
Datastream admite el streaming de datos de bases de datos de Oracle, MySQL y PostgreSQL directamente en conjuntos de datos de BigQuery. Sin embargo, si necesitas más control sobre la lógica de procesamiento de la secuencia, como la transformación de datos o la configuración manual de claves primarias lógicas, puedes integrar Datastream con plantillas de trabajos de Dataflow.
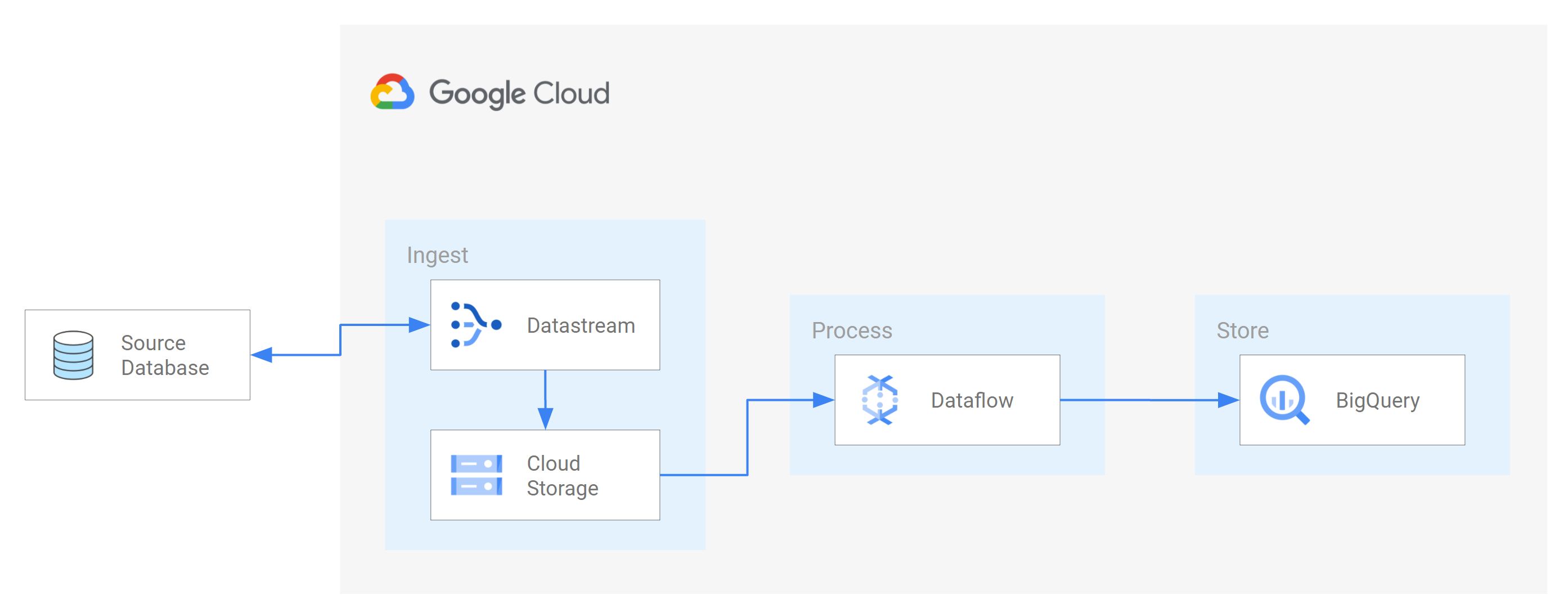
En este tutorial se muestra cómo se integra Datastream con Dataflow mediante el uso de plantillas de tareas de Dataflow para transmitir vistas materializadas actualizadas en BigQuery con fines analíticos.
En las organizaciones con muchas fuentes de datos aisladas, el acceso a los datos empresariales en toda la organización, especialmente en tiempo real, puede ser limitado y lento. Esto restringe la capacidad de la organización para introspeccionar.
Datastream proporciona acceso casi en tiempo real a los datos de cambios de varias fuentes de datos on-premise y basadas en la nube. Datastream ofrece una experiencia de configuración en la que no tiene que hacer mucho para transmitir datos, ya que Datastream lo hace por usted. Datastream también tiene una API de consumo unificada que democratiza el acceso de tu organización a los datos empresariales más recientes disponibles para crear escenarios integrados.
