
In diesem Dokument wird beschrieben, wie Sie Dokumente aus Document AI Warehouse in den Datensatz eines benutzerdefinierten Dokumentextraktors (Custom Document Extractor, CDE) in Document AI Workbench exportieren.
Mit CDE können Nutzer Dokumentextraktoren erstellen. Sie importieren Dokumente in das Prozessor-Dataset und versehen sie dann mit Labels, bevor sie das Modell trainieren. Wenn Nutzer ausgewählte Dokumente in das Dataset einer CDE exportieren, können sie das Dataset aufbauen, indem sie die Dokumente in Document AI Warehouse verwalten oder durchsuchen.
Benutzerdefinierten Dokumentextraktor in Document AI Workbench erstellen
Eine vollständige Anleitung zum Erstellen eines CDE finden Sie in diesem offiziellen Leitfaden. In diesem Leitfaden werden einige wichtige Schritte beschrieben.
CDE aus der Prozessorliste erstellen
Rufen Sie die Seite Meine Prozessoren auf und klicken Sie auf Benutzerdefinierten Prozessor erstellen:
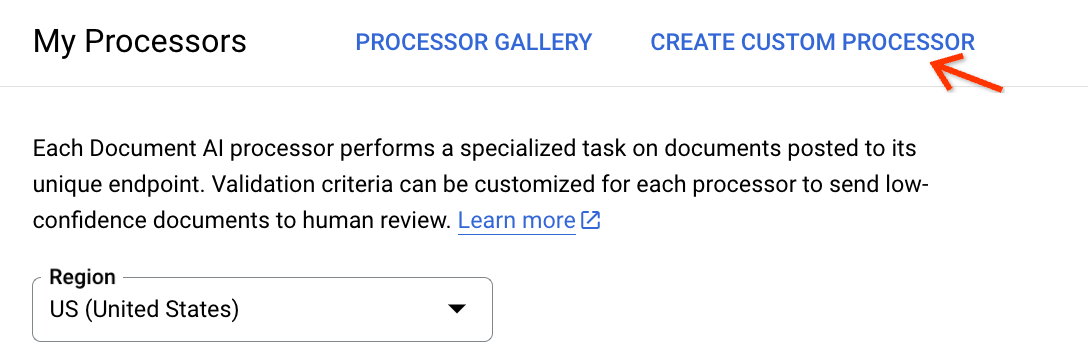
Wählen Sie auf der Karte Benutzerdefinierter Dokumentextraktor die Option Prozessor erstellen aus:
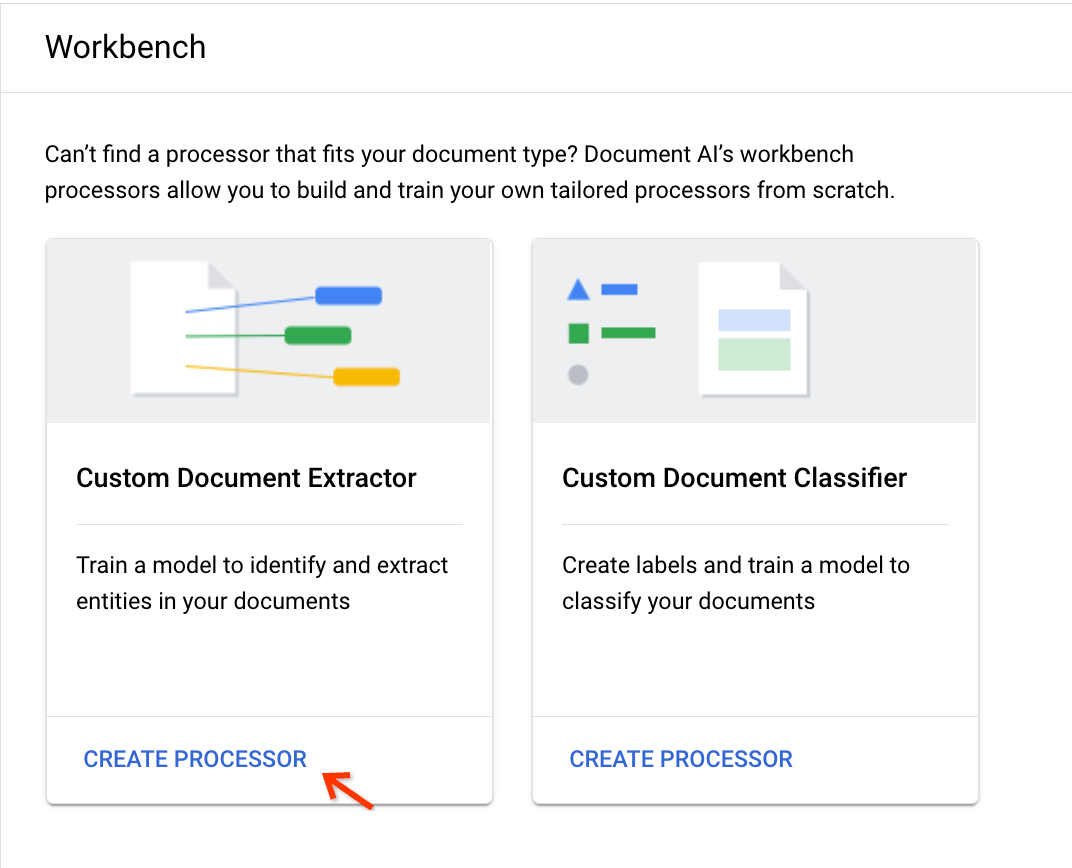
Geben Sie einen Anzeigenamen ein und klicken Sie auf Erstellen:
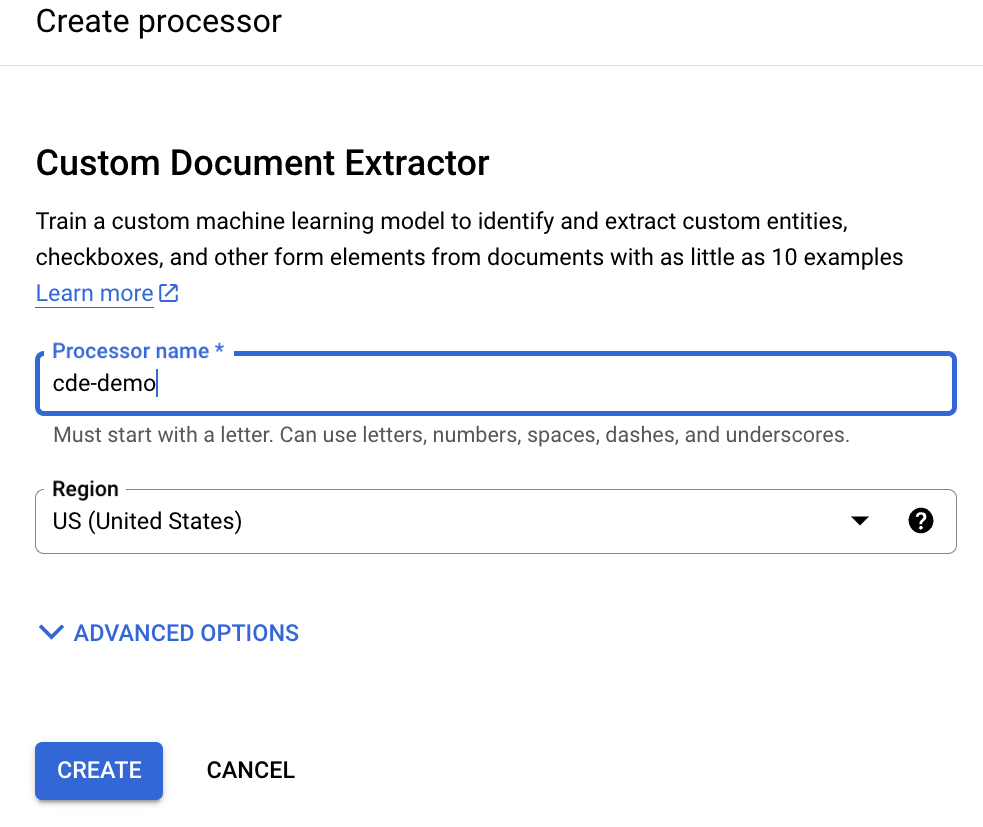
Die CDE sollte schnell erstellt werden.
