
始める前に
まだ設定していない場合は、 Google Cloud プロジェクトと 2 つの Cloud Storage バケットを設定します。
プロジェクトを設定する
- Google Cloud アカウントにログインします。 Google Cloudを初めて使用する場合は、 アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Google Cloud CLI をインストールします。
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Google Cloud CLI をインストールします。
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init
プロジェクトで 2 つの Cloud Storage バケットを作成または使用する
プロジェクトには、入力ファイル用と出力ファイル用の 2 つの Cloud Storage バケットが必要です。
- Google Cloud コンソールで、Cloud Storage の [バケット] ページに移動します。
- [ 作成] をクリックします。
- [バケットの作成] ページでユーザーのバケット情報を入力します。次のステップに進むには、[続行] をクリックします。
- [始める] セクションで、次の操作を行います。
-
[データの保存場所の選択] セクションで、次の操作を行います。
- ロケーション タイプを選択してください。
- [ロケーション タイプ] プルダウン メニューから、バケットのデータが永続的に保存されるロケーションを選択します。
- ロケーション タイプとして [デュアルリージョン] を選択した場合は、関連するチェックボックスを使用してターボ レプリケーションを有効にすることもできます。
- クロスバケット レプリケーションを設定するには、[Storage Transfer Service 経由でクロスバケット レプリケーションを追加する] を選択し、次の手順を実施します。
クロスバケット レプリケーションを設定する
- [バケット] メニューで、バケットを選択します。
[レプリケーション設定] セクションで、[構成] をクリックして、レプリケーション ジョブの設定を構成します。
[クロスバケット レプリケーションを構成する] ペインが表示されます。
- オブジェクト名の接頭辞で複製するオブジェクトをフィルタするには、オブジェクトを追加または除外する接頭辞を入力し、 [接頭辞を追加] をクリックします。
