
Criar um lakehouse com o Spark e o catálogo de ambiente de execução do Lakehouse
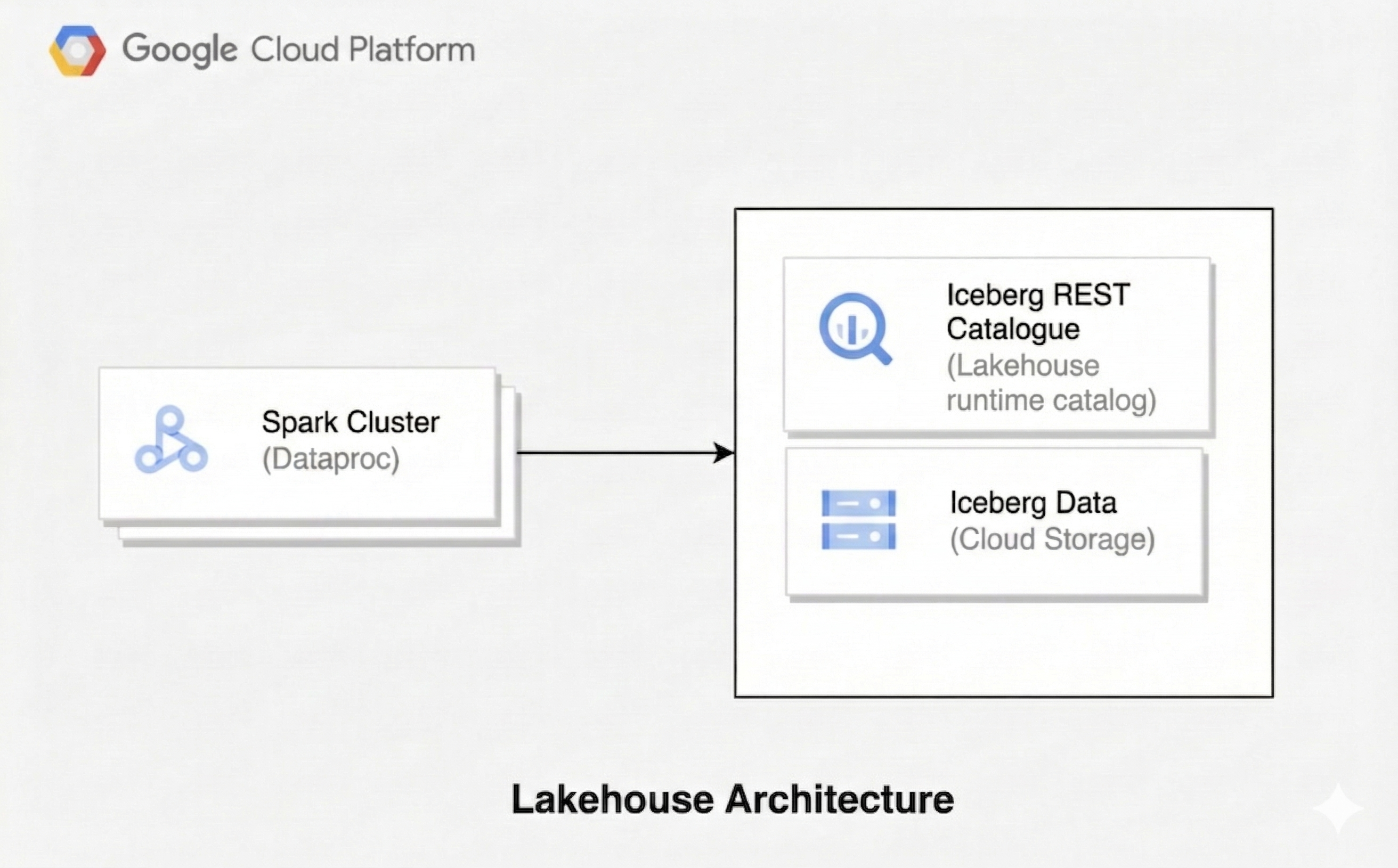
Uma arquitetura de lakehouse combina a flexibilidade de um data lake com os recursos de gerenciamento de dados de um data warehouse. Este documento mostra como configurar um lakehouse no Google Cloud. Você usa o Apache Iceberg como formato de tabela, o Serviço Gerenciado para Apache Spark para processamento e o catálogo de ambiente de execução do Lakehouse Iceberg REST Catalog para gerenciamento unificado de metadados.