Un ejemplo de este tipo de situación es la transferencia de datos de una base de datos de origen a un servicio de almacenamiento o una cola de mensajes basados en la nube. Una vez que Datastream ha enviado los datos, estos se transforman en un formato que pueden leer otras aplicaciones y servicios. En este tutorial, Dataflow es el servicio web que se comunica con el servicio de almacenamiento o la cola de mensajes para capturar y procesar datos en Google Cloud.
Aprenderás a usar Datastream para transmitir cambios (datos insertados, actualizados o eliminados) de una base de datos MySQL de origen a una carpeta de un segmento de Cloud Storage. A continuación, configura el segmento de Cloud Storage para que envíe notificaciones que Dataflow usa para obtener información sobre los archivos nuevos que contengan los cambios en los datos que Datastream transmite desde la base de datos de origen. A continuación, una tarea de Dataflow procesa los archivos y transfiere los cambios a BigQuery.
Requisitos
Datastream ofrece varias opciones de origen, opciones de destino y métodos de conectividad de red.
En este tutorial, damos por hecho que usas una base de datos MySQL independiente y un servicio de Cloud Storage de destino. En la base de datos de origen, deberías poder configurar tu red para añadir una regla de cortafuegos entrante. La base de datos de origen puede estar en un entorno local o en un proveedor de servicios en la nube. En el caso del destino de Cloud Storage, no es necesario configurar la conectividad.
Como no conocemos los detalles de tu entorno, no podemos proporcionarte pasos detallados para configurar tu red.
En este tutorial, seleccionará Lista de permitidos de IPs como método de conectividad de red. La lista de permitidos de IPs es una función de seguridad que se suele usar para limitar y controlar el acceso a los datos de tu base de datos de origen a usuarios de confianza. Puedes usar listas de IPs permitidas para crear listas de direcciones IP o intervalos de IPs de confianza desde los que tus usuarios y otros Google Cloud servicios, como Datastream, pueden acceder a estos datos. Para usar listas de IP permitidas, debe abrir la base de datos de origen o el cortafuegos a las conexiones entrantes de Datastream.
Crear un segmento en Cloud Storage
Crea un segmento de destino en Cloud Storage en el que Datastream transmita esquemas, tablas y datos de una base de datos MySQL de origen.
En la Google Cloud consola, ve a la página Navegador de Cloud Storage.
Haz clic en Crear segmento. Se muestra la página Crear un segmento.
En el campo de texto de la sección Asigna un nombre al contenedor, introduce un nombre único para el contenedor y, a continuación, haz clic en Continuar.
Acepta la configuración predeterminada de cada una de las regiones restantes de la página. Al final de cada región, haz clic en Continuar.
Haz clic en Crear.
Habilita las notificaciones de Pub/Sub para el segmento de Cloud Storage
En esta sección, habilitarás las notificaciones de Pub/Sub para el segmento de Cloud Storage que has creado. De esta forma, configura el segmento para que notifique a Dataflow los archivos nuevos que Datastream escriba en él. Estos archivos contienen cambios en los datos que Datastream transmite desde una base de datos MySQL de origen al bucket.
Accede al segmento de Cloud Storage que has creado. Aparecerá la página Detalles del segmento.
Haz clic en Activar Cloud Shell.
En el mensaje, introduce el siguiente comando:
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/Opcional: Si aparece una ventana Autorizar Cloud Shell, haz clic en Autorizar.
Comprueba que veas las siguientes líneas de código:
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
En la Google Cloud consola, ve a la página Temas de Pub/Sub.
Haz clic en el tema my_integration_notifs que has creado.
En la página my_integration_notifs, ve a la parte inferior. Comprueba que la pestaña Suscripciones esté activa y que aparezca el mensaje No hay suscripciones que mostrar.
Haz clic en Crear suscripción.
En el menú que aparece, selecciona Crear suscripción.
En la página Añadir una suscripción al tema, haz lo siguiente:
- En el campo Subscription ID (ID de suscripción), introduce
my_integration_notifs_sub. - Asigna el valor
120segundos al campo Plazo límite de confirmación. De esta forma, Dataflow tiene tiempo suficiente para confirmar los archivos que ha procesado y se mejora el rendimiento general del trabajo de Dataflow. Para obtener más información sobre las propiedades de las suscripciones a Pub/Sub, consulta Propiedades de las suscripciones. - Deja el resto de los valores predeterminados de la página.
- Haz clic en Crear.