- 複製されたオブジェクトのストレージ クラスを設定するには、[ストレージ クラス] メニューからストレージ クラスを選択します。この手順をスキップすると、複製されたオブジェクトはデフォルトで宛先バケットのストレージ クラスを使用します。
- [完了] をクリックします。
-
[データの保存場所を選択する] セクションで、次の操作を行います。
- バケットのデフォルトのストレージ クラスを選択するか、バケットデータのストレージ クラスを自動的に管理する Autoclass を選択します。
- 階層名前空間を有効にするには、[データ量が多いワークロード向けにストレージを最適化] セクションで、[このバケットで階層的な名前空間を有効にする] を選択します。
- [オブジェクトへのアクセスを制御する方法を選択する] セクションで、バケットに公開アクセスの防止を適用するかどうかを選択し、バケットのオブジェクトに使用するアクセス制御方法を選択します。
-
[オブジェクト データを保護する方法を選択する] セクションで、次の操作を行います。
- [データ保護] で、バケットに設定するオプションを選択します。
- 削除(復元可能)を有効にするには、[削除(復元可能)ポリシー(データ復元用)] チェックボックスをオンにして、削除後にオブジェクトを保持する日数を指定します。
- オブジェクトのバージョニングを設定するには、[オブジェクトのバージョニング(バージョン管理用)] チェックボックスをオンにして、オブジェクトごとの最大バージョン数と、非現行バージョンの有効期限が切れるまでの日数を指定します。
- オブジェクトとバケットで保持ポリシーを有効にするには、[保持(コンプライアンス用)] チェックボックスをオンにして、次の操作を行います。
- オブジェクト保持ロックを有効にするには、[オブジェクト保持を有効にする] チェックボックスをオンにします。
- バケットロックを有効にするには、[バケット保持ポリシーを設定] チェックボックスをオンにして、保持期間の単位と期間を選択します。
- オブジェクト データの暗号化方法を選択するには、[データ暗号化] セクション()を開き、データ暗号化方法を選択します。
- [データ保護] で、バケットに設定するオプションを選択します。
- [作成] をクリックします。
ワークフロー テンプレートを作成する
ワークフロー テンプレートを作成して定義するには、ローカル ターミナル ウィンドウまたは Cloud Shell で次のコマンドをコピーして実行します。
- ワークフロー テンプレートを作成します。
