
Crea un lakehouse con Spark y el catálogo del entorno de ejecución de Lakehouse
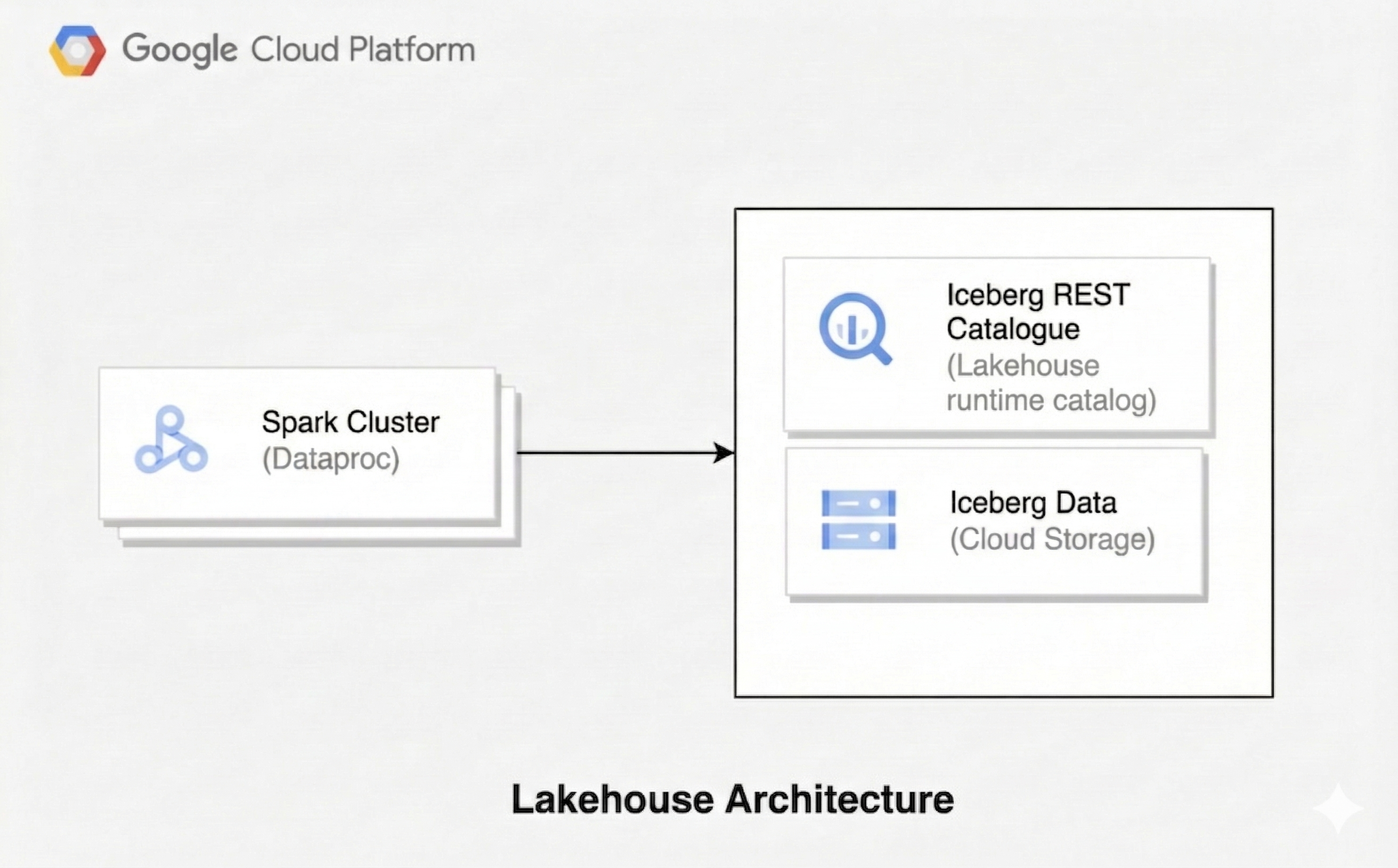
Una arquitectura de lakehouse combina la flexibilidad de un data lake con las funciones de administración de datos de un almacén de datos. En este documento, se muestra cómo configurar un lakehouse en Google Cloud. Usas Apache Iceberg como formato de tabla, Managed Service para Apache Spark para el procesamiento y el catálogo de tiempo de ejecución de Lakehouse, Iceberg REST Catalog, para la administración unificada de metadatos.
Esta arquitectura usa formatos de tabla abierta, como Iceberg, para agregar capacidades de almacenamiento de datos, como transacciones y evolución de esquemas, a los datos en Cloud Storage. Este enfoque crea una única fuente de información para tus datos a la que pueden acceder varios motores.
Antes de comenzar
- Accede a tu cuenta de Google Cloud . Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that you have the permissions required to complete this guide.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Crea un bucket de Cloud Storage para almacenar datos de Iceberg.
Roles obligatorios
Se requieren ciertos roles de Identity and Access Management (IAM) para ejecutar los ejemplos de esta página. Según las políticas de la organización, es posible que estos roles ya se hayan otorgado. Para verificar las asignaciones de roles, consulta ¿Necesitas otorgar roles?.
Para obtener más información sobre cómo otorgar roles, consulta Administra el acceso a proyectos, carpetas y organizaciones.
Funciones de usuario
Para obtener los permisos que necesitas para crear un clúster de Managed Service para Apache Spark, pídele a tu administrador que te otorgue los siguientes roles de IAM:
-
Editor de Dataproc (
roles/dataproc.editor) en el proyecto -
Usuario de cuenta de servicio (
roles/iam.serviceAccountUser) en la cuenta de servicio predeterminada de Compute Engine
Función de cuenta de servicio
Para asegurarte de que la cuenta de servicio predeterminada de Compute Engine tenga los permisos necesarios para crear un clúster de Managed Service para Apache Spark, pídele a tu administrador que otorgue el rol de IAM de trabajador de Dataproc (roles/dataproc.worker) a la cuenta de servicio predeterminada de Compute Engine en el proyecto.
Crea un clúster de Managed Service para Apache Spark
Crea un clúster de Managed Service for Apache Spark con los componentes opcionales de Iceberg y Jupyter.
Para crear el clúster, ejecuta el siguiente comando de
gcloud:gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT_ID \ --region=REGION \ --image-version=2.3-debian12 \ --optional-components=ICEBERG,JUPYTER \ --enable-component-gateway \ --properties 'dataproc:dataproc.lineage.enabled=true'Reemplaza lo siguiente:
CLUSTER_NAME: Es un nombre para tu clúster.PROJECT_ID: Es el ID del proyecto de Google Cloud .REGION: La región Google Cloud del clúster, por ejemplo,us-central1.
Ten en cuenta que no es necesario configurar
dataproc:dataproc.lineage.enabled=truepara que el catálogo de REST de Iceberg del catálogo de tiempo de ejecución de Lakehouse funcione correctamente. Se agrega para el seguimiento del linaje en el ejemplo de linaje de datos que se muestra a continuación.Conéctate al clúster con un notebook de Jupyter. Puedes usar un notebook de Vertex AI Workbench o iniciar un notebook directamente en el clúster.
Configura una sesión de Spark
En tu notebook de Jupyter, crea una sesión de Spark configurada para usar el catálogo de tiempo de ejecución de Lakehouse, el catálogo de REST de Iceberg.