Dataset der CDE einrichten
Klicken Sie auf der Seite mit den Prozessordetails auf Dataset-Speicherort festlegen:
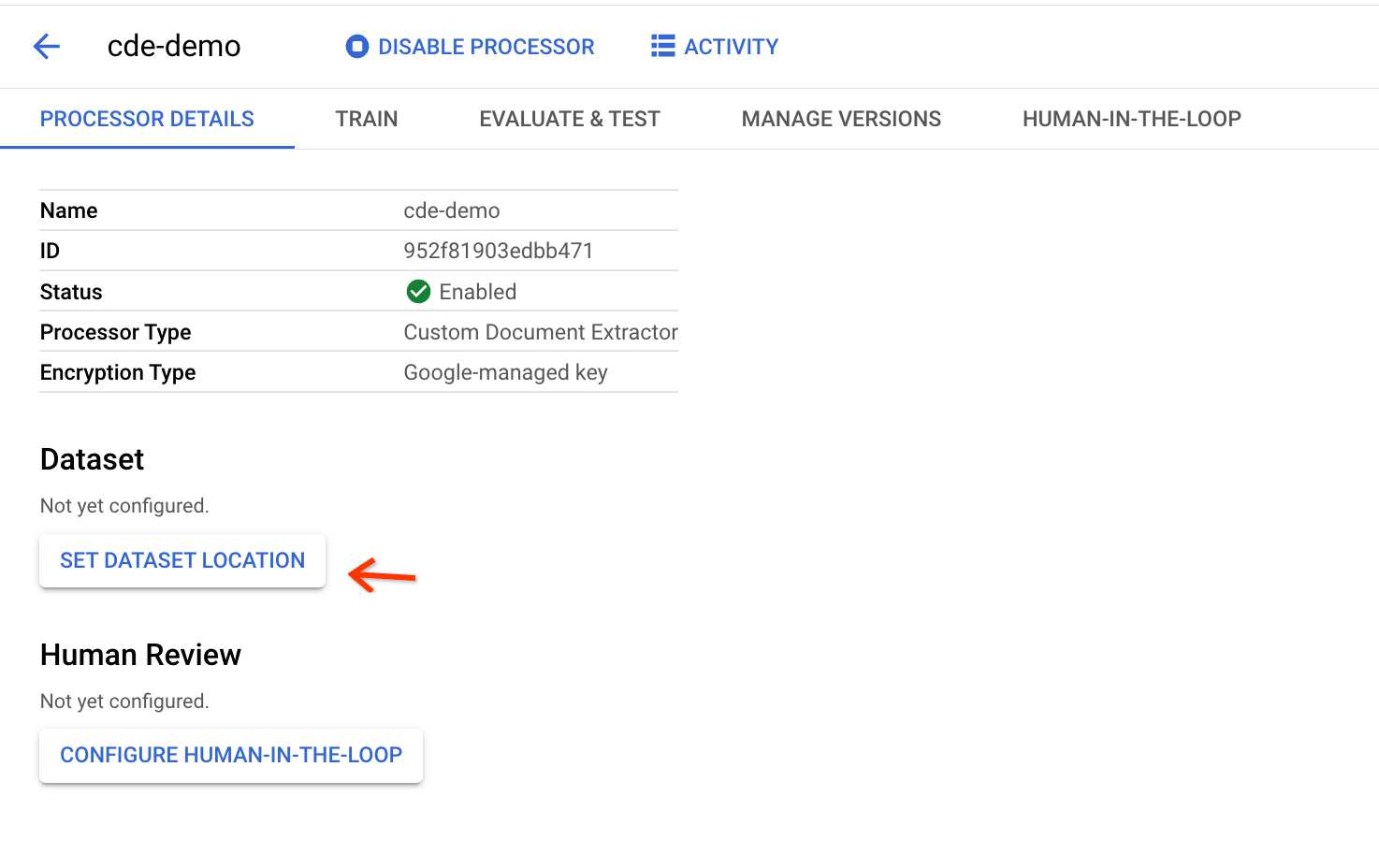
Geben Sie einen Bucket-Pfad an, der zum Speichern der Dokumente im Dataset verwendet werden soll:
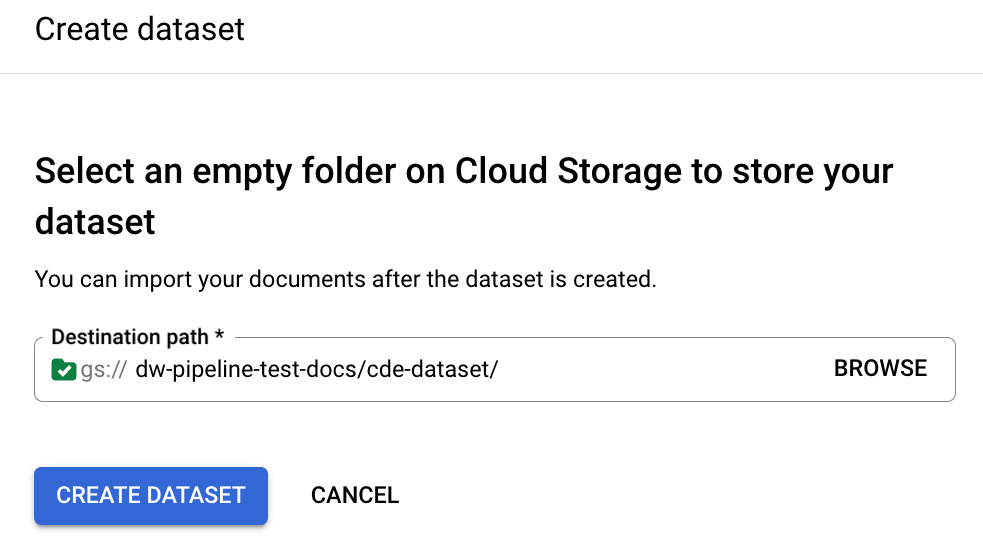
