
このドキュメントでは、Document AI Warehouse から Document AI Workbench のカスタム ドキュメント エクストラクタ(CDE)のデータセットにドキュメントをエクスポートする方法について説明します。
CDE を使用すると、ドキュメント エクストラクタを作成できます。ドキュメントをプロセッサ データセットにインポートし、ラベルを付けてからモデルをトレーニングします。選択したドキュメントを CDE のデータセットにエクスポートすると、Document AI Warehouse でドキュメントを管理または検索してデータセットを構築できます。
Document AI Workbench で CDE を作成する
CDE の作成方法の詳細な手順については、こちらの公式 ガイドをご覧ください。このガイドでは、主な手順について説明します。
プロセッサ リストから CDE を作成する
[My processors] ページに移動し、[Create Custom Processor] をクリックします。
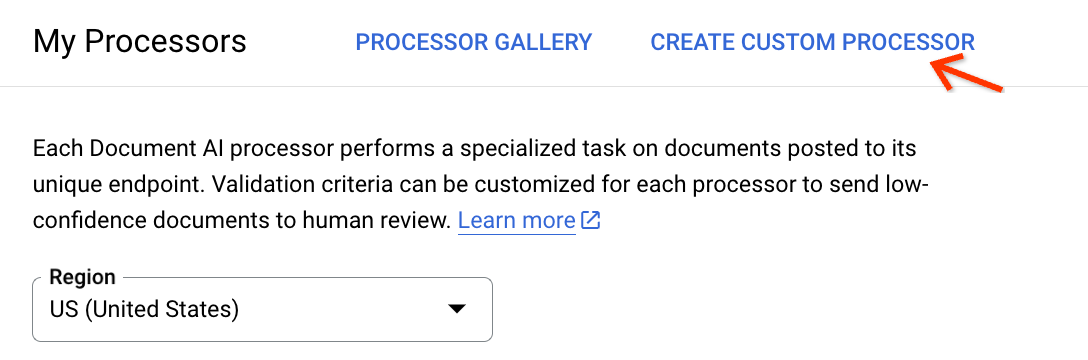
[Custom Document Extractor] カードで [Create Processor] を選択します。
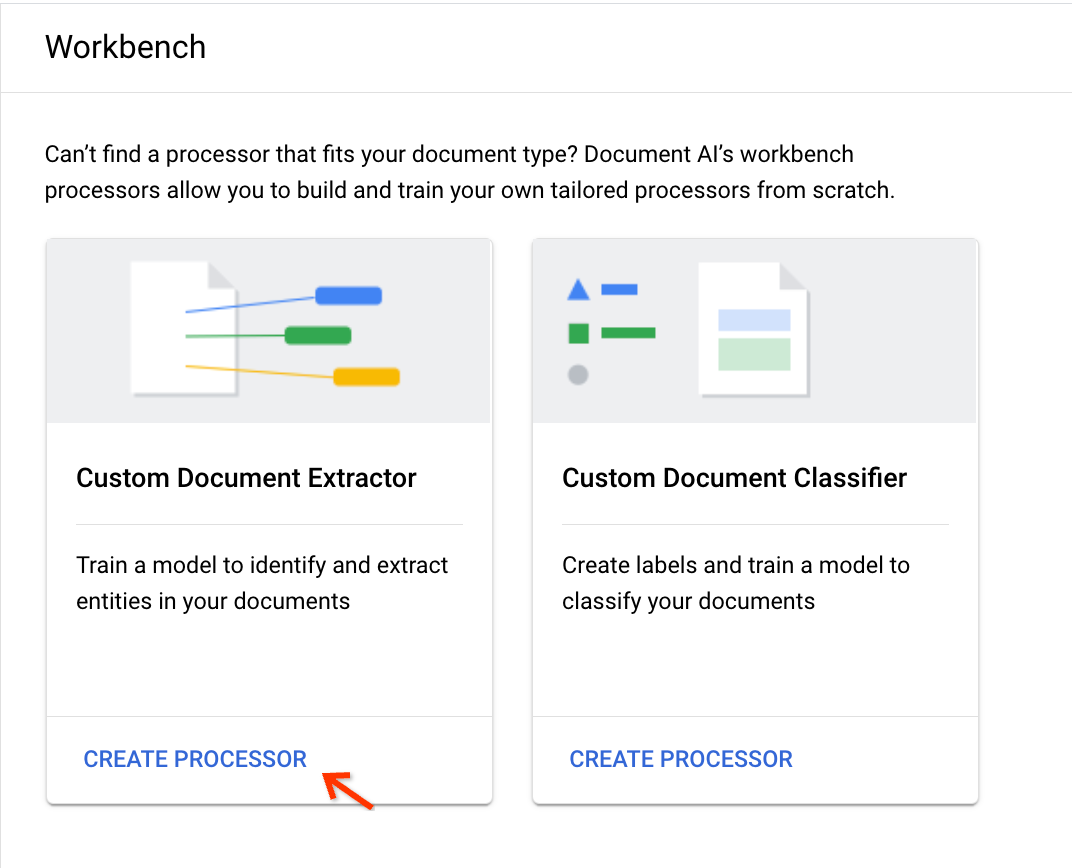
表示名を入力して [Create] をクリックします。
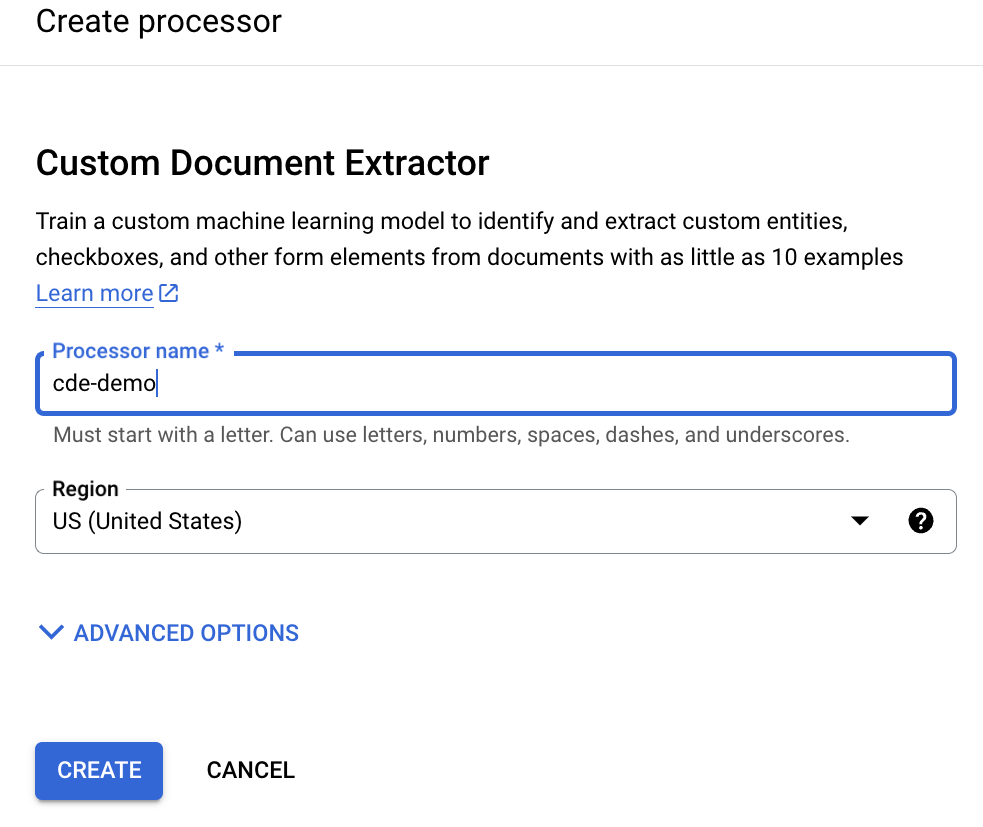
CDE はすぐに作成されます。
CDE のデータセットを設定する