import pyspark
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
catalog_name = "CATALOG_NAME"
spark = SparkSession.builder.appName("APP_NAME") \
.config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{catalog_name}.type', 'rest') \
.config(f'spark.sql.catalog.{catalog_name}.uri', 'https://biglake.googleapis.com/iceberg/v1beta/restcatalog') \
.config(f'spark.sql.catalog.{catalog_name}.warehouse', 'gs://GCS_BUCKET') \
.config(f'spark.sql.catalog.{catalog_name}.header.x-goog-user-project', 'PROJECT_ID') \
.config(f'spark.sql.catalog.{catalog_name}.rest.auth.type', 'org.apache.iceberg.gcp.auth.GoogleAuthManager') \
.config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.gcp.gcs.GCSFileIO') \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', catalog_name) \
.getOrCreate()
Reemplaza lo siguiente:
CATALOG_NAME: Un nombre para tu catálogo de Iceberg, por ejemplo,iceberg_catalog.APP_NAME: Es el nombre de tu aplicación de Spark.GCS_BUCKET: Es el bucket de Cloud Storage en el que se almacenarán los datos de la tabla de Iceberg.PROJECT_ID: Es el ID del proyecto de Google Cloud .
Administra datos con Spark SQL
Después de configurar la sesión de Spark, usa Spark SQL para realizar operaciones de administración de datos.
Crea un espacio de nombres. En el catálogo de tiempo de ejecución de Lakehouse, el catálogo de REST de Iceberg, un espacio de nombres corresponde a un conjunto de datos de BigQuery.
spark.sql("CREATE NAMESPACE IF NOT EXISTS NAMESPACE_NAME") spark.sql("USE NAMESPACE_NAME")Reemplaza
NAMESPACE_NAMEpor el nombre de tu espacio de nombres, por ejemplo,spark_lakehouse.Crea una tabla base en formato Iceberg y, luego, inserta datos.
spark.sql("DROP TABLE IF EXISTS base_table PURGE") spark.sql("CREATE TABLE base_table (id LONG) USING iceberg") spark.sql("INSERT INTO base_table VALUES 0, 1, 2, 3, 4") spark.sql("SELECT * FROM base_table").show()El resultado es similar a lo siguiente:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| +---+Crea una segunda tabla para los datos nuevos.
spark.sql("DROP TABLE IF EXISTS newdata PURGE") spark.sql("CREATE TABLE newdata(id LONG) USING iceberg") spark.sql("INSERT INTO newdata VALUES 3, 4, 5, 6") spark.sql("SELECT * FROM newdata").show()El resultado es similar a lo siguiente:
+---+ | id| +---+ | 3| | 4| | 5| | 6| +---+Combina los datos nuevos en la tabla base.
spark.sql("""MERGE INTO base_table USING newdata ON base_table.id = newdata.id WHEN MATCHED THEN UPDATE SET base_table.id = newdata.id WHEN NOT MATCHED THEN INSERT * """) spark.sql("SELECT * FROM base_table").show()El resultado es similar a lo siguiente:
+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+Actualiza los registros de la tabla base.
spark.sql( "UPDATE base_table SET id = (id + 100) WHERE (id % 2 == 0)" ) spark.sql("SELECT * FROM base_table").show()El resultado es similar a lo siguiente:
+---+ | id| +---+ | 3| |104| | 5| |106| |100| |102| | 1| +---+Borra registros de la tabla base.
spark.sql("DELETE FROM base_table WHERE (id % 2 == 0)") spark.sql("SELECT * FROM base_table").show()El resultado es similar a lo siguiente:
+---+ | id| +---+ | 3| | 5| | 1| +---+
Cómo consultar una instantánea histórica
Recupera una versión anterior de una tabla consultando un ID de instantánea específico. Esta operación también se conoce como viaje en el tiempo.
Recupera el ID de la instantánea de la versión de la tabla antes de las operaciones
MERGE,UPDATEyDELETE.snapshot_ids = spark.sql( "SELECT snapshot_id FROM `NAMESPACE_NAME`.`base_table`.snapshots" ).collect() oldest_snapshot_id = snapshot_ids[1]["snapshot_id"]Reemplaza
NAMESPACE_NAMEpor el espacio de nombres que creaste.Consulta la tabla con el ID de instantánea recuperado.
df = ( spark.read.format("iceberg") .option("versionAsOf", oldest_snapshot_id) .load("base_table") ) df.show()El resultado muestra el estado de la tabla después de la operación
MERGE, pero antes de cualquier operaciónUPDATEoDELETE.+---+ | id| +---+ | 0| | 1| | 2| | 3| | 4| | 5| | 6| +---+
Descubre el linaje de datos
Puedes hacer un seguimiento del movimiento de datos entre las tablas del catálogo de Iceberg REST del catálogo del entorno de ejecución de Lakehouse con el linaje de datos, que está disponible en Managed Service para Apache Spark 2.2 y versiones de imágenes posteriores.