Es dauert einige Minuten, bis die Konfiguration abgeschlossen ist. Anschließend können Sie den Bucket-Pfad und die Anzahl auf der Detailseite sehen:
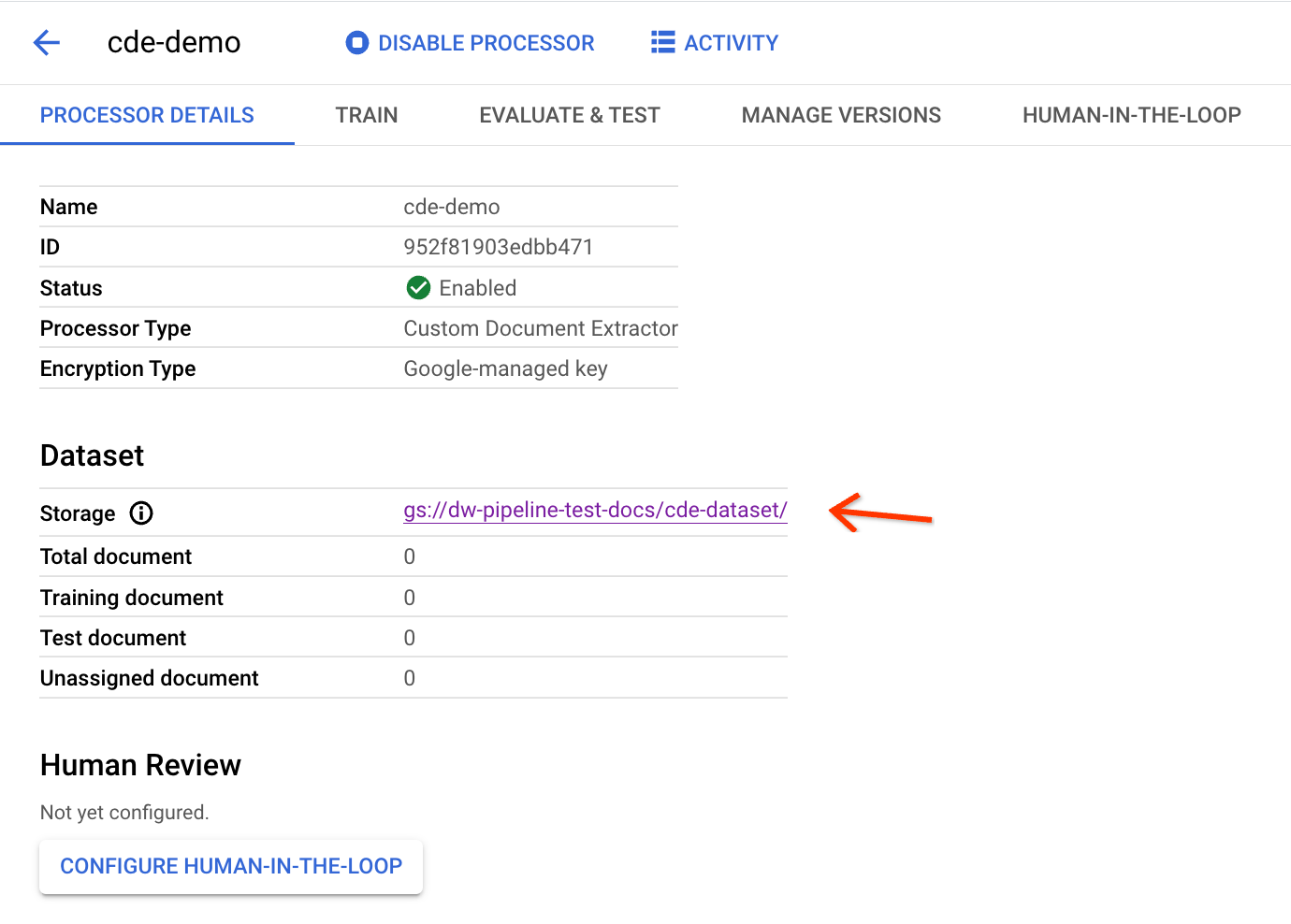
Sie benötigen die oben genannte Prozessor-ID, um die Pipeline „Exportieren nach Workbench“ auszulösen.
