
本文列出常見的工作錯誤訊息,並提供工作監控和偵錯資訊,有助於排解 Dataproc 工作上的問題。
常見的工作錯誤訊息
未取得任務
這表示主要節點上的 Dataproc 代理程式無法從控制層取得任務。通常是由於記憶體不足 (OOM) 或網路問題所導致。若此工作原先能夠順利執行,且網路設定未曾變更,則最可能的原因是記憶體不足,通常是由於提交大量並行執行的工作,或是工作的驅動程式消耗大量記憶體所造成 (例如某些工作會將大型資料集載入記憶體)。
在主要節點上找不到啟用狀態的代理程式
這表示主要節點上的 Dataproc 代理程式尚未啟用,無法受理新工作,通常是由於記憶體不足 (OOM)、網路問題,或是主要節點 VM 狀況不佳所致。若此工作原先能夠順利執行,且網路設定未曾變更,則最可能的原因是記憶體不足,通常是由於提交大量並行執行的工作,或是工作的驅動程式消耗大量記憶體所造成 (會將大型資料集載入記憶體的工作)。
為解決這些問題,請嘗試執行下列動作:
- 重新啟動工作。
- 使用 SSH 連線至叢集主要執行個體節點,判斷哪個工作或其他資源使用最多記憶體。
如果無法登入主要節點,請檢查序列埠 (控制台) 記錄檔。

產生診斷套件,內含 syslog 和其他資料。
找不到任務
這個錯誤表示叢集在工作執行期間遭到刪除。您可以執行下列動作,識別出執行刪除作業的主體,並確認叢集是在工作執行期間遭到刪除:
查看 Dataproc 稽核記錄,識別出執行刪除作業的主體。
使用 Logging 或 gcloud CLI,確認 YARN 應用程式的最後已知狀態為 RUNNING (執行中):
- 在 Cloud Logging 中使用下列篩選條件:
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
- 執行
gcloud dataproc jobs describe job-id --region=REGION,然後檢查輸出內容中的yarnApplications: > STATE。
如果刪除叢集主體的帳戶是 Dataproc 服務代理服務帳戶,請檢查叢集所設定的自動刪除時間長度是否短於工作時間長度。
為避免發生 Task not found 錯誤,請使用自動化功能,確保叢集在所有執行中的工作完成之前,都不會遭到刪除。
裝置沒有足夠的空間
Dataproc 會將 HDFS 和暫存資料寫入磁碟。這則錯誤訊息表示叢集建立時並未配置足夠的磁碟空間。請採取下列步驟分析並避免此錯誤:
在 Google Cloud 控制台的「Cluster details」(叢集詳細資料) 頁面中,查看「Configuration」(設定) 分頁下方列出的叢集主要磁碟大小。對於使用
n1-standard-4機型的叢集,建議磁碟容量至少為1000 GB,而使用n1-standard-32機型的叢集至少應配置2 TB容量。如果叢集磁碟容量低於建議值,請重新建立叢集,並配置建議值以上的磁碟容量。
如果磁碟容量達到建議值以上,請使用 SSH 連線至叢集主 VM,然後在主 VM 上執行
df -h,檢查磁碟使用率,判斷是否需要額外磁碟空間。
工作監控和偵錯
使用 Google Cloud CLI、Dataproc REST API 和 Google Cloud 控制台對 Dataproc 工作進行分析及偵錯。
gcloud CLI
檢查執行中工作的狀態:
gcloud dataproc jobs describe job-id \ --region=region
如要查看工作驅動程式輸出內容,請參閱「查看工作輸出內容」。
REST API
呼叫 jobs.get 來檢查工作的 JobStatus.State、JobStatus.Substate、JobStatus.details,以及 YarnApplication 欄位。
控制台
如要查看工作驅動程式輸出內容,請參閱「查看工作輸出內容」。
如要查看 Logging 中的 Dataproc 代理程式記錄檔,請從 Logs Explorer 叢集選取器中,依序選取「Dataproc Cluster」(Dataproc 叢集) →「Cluster Name」(叢集名稱) →「Cluster UUID」(叢集 UUID)。
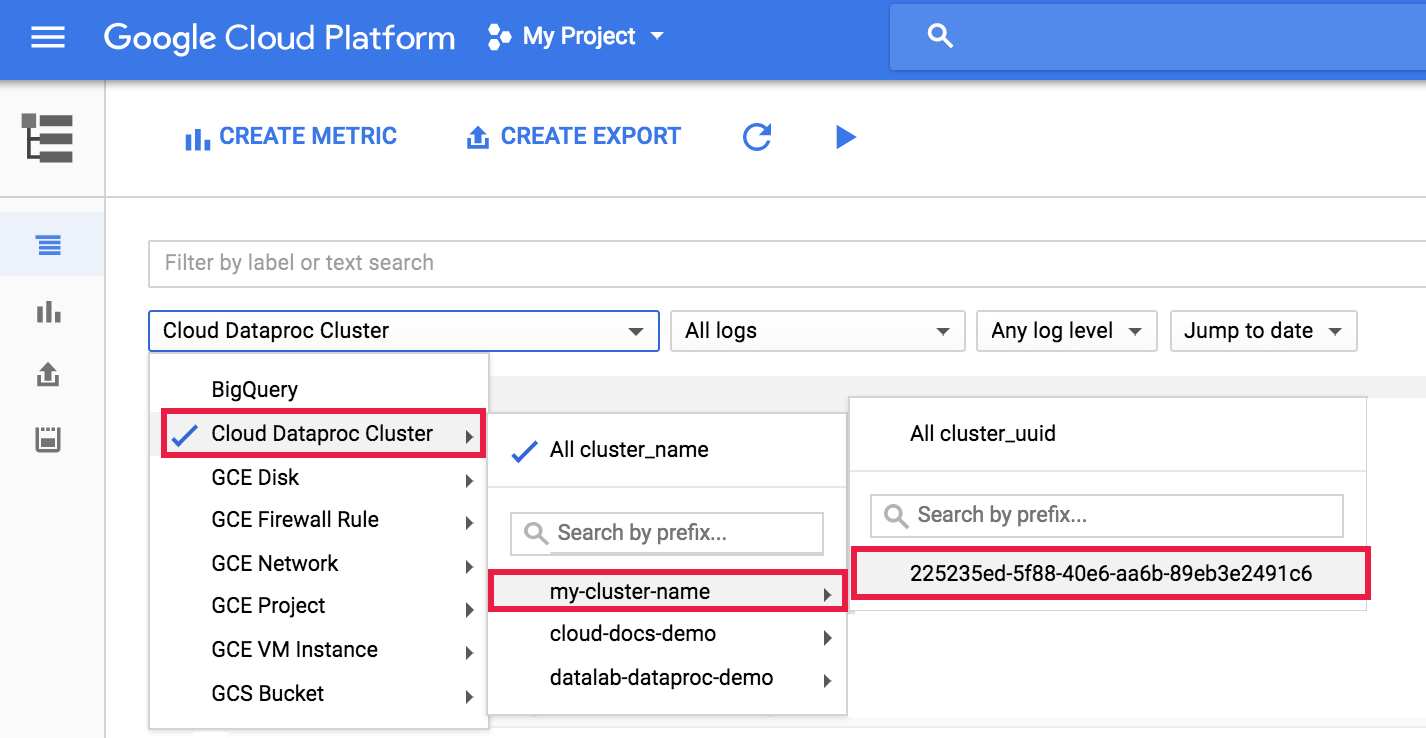
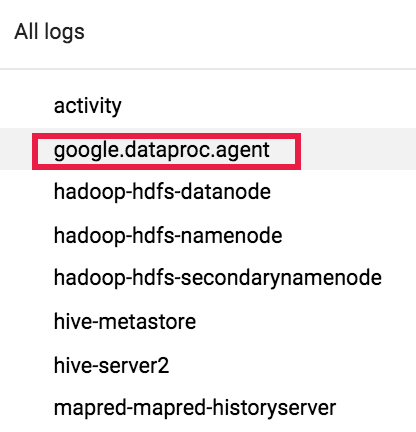
然後使用記錄選取器選取 google.dataproc.agent 記錄檔。
在 Logging 中查看工作記錄檔
如果工作失敗,您可以在 Logging 中存取工作記錄。
判斷工作提交者的身分
只需查詢工作的詳細資料,系統就會在 submittedBy 欄位中顯示提交該工作的使用者。例如,下列工作輸出內容顯示將範例工作提交到叢集的使用者是 user@domain。
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain