Dashboard.
Klicken Sie auf Schemazuordnung , um Zuordnungsdateien aus unserer Vorlage für jede Ihrer Datenquellen zu erstellen, und speichern Sie die Zuordnungsdatei dann in Cloud Storage.

Klicken Sie auf Job und Job ausführen , um die Jobparameter zu konfigurieren, bevor Sie den Job starten.
Entitätstyp
Wert Modellname Beschreibung Organizationgoogle_brasilEntitäten auf der Ebene Organizationabgleichen. Beispiel: der Name einer Aktiengesellschaft als Unternehmen. Dies unterscheidet sich vonLocalBusiness, das sich auf eine bestimmte Niederlassung, einen bestimmten POI oder eine bestimmte physische Präsenz konzentriert, z. B. einen von vielen Unternehmensstandorten.LocalBusinessgoogle_cyprusEntität basierend auf einer bestimmten Niederlassung, einem bestimmten POI oder einer bestimmten physischen Präsenz abgleichen. Es können auch geografische Koordinaten als Modelleingabe verwendet werden. Persongoogle_atlantisDie Entität „Person“ anhand einer Reihe vordefinierter Attribute in schema.orgabgleichen.Datenquellen
Es werden nur BigQuery-Tabellen unterstützt.
Ziel
Der Ausgabepfad muss ein BigQuery-Dataset sein, in das Enterprise Knowledge Graph schreiben darf.
Für jeden ausgeführten Job erstellt Enterprise Knowledge Graph eine neue BigQuery-Tabelle mit Zeitstempel, um die Ergebnisse zu speichern.
Wenn Sie die Entity Reconciliation API verwenden, enthält die Jobantwort den vollständigen Namen und Speicherort der Ausgabetabelle.
Konfigurieren Sie bei Bedarf die erweiterten Optionen.
Klicken Sie auf Fertig, um den Job zu starten.
Jobstatus überwachen
Sie können den Jobstatus sowohl in der Google Cloud Console als auch über die API überwachen. Je nach Anzahl der Datensätze in Ihren Datasets kann es bis zu 24 Stunden dauern, bis der Job abgeschlossen ist. Klicken Sie auf die einzelnen Jobs, um die detaillierte Konfiguration des Jobs zu sehen.
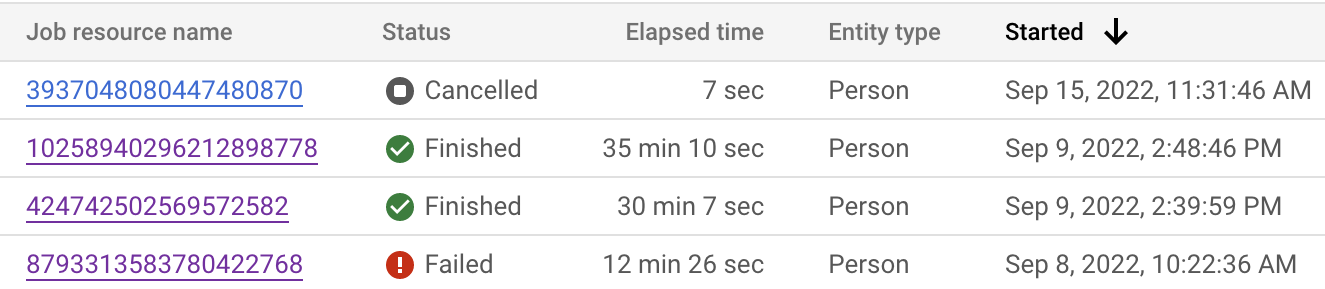
Sie können auch den Jobstatus prüfen, um zu sehen, wo sich der aktuelle Schritt befindet.
| Anzeigestatus des Jobs | Codestatus | Beschreibung |
|---|---|---|
| Wird ausgeführt | JOB_STATE_RUNNING |
Der Job wird bearbeitet. |
| Wissensextraktion | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph ruft Daten aus BigQuery ab und erstellt Features. |
| Abgleichvorverarbeitung | JOB_STATE_RECON_PREPROCESSING |
Der Job befindet sich im Schritt der Abgleichvorverarbeitung. |
| Clustering | JOB_STATE_CLUSTERING |
Der Job befindet sich im Schritt des Clusterings. |
| Cluster werden exportiert | JOB_STATE_EXPORTING_CLUSTERS |
Der Job schreibt die Ausgabe in das BigQuery-Ziel-Dataset. |
Die Laufzeit der einzelnen Jobs variiert je nach vielen Faktoren, z. B. der Komplexität der Daten, der Größe des Datasets und der Anzahl anderer paralleler Jobs, die gleichzeitig ausgeführt werden. Hier finden Sie eine grobe Schätzung der Jobausführungszeit im Vergleich zur Dataset-Größe. Die tatsächliche Zeit bis zum Abschluss des Jobs kann abweichen.
| Gesamtzahl der Datensätze | Ausführungszeit |
|---|---|
| 100.000 | ~2 Stunden |
| 100 Mio. | ~16 Stunden |
| 300 Mio. | ~24 Stunden |
Abgleichsjob abbrechen
Sie können einen laufenden Job sowohl in der Google Cloud Console (auf der Jobdetailseite) als auch über die API cancel abbrechen. Enterprise Knowledge Graph beendet den Job so schnell wie möglich. Es wird nicht garantiert, dass der Befehl cancel erfolgreich ist.
Erweiterte Optionen
| Konfiguration | Beschreibung |
|---|---|
| Vorherige BigQuery-Tabelle | Wenn Sie eine vorherige Ergebnistabelle angeben, bleibt die Cluster-ID für verschiedene Jobs stabil. Dann können Sie die Cluster-ID als permanente ID verwenden. |
| Affinitäts-Clustering | Für die meisten Fälle empfohlene Option. Es handelt sich um eine parallele Version des hierarchischen agglomerativen Clusterings, die sehr gut skaliert. Die Anzahl der Clustering-Runden (Iterationen) kann im Bereich [1, 5] angegeben werden. Je höher die Zahl, desto mehr neigt der Algorithmus dazu, die Cluster zu stark zusammenzuführen.
|
| Clustering verbundener Komponenten | Standardoption. Dies ist eine alternative und ältere Option. Versuchen Sie diese Option nur, wenn das Affinitäts-Clustering für Ihr Dataset nicht gut funktioniert. Der Gewichtungsschwellenwert kann eine Zahl im Bereich [0.6, 1] sein. |
| Geocoding-Trennung | Mit dieser Option wird sichergestellt, dass Entitäten aus verschiedenen geografischen Regionen nicht zusammen gruppiert werden. |