
Datastream תומך בהזרמת נתונים ממסדי נתונים של Oracle, MySQL ו-PostgreSQL ישירות למערכי נתונים של BigQuery. עם זאת, אם אתם צריכים יותר שליטה בלוגיקה של עיבוד זרמי נתונים (stream processing), כמו טרנספורמציה של נתונים או הגדרה ידנית של מפתחות ראשיים לוגיים, אתם יכולים לשלב את Datastream עם תבניות של משימות Dataflow.
במדריך הזה נסביר איך לשלב את Datastream עם Dataflow באמצעות תבניות של משימות Dataflow כדי להזרים תצוגות חומריות עדכניות ב-BigQuery לצורך ניתוח.
בארגונים עם הרבה מקורות נתונים מבודדים, הגישה לנתונים ארגוניים בכל הארגון, במיוחד בזמן אמת, יכולה להיות מוגבלת ואיטית. כך מוגבלת היכולת של הארגון לבצע בדיקה עצמית.
Datastream מספק גישה כמעט בזמן אמת לנתוני שינויים ממגוון מקורות נתונים מקומיים ומבוססי-ענן. ב-Datastream יש תהליך הגדרה שבו לא צריך לבצע הרבה הגדרות כדי להזרים נתונים. Datastream עושה את זה בשבילכם. בנוסף, ל-Datastream יש API מאוחד לצריכת נתונים, שמאפשר לארגון שלכם גישה לנתונים העדכניים ביותר שזמינים לשימוש ארגוני, כדי ליצור תרחישים משולבים.
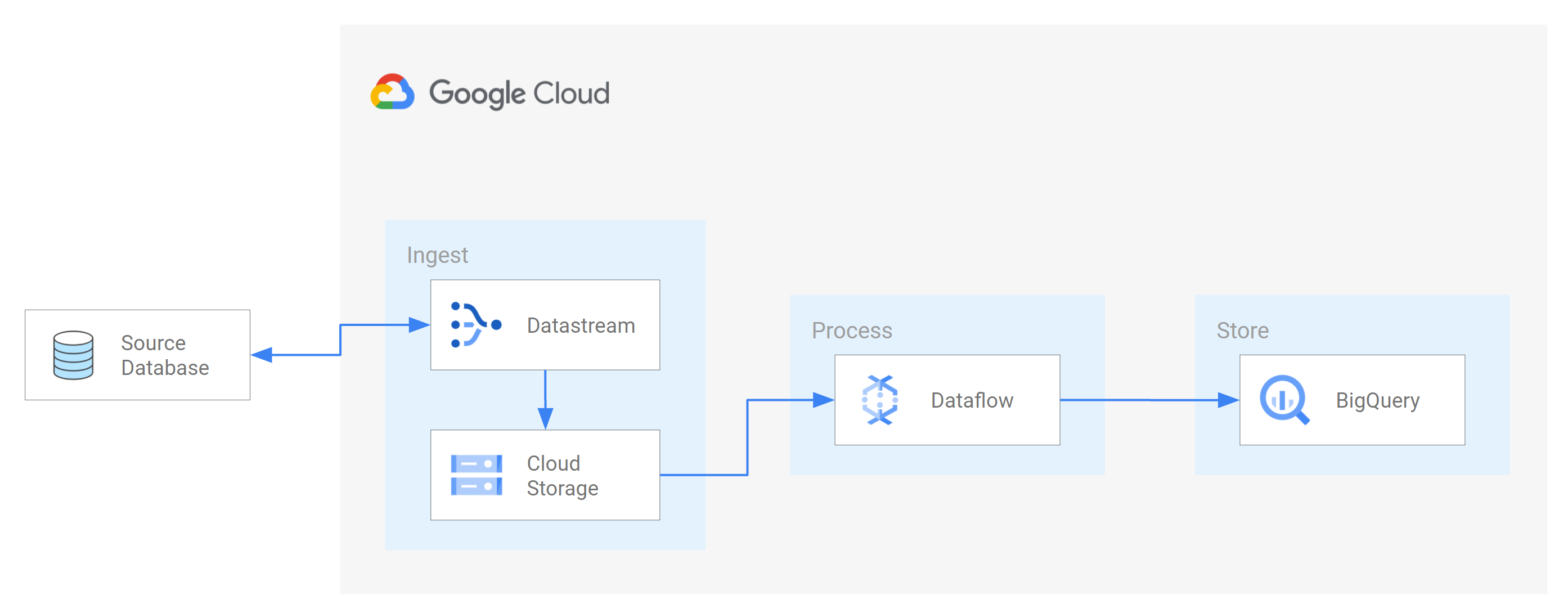
תרחיש כזה הוא העברת נתונים ממסד נתונים של מקור אל שירות אחסון או תור הודעות מבוסס-ענן. אחרי ש-Datastream מזרימה את הנתונים, הם עוברים המרה לפורמט שאפליקציות ושירותים אחרים יכולים לקרוא. במדריך הזה, Dataflow הוא שירות האינטרנט שמתקשר עם שירות האחסון או עם תור ההודעות כדי ללכוד ולעבד נתונים ב- Google Cloud.