プロセッサの詳細ページで、[Set Dataset Location] をクリックします。
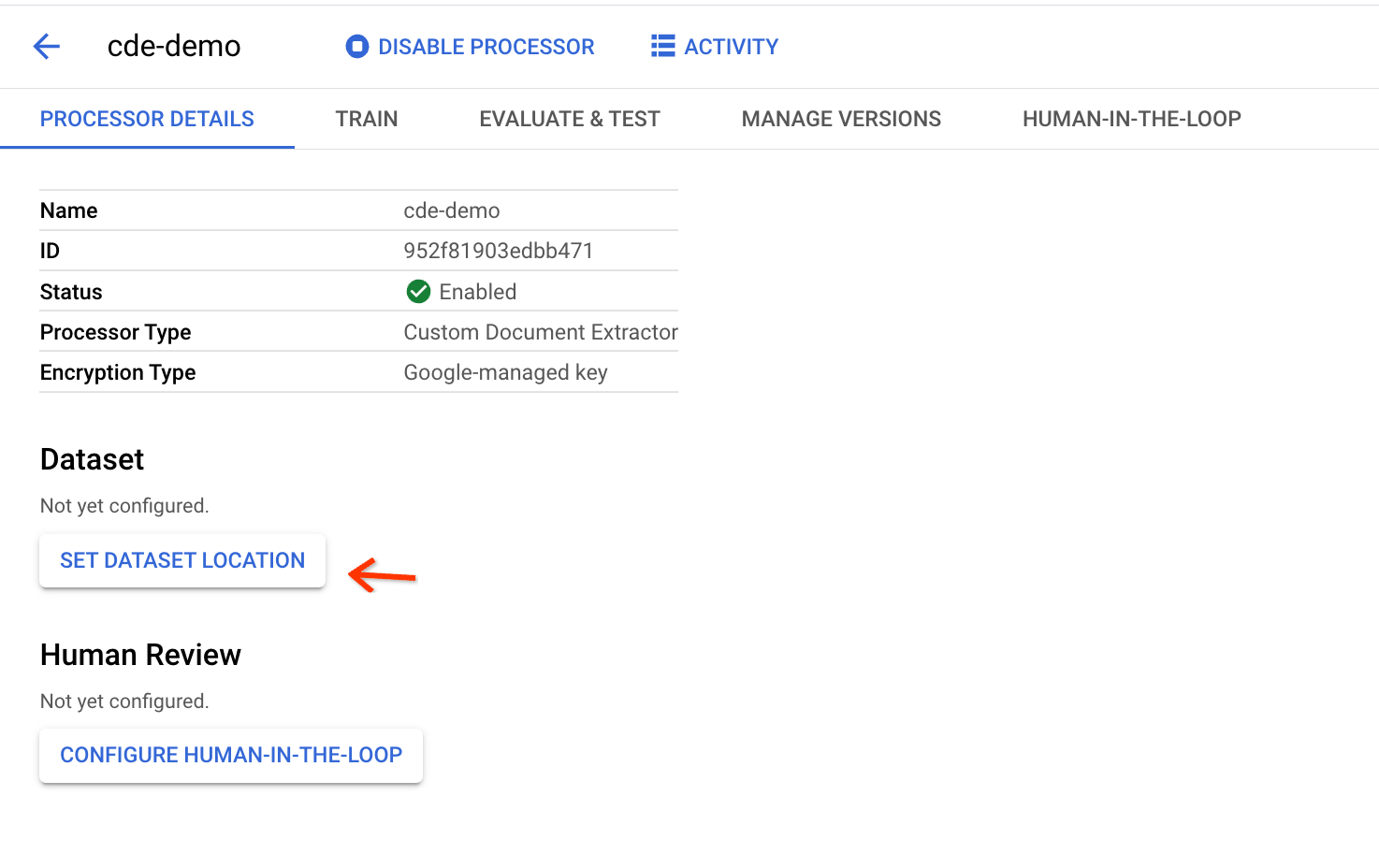
データセットにドキュメントを保存するバケットパスを指定します。
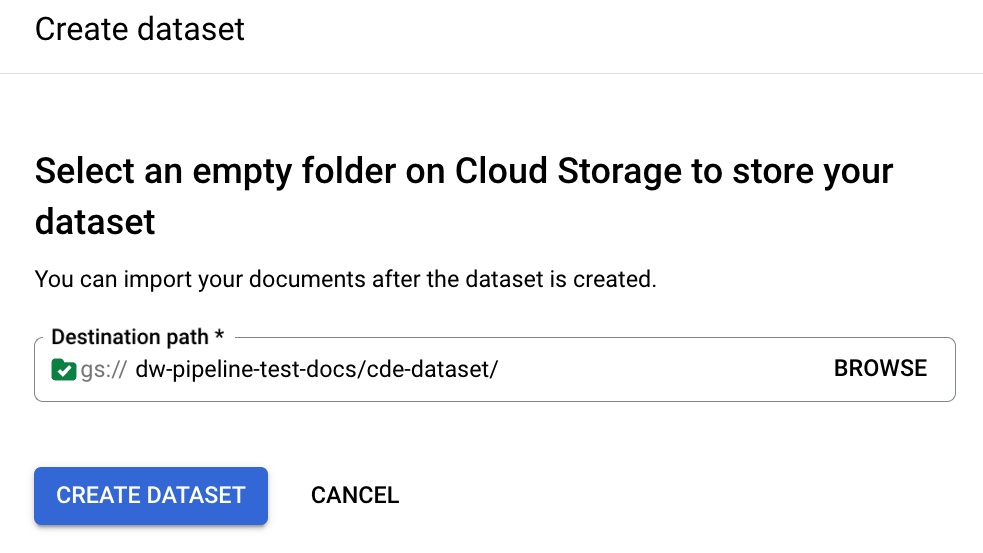
構成が完了するまで数分かかります。完了すると、詳細ページにバケットパスと数が表示されます。
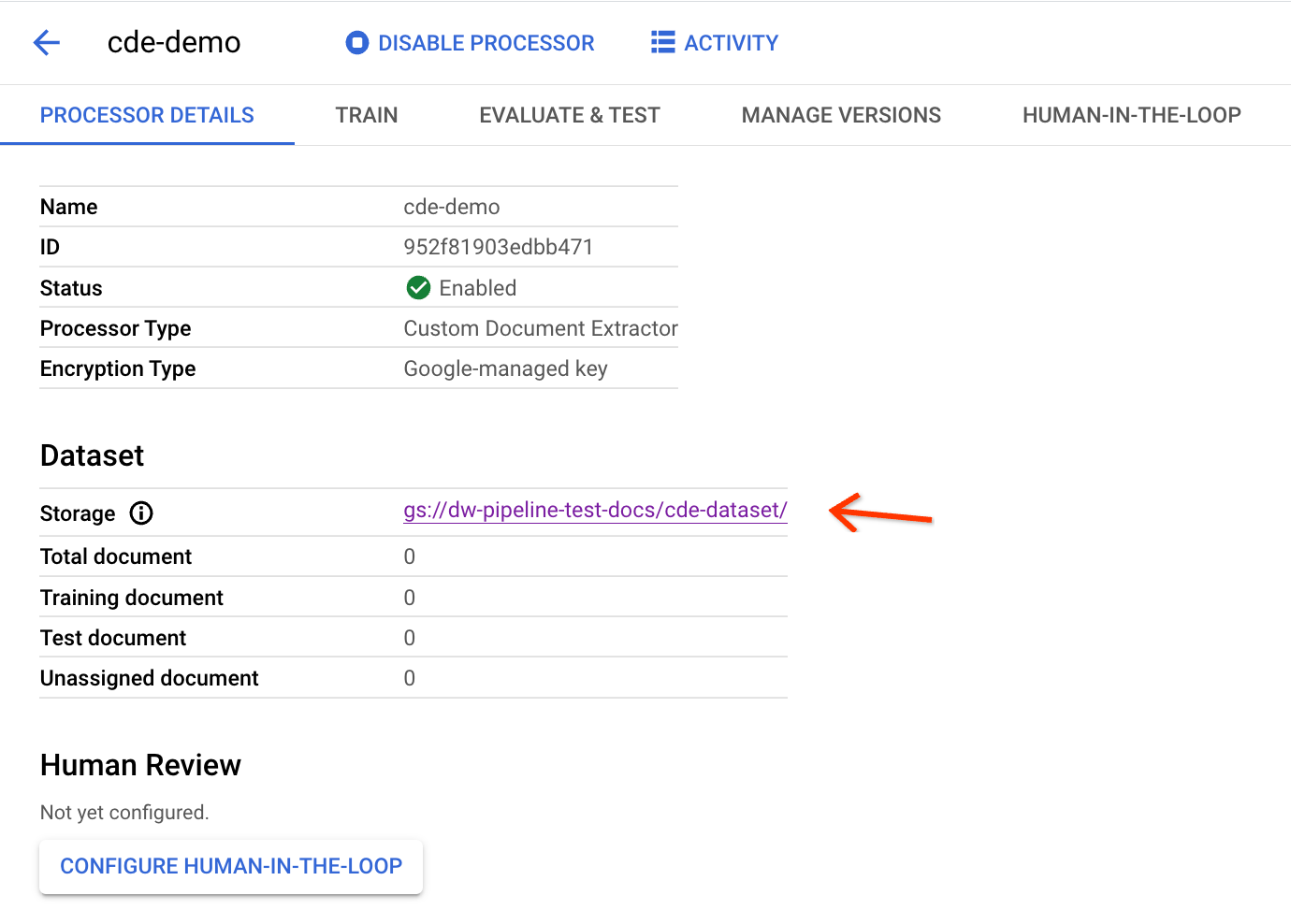