Essa arquitetura usa formatos de tabela abertos, como o Iceberg, para adicionar recursos de armazenamento em data warehouse, como transações e evolução de esquema, aos dados no Cloud Storage. Essa abordagem cria uma única fonte de verdade para seus dados que pode ser acessada por vários mecanismos.
Antes de começar
- Faça login na sua Google Cloud conta do. Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho dos nossos produtos em situações reais. Clientes novos também recebem US $300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Crie um bucket do Cloud Storage para armazenar dados do Iceberg.
Funções exigidas
Algumas funções do Identity and Access Management (IAM) são necessárias para executar os exemplos nesta página. Dependendo das políticas da organização, essas funções já podem ter sido concedidas. Para verificar as concessões de papéis, consulte Você precisa conceder papéis?.
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos,pastas e organizações.
Papéis do usuário
Para receber as permissões necessárias para criar um cluster do Serviço Gerenciado para Apache Spark, peça ao administrador para conceder a você os seguintes papéis do IAM:
-
Editor do Dataproc (
roles/dataproc.editor) no projeto -
Usuário da conta de serviço (
roles/iam.serviceAccountUser) na conta de serviço padrão do Compute Engine
Papel de conta de serviço
Para garantir que a conta de serviço padrão do Compute Engine tenha as permissões necessárias para criar um cluster do Serviço Gerenciado para Apache Spark, peça ao administrador para conceder o papel do IAM de Worker do Dataproc (roles/dataproc.worker) à conta de serviço padrão do Compute Engine no projeto.
Criar um cluster do Serviço Gerenciado para Apache Spark
Crie um cluster do Serviço Gerenciado para Apache Spark com os componentes opcionais do Iceberg e do Jupyter.
Para criar o cluster, execute o seguinte comando
gcloud:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'Substitua:
CLUSTER_NAME: um nome para o cluster.PROJECT_ID: o ID do Google Cloud projeto.REGION: aregião do Google Cloud cluster, por exemplo,us-central1.
A definição de
dataproc:dataproc.lineage.enabled=truenão é necessária para que o catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse funcione corretamente. Ele é adicionado para rastreamento de linhagem no exemplo de linhagem de dados abaixo.Conecte-se ao cluster usando um notebook do Jupyter. É possível usar um notebook do Vertex AI Workbench ou iniciar um notebook diretamente no cluster.
Configurar uma sessão do Spark
No notebook do Jupyter, crie uma sessão do Spark configurada para usar o catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
Substitua:
CATALOG_NAME: um nome para o catálogo do Iceberg, por exemplo,iceberg_catalog.APP_NAME: o nome do aplicativo Spark.GCS_BUCKET: o bucket do Cloud Storage para armazenar os dados da tabela do Iceberg.PROJECT_ID: o ID do Google Cloud projeto.
Gerenciar dados com o Spark SQL
Depois de configurar a sessão do Spark, use o Spark SQL para realizar operações de gerenciamento de dados.
Crie um namespace. No catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse, um namespace corresponde a um conjunto de dados do BigQuery.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")Substitua
NAMESPACE_NAMEpelo nome do namespace, por exemplo,spark_lakehouse.Crie uma tabela base no formato Iceberg e insira dados.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()O resultado será assim:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+Crie uma segunda tabela para novos dados.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()O resultado será assim:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+Mescle os novos dados na tabela base.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()O resultado será assim:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+Atualize os registros na tabela base.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()O resultado será assim:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+Exclua registros da tabela base.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()O resultado será assim:
+---+ | id| +---+ | 3| | 5| | 1| +---+
Consultar um snapshot histórico
Recupere uma versão anterior de uma tabela consultando um ID de snapshot específico. Essa operação também é conhecida como viagem no tempo.