במאמר הזה נסביר איך להשתמש ב-Datastream כדי להזרים שינויים (נתונים שנוספו, עודכנו או נמחקו) ממסד נתונים של MySQL אל תיקייה בקטגוריה של Cloud Storage. לאחר מכן, מגדירים את קטגוריית Cloud Storage לשליחת התראות ש-Dataflow משתמש בהן כדי לקבל מידע על קבצים חדשים שמכילים את שינויי הנתונים ש-Datastream מזרימה ממסד הנתונים של המקור. לאחר מכן, משימת Dataflow מעבדת את הקבצים ומעבירה את השינויים ל-BigQuery.
מטרות
במדריך הזה תלמדו:- יוצרים קטגוריה ב-Cloud Storage. זהו באקט היעד שאליו Datastream מעביר סכימות, טבלאות ונתונים ממסד נתונים של MySQL.
- מפעילים התראות Pub/Sub לקטגוריה של Cloud Storage. כך מגדירים את ה-bucket לשליחת התראות ש-Dataflow משתמש בהן כדי ללמוד על קבצים חדשים שמוכנים לעיבוד. הקבצים האלה מכילים שינויים בנתונים ש-Datastream מעביר ממאגר הנתונים של המקור אל הדלי.
- יוצרים מערכי נתונים ב-BigQuery. ב-BigQuery נעשה שימוש במערכי נתונים כדי להכיל את הנתונים שמתקבלים מ-Dataflow. הנתונים האלה מייצגים את השינויים במסד הנתונים של המקור ש-Datastream מעביר בסטרימינג לקטגוריה של Cloud Storage.
- יצירה וניהול של פרופילי חיבור למסד נתונים של מקור ולקטגוריית יעד ב-Cloud Storage. מקור נתונים ב-Datastream משתמש במידע שבפרופילים של החיבור כדי להעביר נתונים ממסד הנתונים של המקור אל הדלי.
- יוצרים שידור סטרימינג ומתחילים אותו. הזרם הזה מעביר נתונים, סכימות וטבלאות ממסד הנתונים של המקור אל הדלי.
- מוודאים ש-Datastream מעביר את הנתונים והטבלאות שמשויכים לסכימה של מסד הנתונים של המקור אל הדלי.
- יוצרים משימה ב-Dataflow. אחרי ש-Datastream מעביר בסטרימינג שינויים בנתונים ממסד הנתונים של המקור לקטגוריה של Cloud Storage, נשלחות ל-Dataflow התראות על קבצים חדשים שמכילים את השינויים. העבודה של Dataflow מעבדת את הקבצים ומעבירה את השינויים ל-BigQuery.
- מוודאים ש-Dataflow מעבד את הקבצים שמכילים שינויים שמשויכים לנתונים האלה, ומעביר את השינויים אל BigQuery. כתוצאה מכך, יש לכם שילוב מקצה לקצה בין Datastream ל-BigQuery.
- חשוב להסיר את המשאבים שיצרתם ב-Datastream, ב-Cloud Storage, ב-Pub/Sub, ב-Dataflow וב-BigQuery כדי שלא יתפסו מכסת אחסון ולא תחויבו עליהם בעתיד.
עלויות
במסמך הזה משתמשים ברכיבים הבאים של Google Cloud, והשימוש בהם כרוך בתשלום:
- Datastream
- Cloud Storage
- Pub/Sub
- Dataflow
- BigQuery
כדי להעריך את ההוצאות בהתאם לתחזית השימוש שלכם, אתם יכולים להיעזר במחשבון העלויות.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- מפעילים את Datastream API.
- מוודאים שלחשבון המשתמש שלכם הוקצה תפקיד אדמין ב-Datastream.
- מוודאים שיש לכם מסד נתונים של MySQL כמקור ש-Datastream יכול לגשת אליו. בנוסף, צריך לוודא שיש לכם נתונים, טבלאות וסכימות במסד הנתונים.
- מגדירים את מסד הנתונים של MySQL כך שיאפשר חיבורים נכנסים מכתובות IP ציבוריות של Datastream. רשימה של כל האזורים של Datastream וכתובות ה-IP הציבוריות המשויכות אליהם מופיעה במאמר בנושא רשימות היתרים של כתובות IP ואזורים.
- מגדירים את התכונה 'לכידת נתונים לשינוי' (CDC) עבור מסד הנתונים של המקור. מידע נוסף זמין במאמר בנושא הגדרת מסד נתונים של MySQL כמקור.
מוודאים שאתם עומדים בכל הדרישות המוקדמות להפעלת התראות Pub/Sub ל-Cloud Storage.
במדריך הזה, יוצרים קטגוריית יעד ב-Cloud Storage ומפעילים התראות Pub/Sub לקטגוריה. כך, Dataflow יכול לקבל התראות על קבצים חדשים ש-Datastream כותב ל-bucket. הקבצים האלה מכילים שינויים בנתונים ש-Datastream מעביר ממאגר הנתונים של המקור אל הדלי.
דרישות
Datastream מציע מגוון אפשרויות למקורות, אפשרויות ליעדים ושיטות לחיבור לרשת.