Workbench へのエクスポート パイプラインをトリガーするには、上記のプロセッサ ID が必要です。
Workbench へのエクスポート パイプラインをトリガーする
エクスポートするドキュメントを選択し、アクションバーで [Export to Document AI Workbench] をクリックします。
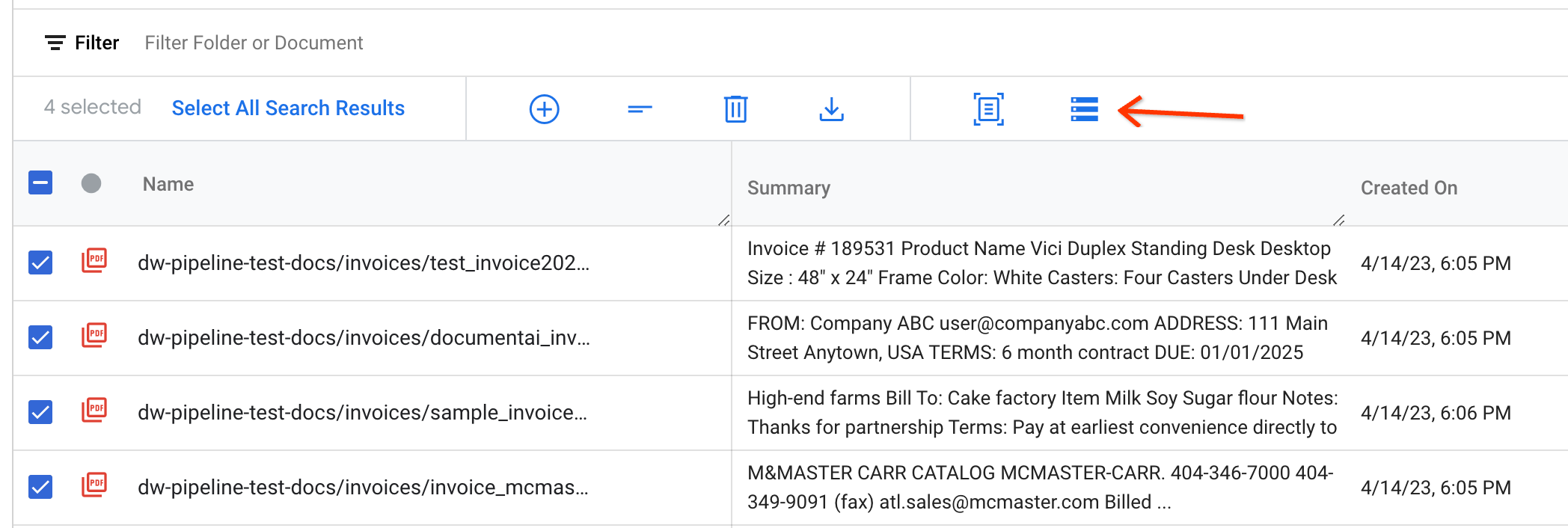
入力パラメータを入力し、CDE からプロセッサ ID をコピーしてダイアログに貼り付けて、パイプラインをトリガーします。
