
In diesem Dokument wird beschrieben, wie Sie einen Bulk-Upload durchführen, der im Hintergrund die Cloud Storage-Aufnahmepipeline auslöst.
Vorverarbeitungsoptionen
Derzeit bietet der Bulk-Upload drei Vorverarbeitungsoptionen:
Bulk-Upload ohne Vorverarbeitung: Dadurch wird die runPipeline API mit GcsIngestPipeline ausgelöst, ohne die Dokumente mit Document AI-Prozessoren zu verarbeiten.
Entitäten mit Document AI-Prozessoren extrahieren: Dadurch wird die runPipeline API mit GcsIngestWithDocAiProcessorsPipeline ausgelöst. Die Pipeline ruft zuerst den angegebenen Document AI-Prozessor auf und nimmt dann die Dokumente mit den verarbeiteten Ergebnissen auf.
Dokumenttypen klassifizieren und Entitäten für jeden Typ extrahieren: Dadurch wird auch die runPipeline API mit GcsIngestWithDocAiProcessorsPipeline ausgelöst, die zuerst einen Klassifikator aufruft. Anschließend können Sie für jeden Dokument typ ein entsprechendes Schema und einen Prozessor angeben, um diese bestimmten Dokument typen zu verarbeiten. Sie werden mit den Ergebnissen aufgenommen und auf dieses Schema festgelegt.
Jeder Vorverarbeitungstyp entspricht den folgenden Optionen in der Benutzeroberfläche:
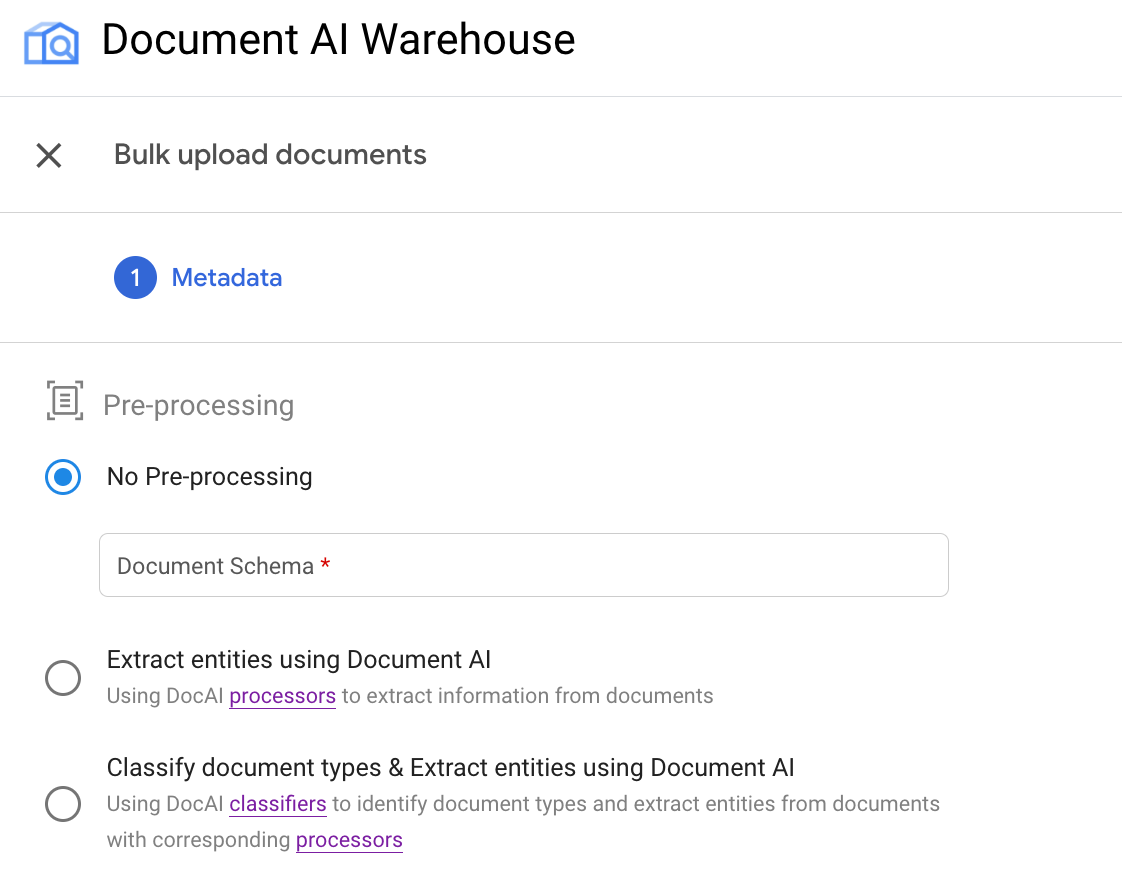
Beispiel: Bulk-Upload mit einem OCR-Prozessor auslösen
In diesem Beispiel wird die zweite Verwendung der Pipeline veranschaulicht.