במדריך הזה אנחנו מניחים שאתם משתמשים במסד נתונים עצמאי של MySQL ובשירות יעד של Cloud Storage. במסד הנתונים של המקור, צריכה להיות לכם אפשרות להגדיר את הרשת כדי להוסיף כלל חומת אש לתעבורה נכנסת. מסד הנתונים של המקור יכול להיות מקומי או אצל ספק שירותי ענן. במקרה של יעד Cloud Storage, לא נדרשת הגדרת קישוריות.
מכיוון שאין לנו דרך לדעת את הפרטים הספציפיים של הסביבה שלכם, אנחנו לא יכולים לספק שלבים מפורטים לגבי הגדרת הרשת.
במדריך הזה, בוחרים באפשרות IP allowlisting (הוספה לרשימת ההיתרים של כתובות IP) כשיטה לקישוריות לרשת. רשימת כתובות IP מורשות היא תכונת אבטחה שמשמשת לעיתים קרובות להגבלת הגישה לנתונים במסד הנתונים של המקור ולשליטה בה, כך שרק משתמשים מהימנים יוכלו לגשת אליהם. אתם יכולים להשתמש ברשימות היתרים של כתובות IP כדי ליצור רשימות של כתובות IP או טווחי כתובות IP מהימנים, שמהם המשתמשים שלכם ושירותים אחרים כמו Datastream יכולים לגשת לנתונים האלה. Google Cloud כדי להשתמש ברשימות היתרים של כתובות IP, צריך לפתוח את מסד הנתונים או את חומת האש של המקור לחיבורים נכנסים מ-Datastream.
יצירת קטגוריה ב-Cloud Storage
יוצרים קטגוריה של יעד ב-Cloud Storage שאליה Datastream מעביר סכימות, טבלאות ונתונים ממסד נתונים של MySQL.
נכנסים לדף Browser של Cloud Storage במסוף Google Cloud .
לוחצים על Create bucket. יופיע הדף Create a bucket.
בתיבת הטקסט של האזור Name your bucket, מזינים שם ייחודי לקטגוריה ולוחצים על Continue.
מאשרים את הגדרות ברירת המחדל לכל אזור שנותר בדף. בסוף כל אזור, לוחצים על המשך.
לוחצים על יצירה.
הפעלת התראות Pub/Sub לקטגוריה של Cloud Storage
בקטע הזה מפעילים התראות Pub/Sub לקטגוריה של Cloud Storage שיצרתם. כך מגדירים את הקטגוריה לשלוח ל-Dataflow הודעה על כל קובץ חדש ש-Datastream כותב לקטגוריה. הקבצים האלה מכילים שינויים בנתונים ש-Datastream מעביר בסטרימינג ממסד נתונים של MySQL אל הקטגוריה.
ניגשים לקטגוריה של Cloud Storage שיצרתם. יופיע הדף Bucket details.
לוחצים על הפעלת Cloud Shell.
בשורת הפקודה, מזינים את הפקודה הבאה:
gcloud storage buckets notifications create gs://bucket-name --topic=my_integration_notifs --payload-format=json --object-prefix=integration/tutorial/אופציונלי: אם מופיע חלון Authorize Cloud Shell, לוחצים על Authorize.
מוודאים ששורות הקוד הבאות מופיעות:
Created Cloud Pub/Sub topic projects/project-name/topics/my_integration_notifs Created notification config projects/_/buckets/bucket-name/notificationConfigs/1
נכנסים לדף Topics של Pub/Sub במסוף Google Cloud .
לוחצים על הנושא my_integration_notifs שיצרתם.
בדף my_integration_notifs, גוללים לתחתית הדף. מוודאים שהכרטיסייה מינויים פעילה ומופיעה ההודעה אין מינויים להצגה.
לוחצים על יצירת מינוי.
בתפריט שמופיע, בוחרים באפשרות יצירת מינוי.
בדף Add subscription to topic (הוספת מינוי לנושא):
- בשדה Subscription ID (מזהה המינוי), מזינים את הערך
my_integration_notifs_sub. - מגדירים את הערך של Acknowledgement deadline (מועד אחרון לאישור) ל-
120שניות. כך ל-Dataflow יש מספיק זמן לאשר את הקבצים שהוא עיבד, והביצועים הכוללים של עבודת Dataflow משתפרים. מידע נוסף על מאפייני מינוי ב-Pub/Sub זמין במאמר מאפייני מינוי. - משאירים את כל שאר ערכי ברירת המחדל בדף.
- לוחצים על יצירה.
- בשדה Subscription ID (מזהה המינוי), מזינים את הערך
בהמשך המדריך הזה תצרו משימת Dataflow. במסגרת יצירת המשימה הזו, אתם מקצים את Dataflow כמנוי למינוי my_integration_notifs_sub. כך, Dataflow יכול לקבל התראות על קבצים חדשים ש-Datastream כותב ל-Cloud Storage, לעבד את הקבצים ולהעביר את שינויי הנתונים ל-BigQuery.
יצירת מערכי נתונים ב-BigQuery
בקטע הזה, תיצרו מערכי נתונים ב-BigQuery. ב-BigQuery נעשה שימוש במערכי נתונים כדי להכיל את הנתונים שמתקבלים מ-Dataflow. הנתונים האלה מייצגים את השינויים במסד הנתונים של MySQL שמערכת Datastream מזרימה לקטגוריה של Cloud Storage.
