
このドキュメントでは、バックグラウンドで Cloud Storage 取り込みパイプラインをトリガーする一括アップロードを実行する方法について説明します。
前処理のオプション
現在、一括アップロードでは次の 3 つの前処理オプションが用意されています。
前処理なしの一括アップロード: Document AI プロセッサでドキュメントを処理せずに、GcsIngestPipeline を使用して runPipeline API をトリガーします。
Document AI プロセッサでエンティティを抽出する: これにより、 GcsIngestWithDocAiProcessorsPipeline を使用して runPipeline API がトリガーされます。 パイプラインは、まず指定された Document AI プロセッサを呼び出し、処理された結果を使用してドキュメントを取り込みます。
ドキュメント タイプを分類し、タイプごとにエンティティを抽出する: これも GcsIngestWithDocAiProcessorsPipeline を使用して runPipeline API をトリガーします。 これにより、まず分類子が呼び出されます。次に、ドキュメント タイプごとに、特定のドキュメント タイプを処理する 対応するスキーマとプロセッサを指定できます。結果とともに取り込まれ、このスキーマに設定されます。
各前処理タイプは、UI の次のオプションに対応しています。
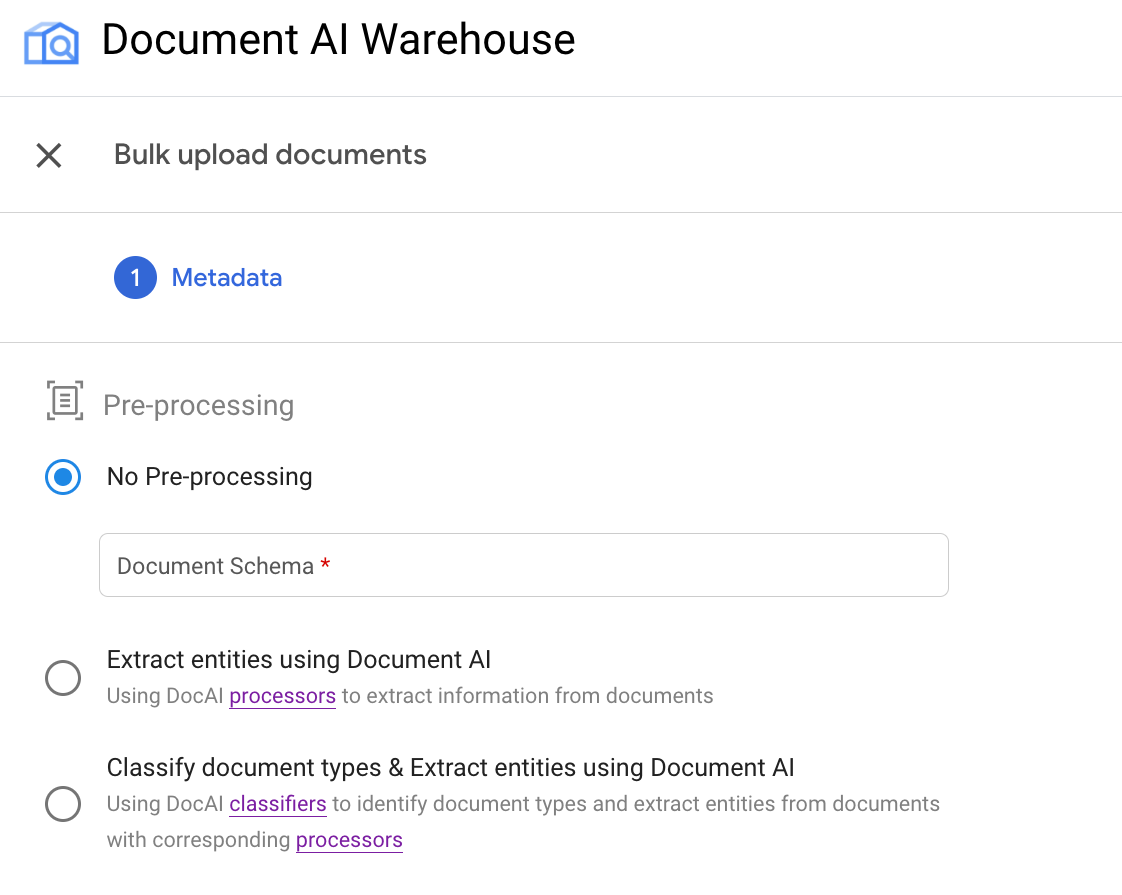
例: OCR プロセッサで一括アップロードをトリガーする
この例では、パイプラインの 2 つ目の使用方法を示します。
OCR プロセッサを作成してプロセッサ ID を取得する
以前に OCR プロセッサを作成したことがある場合は、プロセッサ リストでそのプロセッサを見つけて、プロセッサの詳細ページに移動し てプロセッサ ID を取得します。
作成していない場合は、次の手順を行います。
プロセッサ リストの上部にある [プロセッサ ギャラリー] をクリックします。
