
BigQuery 连接器简介
BigQuery 连接器可帮助您将存储在 Document AI Warehouse 中的文档元数据 (包括属性)导出到您的 BigQuery 表中。将数据存储在 BigQuery 中后,您可以运行分析、创建报告和信息中心,以帮助您做出业务决策。
如需启用 BigQuery 连接器,您需要设置 BigQuery 表并授予必要的权限,并通过 API 配置异步任务。BigQuery 连接器会将数据从 Document AI Warehouse 导出到您的 BigQuery 表。
前期准备
设置 Document AI Warehouse 并注入文档。如需了解详情,请按照 快速入门操作。
您必须确保托管 BigQuery 表的项目与 Document AI Warehouse 用于存储文档的项目相同。换句话说,数据必须始终从 Document AI Warehouse 导出到同一项目中的 BigQuery 表。
在项目中,您必须拥有 Owner (roles/owner) 角色,或者必须拥有 resourcemanager.projects.getIamPolicy 和 resourcemanager.projects.setIamPolicy
权限。
设置 BigQuery 访问权限
将服务帐号 doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
绑定到 BigQuery Admin 角色:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
设置 BigQuery 数据集和表
设置 BigQuery 数据集和表,以便 Document AI Warehouse 导出数据。如果您没有 BigQuery 数据集,请按照 创建数据集中的说明创建一个。
在 BigQuery 数据集中创建 BigQuery 表。按照 BigQuery 说明, 使用 DDL 示例语句创建表:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
DDL 会为您创建一个新的 BigQuery 表。该表按小时进行时间分区,分区将在 150 天后删除。
配置 BigQuery 连接器