ドキュメントをエクスポートする前に一時的に保存するには、ステージング バケットパスが必要です。データの分割 を使用すると、ドキュメントをトレーニング セットまたはテストセットにランダムに配置できます。分割の比率は、この値に基づいています。
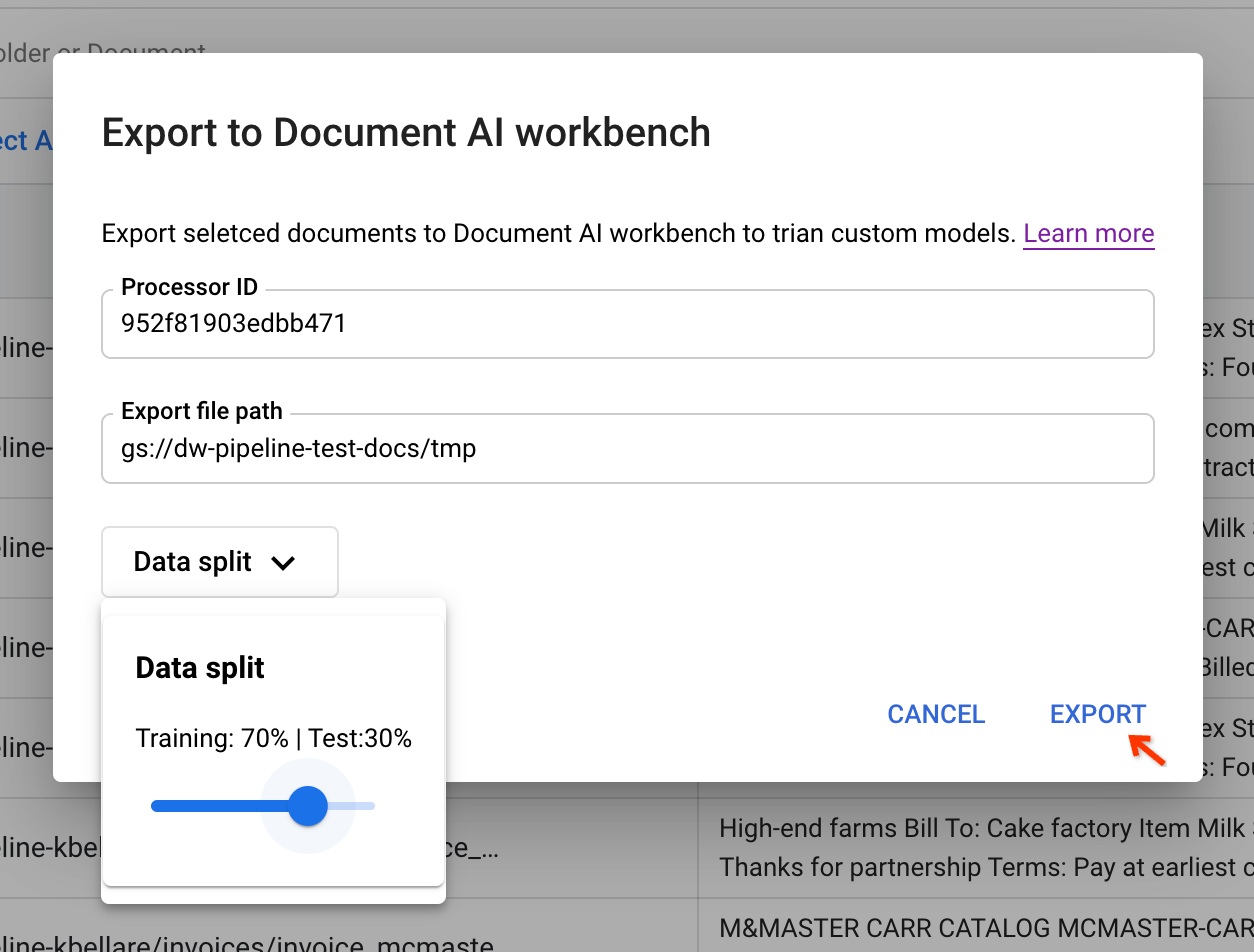
[Export] をクリックすると、パイプライン ジョブがトリガーされます。
ステータスを追跡します。