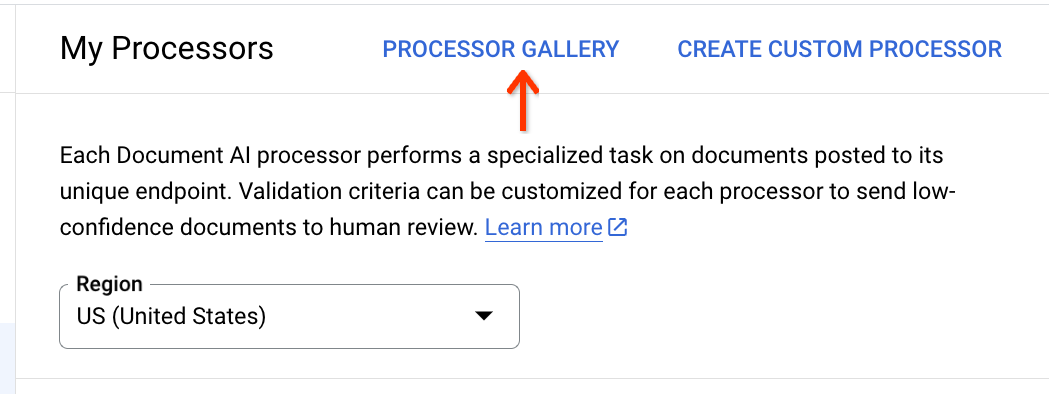
ギャラリーで Document OCR プロセッサを見つけ、 カードの下部にある [プロセッサを作成] をクリックします。
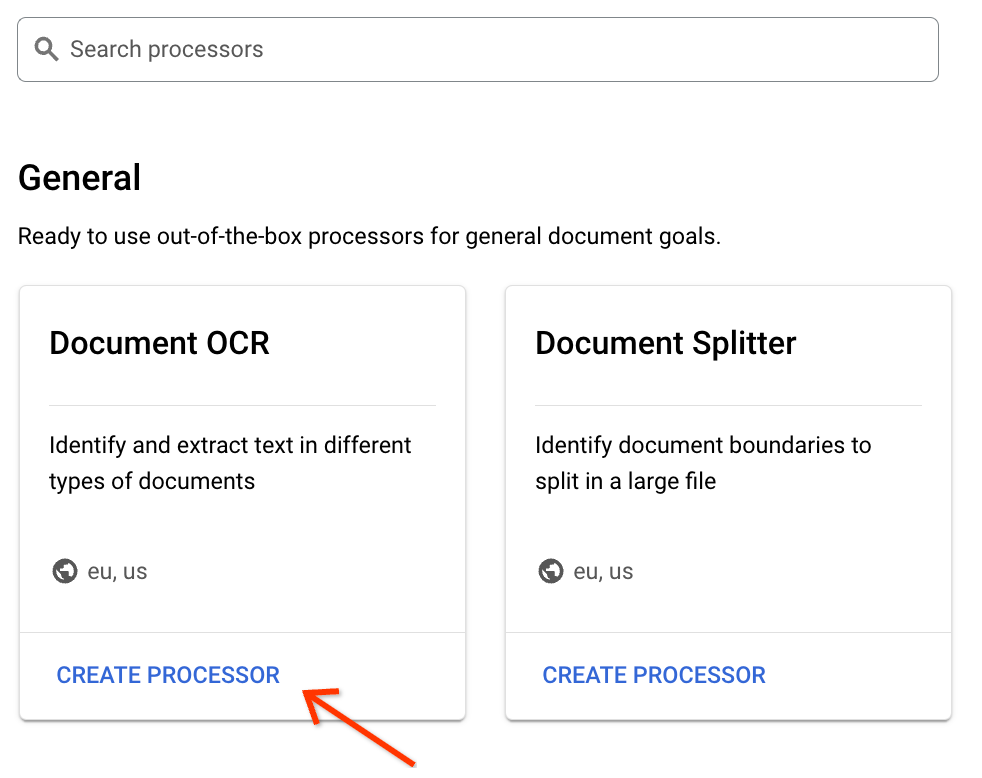
プロセッサの表示名を入力します。
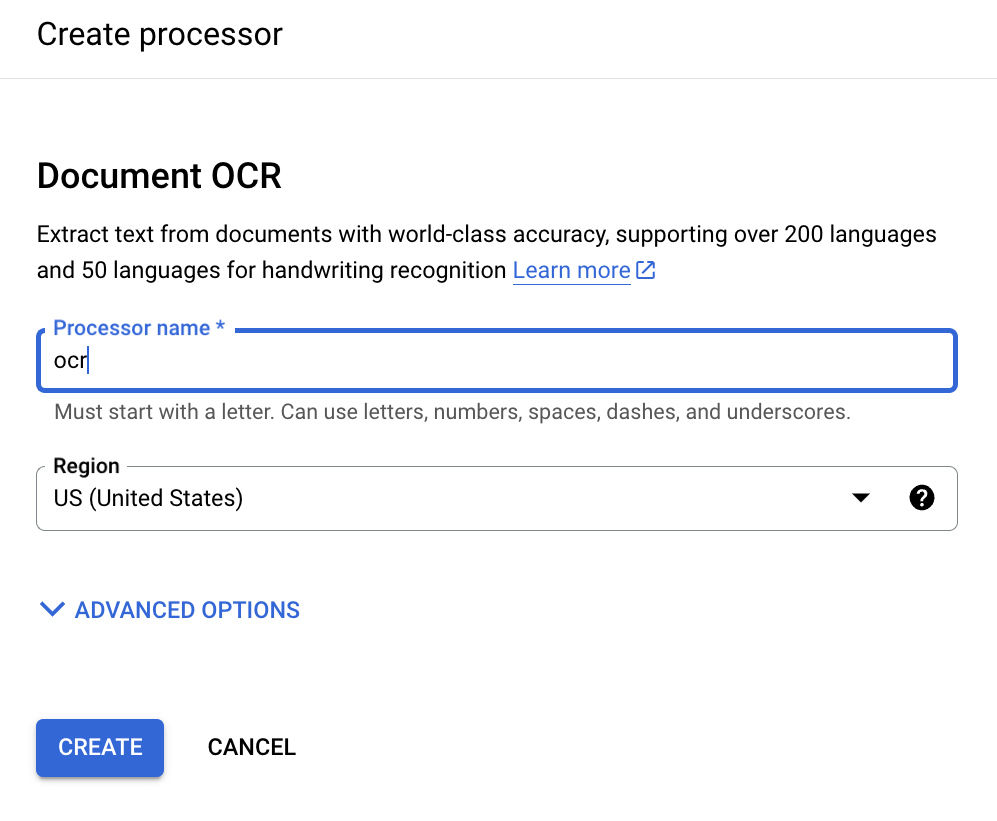
[作成] をクリックします。[プロセッサの詳細] ページにリダイレクトされたら、ID を見つけます。
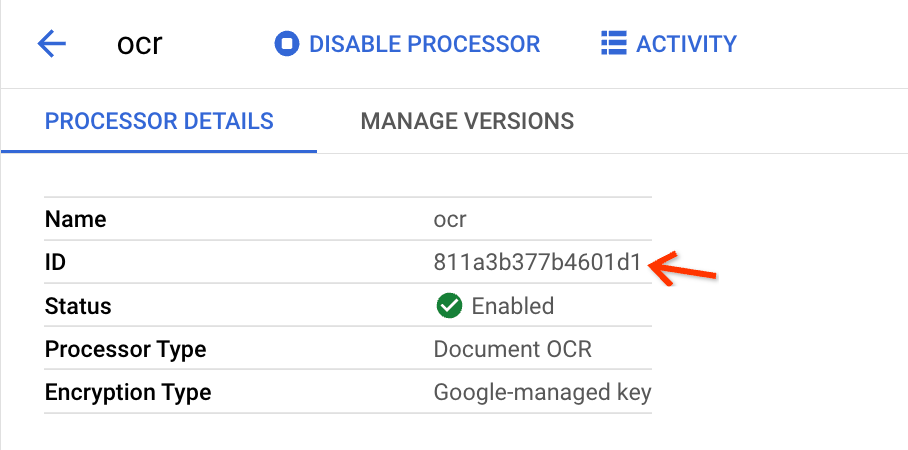