עוברים לדף SQL workspace ב-BigQuery במסוף Google Cloud .
בחלונית Explorer, לצד שם הפרויקט, לוחצים על View actions (הצגת פעולות). Google Cloud
בתפריט שמופיע, בוחרים באפשרות יצירת מערך נתונים.
בחלון יצירת מערך נתונים:
- בשדה Dataset ID (מזהה מערך הנתונים), מזינים מזהה למערך הנתונים. במדריך הזה, מזינים
My_integration_dataset_logבשדה. - משאירים את כל שאר ערכי ברירת המחדל בחלון.
- לוחצים על יצירת מערך נתונים.
- בשדה Dataset ID (מזהה מערך הנתונים), מזינים מזהה למערך הנתונים. במדריך הזה, מזינים
בחלונית Explorer, לצד שם הפרויקט Google Cloud לוחצים על Expand node (הרחבת הצומת) ומוודאים שמערך הנתונים שיצרתם מופיע.
כדי ליצור מערך נתונים שני: My_integration_dataset_final, פועלים לפי השלבים שמתוארים בהמשך.
לצד כל קבוצת נתונים, לוחצים על סמל ההרחבה הרחבת הצומת.
מוודאים שכל מערך נתונים ריק.
אחרי ש-Datastream מעביר שינויים בנתונים ממסד הנתונים של המקור לקטגוריה של Cloud Storage, משימת Dataflow מעבדת את הקבצים שמכילים את השינויים ומעבירה את השינויים למערכי הנתונים ב-BigQuery.
יצירת פרופילים של חיבורים ב-Datastream
בקטע הזה יוצרים פרופילים של חיבורים ב-Datastream למסד נתונים של מקור וליעד. במסגרת יצירת פרופילי החיבור, בוחרים באפשרות MySQL כסוג הפרופיל של פרופיל חיבור המקור, ובאפשרות Cloud Storage כסוג הפרופיל של פרופיל חיבור היעד.
Datastream משתמש במידע שמוגדר בפרופילים של החיבור כדי להתחבר גם למקור וגם ליעד, וכך הוא יכול להזרים נתונים ממסד הנתונים של המקור אל קטגוריית היעד ב-Cloud Storage.
יצירת פרופיל של חיבור למקור עבור מסד הנתונים של MySQL
נכנסים לדף Connection profiles במסוף Google Cloud של Datastream.
לוחצים על יצירת פרופיל.
כדי ליצור פרופיל של חיבור למקור נתונים עבור מסד הנתונים של MySQL, בדף יצירת פרופיל של חיבור, לוחצים על סוג הפרופיל MySQL.
בקטע Define connection settings בדף Create MySQL profile, מספקים את הפרטים הבאים:
- בשדה שם פרופיל החיבור, מזינים את הערך
My Source Connection Profile. - משאירים את מזהה פרופיל החיבור שנוצר אוטומטית.
בוחרים את האזור שבו רוצים לאחסן את פרופיל החיבור.
מזינים את פרטי החיבור:
- בשדה שם מארח או כתובת IP, מזינים שם מארח או כתובת IP ציבורית ש-Datastream יכול להשתמש בהם כדי להתחבר למסד הנתונים של המקור. אתם מספקים כתובת IP ציבורית כי אתם משתמשים בהוספה לרשימת ההיתרים של כתובות IP כשיטה לקישוריות רשת במדריך הזה.
- בשדה יציאה, מזינים את מספר היציאה ששמור למסד הנתונים של המקור. במסד נתונים של MySQL, יציאת ברירת המחדל היא בדרך כלל
3306. - מזינים שם משתמש וסיסמה כדי לאמת את הגישה למסד הנתונים של המקור.
- בשדה שם פרופיל החיבור, מזינים את הערך
בקטע הגדרת הגדרות החיבור, לוחצים על המשך. הקטע מאבטחים את החיבור למקור בדף יצירת פרופיל MySQL פעיל.
בתפריט סוג ההצפנה, בוחרים באפשרות ללא. מידע נוסף על התפריט הזה זמין במאמר יצירת פרופיל חיבור למסד נתונים של MySQL.
בקטע הגנה על החיבור למקור, לוחצים על המשך. הקטע Define connectivity method בדף Create MySQL profile פעיל.
בתפריט הנפתח שיטת הקישוריות, בוחרים את שיטת הקישוריות שרוצים להשתמש בה כדי ליצור קישוריות בין Datastream לבין מסד הנתונים של המקור. במדריך הזה, בוחרים באפשרות IP allowlisting (הוספת כתובות IP לרשימת ההיתרים) כשיטת הקישוריות.
מגדירים את מסד הנתונים של המקור כך שיאפשר חיבורים נכנסים מכתובות ה-IP הציבוריות של Datastream שמופיעות.
בקטע Define connectivity method (הגדרת שיטת הקישוריות), לוחצים על Continue (המשך). הקטע בדיקת פרופיל החיבור בדף יצירת פרופיל MySQL פעיל.