Export-Pipeline für Workbench auslösen
Wählen Sie die zu exportierenden Dokumente aus und klicken Sie in der Aktionsleiste auf In Document AI Workbench exportieren:
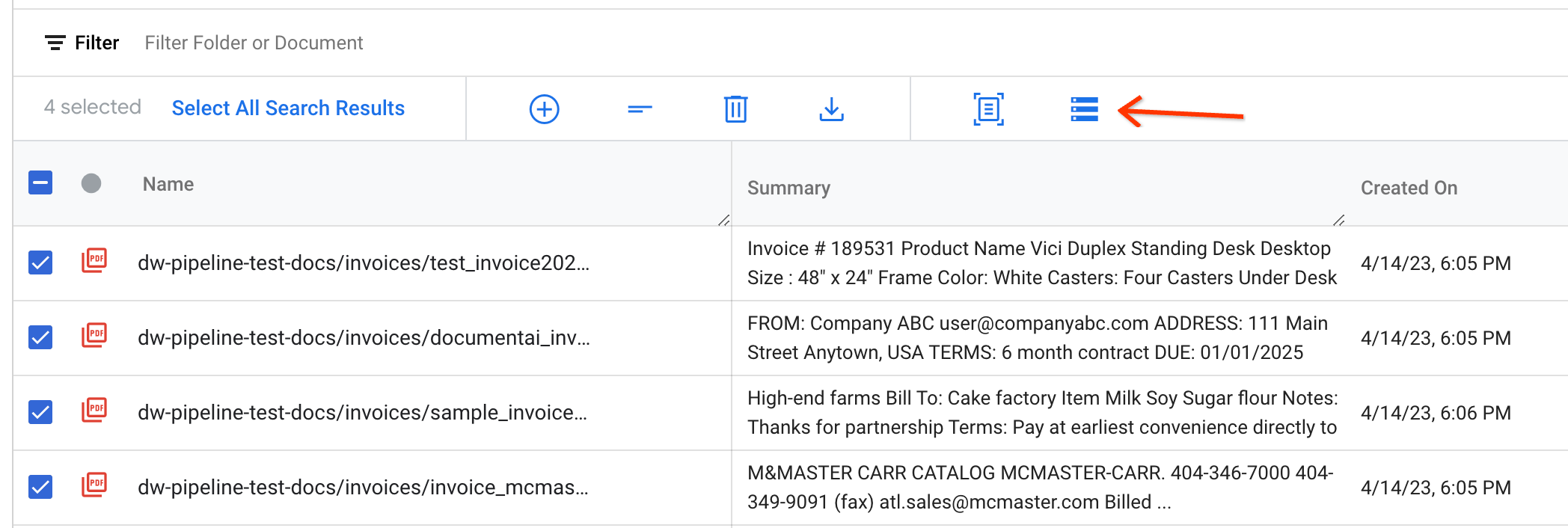
Geben Sie die Eingabeparameter ein und lösen Sie die Pipeline aus, indem Sie die Prozessor-ID aus dem CDE kopieren und in das Dialogfeld einfügen.
Sie benötigen einen Staging-Bucket-Pfad, um die Dokumente vor dem Exportieren vorübergehend zu speichern. Mit Data split (Datenteilung) können Nutzer das Dokument nach dem Zufallsprinzip in einen Trainings- oder Testsatz einfügen. Das Verhältnis der Aufteilungen basiert auf diesem Wert.