パイプラインをトリガーすると、ステータス トラッキング ページが表示されます。現在、このページには進行状況のトラッキングはありません。ジョブが完了するまで、ステータス ページに [保留中] と表示されます。
結果を確認します。
ジョブが完了すると、成功したドキュメントと失敗したドキュメントが表示されます。
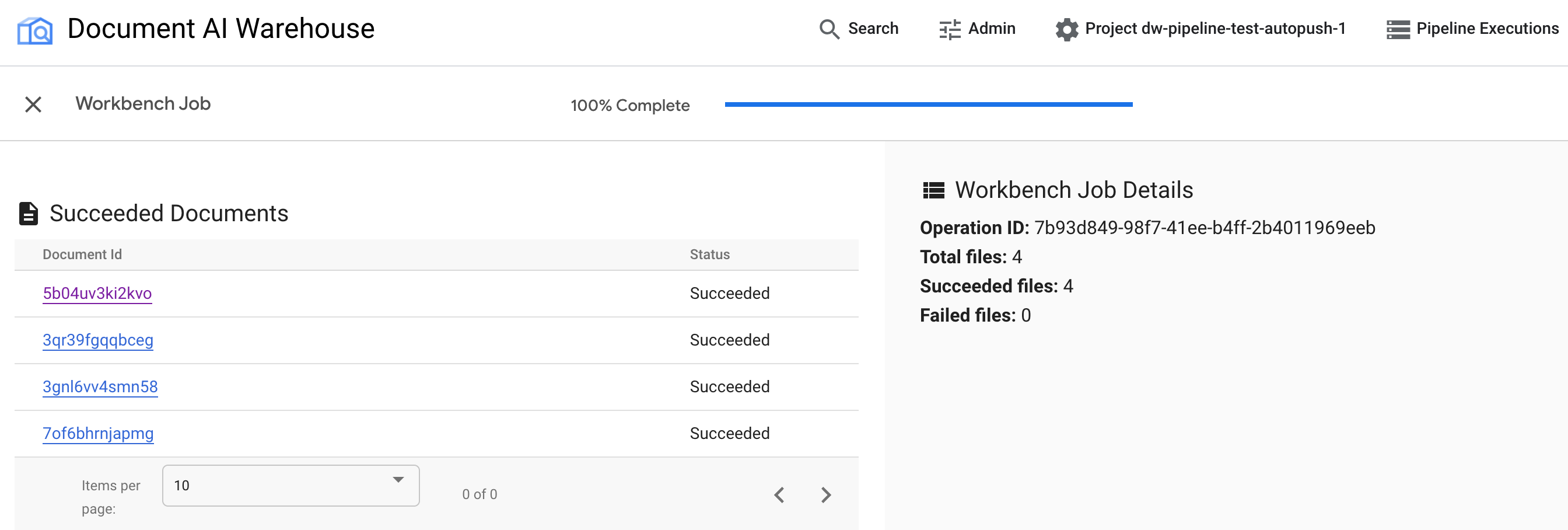
ドキュメントが正しくエクスポートされているかどうかを確認するには、CDE の詳細ページに戻ります。