לוחצים על Run test (הפעלת בדיקה) כדי לוודא שמאגר הנתונים של המקור ו-Datastream יכולים לתקשר זה עם זה.
מוודאים שהסטטוס הוא Test passed.
לוחצים על יצירה.
יצירת פרופיל חיבור ליעד ב-Cloud Storage
נכנסים לדף Connection profiles במסוף Google Cloud של Datastream.
לוחצים על יצירת פרופיל.
כדי ליצור פרופיל של חיבור ליעד ב-Cloud Storage, בדף Create a connection profile (יצירת פרופיל חיבור), לוחצים על סוג הפרופיל Cloud Storage (Cloud Storage).
בדף Create Cloud Storage profile (יצירת פרופיל Cloud Storage), מזינים את הפרטים הבאים:
- בשדה שם פרופיל החיבור, מזינים את הערך
My Destination Connection Profile. - משאירים את מזהה פרופיל החיבור שנוצר אוטומטית.
- בוחרים את האזור שבו רוצים לאחסן את פרופיל החיבור.
בחלונית פרטי החיבור, לוחצים על עיון כדי לבחור את קטגוריית Cloud Storage שיצרתם קודם במדריך הזה. זהו מאגר (bucket) שאליו Datastream מעביר נתונים ממסד הנתונים של המקור. אחרי שבוחרים את האפשרות הרצויה, לוחצים על בחירה.
הקטגוריה שלכם מופיעה בשדה Bucket name (שם הקטגוריה) בחלונית Connection details (פרטי החיבור).
בשדה Connection profile path prefix (תוספת לנתיב של פרופיל החיבור), מציינים תוספת לנתיב שרוצים להוסיף לשם של הקטגוריה כש-Datastream מעביר נתונים ליעד. חשוב לוודא ש-Datastream כותב נתונים לנתיב בתוך הדלי, ולא לתיקיית השורש של הדלי. במדריך הזה, משתמשים בנתיב שהגדרתם כשקבעתם את התראת Pub/Sub. מזינים
/integration/tutorialבשדה.
- בשדה שם פרופיל החיבור, מזינים את הערך
לוחצים על יצירה.
אחרי שיוצרים פרופיל חיבור למקור עבור מסד הנתונים של MySQL ופרופיל חיבור ליעד עבור Cloud Storage, אפשר להשתמש בהם כדי ליצור זרם.
יצירת מקור נתונים ב-Datastream
בקטע הזה יוצרים עדכון תוכן. הסטרימינג הזה משתמש במידע בפרופילים של החיבור כדי להעביר נתונים ממסד נתונים של MySQL כמקור לקטגוריית יעד ב-Cloud Storage.
הגדרת ההגדרות של השידור
נכנסים לדף Streams במסוף Google Cloud של Datastream.
לוחצים על יצירת עדכון תוכן.
בחלונית הגדרת פרטים של מקור נתונים בדף יצירת מקור נתונים, מזינים את הפרטים הבאים:
- בשדה שם מקור הנתונים, מזינים
My Stream. - משאירים את מזהה מקור הנתונים שנוצר אוטומטית.
- בתפריט Region (אזור), בוחרים את האזור שבו יצרתם את פרופילי החיבור של המקור והיעד.
- בתפריט סוג המקור, בוחרים את סוג הפרופיל MySQL.
- בתפריט סוג היעד, בוחרים את סוג הפרופיל Cloud Storage.
- בשדה שם מקור הנתונים, מזינים
בודקים את הדרישות המוקדמות שנוצרות באופן אוטומטי כדי להבין איך צריך להכין את הסביבה לשידור. הדרישות המוקדמות האלה יכולות לכלול את אופן ההגדרה של מסד הנתונים של המקור ואת אופן הקישור של Datastream לקטגוריית היעד ב-Cloud Storage.
לוחצים על Continue. מופיעה החלונית Define MySQL connection profile (הגדרת פרופיל חיבור ל-MySQL) בדף Create stream (יצירת מקור נתונים).
ציון מידע על פרופיל החיבור למקור
בקטע הזה, בוחרים את פרופיל החיבור שיצרתם עבור מסד הנתונים של המקור (פרופיל חיבור המקור). במדריך הזה, זהו פרופיל החיבור למקור.
בתפריט Source connection profile (פרופיל חיבור למקור), בוחרים את פרופיל החיבור למקור של מסד הנתונים MySQL.
לוחצים על Run test (הפעלת בדיקה) כדי לוודא שמאגר הנתונים של המקור ו-Datastream יכולים לתקשר זה עם זה.
אם הבדיקה נכשלת, הבעיה שמשויכת לפרופיל החיבור מופיעה. בדף הזה מפורטים שלבים לפתרון בעיות. מבצעים את השינויים הנדרשים כדי לתקן את הבעיה, ואז בודקים שוב.
לוחצים על Continue. מופיעה החלונית Configure stream source בדף Create stream.
הגדרת מידע על מסד הנתונים של המקור עבור הזרם
בקטע הזה מגדירים מידע על מסד הנתונים של המקור לנתונים של הסטרים, על ידי ציון הטבלאות והסכימות במסד הנתונים של המקור ש-Datastream:
- אפשר להעביר את המספר ליעד.