これは、一括アップロード ビューの入力フィールドにコピーする必要があるものです。
一括アップロードをトリガーする
一括アップロード ビューを開きます。
[新規追加] の横にある [一括アップロード] をクリックします。
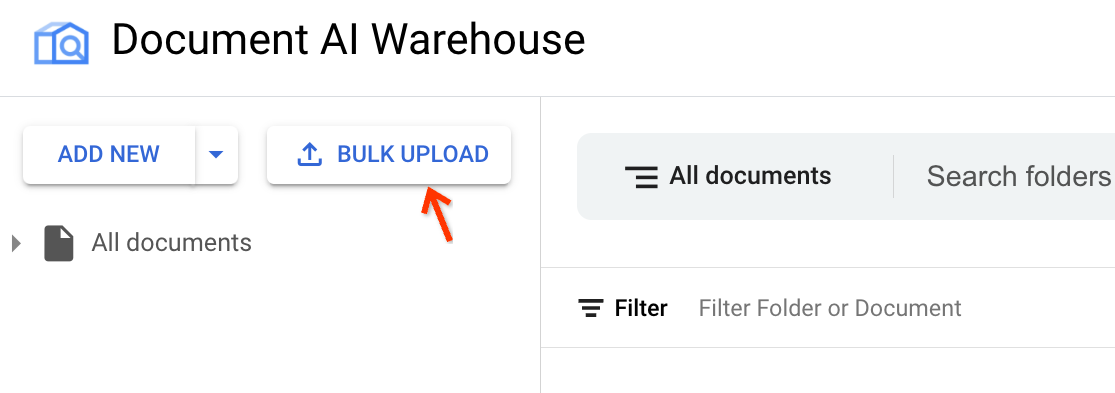
適切なプロセッサを見つけます。
2 つ目の前処理オプションを選択します。
スキーマを選択し、抽出結果を JSON 形式で保存するプロセッサと Cloud Storage バケットパスを指定します。
説明テキストのリンクからプロセッサ ID を見つけます。
