
Ringkasan
Dataproc Persistent History Server (PHS) menyediakan antarmuka web untuk melihat histori tugas yang dijalankan di cluster Dataproc yang aktif atau dihapus. Fitur ini tersedia di versi image 1.5 Dataproc dan yang lebih baru, serta berjalan di cluster Dataproc node tunggal. API ini menyediakan antarmuka web ke file dan data berikut:
File histori tugas MapReduce dan Spark
File histori tugas Flink (baca bagian Komponen Flink opsional Dataproc untuk membuat cluster Dataproc agar menjalankan tugas Flink)
File data Linimasa aplikasi yang dibuat oleh YARN Timeline Service v2 dan disimpan dalam instance Bigtable.
Log agregasi YARN
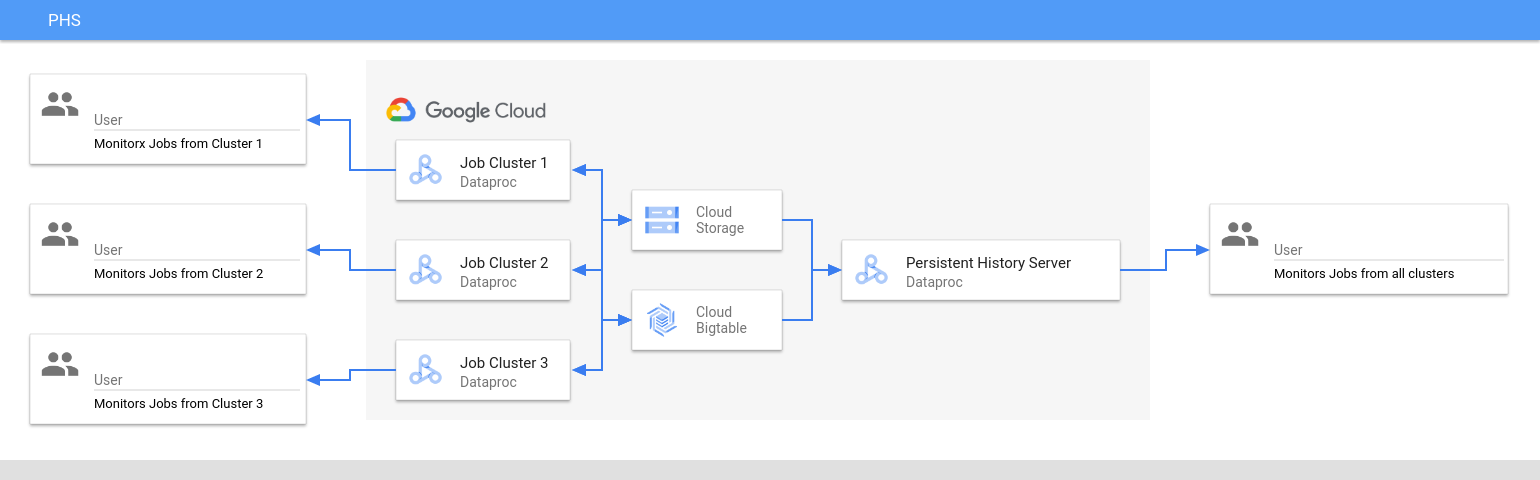
Persistent History Server mengakses dan menampilkan file histori tugas Spark dan MapReduce, file histori tugas Flink, serta file log YARN yang ditulis ke Cloud Storage selama masa aktif cluster tugas Dataproc.
Batasan
Versi image cluster PHS harus sama dengan versi image cluster tugas Dataproc. Misalnya, cluster PHS versi image 2.0 Dataproc hanya dapat digunakan untuk melihat file histori tugas dari tugas yang dijalankan di cluster tugas versi image 2.0 Dataproc yang berada dalam project yang sama dengan cluster PHS.
Cluster PHS tidak mendukung Kerberos dan Autentikasi Pribadi.
Membuat cluster PHS Dataproc
Anda dapat menjalankan perintah
gcloud dataproc clusters create
berikut di terminal lokal atau di
Cloud Shell dengan flag dan
properti cluster
berikut untuk membuat cluster node tunggal Dataproc Persistent History Server.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: Tentukan nama cluster PHS.
- PROJECT: Tentukan project yang akan dikaitkan dengan cluster PHS. Project ini harus sama dengan project yang digunakan oleh cluster yang menjalankan tugas Anda (baca bagian Membuat cluster tugas Dataproc).