- מוגבלת מהעברה ליעד.
אתם גם קובעים אם Datastream ימלא מחדש נתונים היסטוריים, וגם ישדר שינויים שוטפים ליעד, או ישדר רק שינויים בנתונים.
בתפריט Objects to include (אובייקטים להכללה), מציינים את הטבלאות והסכימות במסד הנתונים של המקור ש-Datastream יכול להעביר לתיקייה בקטגוריית היעד ב-Cloud Storage. התפריט נטען רק אם במסד הנתונים יש עד 5,000 אובייקטים.
במדריך הזה, רוצים ש-Datastream יעביר את כל הטבלאות והסכימות. לכן, בתפריט בוחרים באפשרות All tables from all schemas (כל הטבלאות מכל הסכימות).
מוודאים שהחלונית Select objects to exclude מוגדרת לNone. אתם לא רוצים להגביל את Datastream כך שלא יעביר טבלאות וסכימות ממסד הנתונים של המקור אל Cloud Storage.
מוודאים שהאפשרות Choose backfill mode for historical data מוגדרת לAutomatic. מקור נתונים מעביר את כל הנתונים הקיימים, בנוסף לשינויים בנתונים, מהמקור ליעד.
לוחצים על Continue. מופיעה החלונית הגדרת פרופיל לחיבור Cloud Storage בדף יצירת מקור נתונים.
בחירת פרופיל חיבור ליעד
בקטע הזה בוחרים את פרופיל החיבור שיצרתם ל-Cloud Storage (פרופיל חיבור היעד). במדריך הזה, זהו פרופיל החיבור של יעד.
בתפריט פרופיל חיבור ליעד, בוחרים את פרופיל החיבור ליעד ב-Cloud Storage.
לוחצים על Continue. מופיעה החלונית Configure stream destination בדף Create stream.
הגדרת מידע על היעד של מקור הנתונים
בקטע הזה מגדירים את המידע על קטגוריית היעד של מקור הנתונים. המידע כולל:
- פורמט הפלט של קבצים שנכתבים ב-Cloud Storage.
- התיקייה בדלי היעד שאליה Datastream מעביר סכימות, טבלאות ונתונים ממסד הנתונים של המקור.
בשדה פורמט פלט, בוחרים את פורמט הקבצים שנכתבים ב-Cloud Storage. Datastream תומך בשני פורמטים של פלט: Avro ו-JSON. במדריך הזה, פורמט הקובץ הוא Avro.
לוחצים על Continue. מופיעה החלונית בדיקת פרטי מקור הנתונים ויצירה בדף יצירת מקור נתונים.
יצירת מקור הנתונים
תוכלו לבדוק את הפרטים של הזרם, וגם את פרופילי החיבור של המקור והיעד שבהם הזרם משתמש כדי להעביר נתונים ממסד נתונים של MySQL כמקור אל קטגוריית יעד ב-Cloud Storage.
כדי לאמת את הפיד, לוחצים על הפעלת אימות. באימות של זרם, Datastream בודק שהמקור מוגדר בצורה תקינה, מוודא שהזרם יכול להתחבר גם למקור וגם ליעד, ומאמת את ההגדרה מקצה לקצה של הזרם.
אחרי שכל בדיקות האימות עוברות בהצלחה, לוחצים על יצירה.
בתיבת הדו-שיח ליצור מקור נתונים?, לוחצים על יצירה.
התחלת השידור
במדריך הזה, יוצרים ומפעילים את הסטרים בנפרד, למקרה שתהליך יצירת הסטרים יגרום לעומס מוגבר על מסד הנתונים של המקור. כדי לדחות את הטעינה, יוצרים את מקור הנתונים בלי להפעיל אותו, ואז מפעילים אותו כשהמסד נתונים יכול להתמודד עם הטעינה.
אחרי שמפעילים את מקור הנתונים, Datastream יכול להעביר נתונים, סכימות וטבלאות ממסד הנתונים של המקור אל היעד.
נכנסים לדף Streams במסוף Google Cloud של Datastream.
מסמנים את התיבה לצד הסטרים שרוצים להפעיל. במדריך הזה, השם הוא השידור שלי.
לוחצים על התחלה.
בתיבת הדו-שיח, לוחצים על התחלה. הסטטוס של הזרם משתנה מ
Not startedלStartingלRunning.
אחרי שמתחילים להזרים נתונים, אפשר לוודא ש-Datastream העביר נתונים ממסד הנתונים של המקור ליעד.
אימות השידור
בקטע הזה מאשרים ש-Datastream מעביר את הנתונים מכל הטבלאות של מסד נתונים של MySQL כמקור לתיקייה /integration/tutorial בקטגוריית היעד ב-Cloud Storage.
נכנסים לדף Streams במסוף Google Cloud של Datastream.
לוחצים על מקור הנתונים שיצרתם. במדריך הזה, השם הוא השידור שלי.
בדף Stream details (פרטי מקור הנתונים), לוחצים על הקישור bucket-name/integration/tutorial, כאשר bucket-name הוא השם שנתתם לקטגוריה של Cloud Storage. הקישור הזה מופיע אחרי השדה נתיב הכתיבה של היעד. הדף Bucket details של Cloud Storage נפתח בכרטיסייה נפרדת.