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- wordcount ジョブをワークフロー テンプレートに追加します。
-
コマンドを実行する前に output-bucket-name を指定します(関数は入力バケットを提供します)。出力バケット名を挿入すると、出力バケット引数は
gs://your-output-bucket/wordcount-output"のようになります。 -
「count」ステップ ID は必須です。追加された Hadoop ジョブを識別します。
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
コマンドを実行する前に output-bucket-name を指定します(関数は入力バケットを提供します)。出力バケット名を挿入すると、出力バケット引数は
- ワークフローを実行するには、マネージドの単一ノードクラスタを使用します。Managed Service for Apache Spark によってクラスタが作成され、ワークフローがクラスタ上で実行され、ワークフローの完了時にクラスタが削除されます。
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Google Cloud コンソールの Managed Service for Apache Spark の [ワークフロー] ページで
wordcount-template名をクリックし、[ワークフロー テンプレートの詳細] ページを開きます。wordcount-template 属性を確認します。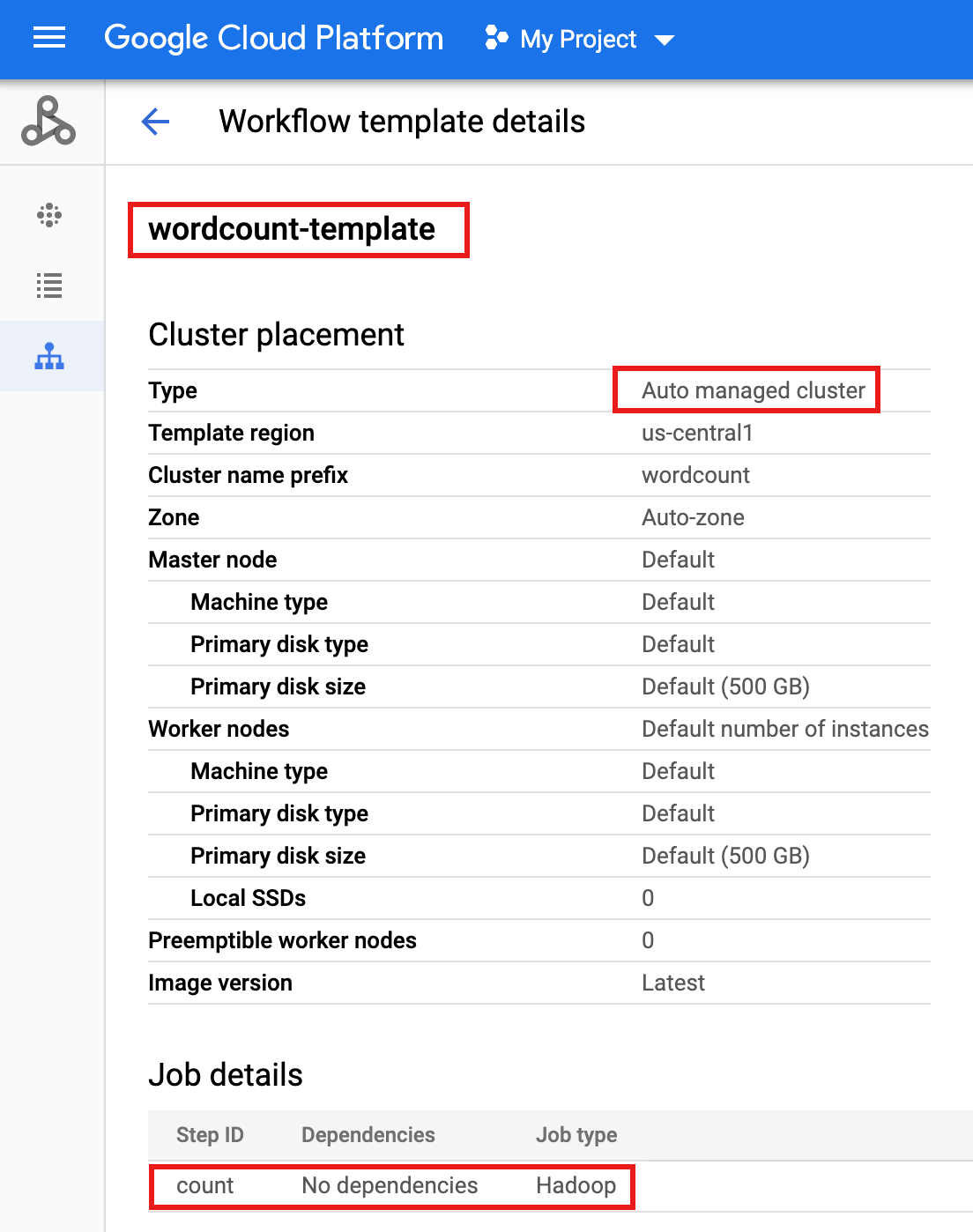
ワークフロー テンプレートをパラメータ化する
ワークフロー テンプレートに渡す入力バケット変数をパラメータ化します。
- パラメータ化のために、ワークフロー テンプレートを
wordcount.yamlテキスト ファイルにエクスポートします。gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- テキスト エディタを使用して
wordcount.yamlを開き、ワークフローがトリガーされた際に、ワードカウント バイナリにargs[1]として Cloud Storage の INPUT_BUCKET_URI が渡されるようにするため、YAML ファイルの末尾にparametersブロックを追加します。エクスポートされた YAML ファイルの例を以下に示します。テンプレートを更新する方法は次の 2 つがあります。このうちの 1 つを選びます。