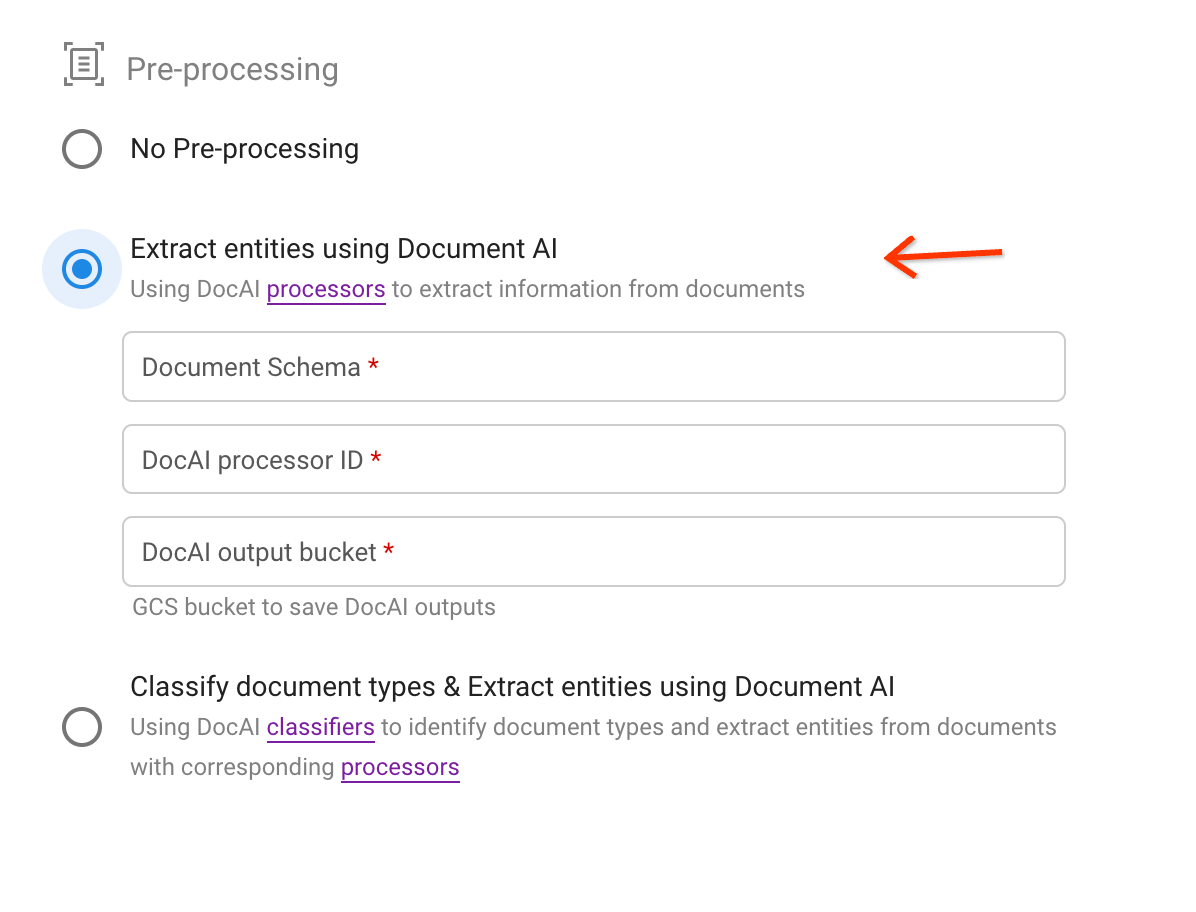
アップロードをトリガーします。
前のステップでコピーしたプロセッサ ID を使用して、入力フィールドを指定します。ソース ファイル バケットパスには、バケット、バケット内のフォルダ、サブフォルダを指定できます。
入力フィールドが有効な場合は、一括アップロードをトリガーするため、右上の [アップロード] をクリックします。
ステータス ページで進行状況を確認する
一括アップロードがトリガーされると、ステータス トラッキング ページにリダイレクトされます。
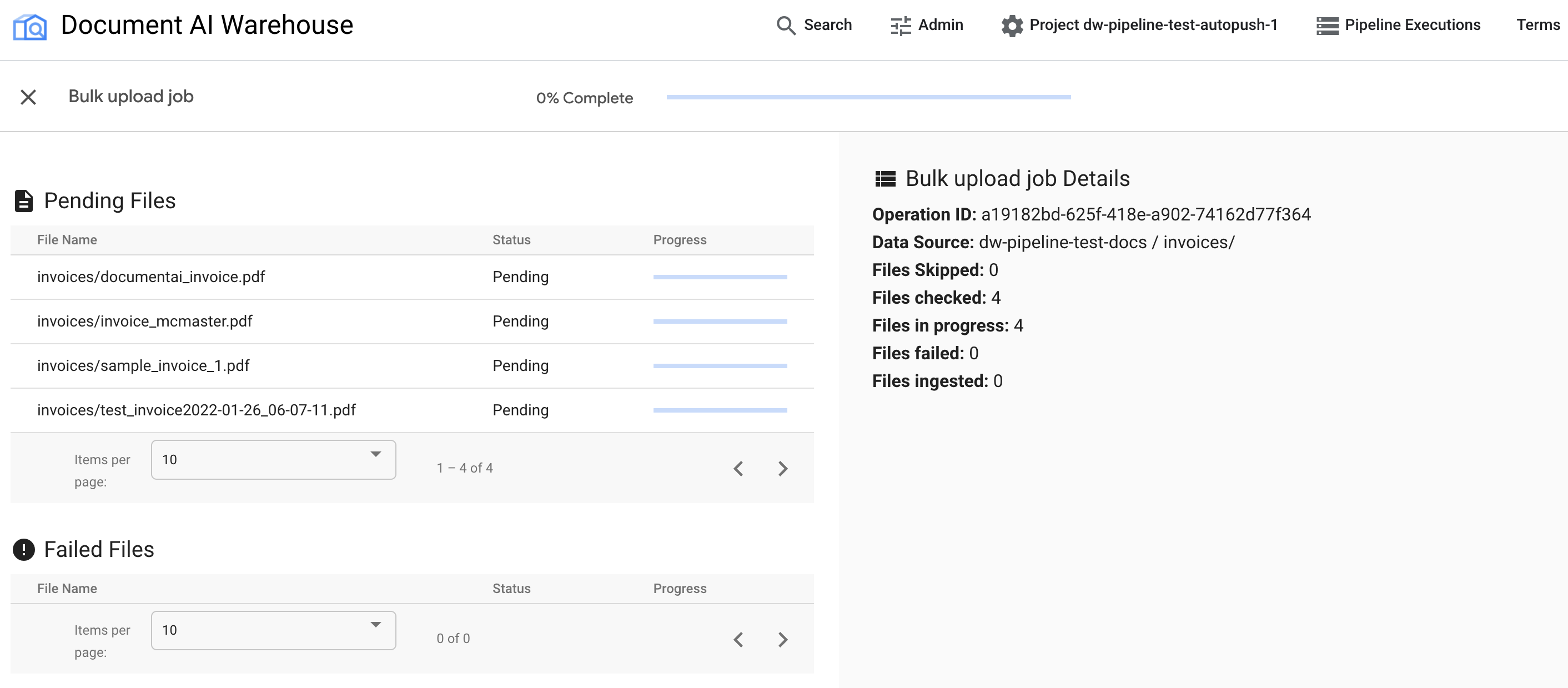