- En el campo Subscription ID (ID de suscripción), introduce
Más adelante en este tutorial, crearás una tarea de Dataflow. Como parte de la creación de esta tarea, asignas Dataflow como suscriptor de la suscripción my_integration_notifs_sub. De esta forma, Dataflow puede recibir notificaciones sobre los archivos nuevos que Datastream escribe en Cloud Storage, procesar los archivos y transferir los cambios de datos a BigQuery.
Crear conjuntos de datos en BigQuery
En esta sección, creará conjuntos de datos en BigQuery. BigQuery usa conjuntos de datos para contener los datos que recibe de Dataflow. Estos datos representan los cambios en la base de datos MySQL de origen que Datastream transmite a tu segmento de Cloud Storage.
Ve a la página Espacio de trabajo de SQL de BigQuery en la Google Cloud consola.
En el panel Explorador, junto al nombre de tu proyecto Google Cloud , haz clic en Ver acciones.
En el menú que aparece, selecciona Crear conjunto de datos.
En la ventana Crear conjunto de datos, haz lo siguiente:
- En el campo ID del conjunto de datos, introduzca el ID del conjunto de datos. En este tutorial, escribe
My_integration_dataset_logen el campo. - Deja el resto de los valores predeterminados de la ventana.
- Haz clic en Crear conjunto de datos.
- En el campo ID del conjunto de datos, introduzca el ID del conjunto de datos. En este tutorial, escribe
En el panel Explorador, junto al nombre de tu Google Cloud proyecto, haz clic en Expandir nodo y, a continuación, comprueba que aparece el conjunto de datos que has creado.
Sigue los pasos de este procedimiento para crear un segundo conjunto de datos: My_integration_dataset_final.
Junto a cada conjunto de datos, despliega Desplegar nodo.
Verifica que cada conjunto de datos esté vacío.
Una vez que Datastream transmite los cambios de datos de la base de datos de origen a tu segmento de Cloud Storage, una tarea de Dataflow procesa los archivos que contienen los cambios y los transfiere a los conjuntos de datos de BigQuery.
Crear perfiles de conexión en Datastream
En esta sección, creará perfiles de conexión en Datastream para una base de datos de origen y un destino. Al crear los perfiles de conexión, selecciona MySQL como tipo de perfil de conexión de origen y Cloud Storage como tipo de perfil de conexión de destino.
Datastream usa la información definida en los perfiles de conexión para conectarse tanto al origen como al destino, de forma que pueda transmitir datos desde la base de datos de origen al segmento de destino en Cloud Storage.
Crear un perfil de conexión de origen para tu base de datos MySQL
En la Google Cloud consola, ve a la página Perfiles de conexión de Datastream.
Haz clic en Create profile (Crear perfil).
Para crear un perfil de conexión de origen para tu base de datos MySQL, en la página Crear un perfil de conexión, haz clic en el tipo de perfil MySQL.
En la sección Define connection settings (Definir ajustes de conexión) de la página Create MySQL profile (Crear perfil de MySQL), proporciona la siguiente información:
- En el campo Nombre de perfil de conexión, introduce
My Source Connection Profile. - Conserva el ID de perfil de conexión generado automáticamente.
Selecciona la región en la que quieras almacenar el perfil de conexión.
Introduce los detalles de la conexión:
- En el campo Nombre de host o IP, introduce un nombre de host o una dirección IP pública que Datastream pueda usar para conectarse a la base de datos de origen. Proporcionas una dirección IP pública porque usas la lista de IPs permitidas como método de conectividad de red en este tutorial.
- En el campo Port (Puerto), introduce el número de puerto reservado para la base de datos de origen. En el caso de una base de datos MySQL, el puerto predeterminado suele ser
3306. - Introduce un nombre de usuario y una contraseña para autenticarte en tu base de datos de origen.
- En el campo Nombre de perfil de conexión, introduce
En la sección Define connection settings (Definir ajustes de conexión), haz clic en Continue (Continuar). La sección Protege la conexión a tu origen de la página Crear perfil de MySQL está activa.
En el menú Tipo de cifrado, selecciona Ninguno. Para obtener más información sobre este menú, consulta Crear un perfil de conexión para una base de datos MySQL.
En la sección Protege la conexión a tu fuente, haz clic en Continuar. La sección Definir método de conectividad de la página Crear perfil de MySQL está activa.
En el menú desplegable Método de conectividad, elija el método de red que quiera usar para establecer la conectividad entre Datastream y la base de datos de origen. En este tutorial, seleccione Lista de permitidos de IPs como método de conectividad.