- your-output_bucket を出力バケット名に置き換えたあと、エクスポートした
wordcount.yamlを置き換えるため、ファイル全体をコピーして貼り付けます。 - エクスポートした
wordcount.yamlファイルの末尾に、parametersセクションのみをコピーして貼り付けます。
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - your-output_bucket を出力バケット名に置き換えたあと、エクスポートした
- パラメータ化された
wordcount.yamlテキスト ファイルをインポートします。テンプレートを上書きするように求められたら、「Y」(Yes の Y)を入力します。gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
Cloud Functions の関数を作成する
Google Cloud コンソールで [Cloud Run functions] ページを開き、[関数の作成] をクリックします。
[関数の作成] ページで、次の情報を入力または選択します。
- 名前: wordcount
- 割り当てられているメモリ: デフォルトの選択のままにします。
- トリガー:
- Cloud Storage
- イベント タイプ: 確定 / 作成
- バケット: 入力バケットを選択します(プロジェクトで Cloud Storage バケットを作成するを参照)。このバケットにファイルが追加されると、この関数はワークフローをトリガーします。ワークフローでワードカウント アプリケーションが実行され、バケット内のすべてのテキスト ファイルが処理されます。
ソースコード:
- インライン エディタ
- ランタイム: Node.js 8
INDEX.JSタブ: デフォルトのコード スニペットを次のコードに置き換え、-your-project-id-(先頭または末尾に「-」がないもの)を指定するようにconst projectId行を編集します。
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };PACKAGE.JSONタブ: デフォルトのコード スニペットを次のコードに置き換えます。
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- 実行する関数: 「startWorkflow」を挿入します。
[作成] をクリックします。
関数をテストする
公開ファイル