OCR-Prozessor erstellen und Prozessor-ID abrufen
Wenn Sie bereits einen OCR-Prozessor erstellt haben, suchen Sie ihn einfach in der Prozessor Liste. Rufen Sie die Detailseite des Prozessors auf und rufen Sie die Prozessor-ID ab.
Wenn Sie noch keinen erstellt haben, führen Sie die folgenden Schritte aus:
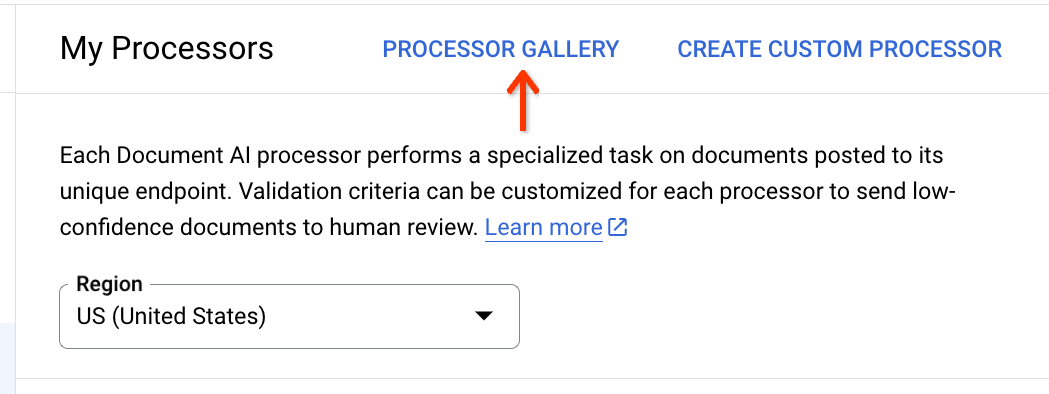
Klicken Sie oben in der Prozessor liste auf die Prozessor Galerie:
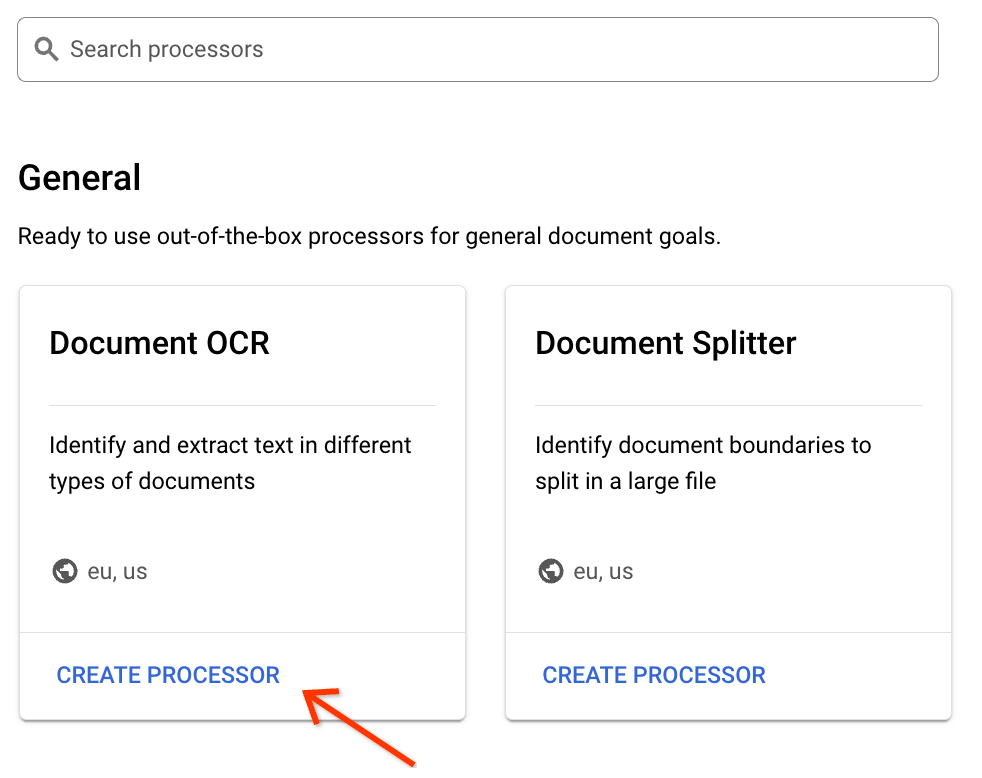
Suchen Sie in der Galerie nach dem Document OCR-Prozessor und klicken Sie unten auf der Karte auf Prozessor erstellen:
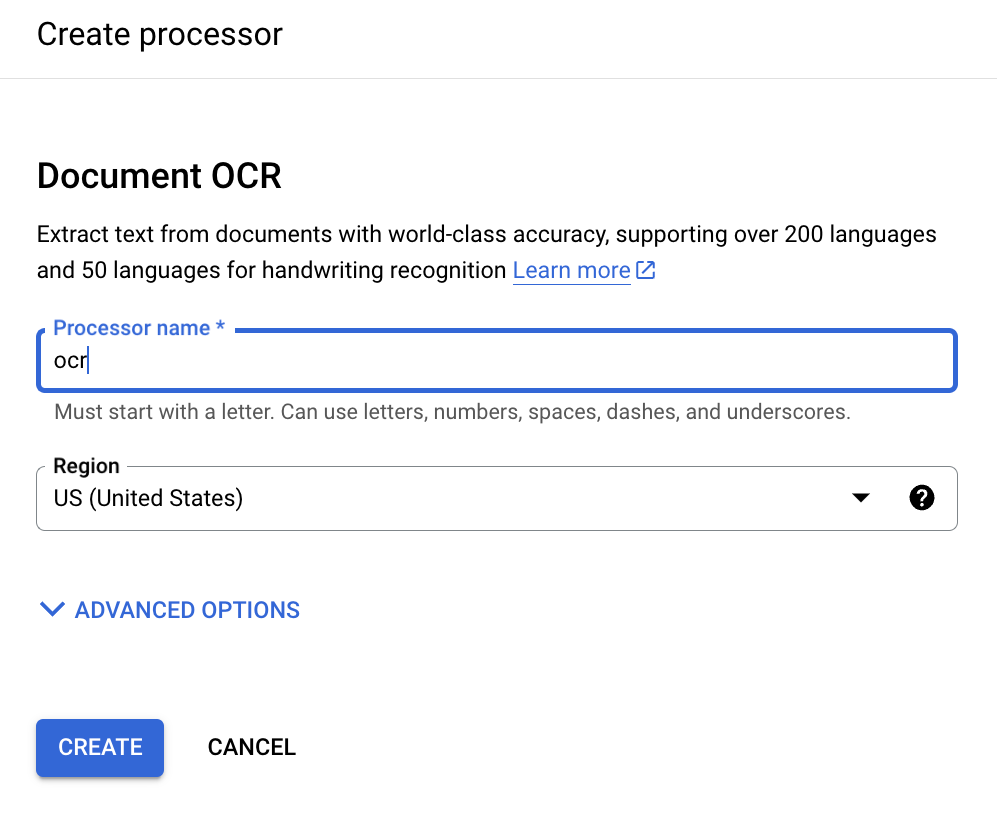
Geben Sie einen Anzeigenamen für den Prozessor ein:
Klicken Sie auf Erstellen und suchen Sie die ID, wenn Sie zur Seite Prozessordetails weitergeleitet werden:
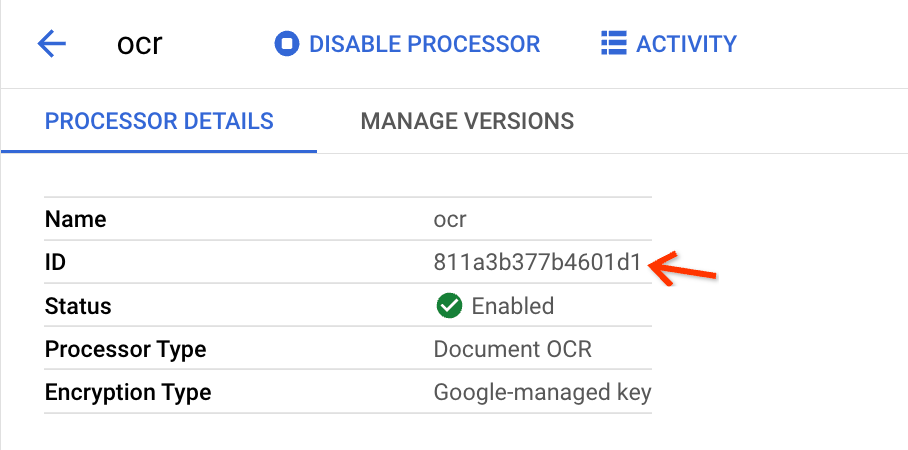
Diese ID müssen Sie in die Eingabefelder in der Bulk-Upload-Ansicht kopieren.
Bulk-Upload auslösen
Öffnen Sie die Bulk-Upload-Ansicht.
Klicken Sie neben Neu hinzufügen auf Bulk-Upload:
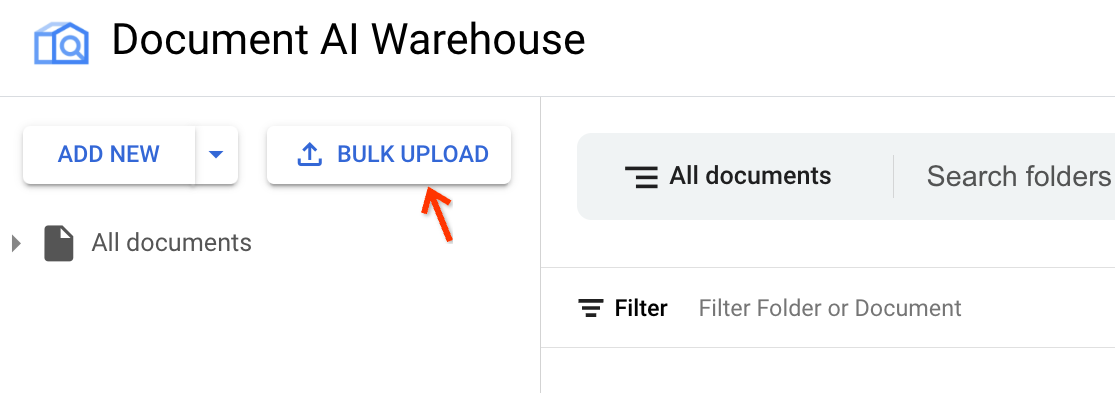
Suchen Sie den richtigen Prozessor.
Wählen Sie die zweite Vorverarbeitungsoption aus.
Wählen Sie ein Schema aus und geben Sie einen Prozessor und einen Cloud Storage-Bucket-Pfad an, um die Extraktionsergebnisse im JSON-Format zu speichern.
Suchen Sie die Prozessor-ID über den Link im Beschreibungstext:
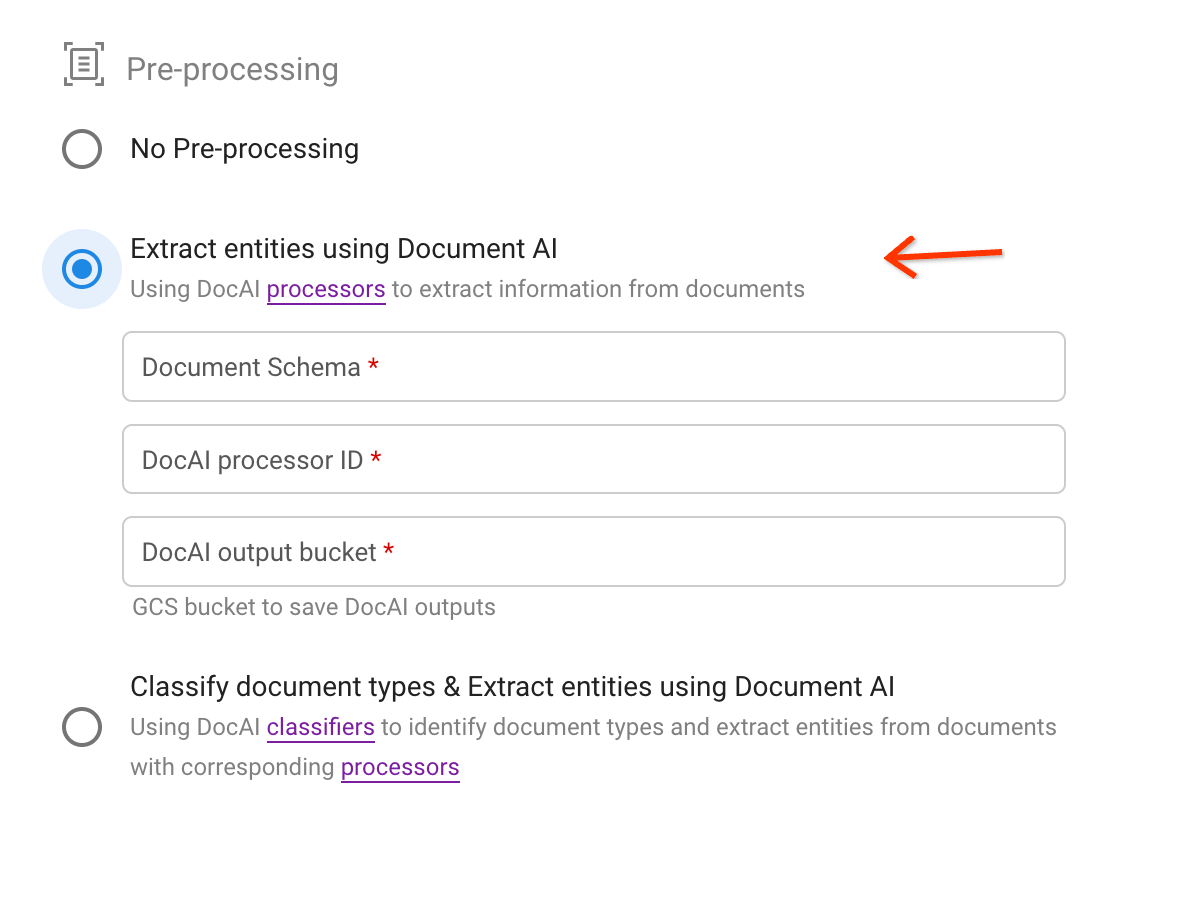
Upload auslösen:
Geben Sie die Eingabefelder mit der im letzten Schritt kopierten Prozessor-ID an. Der Bucket-Pfad der Quelldatei kann ein Bucket oder ein Ordner oder Unterordner im Bucket sein.
Wenn die Eingabefelder gültig sind, klicken Sie oben rechts auf Hochladen , um den Bulk-Upload auszulösen.
Fortschritt auf der Statusseite prüfen
Nachdem der Bulk-Upload ausgelöst wurde, werden Sie zur Seite zur Statusverfolgung weitergeleitet:
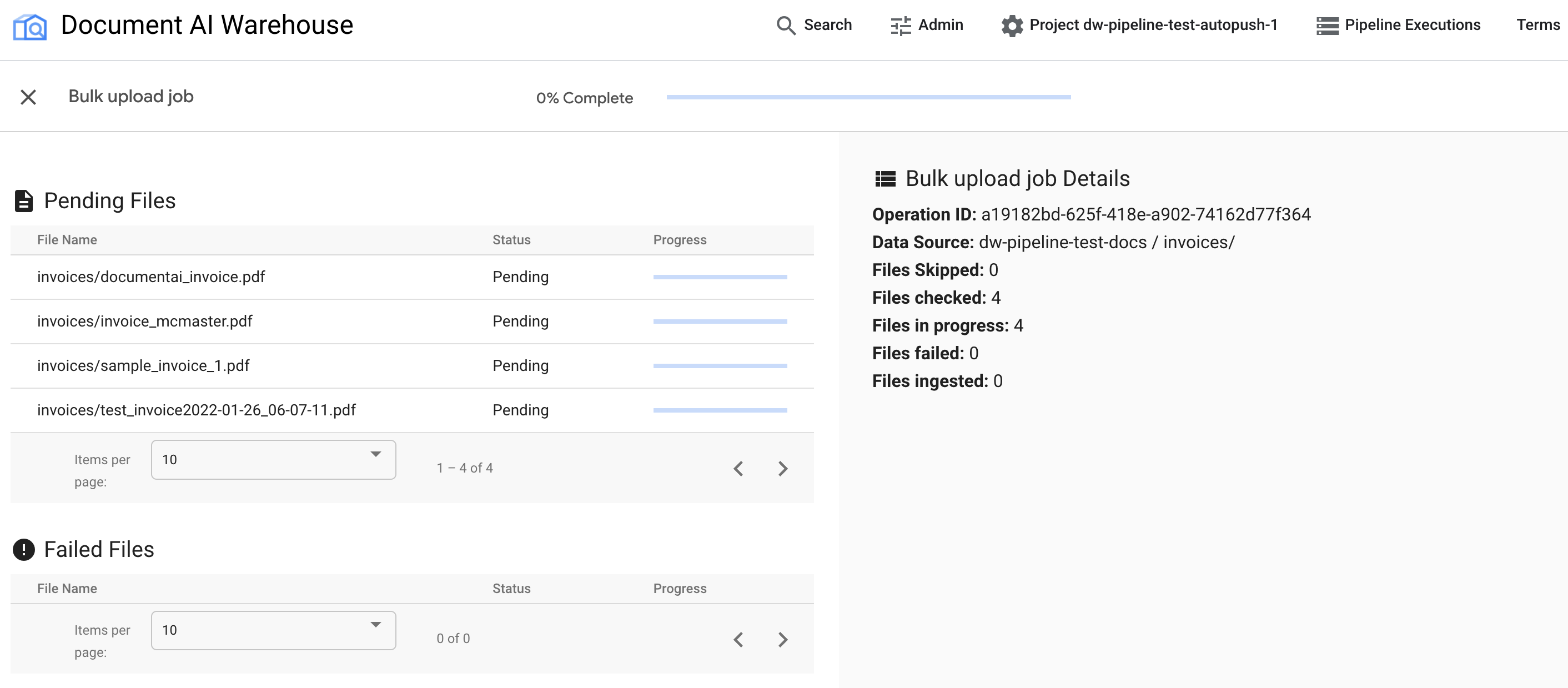
In der ersten Tabelle werden alle ausstehenden oder verarbeiteten Dokumente angezeigt. Nach der Aufnahme wird das Dokument nicht mehr in der ersten Tabelle aufgeführt. Dokumente, die nicht hochgeladen werden konnten, werden in der zweiten Tabelle angezeigt. Rechts sehen Sie in den Statistiken die Anzahl der aufgenommenen, fehlgeschlagenen und ausstehenden Dokumente.
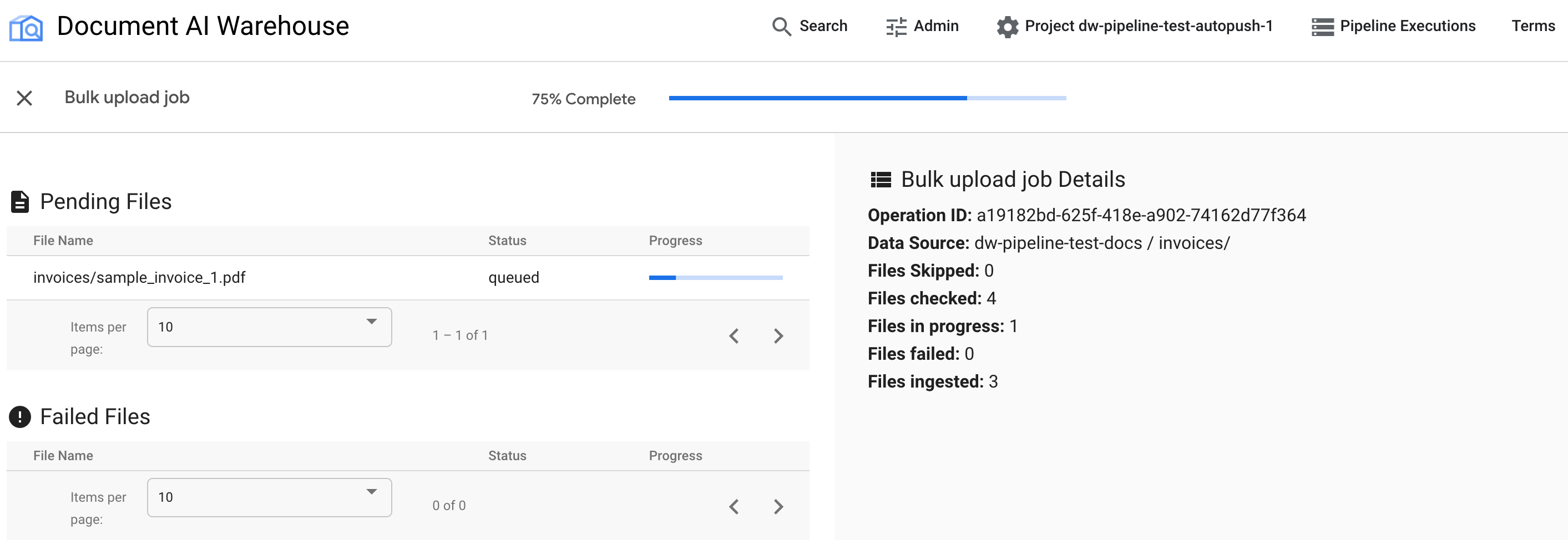
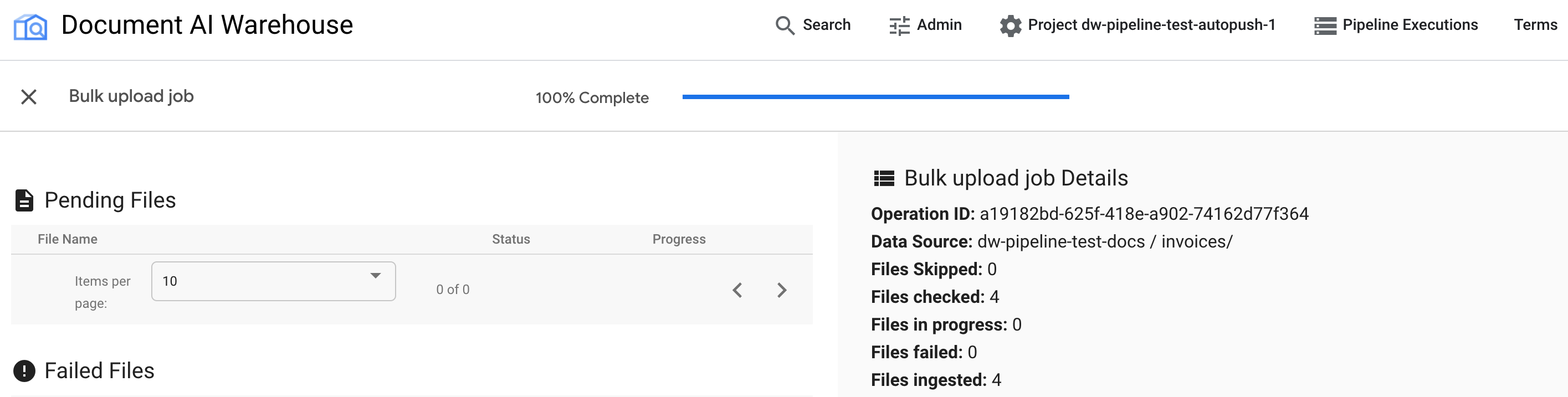
Nach Abschluss des Jobs wird auf der Statusseite angezeigt, dass 100% abgeschlossen sind und keine ausstehenden Dokumente vorhanden sind:
Hochgeladene Dokumente prüfen
Suchen Sie die neu aufgenommenen Dokumente, indem Sie zur Suchansicht zurückkehren. Klicken Sie oben in der Navigationsleiste auf das Document AI Warehouse-Logo oder auf Suchen:

Öffnen Sie eines der neu aufgenommenen Dokumente, indem Sie auf den Dokumentnamen klicken. In der Dokumentansicht können Sie die AI-Ansicht öffnen.
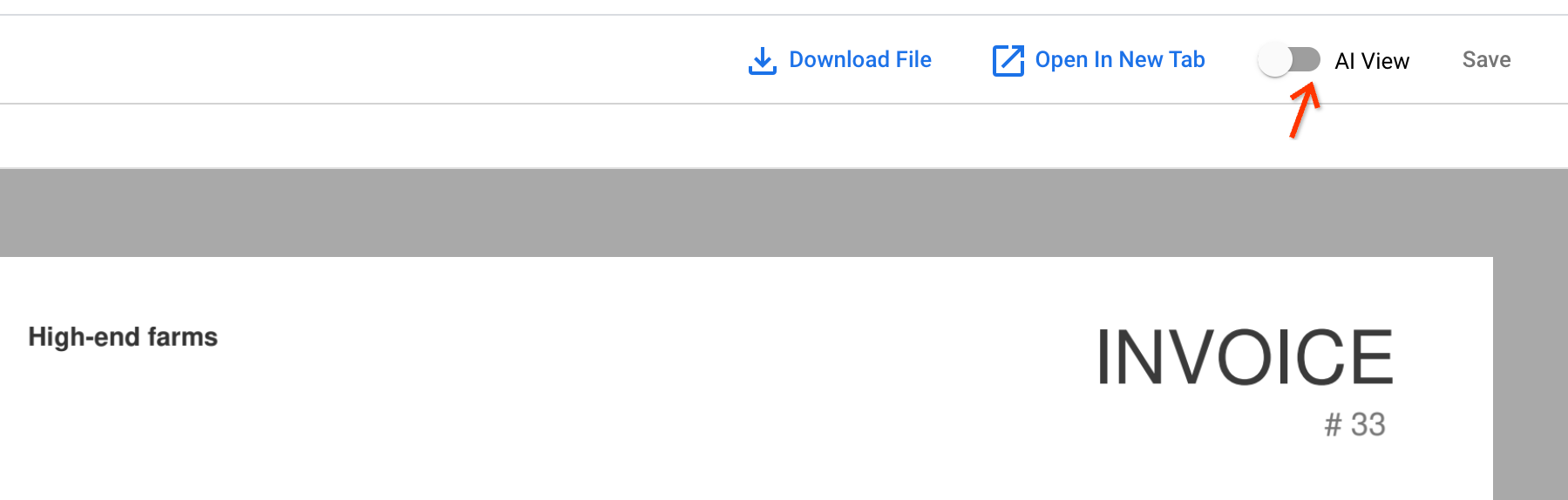
Rufen Sie den Tab Textblock auf. Die OCR-Ergebnisse werden im Dokument gespeichert:
Nächster Schritt
Aktualisieren Sie vorhandene Dokumente mit der Pipeline „Mit Document AI extrahieren“.