Configura tu base de datos de origen para que permita las conexiones entrantes de las direcciones IP públicas de Datastream que aparecen.
En la sección Definir método de conectividad, haz clic en Continuar. La sección Probar perfil de conexión de la página Crear perfil de MySQL está activa.
Haz clic en Ejecutar prueba para verificar que la base de datos de origen y Datastream pueden comunicarse entre sí.
Comprueba que se muestre el estado Prueba superada.
Haz clic en Crear.
Crear un perfil de conexión de destino para Cloud Storage
En la Google Cloud consola, ve a la página Perfiles de conexión de Datastream.
Haz clic en Create profile (Crear perfil).
Para crear un perfil de conexión de destino de Cloud Storage, en la página Crear un perfil de conexión, haga clic en el tipo de perfil Cloud Storage.
En la página Crear perfil de Cloud Storage, proporciona la siguiente información:
- En el campo Nombre de perfil de conexión, introduce
My Destination Connection Profile. - Conserva el ID de perfil de conexión generado automáticamente.
- Selecciona la región en la que quieras almacenar el perfil de conexión.
En el panel Detalles de la conexión, haz clic en Examinar para seleccionar el segmento de Cloud Storage que has creado anteriormente en este tutorial. Es el contenedor al que Datastream transfiere datos desde la base de datos de origen. Cuando hayas seleccionado la opción que quieras, haz clic en Seleccionar.
Tu segmento aparecerá en el campo Nombre del segmento del panel Detalles de la conexión.
En el campo Prefijo de la ruta del perfil de conexión, proporcione un prefijo para la ruta que quiera añadir al nombre del segmento cuando Datastream transmita datos al destino. Asegúrate de que Datastream escriba los datos en una ruta dentro del segmento, no en la carpeta raíz del segmento. En este tutorial, usa la ruta que definiste al configurar la notificación de Pub/Sub. Introduce
/integration/tutorialen el campo.
- En el campo Nombre de perfil de conexión, introduce
Haz clic en Crear.
Después de crear un perfil de conexión de origen para tu base de datos MySQL y un perfil de conexión de destino para Cloud Storage, puedes usarlos para crear un flujo.
Crear un flujo en Datastream
En esta sección, crearás un flujo. Este flujo usa la información de los perfiles de conexión para transferir datos de una base de datos MySQL de origen a un segmento de destino en Cloud Storage.
Definir los ajustes de la emisión
En la Google Cloud consola, ve a la página Streams (Streams) de Datastream.
Haz clic en Crear novedad.
Proporciona la siguiente información en el panel Define stream details (Definir detalles del flujo) de la página Create stream (Crear flujo):
- En el campo Nombre del flujo, introduzca
My Stream. - Conserva el ID de flujo autogenerado.
- En el menú Región, selecciona la región en la que has creado los perfiles de conexión de origen y destino.
- En el menú Tipo de fuente, selecciona el tipo de perfil MySQL.
- En el menú Tipo de destino, seleccione el tipo de perfil Cloud Storage.
- En el campo Nombre del flujo, introduzca
Revisa los requisitos previos que se generan automáticamente para saber cómo debes preparar tu entorno para un flujo. Entre estos requisitos previos se incluye cómo configurar la base de datos de origen y cómo conectar Datastream al segmento de destino en Cloud Storage.
Haz clic en Continuar. Aparecerá el panel Definir perfil de conexión de MySQL de la página Crear flujo.
Especificar información sobre el perfil de conexión de origen
En esta sección, debe seleccionar el perfil de conexión que ha creado para su base de datos de origen (el perfil de conexión de origen). En este tutorial, es Mi perfil de conexión de origen.
En el menú Perfil de conexión de origen, selecciona el perfil de conexión de origen de la base de datos MySQL.
Haz clic en Ejecutar prueba para verificar que la base de datos de origen y Datastream pueden comunicarse entre sí.
Si la prueba falla, aparecerá el problema asociado al perfil de conexión. Consulte los pasos para solucionar problemas en la página Diagnosticar problemas. Haga los cambios necesarios para corregir el problema y, a continuación, vuelva a hacer la prueba.
Haz clic en Continuar. Aparecerá el panel Configurar origen del flujo de la página Crear flujo.
Configurar la información sobre la base de datos de origen del flujo
En esta sección, se configura la información sobre la base de datos de origen del flujo especificando las tablas y los esquemas de la base de datos de origen que Datastream:
- Puede transferir al destino.