rose.txtをバケットにコピーして、関数をトリガーします。コマンドに your-input-bucket-name(関数のトリガーに使用されるバケット)を挿入します。gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
30 秒待ってから、次のコマンドを実行して関数が正常に完了したことを確認します。
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Google Cloud コンソールの [関数] リストページから関数ログを表示するには、関数名
wordcountをクリックし、[ファンクションの詳細] ページで [ログを表示] をクリックします。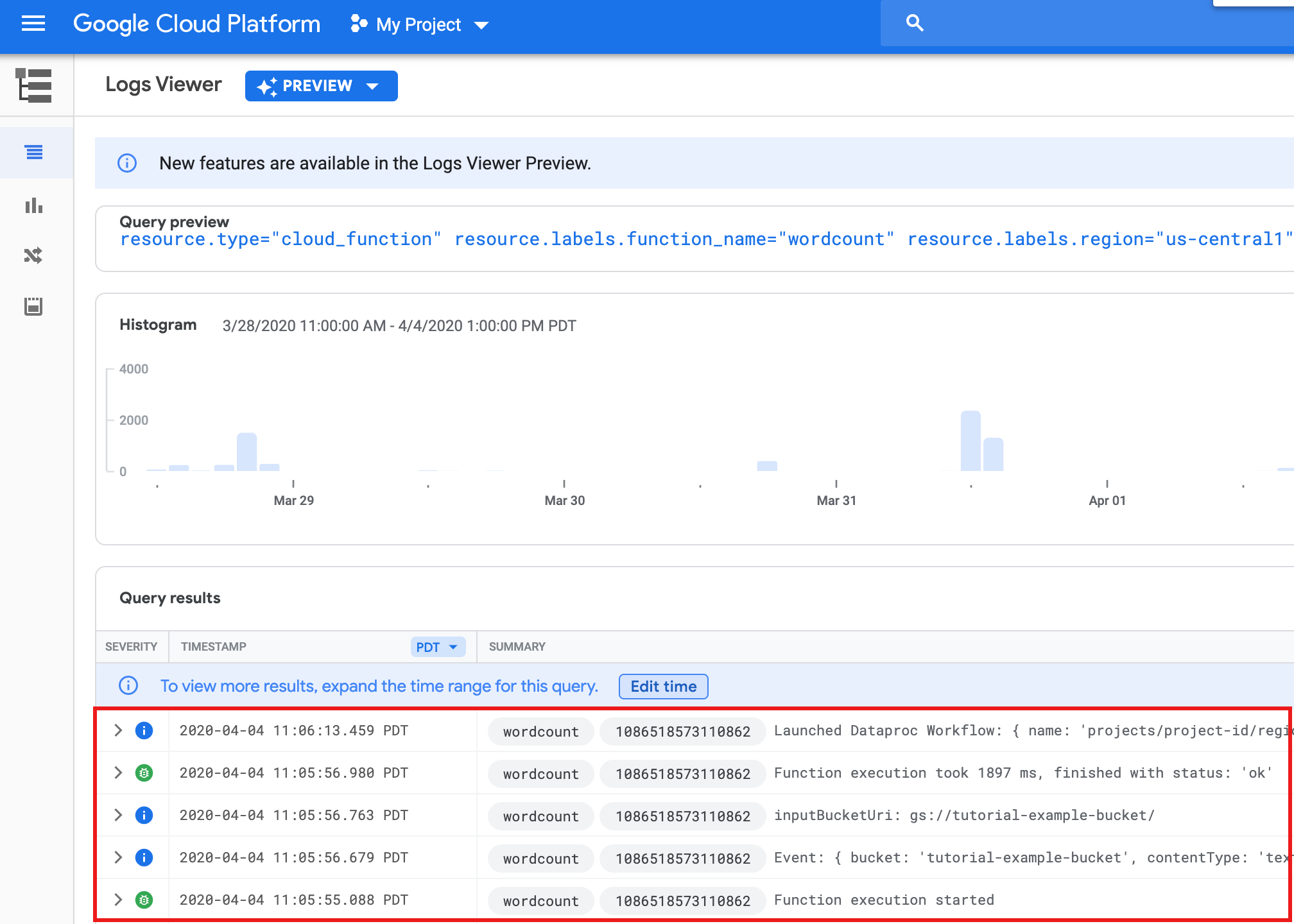
出力バケットの
wordcount-outputフォルダは、Google Cloud コンソールのストレージ ブラウザ ページで確認できます。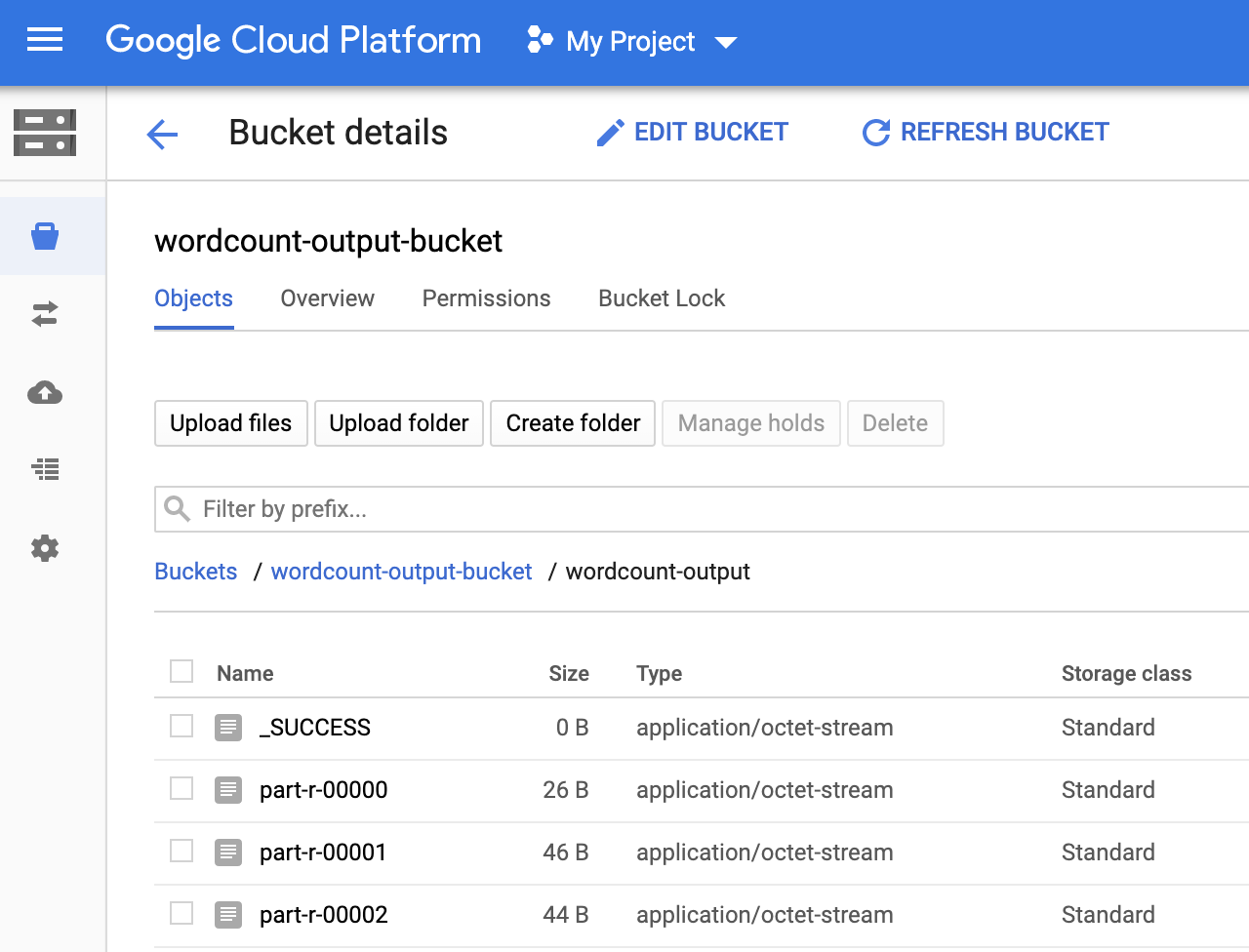
ワークフローの完了後、ジョブの詳細はGoogle Cloud コンソールに残ります。Managed Service for Apache Spark の [ジョブ] ページに表示されている
count...ジョブをクリックして、ワークフロー ジョブの詳細を表示します。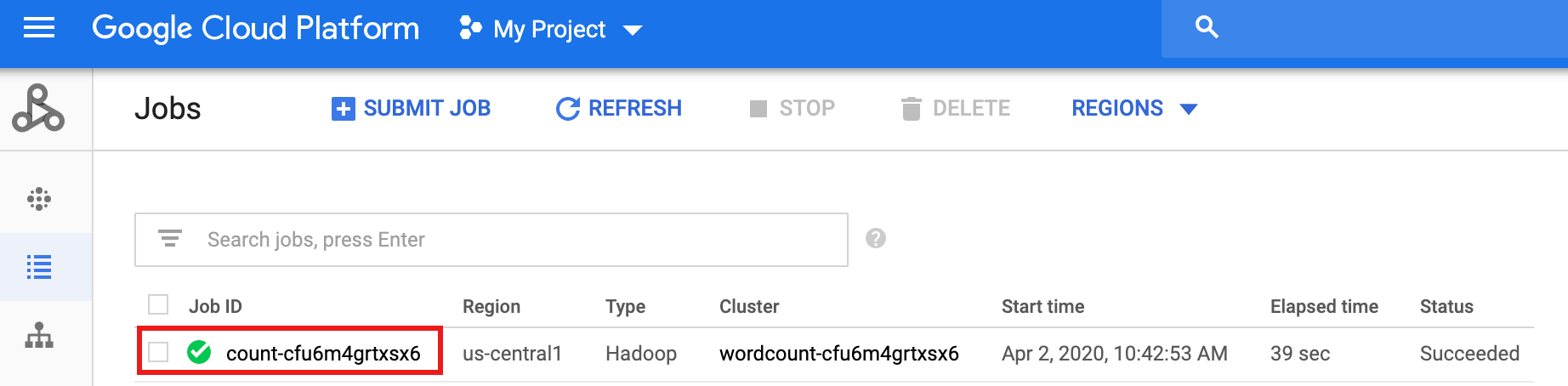
クリーンアップ
このチュートリアルのワークフローでは、ワークフローが完了するとマネージド クラスタが削除されます。繰り返し費用が発生しないようにするには、このチュートリアルに関連する他のリソースを削除します。
プロジェクトを削除する
- Google Cloud コンソールで [リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
Cloud Storage バケットを削除する
- Google Cloud コンソールで、Cloud Storage の [バケット] ページに移動します。
- 削除するバケットのチェックボックスをクリックします。
- バケットを削除するには、 [削除] をクリックして、指示に沿って操作します。
ワークフロー テンプレートを削除する
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Cloud Functions の関数を削除する
Google Cloud コンソールで [Cloud Run functions] ページを開き、wordcount 関数の左側にあるボックスを選択して [削除] をクリックします。