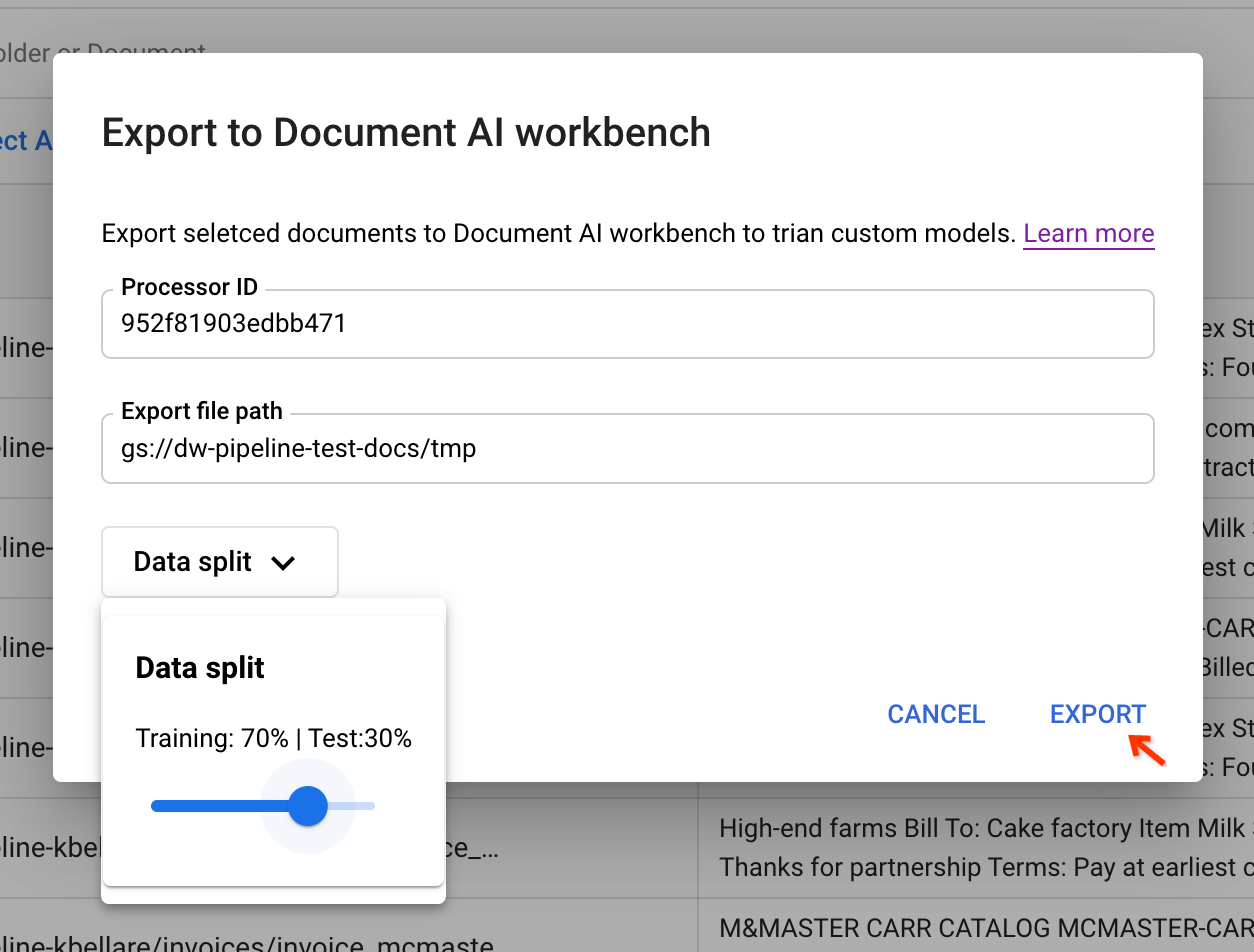
Wenn Sie auf Exportieren klicken, wird der Pipelinejob ausgelöst.
Track-Status
Nachdem Sie die Pipeline ausgelöst haben, wird eine Seite zur Statusverfolgung angezeigt. Derzeit ist kein In-Progress-Tracking für die Seite eingerichtet. Auf der Statusseite wird „Ausstehend“ angezeigt, bis der Job abgeschlossen ist.
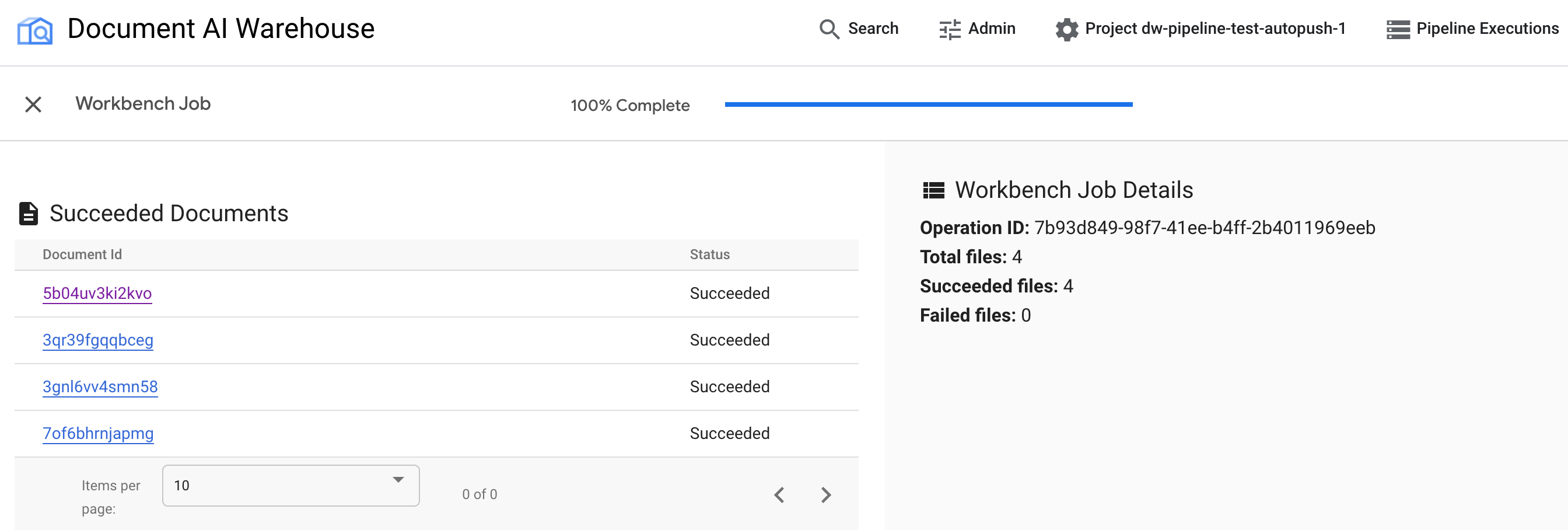
Ergebnisse ansehen
Nach Abschluss des Jobs können Sie die erfolgreichen und fehlgeschlagenen Dokumente sehen.