- No se puede transferir al destino.
También puede determinar si Datastream rellena el historial de datos y si transmite los cambios continuos al destino o solo los cambios en los datos.
Usa el menú Objetos que incluir para especificar las tablas y los esquemas de la base de datos de origen que Datastream puede transferir a una carpeta del segmento de destino en Cloud Storage. El menú solo se carga si tu base de datos tiene hasta 5000 objetos.
En este tutorial, queremos que Datastream transfiera todas las tablas y esquemas. Por lo tanto, seleccione Todas las tablas de todos los esquemas en el menú.
Comprueba que el panel Seleccionar objetos que excluir esté configurado como Ninguno. No quieres impedir que Datastream transfiera ninguna tabla ni esquema de tu base de datos de origen a Cloud Storage.
Compruebe que el panel Elegir modo de relleno para datos históricos esté configurado como Automático. Datastream transmite todos los datos disponibles, además de los cambios en los datos, del origen al destino.
Haz clic en Continuar. Aparecerá el panel Definir perfil de conexión de Cloud Storage de la página Crear flujo.
Selecciona un perfil de conexión de destino
En esta sección, selecciona el perfil de conexión que has creado para Cloud Storage (el perfil de conexión de destino). En este tutorial, se llama My Destination Connection Profile (Mi perfil de conexión de destino).
En el menú Perfil de conexión de destino, selecciona el perfil de conexión de destino de Cloud Storage.
Haz clic en Continuar. Aparecerá el panel Configurar destino del flujo de la página Crear flujo.
Configurar la información sobre el destino del flujo
En esta sección, se configura la información sobre el contenedor de destino del flujo. Entre la información obtenida de esta forma, se incluyen los siguientes datos:
- El formato de salida de los archivos que se escriben en Cloud Storage.
- Carpeta del bucket de destino en la que Datastream transfiere esquemas, tablas y datos de la base de datos de origen.
En el campo Formato de salida, selecciona el formato de los archivos que se escriben en Cloud Storage. Datastream admite dos formatos de salida: Avro y JSON. En este tutorial, el formato de archivo es Avro.
Haz clic en Continuar. Aparecerá el panel Revisar detalles del flujo y crearlo de la página Crear flujo.
Crear el flujo
Verifica los detalles del flujo, así como los perfiles de conexión de origen y destino que utiliza el flujo para transferir datos de una base de datos MySQL de origen a un segmento de destino en Cloud Storage.
Para validar el flujo, haz clic en Ejecutar validación. Al validar un flujo, Datastream comprueba que la fuente esté configurada correctamente, valida que el flujo pueda conectarse tanto a la fuente como al destino y verifica la configuración integral del flujo.
Una vez que se hayan superado todas las comprobaciones de validación, haz clic en Crear.
En el cuadro de diálogo ¿Crear flujo?, haz clic en Crear.
Iniciar la emisión
En este tutorial, creará e iniciará un flujo por separado por si el proceso de creación del flujo supone una mayor carga en la base de datos de origen. Para evitar esa carga, crea el flujo sin iniciarlo y, a continuación, inicia el flujo cuando tu base de datos pueda gestionar la carga.
Al iniciar el flujo, Datastream puede transferir datos, esquemas y tablas de la base de datos de origen al destino.
En la Google Cloud consola, ve a la página Streams (Streams) de Datastream.
Seleccione la casilla situada junto al stream que quiera iniciar. En este tutorial, se llama Mi stream.
Haz clic en Empezar.
En el cuadro de diálogo, haz clic en Iniciar. El estado de la emisión cambia de
Not startedaStartingy, después, aRunning.
Después de iniciar un flujo, puede verificar que Datastream ha transferido datos de la base de datos de origen al destino.
Verificar la emisión
En esta sección, confirmará que Datastream transfiere los datos de todas las tablas de una base de datos MySQL de origen a la carpeta /integration/tutorial de su segmento de destino de Cloud Storage.
En la Google Cloud consola, ve a la página Streams (Streams) de Datastream.
Haz clic en el flujo que has creado. En este tutorial, se llama Mi stream.
En la página Detalles del flujo, haga clic en el enlace bucket-name/integration/tutorial, donde bucket-name es el nombre que ha asignado al segmento de Cloud Storage. Este enlace aparece después del campo Ruta de escritura de destino. La página Detalles del segmento de Cloud Storage se abre en otra pestaña.