最初の表には、保留中または処理済みのドキュメントが表示されます。取り込まれたドキュメントは、最初の表に表示されなくなります。アップロードに失敗したドキュメントは、2 番目の表に表示されます。右側の統計には、取り込まれたドキュメント、失敗したドキュメント、保留中のドキュメントの数が表示されます。
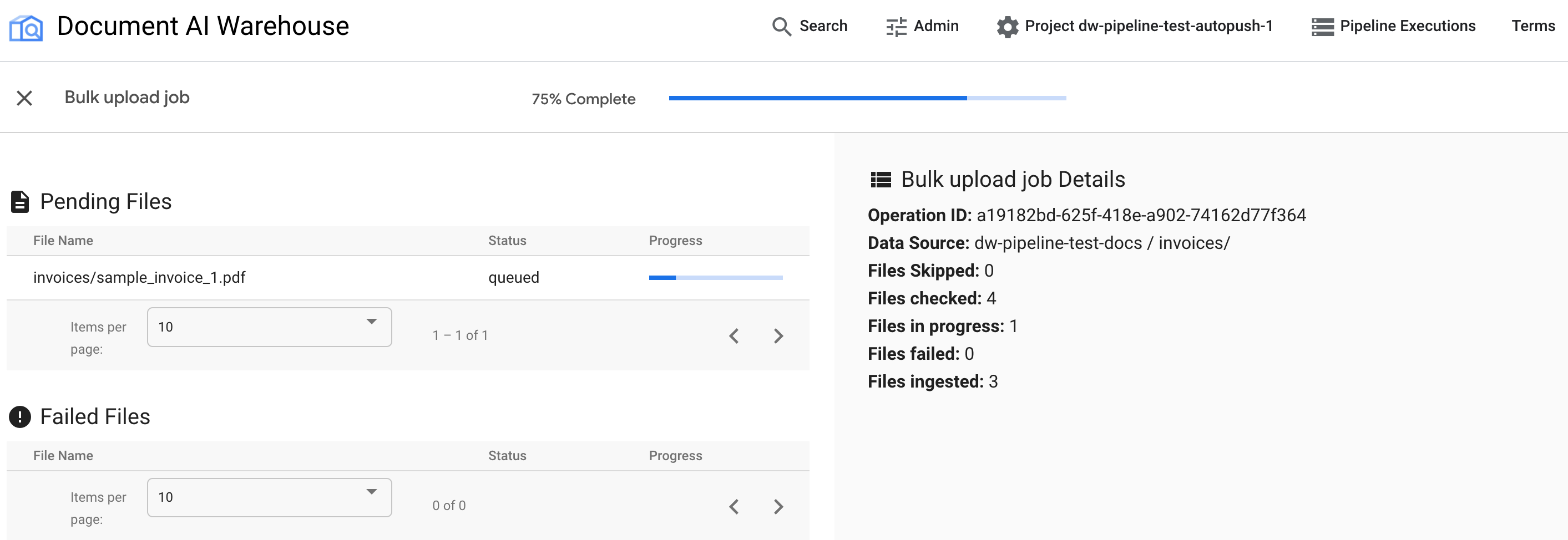
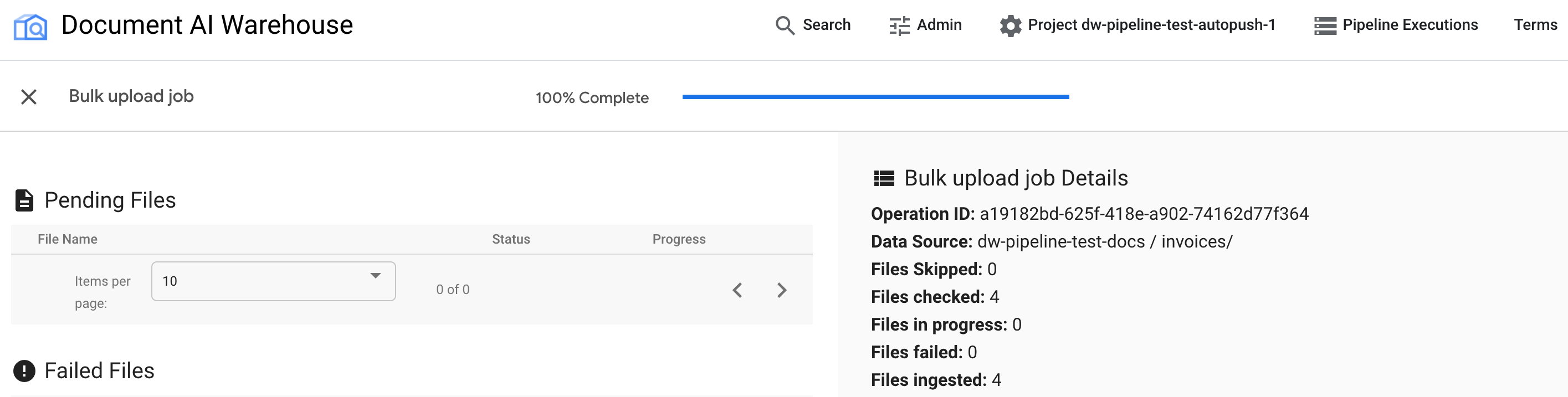
ジョブが完了すると、ステータス ページに [100% 完了] と表示され、保留中のドキュメントは表示されません。
アップロードしたドキュメントを確認する
