
Ziele
Verwenden Sie Dataproc Hub, um eine JupyterLab-Notebook-Umgebung für einen einzelnen Nutzer zu erstellen, die in einem Managed Service for Apache Spark-Cluster ausgeführt wird.
Erstellen Sie ein Notebook und führen Sie einen Spark-Job im Managed Service for Apache Spark-Cluster aus.
Löschen Sie den Cluster und behalten Sie Ihr Notebook in Cloud Storage bei.
Hinweis
- Der Administrator muss Ihnen die Berechtigung
notebooks.instances.useerteilen (siehe IAM-Identity and Access Management festlegen).
Dataproc JupyterLab-Cluster über Dataproc Hub erstellen
Wählen Sie in der Google Cloud console auf der Dataproc → Workbench Seite den Tab Nutzerverwaltete Notebooks aus.
Klicken Sie in der Zeile, in der die vom Administrator erstellte Dataproc Hub-Instanz aufgeführt ist, auf JupyterLab öffnen.
- Wenn Sie keinen Zugriff auf die Google Cloud console haben, geben Sie in Ihrem Webbrowser die Dataproc Hub-Instanz-URL ein, die ein Administrator für Sie freigegeben hat.
Wählen Sie auf der Seite Jupyterhub → Dataproc-Optionen eine Clusterkonfiguration und -zone aus. Falls aktiviert, nehmen Sie die gewünschten Anpassungen vor und klicken Sie auf Erstellen.
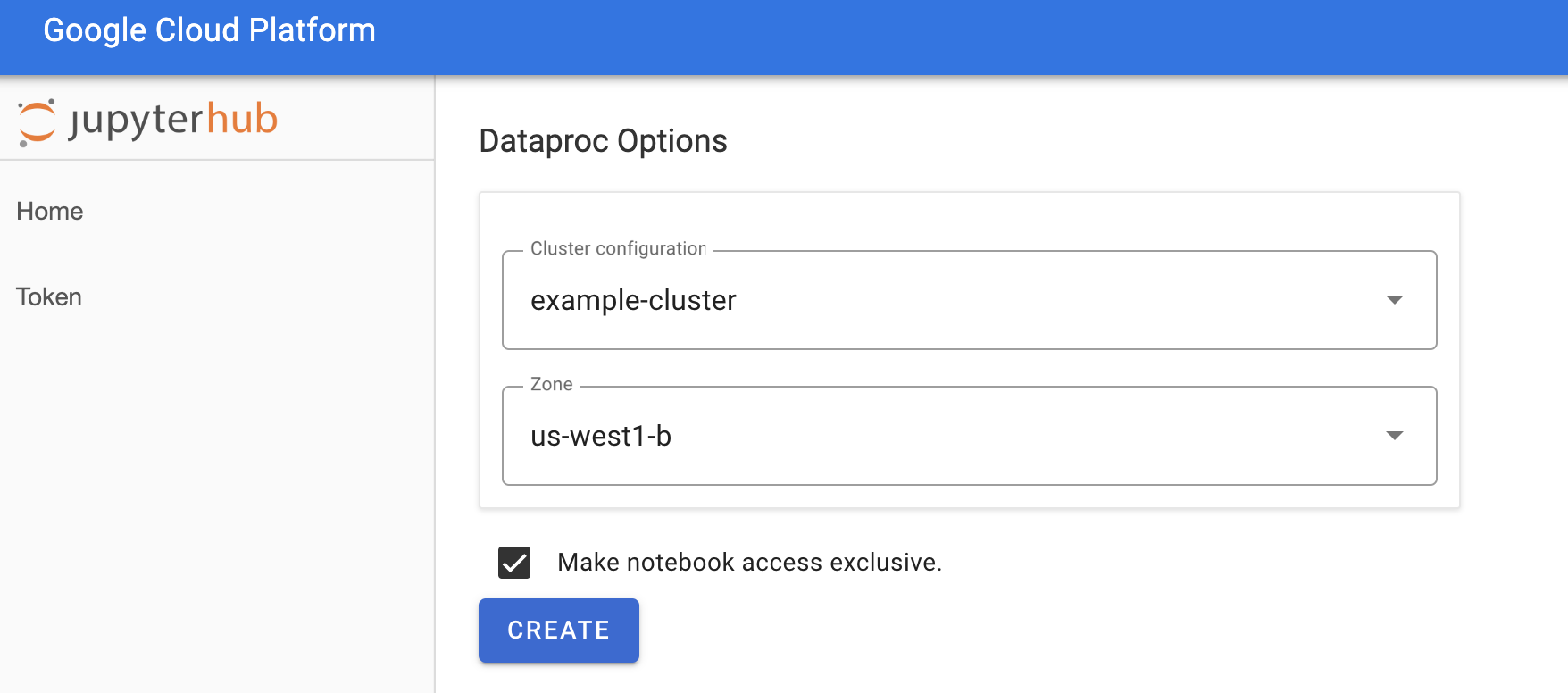
Nachdem der Managed Service for Apache Spark-Cluster erstellt wurde, werden Sie zur JupyterLab-Oberfläche weitergeleitet, die im Cluster ausgeführt wird.