Comprueba que veas carpetas que representen las tablas de la base de datos de origen.
Haz clic en una de las carpetas de la tabla y, a continuación, en cada subcarpeta hasta que veas los datos asociados a la tabla.
Crear una tarea de Dataflow
En esta sección, crearás un trabajo en Dataflow. Una vez que Datastream transmite los cambios de datos de una base de datos MySQL de origen a tu segmento de Cloud Storage, Pub/Sub envía notificaciones a Dataflow sobre los nuevos archivos que contienen los cambios. La tarea de Dataflow procesa los archivos y transfiere los cambios a BigQuery.
En la Google Cloud consola, ve a la página Trabajos de Dataflow.
Haz clic en Crear tarea a partir de plantilla.
En el campo Nombre de la tarea de la página Crear tarea a partir de plantilla, introduce un nombre para la tarea de Dataflow que vas a crear. En este tutorial, escribe
my-dataflow-integration-joben el campo.En el menú Endpoint regional, selecciona la región en la que quieras almacenar el trabajo. Es la misma región que seleccionaste para el perfil de conexión de origen, el perfil de conexión de destino y el flujo que creaste.
En el menú Plantilla de Dataflow, selecciona la plantilla que estés usando para crear el trabajo. En este tutorial, selecciona Datastream a BigQuery.
Después de hacer esta selección, aparecerán campos adicionales relacionados con esta plantilla.
En el campo Ubicación del archivo de salida de Datastream en Cloud Storage, introduzca el nombre del segmento de Cloud Storage con el siguiente formato:
gs://bucket-name.En el campo Suscripción de Pub/Sub que se usa en una política de notificaciones de Cloud Storage, introduce la ruta que contiene el nombre de tu suscripción de Pub/Sub. En este tutorial, escribe
projects/project-name/subscriptions/my_integration_notifs_sub.En el campo Formato de archivo de salida de Datastream (avro/json), introduce
avroporque, en este tutorial, Avro es el formato de archivo que Datastream escribe en Cloud Storage.En el campo Nombre o plantilla del conjunto de datos que contendrá las tablas de almacenamiento temporal, introduce
My_integration_dataset_log, ya que Dataflow usa este conjunto de datos para almacenar temporalmente los cambios de datos que recibe de Datastream.En el campo Template for the dataset to contain replica tables (Plantilla del conjunto de datos que contendrá las tablas de réplica), introduce
My_integration_dataset_final, ya que es el conjunto de datos en el que se combinan los cambios almacenados en el conjunto de datos My_integration_dataset_log para crear una réplica uno a uno de las tablas de la base de datos de origen.En el campo Directorio de la cola de mensajes fallidos, introduce la ruta que contiene el nombre de tu segmento de Cloud Storage y una carpeta para la cola de mensajes fallidos. Asegúrate de no usar una ruta en la carpeta raíz y de que la ruta sea diferente de la ruta en la que Datastream escribe los datos. Los cambios en los datos que Dataflow no pueda transferir a BigQuery se almacenarán en la cola. Puedes corregir el contenido de la cola para que Dataflow pueda volver a procesarlo.
En este tutorial, introduce
gs://bucket-name/dlqen el campo Directorio de la cola de mensajes fallidos (donde bucket-name es el nombre de tu contenedor y dlq es la carpeta de la cola de mensajes fallidos).Haz clic en Ejecutar trabajo.
Verificar la integración
En la sección Verificar el flujo de este tutorial, has confirmado que Datastream ha transferido los datos de todas las tablas de una base de datos MySQL de origen a la carpeta /integration/tutorial de tu segmento de destino de Cloud Storage.
En esta sección, verificará que Dataflow procesa los archivos que contienen los cambios asociados a estos datos y que transfiere los cambios a BigQuery. De esta forma, tendrá una integración integral entre Datastream y BigQuery.
En la Google Cloud consola, ve a la página Espacio de trabajo de SQL de BigQuery.
En el panel Explorador, despliega el nodo situado junto al nombre de tu Google Cloud proyecto.
Despliega los nodos situados junto a los conjuntos de datos My_integration_dataset_log y My_integration_dataset_final.
Verifica que cada conjunto de datos contenga datos. De esta forma, se confirma que Dataflow ha procesado los archivos que contienen los cambios asociados a los datos que Datastream ha transmitido a Cloud Storage y que ha transferido estos cambios a BigQuery.