מוודאים שרואים תיקיות שמייצגות טבלאות של מסד הנתונים של המקור.
לוחצים על אחת מתיקיות הטבלה ואז לוחצים על כל אחת מתיקיות המשנה עד שרואים נתונים שמשויכים לטבלה.
יצירת משימת Dataflow
בקטע הזה, יוצרים משימה ב-Dataflow. אחרי ש-Datastream מעביר בסטרימינג שינויים בנתונים ממסד נתונים של MySQL אל הקטגוריה שלכם ב-Cloud Storage, Pub/Sub שולח ל-Dataflow הודעות על קבצים חדשים שמכילים את השינויים. העבודה של Dataflow מעבדת את הקבצים ומעבירה את השינויים ל-BigQuery.
נכנסים לדף Jobs במסוף Google Cloud של Dataflow.
לוחצים על יצירת עבודה מתבנית.
בשדה Job name (שם הג'וב) בדף Create job from template (יצירת ג'וב מתבנית), מזינים שם לג'וב Dataflow שאתם יוצרים. במדריך הזה, מזינים
my-dataflow-integration-jobבשדה.בתפריט Regional endpoint, בוחרים את האזור שבו רוצים לאחסן את העבודה. זהו אותו אזור שבחרתם עבור פרופיל חיבור המקור, פרופיל חיבור היעד והזרם שיצרתם.
בתפריט Dataflow template (תבנית Dataflow), בוחרים את התבנית שבה משתמשים כדי ליצור את העבודה. במדריך הזה, בוחרים באפשרות Datastream to BigQuery (העברה מ-Datastream ל-BigQuery).
אחרי שבוחרים באפשרות הזו, מופיעים שדות נוספים שקשורים לתבנית הזו.
בשדה File location for Datastream file output in Cloud Storage (מיקום הקובץ של פלט קובץ Datastream ב-Cloud Storage), מזינים את השם של קטגוריה של Cloud Storage בפורמט הבא:
gs://bucket-name.בשדה Pub/Sub subscription being used in a Cloud Storage notification policy (מינוי Pub/Sub שנעשה בו שימוש במדיניות התראות של Cloud Storage), מזינים את הנתיב שמכיל את השם של המינוי ל-Pub/Sub. במדריך הזה, מזינים
projects/project-name/subscriptions/my_integration_notifs_sub.בשדה Datastream output file format (avro/json). (פורמט קובץ הפלט של Datastream (avro/json)), מזינים
avroכי במדריך הזה Avro הוא פורמט הקובץ של הקבצים ש-Datastream כותב ל-Cloud Storage.בשדה Name or template for the dataset to contain staging tables. (שם או תבנית של מערך הנתונים שיכיל את טבלאות הביניים), מזינים
My_integration_dataset_logכי Dataflow משתמש במערך הנתונים הזה כדי להכין את שינויי הנתונים שהוא מקבל מ-Datastream.בשדה תבנית למערך הנתונים שיכיל טבלאות משוכפלות, מזינים
My_integration_dataset_finalכי זה מערך הנתונים שבו השינויים שמוצגים בMy_integration_dataset_log מתמזגים כדי ליצור העתק זהה של הטבלאות במסד הנתונים של המקור.בשדה Dead letter queue directory (ספריית תור הודעות שלא ניתן להעביר), מזינים את הנתיב שמכיל את השם של קטגוריה של Cloud Storage נפרדת ואת התיקייה של תור ההודעות שלא ניתן להעביר. חשוב לוודא שלא משתמשים בנתיב בתיקיית הבסיס, ושהנתיב שונה מהנתיב שבו Datastream כותב נתונים. כל שינוי בנתונים שהמערכת לא מצליחה להעביר מ-Dataflow אל BigQuery מאוחסן בתור. אפשר לתקן את התוכן בתור כדי שמערכת Dataflow תוכל לעבד אותו מחדש.
במדריך הזה, מזינים
gs://dlq-bucket-name/dlqבשדה ספריית תור ההודעות המתות (כאשר dlq-bucket-name הוא השם של קטגוריה של Cloud Storage שמוקדשת לתור ההודעות המתות, ו-dlq הוא התיקייה של תור ההודעות המתות).לוחצים על הפעלת העבודה.
אימות השילוב
בקטע אימות הזרם במדריך הזה, אישרתם ש-Datastream העביר את הנתונים מכל הטבלאות של מסד נתוני MySQL של המקור לתיקייה /integration/tutorial בקטגוריית היעד של Cloud Storage.
בקטע הזה, תבדקו ש-Dataflow מעבד את הקבצים שמכילים שינויים שמשויכים לנתונים האלה, ומעביר את השינויים ל-BigQuery. כתוצאה מכך, יש לכם שילוב מקצה לקצה בין Datastream ל-BigQuery.
במסוף Google Cloud , עוברים לדף SQL workspace ב-BigQuery.
בחלונית Explorer, מרחיבים את הצומת שליד שם הפרויקט Google Cloud .
מרחיבים את הצמתים לצד מערכי הנתונים My_integration_dataset_log ו-My_integration_dataset_final.