So prüfen Sie, ob die Dokumente korrekt exportiert wurden:
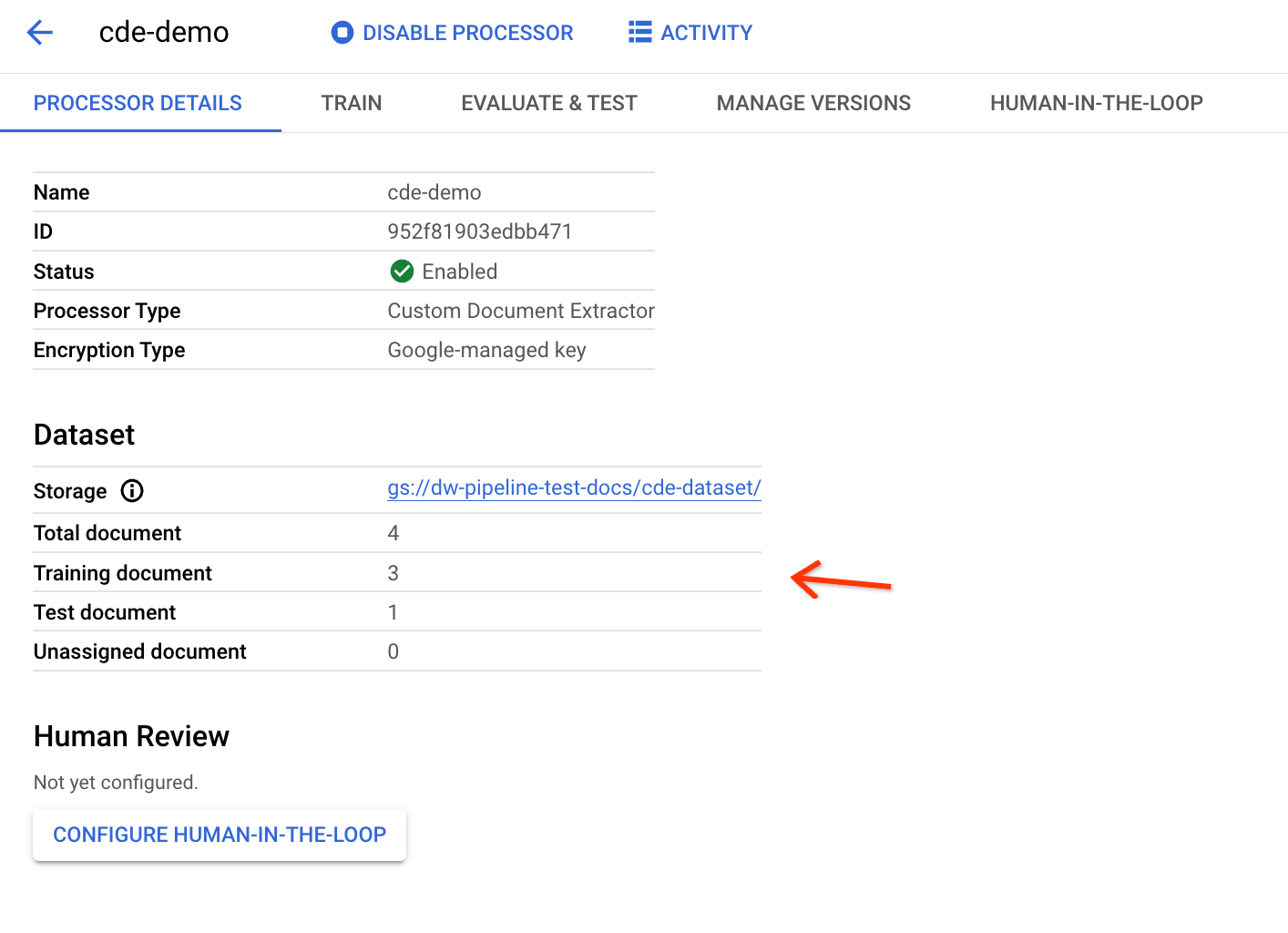
Wenn Sie die Seite vor der Ausführung der Pipeline geöffnet haben, aktualisieren Sie sie, um die aktualisierten Statistiken zu sehen. Die Verteilungen von Trainings- und Test-Dataset basieren auf dem Verhältnis der Datenaufteilung.
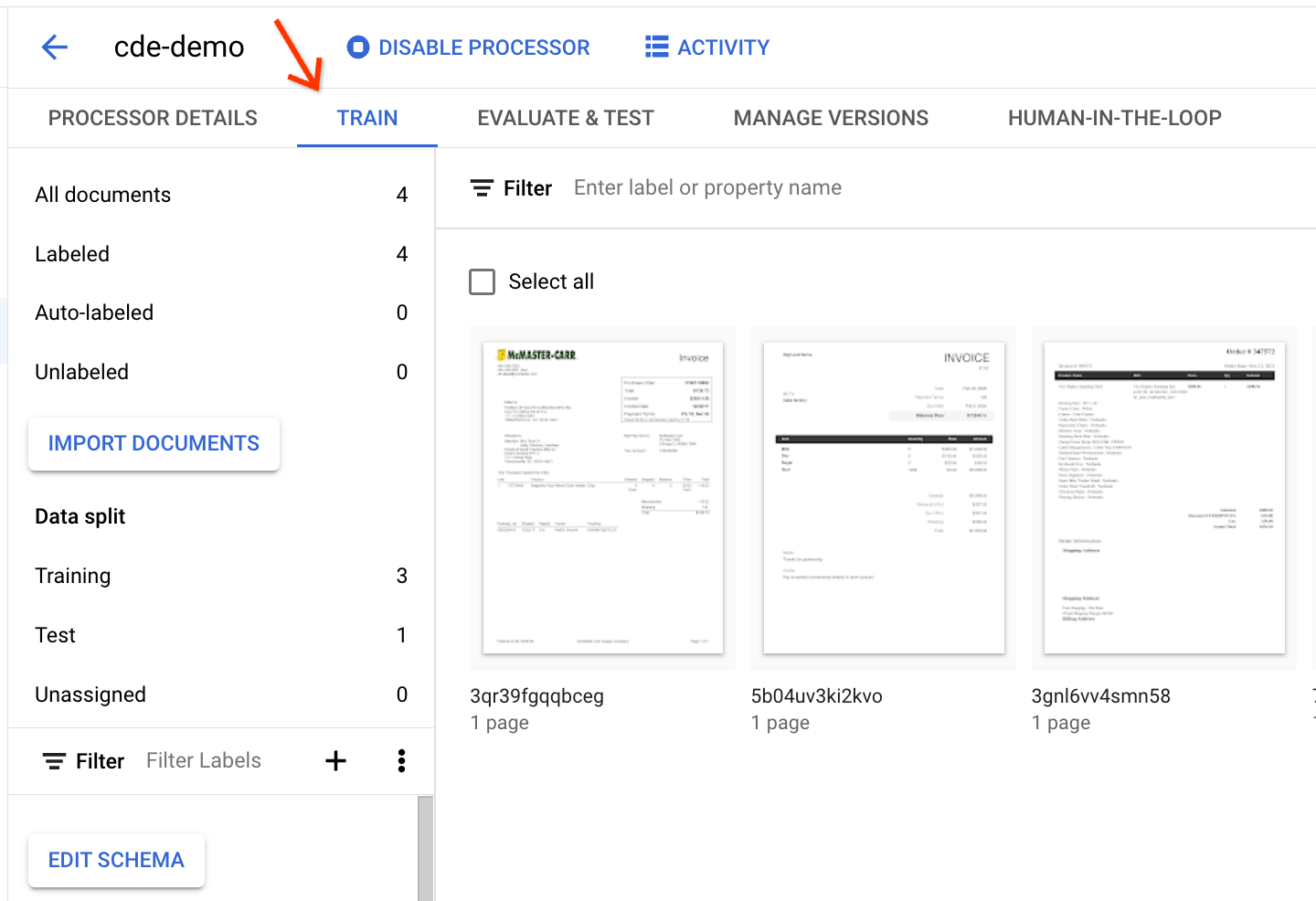
So rufen Sie die Dokumente im Detail auf:
Nächster Schritt
Weitere Informationen zur runPipeline API