Recupere o ID do snapshot da versão da tabela antes das operações
MERGE,UPDATEeDELETE.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]Substitua
NAMESPACE_NAMEpelo namespace que você criou.Consulte a tabela usando o ID do snapshot recuperado.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()A saída mostra o estado da tabela após a operação
MERGE, mas antes de qualquer operaçãoUPDATEouDELETE.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
Descobrir a linhagem de dados
É possível rastrear a movimentação de dados entre as tabelas do catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse
com a linhagem de dados, que
está disponível no Serviço Gerenciado para Apache Spark 2.2 e versões de imagem mais recentes.
Exemplo de linhagem de dados
Crie tabelas de origem e destino do Iceberg e copie os dados.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)No Google Cloud console, acesse a página Pesquisa do Knowledge Catalog.
Pesquise uma das tabelas e clique na guia
Lineage: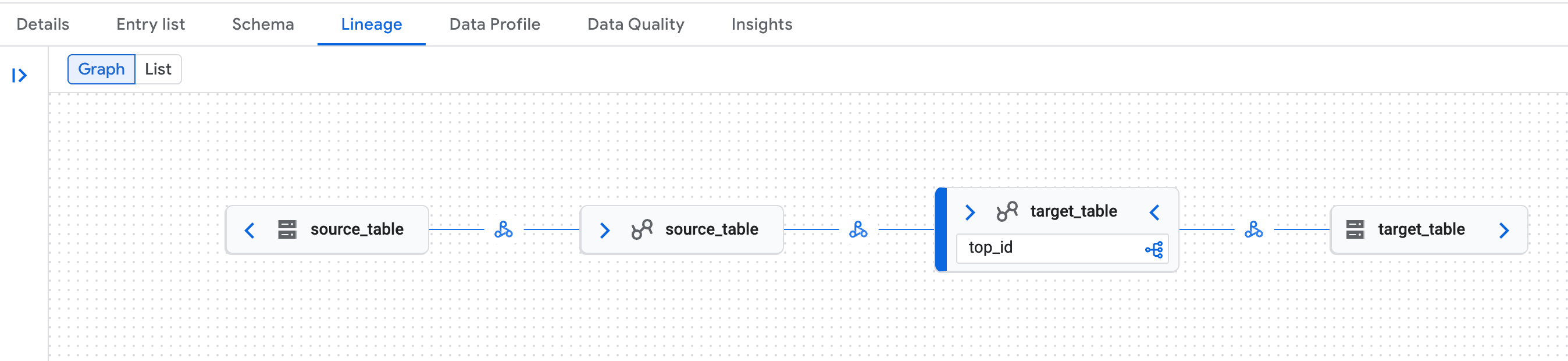
Exemplo de gráfico de linhagem de dados na página do Knowledge Catalog no Google Cloud console. A linhagem de dados reconhece as representações lógicas (tabela do catálogo de ambiente de execução do Lakehouse) e físicas (Cloud Storage) das tabelas do catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse.
Problema conhecido de linhagem de dados
Em alguns clusters do Serviço Gerenciado para Apache Spark, a linhagem de dados completa pode não ser
gerada devido a um OpenLineage.
Solução alternativa: na configuração da sessão do Spark, defina a propriedade spark.sql.catalog.{catalog_name}.uri como https://biglake.googleapis.com/iceberg/v1beta/restcatalog.
A seguir
- Saiba mais sobre o catálogo REST do Iceberg do catálogo de ambiente de execução do Lakehouse.
- Conheça os recursos do Apache Iceberg.
- Aprenda a consultar dados do Iceberg no catálogo de ambiente de execução do Lakehouse.
- Saiba mais sobre a linhagem de dados e o Serviço Gerenciado para Apache Spark.