Ejemplo de linaje de datos
Crea tablas Iceberg de origen y destino, y luego copia los datos.
spark.sql("DROP TABLE IF EXISTS source_table PURGE") spark.sql("DROP TABLE IF EXISTS target_table PURGE") spark.sql("CREATE TABLE source_table (id LONG) USING iceberg") spark.sql("""CREATE TABLE target_table USING ICEBERG AS SELECT max(id) as top_id FROM source_table """)En la consola de Google Cloud , ve a la página Búsqueda de Knowledge Catalog.
Busca una de las tablas y, luego, haz clic en la pestaña
Lineage: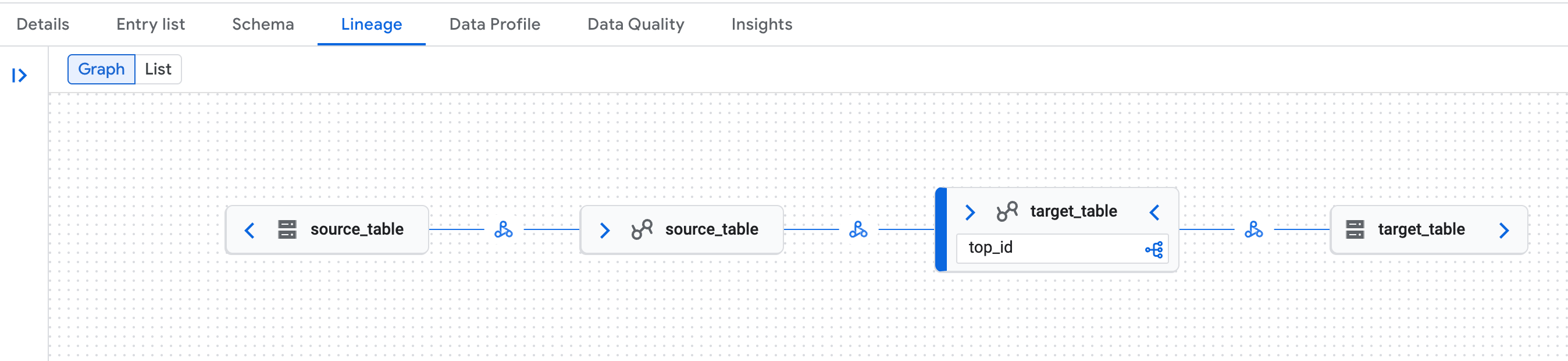
Ejemplo de un gráfico de linaje de datos en la página Knowledge Catalog de la consola de Google Cloud . El linaje de datos reconoce las representaciones lógicas (tabla del catálogo del entorno de ejecución de Lakehouse) y físicas (Cloud Storage) de las tablas del catálogo de REST de Iceberg del catálogo del entorno de ejecución de Lakehouse.
Problema conocido del linaje de datos
En algunos clústeres de Managed Service para Apache Spark, es posible que no se genere el linaje de datos completo debido a un problema de la biblioteca OpenLineage.
Solución alternativa: En la configuración de la sesión de Spark, establece la propiedad spark.sql.catalog.{catalog_name}.uri en https://biglake.googleapis.com/iceberg/v1beta/restcatalog.
¿Qué sigue?
- Obtén más información sobre el catálogo de tiempo de ejecución de Lakehouse, catálogo de REST de Iceberg.
- Explora las funciones de Apache Iceberg.
- Obtén información para consultar datos de Iceberg desde el catálogo de tiempo de ejecución de Lakehouse.
- Obtén más información sobre el linaje de datos y Managed Service para Apache Spark.