- REGION: Tentukan region Compute Engine tempat cluster PHS akan berada.
--single-node: Cluster PHS adalah cluster node tunggal Dataproc.--enable-component-gateway: Flag ini mengaktifkan antarmuka web Component Gateway di cluster PHS.- COMPONENT: Gunakan flag ini untuk menginstal satu atau beberapa
komponen opsional
di cluster. Anda harus menentukan komponen opsional
FLINKuntuk menjalankan Layanan Web Flink HistoryServer di cluster PHS untuk melihat file histori tugas Flink. - PROPERTIES. Tentukan satu atau beberapa properti cluster.
Jika perlu, tambahkan flag --image-version untuk menentukan versi image cluster PHS. Versi image PHS harus sama dengan versi image cluster tugas Dataproc. Lihat Batasan.
Catatan:
- Contoh nilai properti di bagian ini menggunakan karakter pengganti "*" agar PHS dapat mencocokkan beberapa direktori dalam bucket yang ditentukan dan ditulis oleh cluster tugas yang berbeda (baca bagian Pertimbangan efisiensi karakter pengganti).
- Pada contoh berikut, flag
--propertiesditampilkan secara terpisah untuk memudahkan keterbacaan. Praktik yang direkomendasikan saat menggunakangcloud dataproc clusters createuntuk membuat cluster Dataproc di Compute Engine adalah menggunakan satu flag--propertiesuntuk menentukan daftar properti yang dipisahkan koma (baca bagian pemformatan properti cluster).
Properti:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: Tambahkan properti ini untuk menentukan lokasi Cloud Storage tempat PHS akan mengakses log YARN yang ditulis oleh cluster tugas.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: Tambahkan properti ini untuk mengaktifkan histori tugas Spark persisten. Properti ini menentukan lokasi tempat PHS akan mengakses log histori tugas Spark yang ditulis oleh cluster tugas.Di cluster Dataproc 2.0+, dua properti berikut juga harus disetel untuk mengaktifkan log histori Spark PHS (baca bagian Opsi Konfigurasi Spark History Server). Nilai
spark.history.custom.executor.log.urladalah nilai literal yang berisi {{PLACEHOLDER}} untuk variabel yang akan ditetapkan oleh Persistent History Server. Variabel ini tidak ditetapkan oleh pengguna. Gunakan nilai properti seperti yang ditampilkan.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: Tambahkan properti ini untuk mengaktifkan histori tugas MapReduce persisten. Properti ini menentukan lokasi Cloud Storage tempat PHS akan mengakses log histori tugas MapReduce yang ditulis oleh cluster tugas.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: Setelah Anda Mengonfigurasi Yarn Timeline Service v2, tambahkan properti ini untuk menggunakan cluster PHS guna melihat data linimasa di antarmuka web YARN Application Timeline Service V2 dan Tez (baca bagian Antarmuka web Component Gateway).flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: Gunakan properti ini untuk mengonfigurasiHistoryServerFlink guna memantau comma separated list direktori.
Contoh properti:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Membuat cluster tugas Dataproc
Anda dapat menjalankan perintah berikut di terminal lokal atau di Cloud Shell untuk membuat cluster tugas Dataproc yang menjalankan tugas dan menulis file histori tugas ke Persistent History Server (PHS).
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: Tentukan nama cluster tugas.
- PROJECT: Tentukan project yang terkait dengan cluster tugas.
- REGION: Tentukan region Compute Engine tempat cluster tugas akan berada.
--enable-component-gateway: Flag ini akan mengaktifkan antarmuka web Component Gateway di cluster tugas.- COMPONENT: Gunakan flag ini untuk menginstal satu atau beberapa
komponen opsional
di cluster. Tentukan komponen opsional
FLINKuntuk menjalankan tugas Flink di cluster. PROPERTIES: Tambahkan satu atau beberapa properti cluster berikut untuk menetapkan lokasi Cloud Storage non-default yang terkait dengan PHS dan properti cluster tugas lainnya.
Catatan:
- Contoh nilai properti di bagian ini menggunakan karakter pengganti "*" agar PHS dapat mencocokkan beberapa direktori dalam bucket yang ditentukan dan ditulis oleh cluster tugas yang berbeda (baca bagian Pertimbangan efisiensi karakter pengganti).