创建数据导出配置
以下说明会创建一个新的数据导出作业,该作业会设置异步作业以导出数据。我们建议您为每个新的数据导出作业使用一个空表。如需了解配置详情,请参阅 API 参考文档 。
您有以下运行选项。可以使用 FREQUENCY 配置这些选项。
请参阅 API
参考文档。
- ADHOC :作业仅运行一次。所有数据都会导出到您的 BigQuery 表。
- DAILY :作业每天运行。首次运行时,所有数据都会导出到您的 BigQuery 表。初始导出完成后,只有前一天的数据更改(或上次成功同步后的增量)会导出到您的 BigQuery 表。
- HO网址Y :作业每小时运行一次。首次运行时,所有数据都会导出到您的 BigQuery 表。初始导出完成后,只有前一小时的数据更改(或上次成功同步后的增量)会导出到您的 BigQuery 表。
在使用任何请求数据之前, 请先进行以下替换:
- PROJECT_NUMBER:您的 Google Cloud 项目编号
- LOCATION:您的 Document AI Warehouse 位置(例如 `us`)
- DATASET_LOCATION:您的数据集位置
- DATASET_NAME:您的数据集名称
- TABLE_NAME:您的表名称
-
FREQUENCY:
ADHOC、DAILY或HOURLY之一。
请求 JSON 正文:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
作业执行
成功创建作业后,该作业会根据您的配置运行。请注意,作业是异步运行的,因为执行需要时间。首次运行可能需要一些时间才能完成,具体取决于要导出的数据量。对于每日作业,请等待 24 小时,结果才会显示在 BigQuery 表中。
删除数据导出配置
以下命令会删除(通过归档)您创建的作业。
在使用任何请求数据之前, 请先进行以下替换:
- PROJECT_NUMBER:您的 Google Cloud 项目编号
- LOCATION:您的 Document AI Warehouse 位置(例如 `us`)
- JOB_ID:您的作业 ID,在您创建作业时返回的响应中
请求 JSON 正文:
{}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
之后,您的导出作业将被删除(归档),Document AI Warehouse 将不再运行该作业。
探索提取到 BigQuery 中的数据
如需将文档元数据和属性提取到 BigQuery 中的不同表字段以满足您的分析需求,您可以使用以下 DDL 示例查询。这些提取的字段还可以在数据洞察或任何 BI 信息中心工具中使用,以直观呈现数据中的关系。
从 document_json 中提取关键字段
此查询从数据导出中选择相关字段,包括文档元数据(存储在 document_json 字段中)中的关键字段。
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
从 document_json 中取消嵌套属性
此查询从文档元数据 (document_json) 中取消嵌套属性,以创建键值对(属性名称、值)。在下一个查询中,这些键值对将转换为各个表字段,以实现属性级数据探索和信息中心可视化。
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
将 document_json 中的属性透视到 BigQuery 中以创建表字段
以下过程会创建一个表,其中包含通过透视属性和关联值转换的所有文档属性作为各个表字段。您可以利用此表的结果,通过数据洞察和其他 BI 可视化工具中的后续查询来获取更多分析洞见。
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
数据清理和转换过程(特定于业务场景)
根据提取到 BigQuery 中的数据,您可能需要执行其他数据清理和转换过程,以便进行进一步分析。 此类过程因具体情况(数据集)而异,应根据需要执行。
数据清理过程的一些示例可能包括(但不限于):
- 统一日期格式。
- 整合属性值。
- 将数据类型转换为字符串、浮点数和整数等。
在数据洞察中直观呈现数据
在 BigQuery 中提取、清理和转换数据后,您可以将最终数据集导出到数据洞察 以进行可视化 分析。
Looker 信息中心
示例信息中心概述了可以从数据集中创建的可视化效果。在此场景中,从 Document AI Warehouse 导出的示例数据包含 W2 和发票(两种架构)。
示例视图:Document AI Warehouse 分析概览
以下信息中心可让您大致了解提取到 Document AI Warehouse 实例中的各种文档。
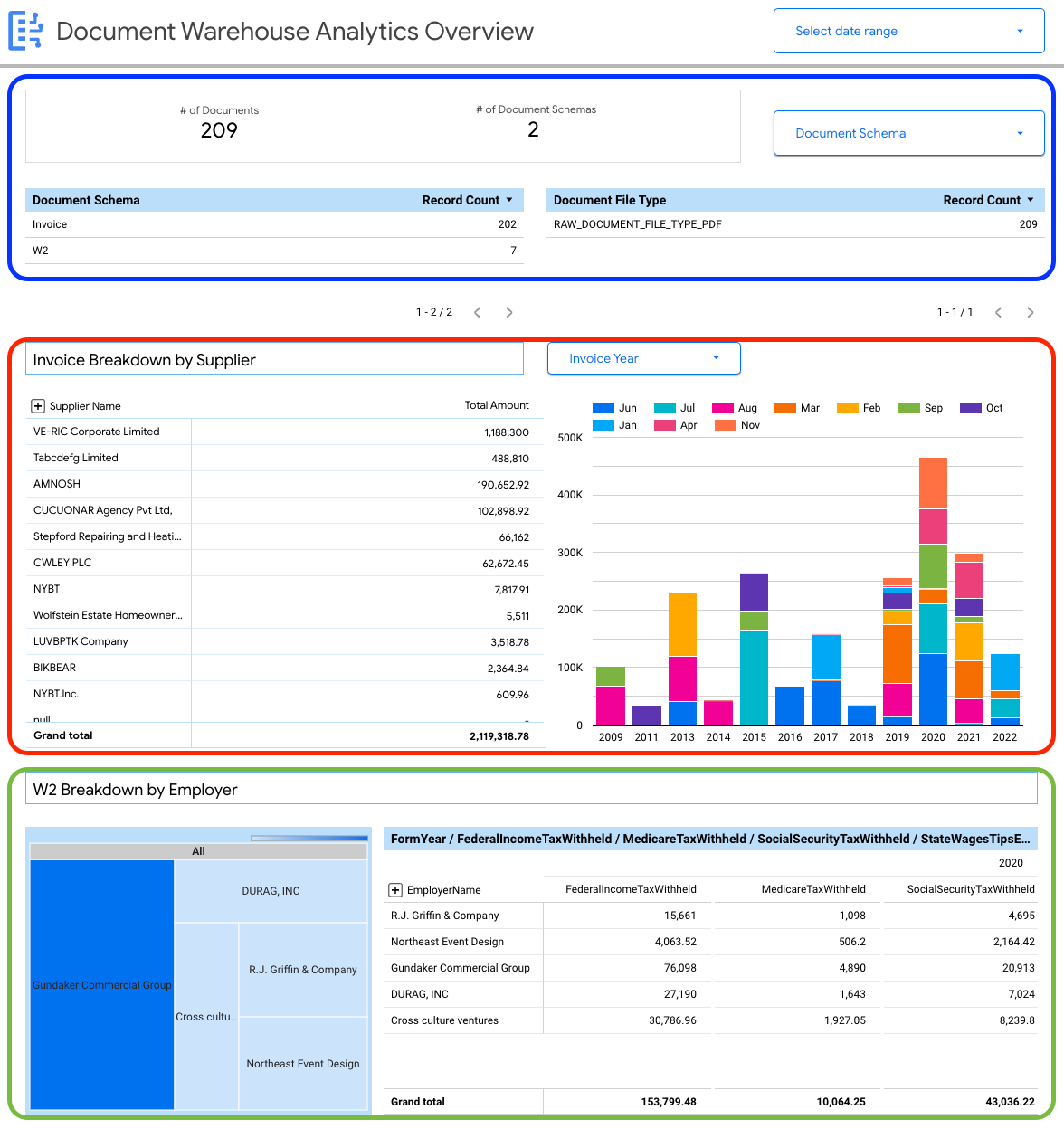
您可以查看文档级详细信息,包括:
- 文档总数。
- 文档架构总数。
- 按文档架构统计的记录数。
- 文档文件类型(例如 PDF、文本、未指定类型)。
您还可以使用从文档元数据 (document_json) 中提取的属性,为提取到 BigQuery 中的发票和 W2 构建关键细分。
示例视图:特定于业务的数据分析信息中心(发票)
以下信息中心可让用户详细了解单个文档架构(发票),以便深入了解提取到 Document AI Warehouse 中的所有发票。
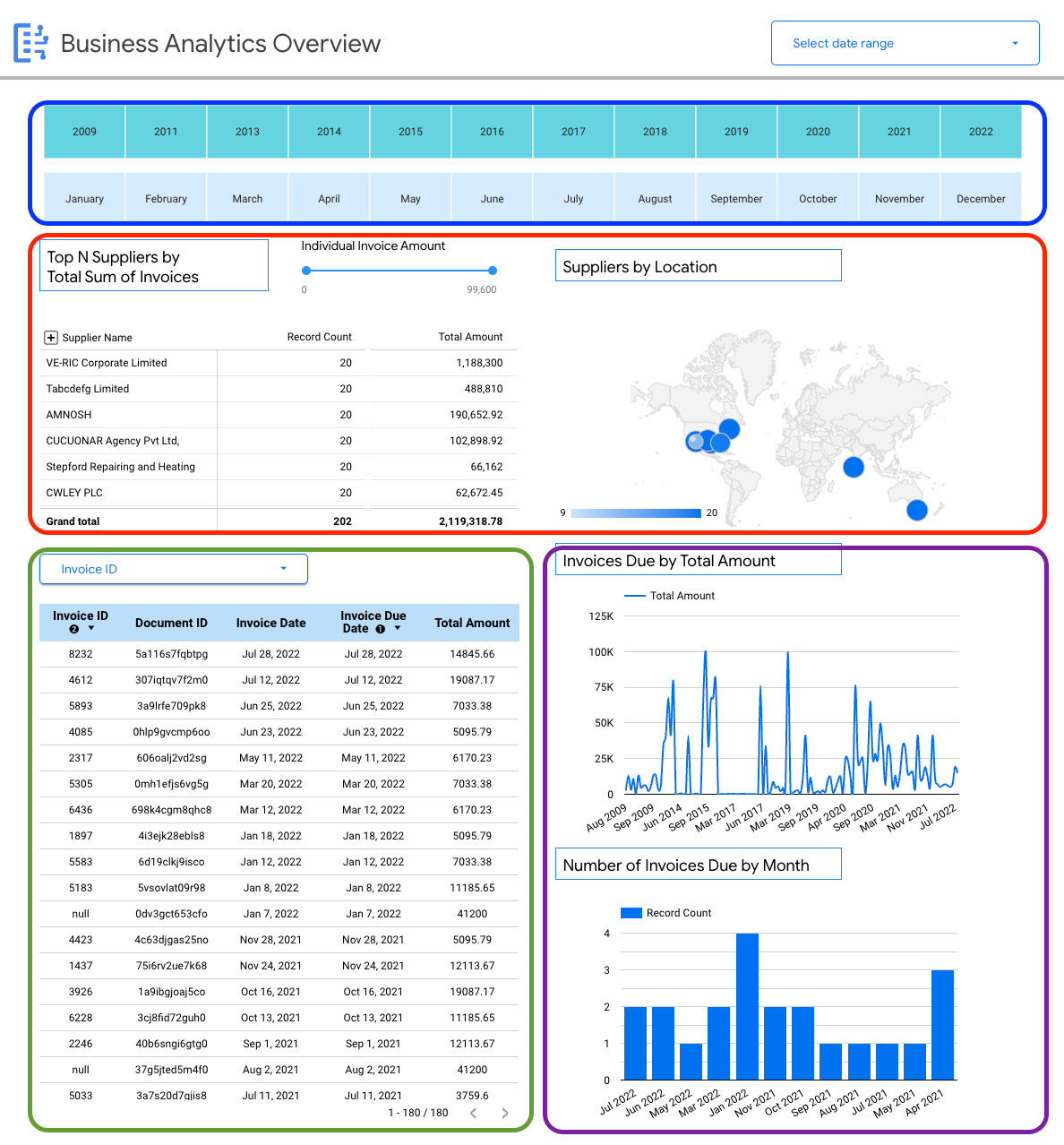
您可以查看发票的架构特定详细信息,例如:
- 按账单金额排名的供应商。
- 按位置排名的供应商。
- 发票日期及其对应的截止日期。
- 按金额和记录数统计的发票环比趋势。
将数据源连接到信息中心
如需使用这些 信息中心 示例 作为可视化数据集的起点,您可以从 BigQuery 连接数据源 。
在将示例信息中心连接到 BigQuery 数据源之前, 请确保您已登录与环境关联的 Google Cloud 账号。

选择突出显示的按钮以显示下拉选项。

选择制作副本 。
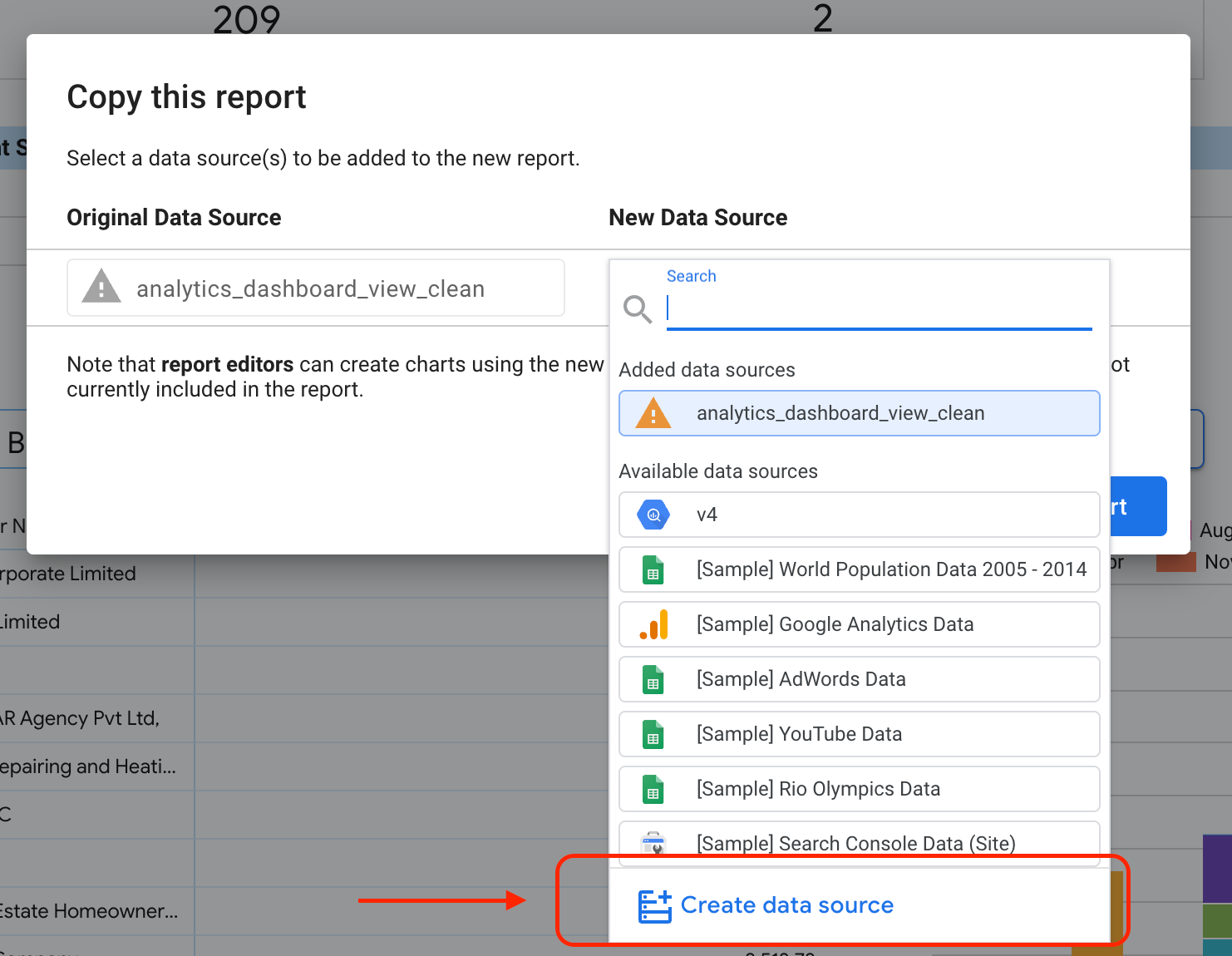
在“新数据源”子部分下,选择创建数据源 。
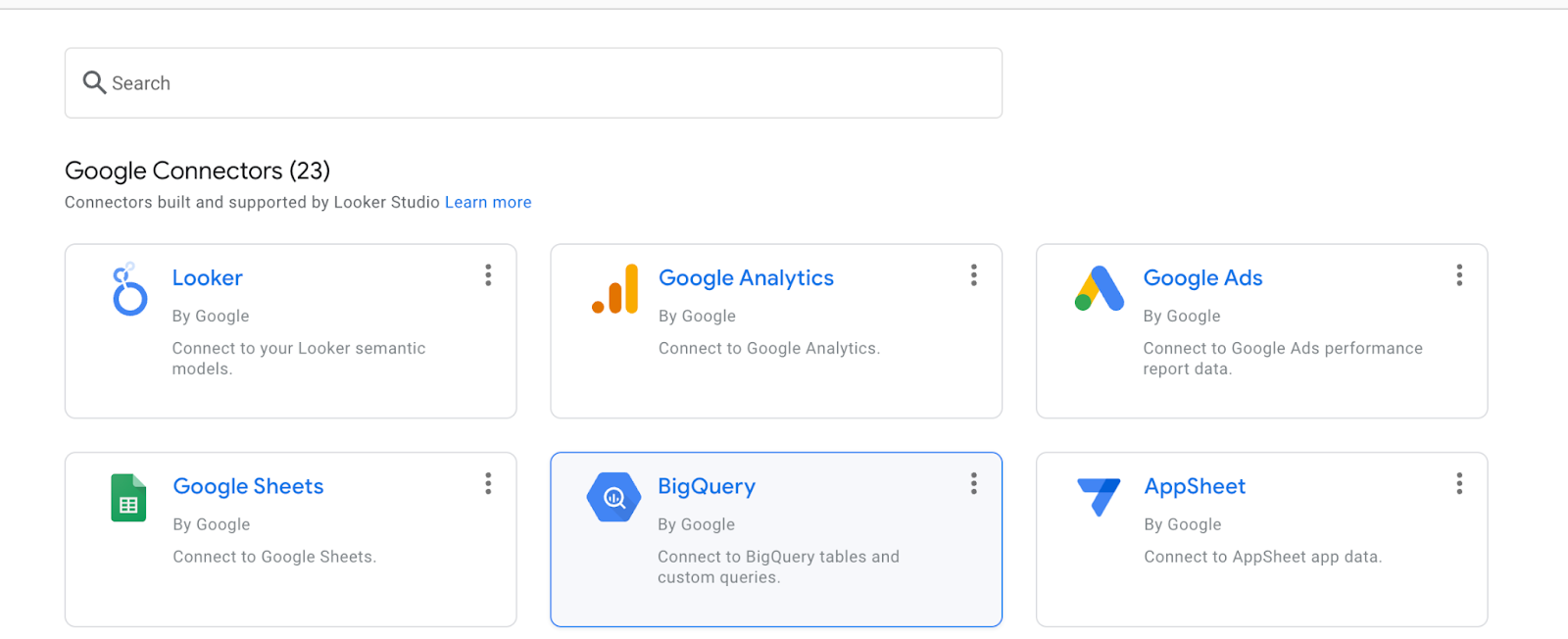
选择 BigQuery 。
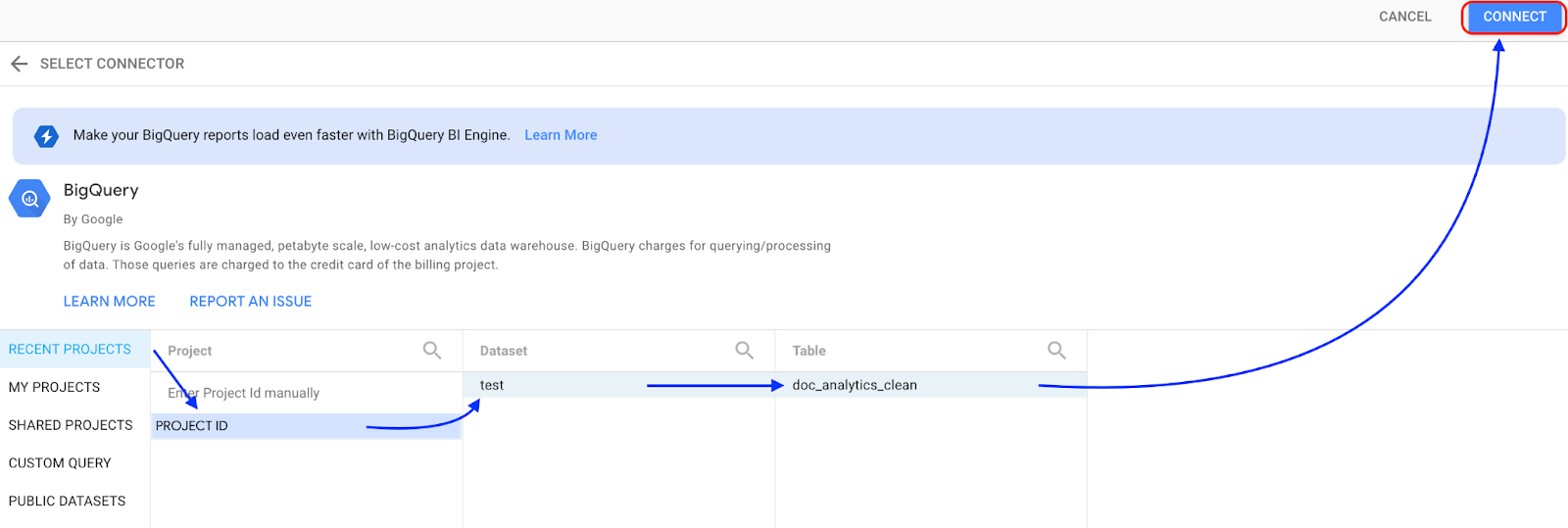
选择存储数据集的项目,然后按照提示选择数据集和表。点击连接 。

点击添加到报告 。
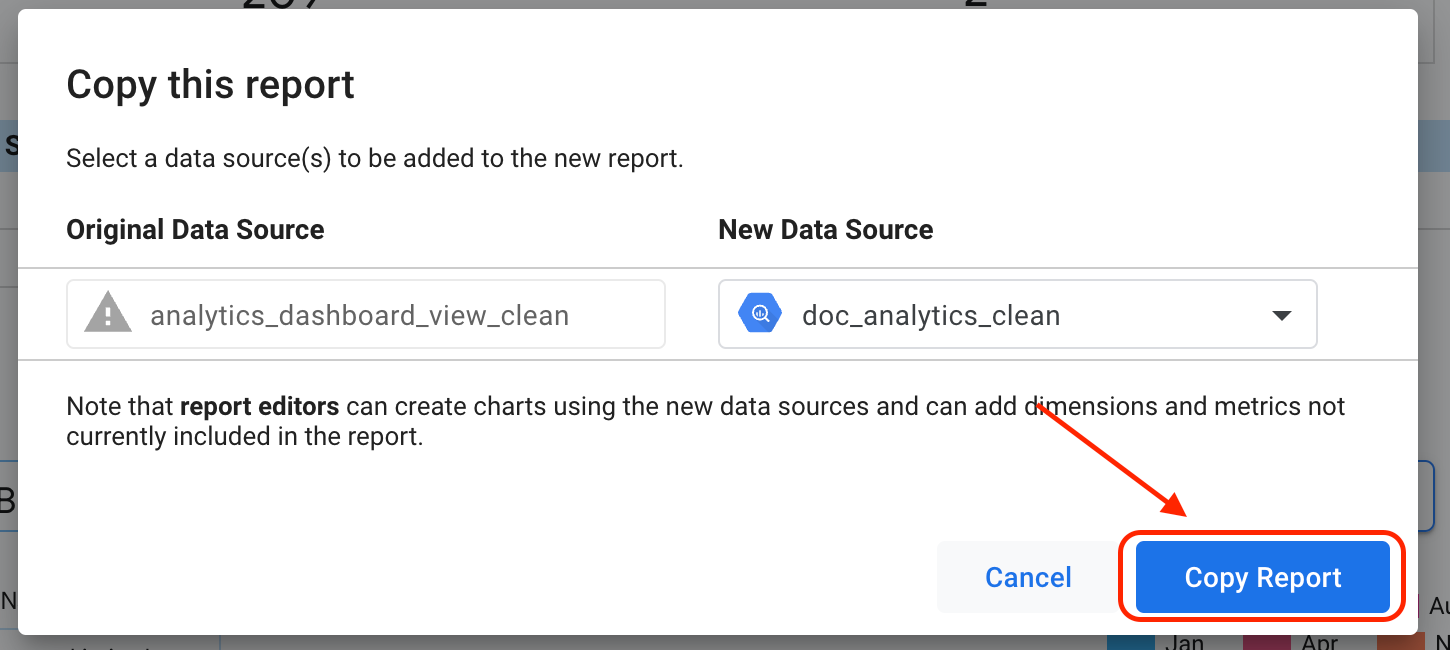
点击复制报告 。
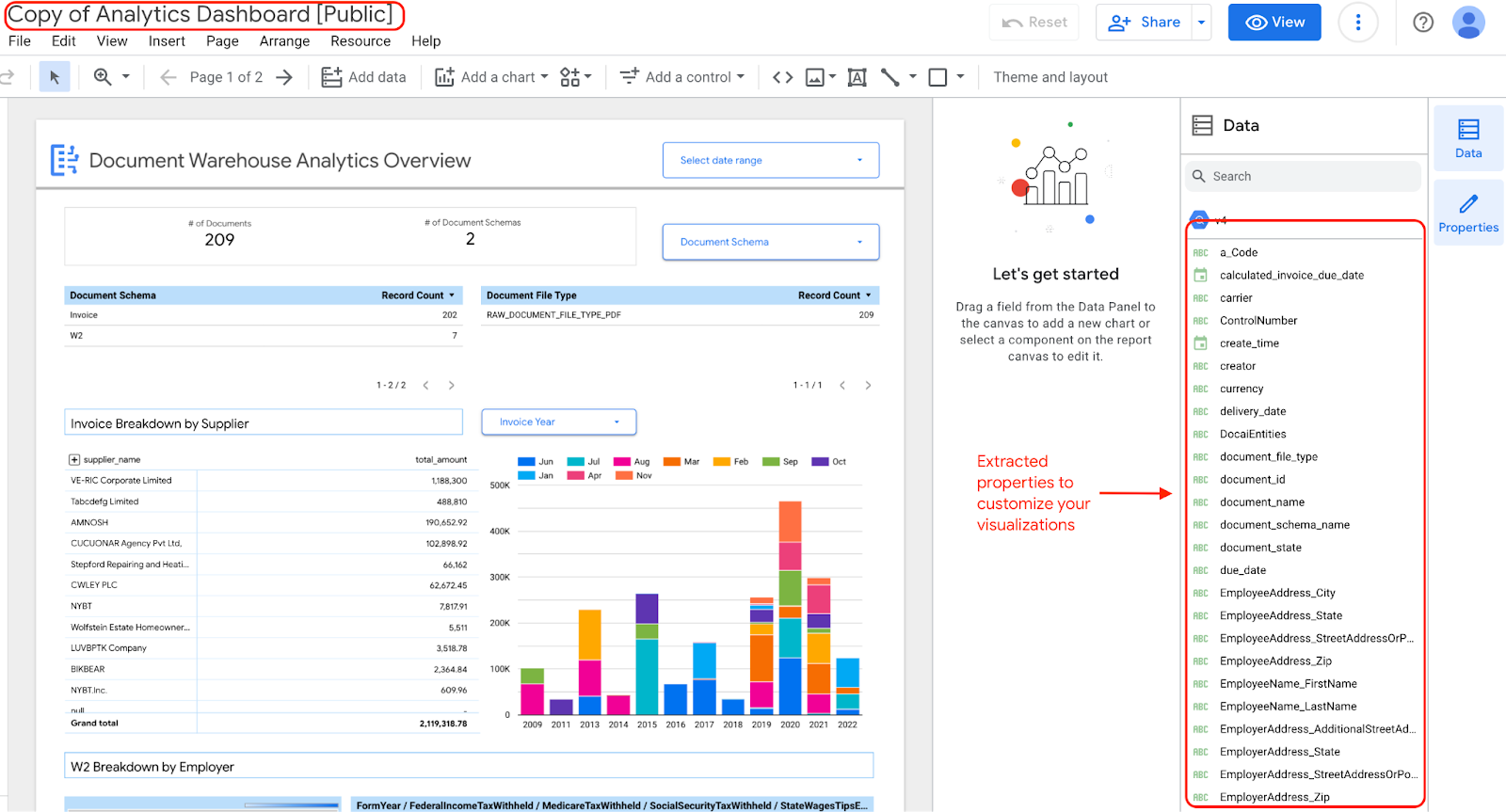
如果您选择修改和更新信息中心内的微件,则可以对其进行修改,因为您拥有包含提取的属性的信息中心副本。