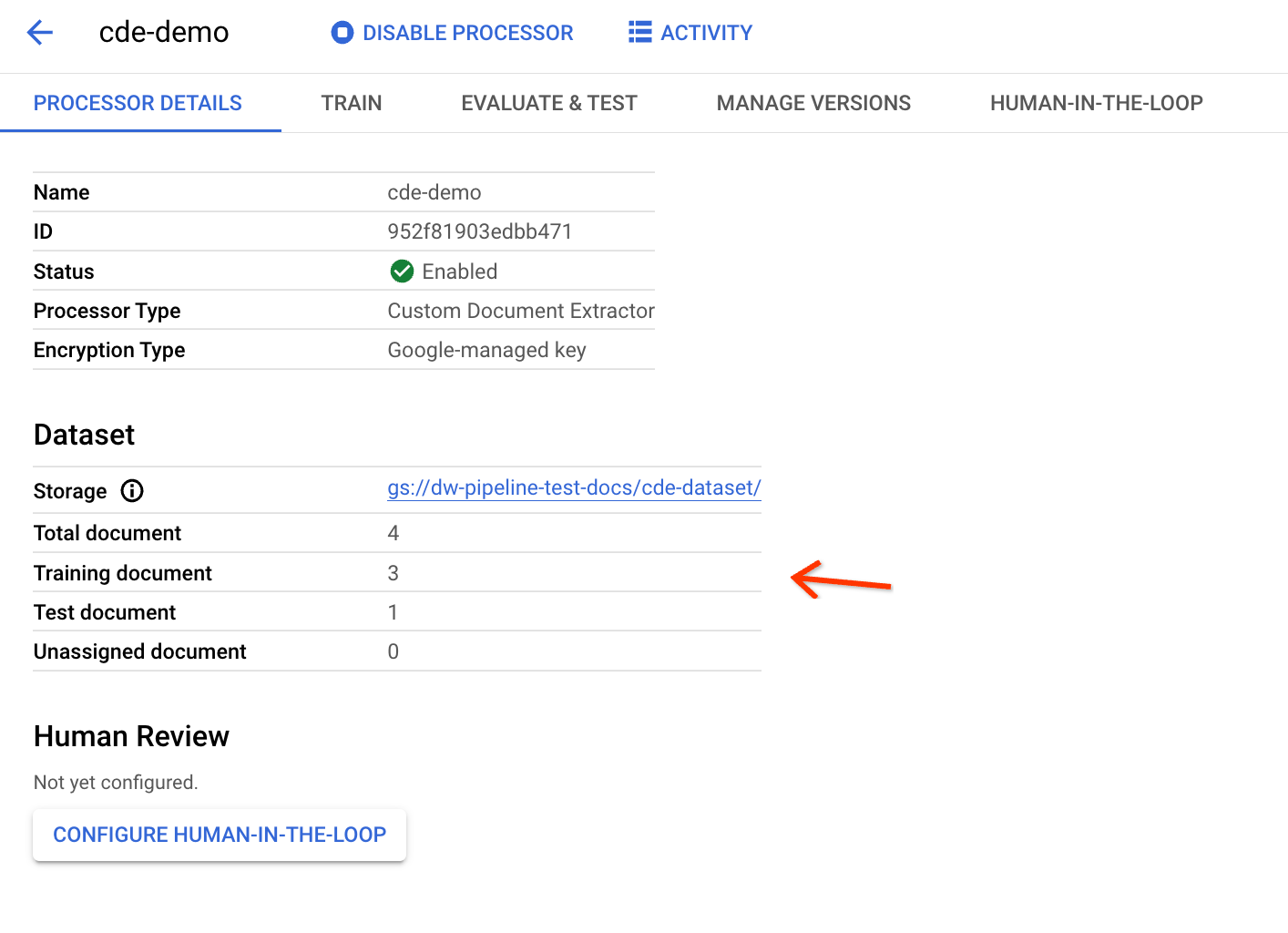
パイプラインの実行前にページを開いている場合は、更新して更新された統計情報を確認します。トレーニング セットとテストセットの分布は、データ分割の比率に基づいています。
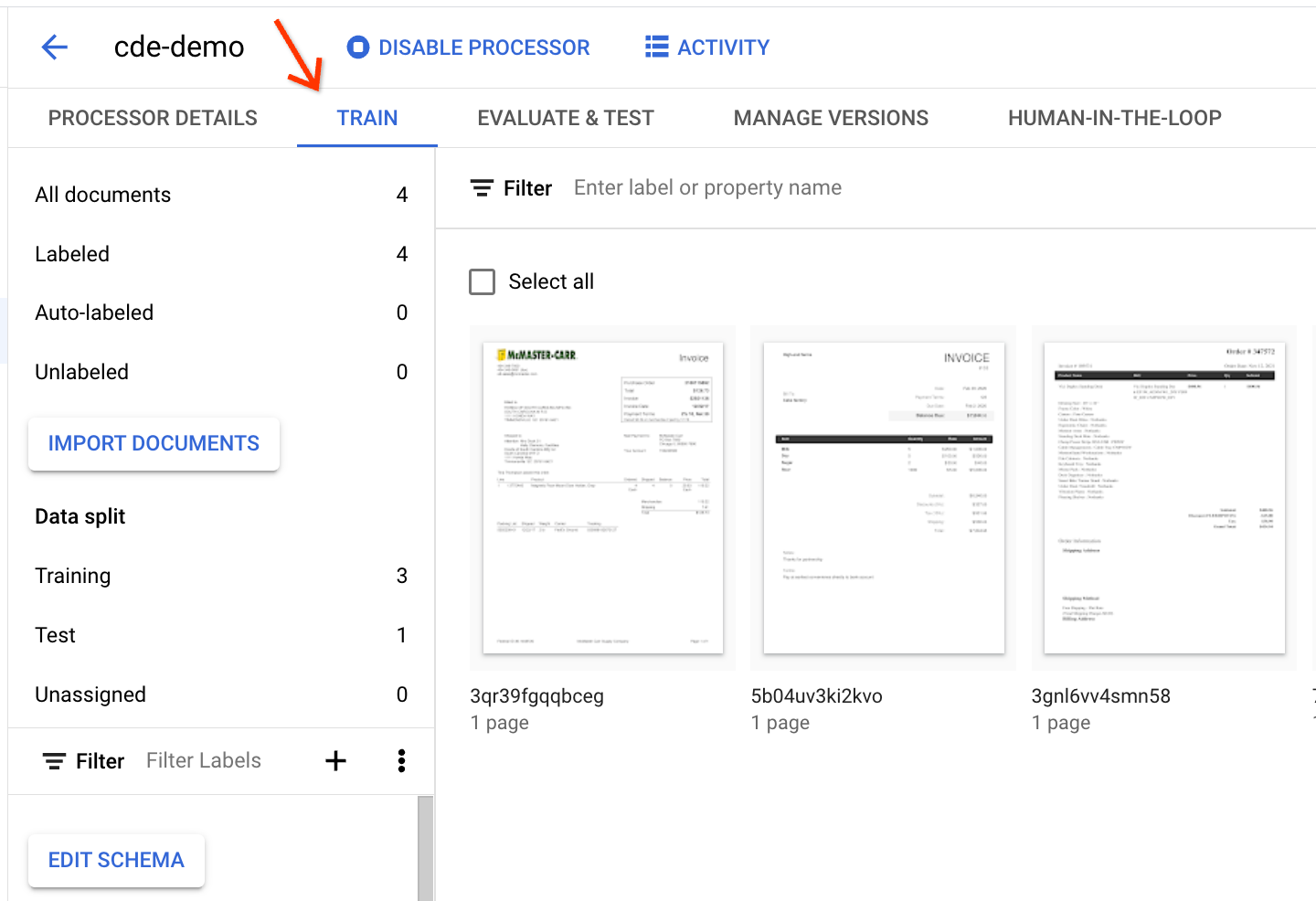
ドキュメントの詳細を表示するには、[Train] タブに移動します。
次のステップ
runPipeline API の詳細を確認する。