מוודאים שכל מערך נתונים מכיל עכשיו נתונים. האישור הזה מעיד על כך ש-Dataflow עיבד את הקבצים שמכילים שינויים שמשויכים לנתונים ש-Datastream העביר ל-Cloud Storage, והעביר את השינויים האלה ל-BigQuery.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud על המשאבים שבהם השתמשתם במדריך הזה, אתם יכולים להשתמש במסוף Google Cloud כדי לבצע את הפעולות הבאות:
- מחיקת הפרויקט, מקור הנתונים ופרופילי החיבור של Datastream.
- מפסיקים את משימת Dataflow.
- מוחקים את מערכי הנתונים ב-BigQuery, את הנושא והמינוי ב-Pub/Sub ואת קטגוריית האחסון ב-Cloud Storage.
כדי למנוע שימוש במכסת המשאבים וחיוב עליהם בעתיד, חשוב להסיר את המשאבים שיצרתם ב-Datastream, ב-Dataflow, ב-BigQuery, ב-Pub/Sub וב-Cloud Storage.
מחיקת פרויקט
הדרך הקלה ביותר לבטל את החיוב היא למחוק את הפרויקט שיצרתם בשביל המדריך הזה.
במסוף Google Cloud , נכנסים לדף Manage resources.
ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
מחיקת השידור
נכנסים לדף Streams במסוף Google Cloud של Datastream.
לוחצים על הזרם שרוצים למחוק. במדריך הזה, השם הוא השידור שלי.
לוחצים על השהיה.
בתיבת הדו-שיח, לוחצים על השהיה.
בחלונית סטטוס המקור לנתונים שבדף פרטי המקור לנתונים, מוודאים שהסטטוס של המקור לנתונים הוא
Paused.לוחצים על Delete.
בתיבת הדו-שיח, בשדה הטקסט, מזינים
Deleteולוחצים על מחיקה.
מחיקת פרופילי הקישור
נכנסים לדף Connection profiles במסוף Google Cloud של Datastream.
מסמנים את תיבת הסימון לצד כל פרופיל חיבור שרוצים למחוק: פרופיל החיבור של מקור הנתונים שלי ופרופיל החיבור של יעד הנתונים שלי.
לוחצים על Delete.
בתיבת הדו-שיח, לוחצים על מחיקה.
הפסקת משימת Dataflow
נכנסים לדף Jobs במסוף Google Cloud של Dataflow.
לוחצים על העבודה שרוצים להפסיק. במדריך הזה, שם המשימה הוא my-dataflow-integration-job.
לוחצים על הפסקה.
בתיבת הדו-שיח Stop job (עצירת העבודה), בוחרים באפשרות Drain (ריקון) ולוחצים על Stop job (עצירת העבודה).
מחיקת מערכי הנתונים ב-BigQuery
במסוף Google Cloud , עוברים לדף SQL workspace ב-BigQuery.
בחלונית Explorer, מרחיבים את הצומת שלצד Google Cloud שם הפרויקט.
לוחצים על הלחצן View actions (הצגת פעולות) משמאל לאחד ממערכי הנתונים שיצרתם בשלב יצירת מערכי נתונים ב-BigQuery. הלחצן הזה נראה כמו שלוש נקודות אנכיות.
במדריך הזה, לוחצים על הלחצן הצגת פעולות משמאל ל-My_integration_dataset_log.
בתפריט הנפתח שמופיע, בוחרים באפשרות מחיקה.
בתיבת הדו-שיח Delete dataset? (מחיקת מערך הנתונים?), מזינים
deleteבשדה הטקסט ולוחצים על Delete (מחיקה).חוזרים על השלבים שמתוארים בהליך הזה כדי למחוק את מערך הנתונים השני שיצרתם: My_integration_dataset_final.
מחיקת המינוי והנושא ב-Pub/Sub
נכנסים לדף Subscriptions של Pub/Sub במסוף Google Cloud .
לוחצים על תיבת הסימון לצד המינוי שרוצים למחוק. במדריך הזה, לוחצים על תיבת הסימון לצד המינוי my_integration_notifs_sub.
לוחצים על Delete.
בתיבת הדו-שיח מחיקת המינוי, לוחצים על מחיקה.
נכנסים לדף Topics של Pub/Sub במסוף Google Cloud .
לוחצים על תיבת הסימון לצד הנושא my_integration_notifs.
לוחצים על Delete.
בתיבת הדו-שיח Delete topic, מזינים
deleteבשדה הטקסט ולוחצים על Delete.
מחיקת קטגוריה של Cloud Storage
נכנסים לדף Browser של Cloud Storage במסוף Google Cloud .
מסמנים את התיבה לצד הקטגוריה.
לוחצים על Delete.
בתיבת הדו-שיח, מזינים
Deleteבשדה הטקסט ולוחצים על מחיקה.
המאמרים הבאים
- מידע נוסף על Datastream
- שימוש ב-Legacy Streaming API כדי לבצע יכולות מתקדמות עם נתונים בסטרימינג ל-BigQuery.
- כדאי לנסות בעצמכם תכונות אחרות של Google Cloud . מומלץ לעיין במדריכים שלנו.