Notebook erstellen und einen Spark-Job ausführen
Klicken Sie im linken Bereich der JupyterLab-Oberfläche auf
GCS(Cloud Storage).Erstellen Sie über den JupyterLab-Launcher ein PySpark-Notebook.
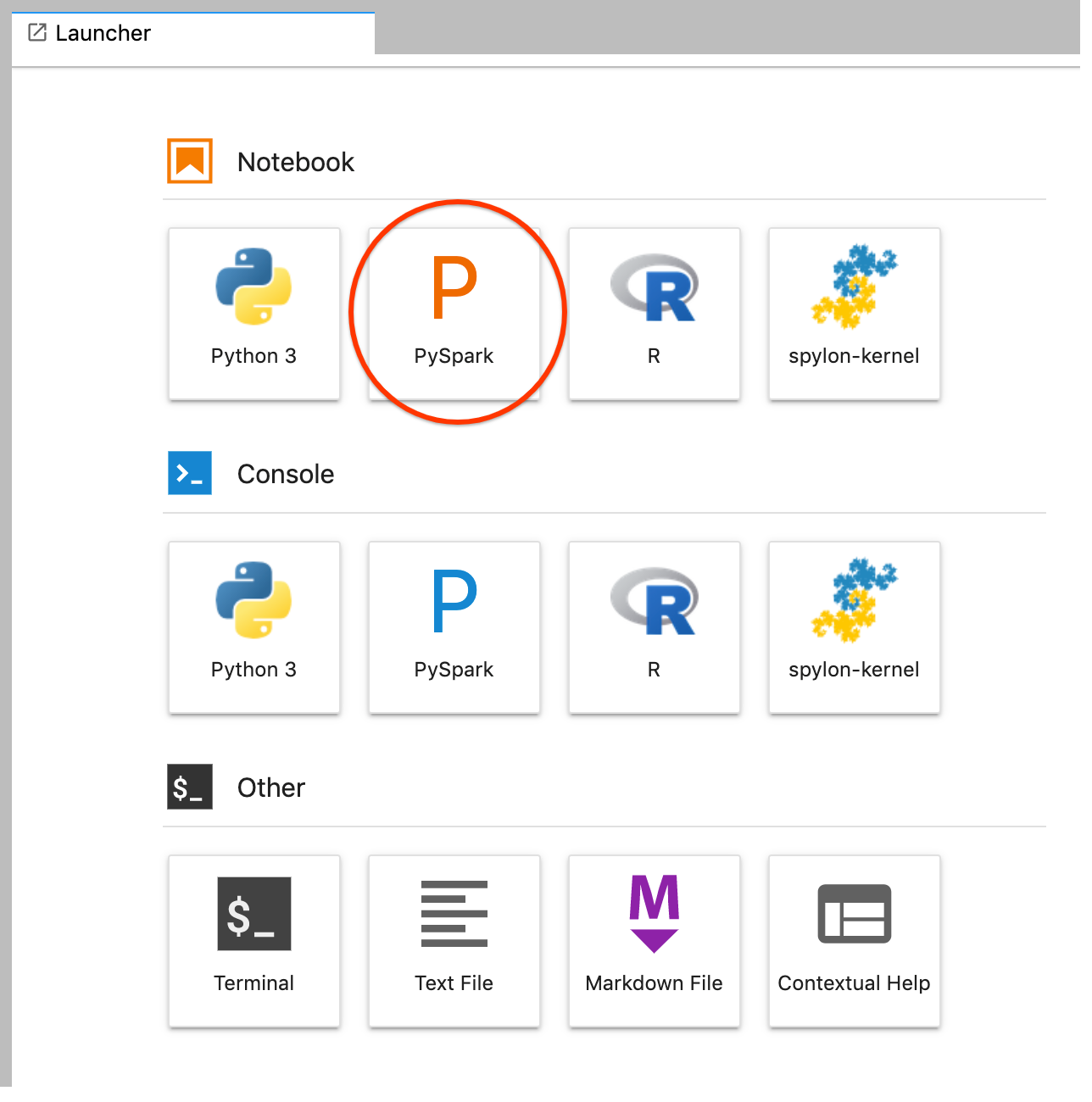
Der PySpark-Kernel initialisiert einen SparkContext mithilfe der Variable
sc. Sie können den SparkContext untersuchen und einen Spark-Job aus dem Notebook ausführen.rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())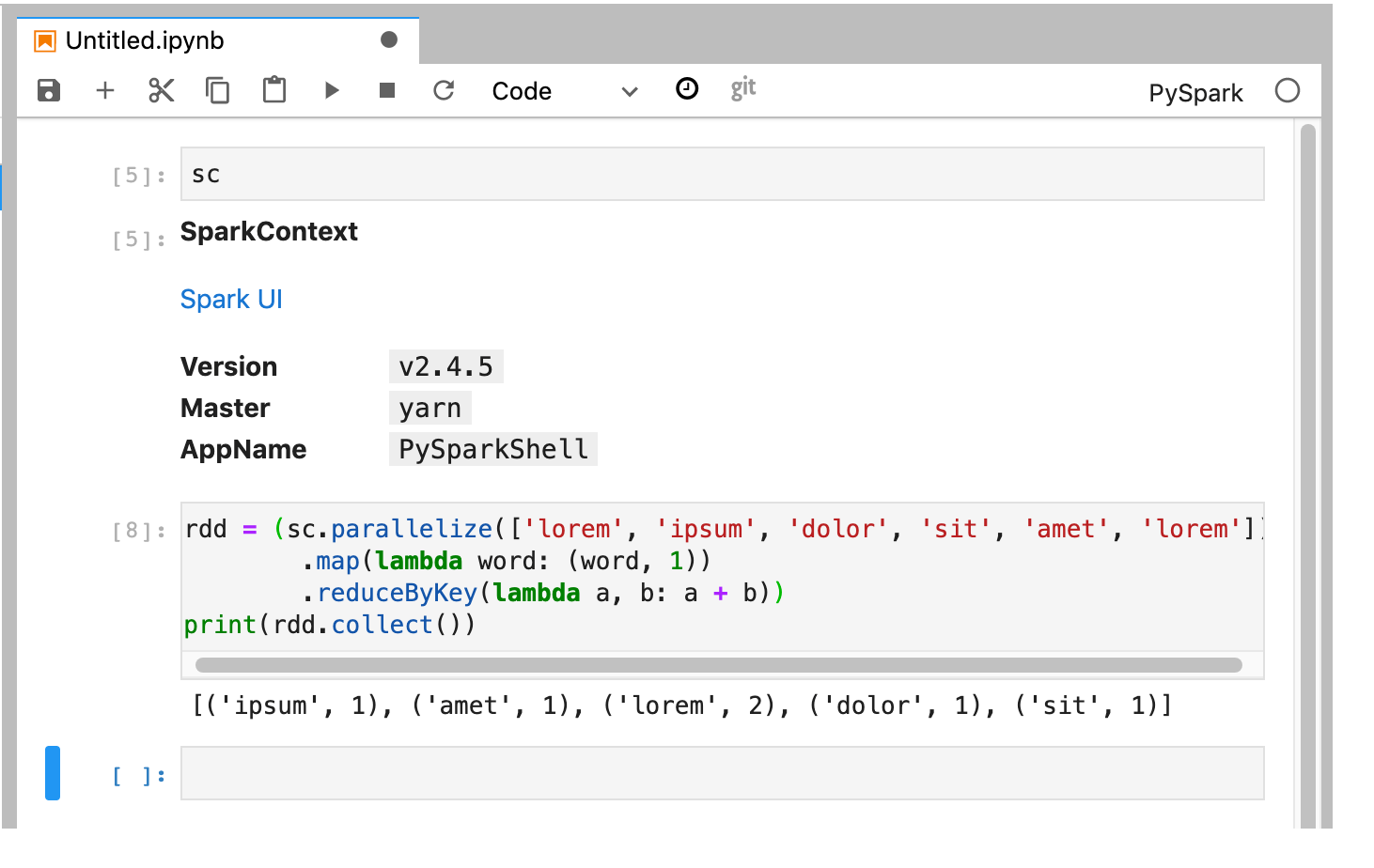
Benennen Sie das Notebook und speichern Sie es. Das Notebook wird gespeichert und verbleibt in Cloud Storage, nachdem der Managed Service for Apache Spark-Cluster gelöscht wurde.
Dataproc-Cluster herunterfahren
Wählen Sie in der JupyterLab-Oberfläche Datei → Hub-Steuerfeld aus, um die Seite Jupyterhub zu öffnen.
Klicken Sie auf Meinen Cluster anhalten , um den JupyterLab-Server herunterzufahren (zu löschen), wodurch der Managed Service for Apache Spark-Cluster gelöscht wird.
Nächste Schritte
- Informationen zu Spark- und Jupyter-Notebooks in Dataproc auf GitHub.