検索ビューに戻って、新しく取り込まれたドキュメントを見つけます。上部のナビゲーション バーにある Document AI Warehouse のロゴまたは [検索] をクリックします。

ドキュメント名をクリックして、新しく取り込まれたドキュメントを開きます。ドキュメント ビューアで、[AI ビュー] を開くことができます。
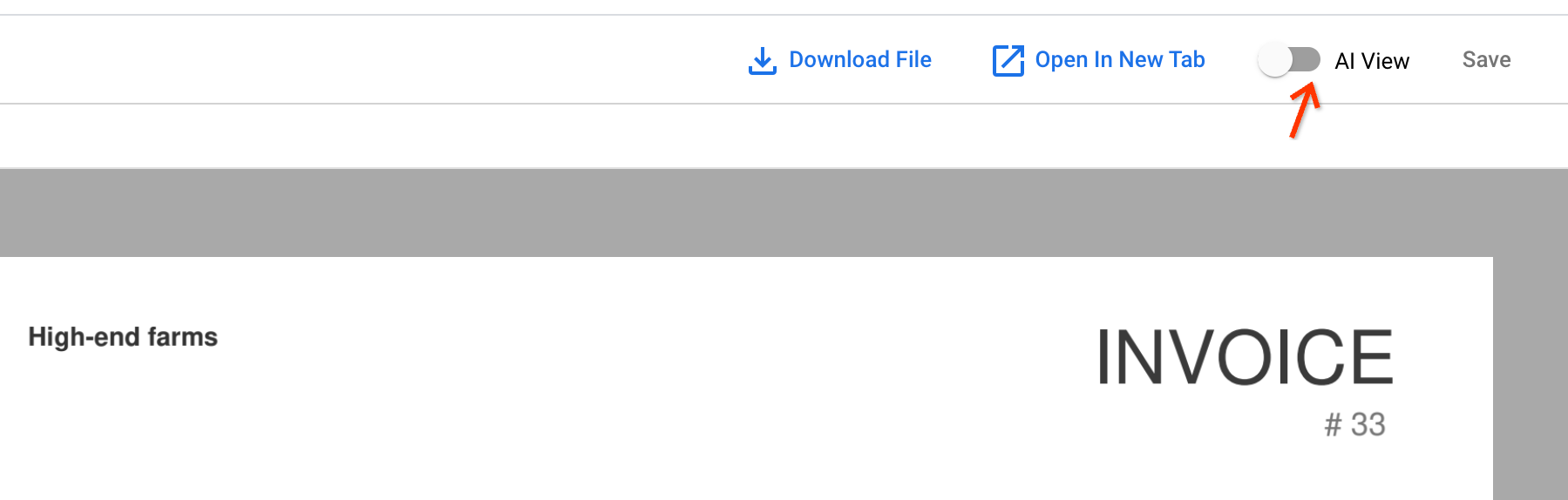
[テキスト ブロック] タブに移動します。OCR の結果はドキュメントに保存されます。
次のステップ
Document AI パイプラインで抽出して、既存のドキュメントを更新します。