- Pada contoh berikut, flag
--propertiesditampilkan secara terpisah untuk memudahkan keterbacaan. Praktik yang direkomendasikan saat menggunakangcloud dataproc clusters createuntuk membuat cluster Dataproc di Compute Engine adalah menggunakan satu flag--propertiesuntuk menentukan daftar properti yang dipisahkan koma (baca bagian pemformatan properti cluster).
Properti:
yarn:yarn.nodemanager.remote-app-log-dir: Secara default, log agregasi YARN diaktifkan di cluster tugas Dataproc dan ditulis ke temp bucket cluster. Tambahkan properti ini untuk menentukan lokasi Cloud Storage lain tempat cluster akan menulis log agregasi agar dapat diakses oleh Persistent History Server.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectorydanspark:spark.eventLog.dir: Secara default, file histori tugas Spark disimpan di clustertemp bucketdi direktori/spark-job-history. Anda dapat menambahkan properti ini untuk menentukan lokasi Cloud Storage yang berbeda untuk file ini. Jika kedua properti digunakan, keduanya harus mengarah ke direktori dalam bucket yang sama.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-dirdanmapred:mapreduce.jobhistory.intermediate-done-dir: Secara default, file histori tugas MapReduce disimpan di clustertemp bucketdi direktori/mapreduce-job-history/donedan/mapreduce-job-history/intermediate-done. Lokasi perantaramapreduce.jobhistory.intermediate-done-dirdigunakan sebagai penyimpanan sementara. File perantara akan dipindahkan ke lokasimapreduce.jobhistory.done-dirsetelah tugas MapReduce selesai. Anda dapat menambahkan properti ini untuk menentukan lokasi Cloud Storage yang berbeda untuk file ini. Jika kedua properti digunakan, keduanya harus mengarah ke direktori dalam bucket yang sama.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type: Properti ini berlaku untuk cluster dengan versi image2.0dan2.1yang menggunakan Cloud Storage connector versi2.0.x(versi konektor default untuk cluster dengan versi image2.0dan2.1). Properti ini mengontrol cara tugas Spark mengirim data ke Cloud Storage. Setelan defaultnya adalahBASIC, yang mengirim data ke Cloud Storage setelah tugas selesai. Jika disetel keFLUSHABLE_COMPOSITE, data akan disalin ke Cloud Storage secara berkala saat tugas berjalan seperti yang ditetapkan olehspark:spark.history.fs.gs.outputstream.sync.min.interval.ms.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: Properti ini berlaku untuk cluster dengan versi image2.0dan2.1yang menggunakan Cloud Storage connector versi2.0.x(versi konektor default untuk cluster dengan versi image2.0dan2.1). Parameter ini mengontrol frekuensi dalam milidetik saat data ditransfer ke Cloud Storage saatspark:spark.history.fs.gs.outputstream.typedisetel keFLUSHABLE_COMPOSITE. Interval waktu default adalah5000ms. Nilai interval waktu milidetik dapat ditentukan dengan atau tanpa menambahkan akhiranms.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval: Properti ini berlaku untuk cluster dengan image versi2.2dan yang lebih baru yang menggunakan Cloud Storage connector versi3.0.x(versi konektor default untuk cluster dengan image versi2.2). Properti ini menggantikan propertispark:spark.history.fs.gs.outputstream.sync.min.interval.mssebelumnya, dan mendukung nilai dengan sufiks waktu, sepertims,s, danm. Parameter ini mengontrol frekuensi transfer data ke Cloud Storage saatspark:spark.history.fs.gs.outputstream.typedisetel keFLUSHABLE_COMPOSITE.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance: Setelah Anda Mengonfigurasi Yarn Timeline Service v2, tambahkan properti ini untuk menulis data linimasa YARN ke instance Bigtable yang ditentukan agar dapat ditampilkan di antarmuka web YARN Application Timeline Service V2 dan Tez pada cluster PHS. Catatan: pembuatan cluster akan gagal jika instance Bigtable tidak ada.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: Flink JobManager mengarsipkan tugas Flink yang telah selesai dengan mengupload informasi tugas yang diarsipkan ke direktori sistem file. Gunakan properti ini untuk menetapkan direktori arsip diflink-conf.yaml.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Menggunakan PHS dengan workload batch Spark
Untuk menggunakan Persistent History Server dengan Dataproc Serverless untuk workload batch Spark:
Pilih atau tentukan cluster PHS saat Anda mengirimkan workload batch Spark.
Menggunakan PHS dengan Dataproc di Google Kubernetes Engine
Untuk menggunakan Persistent History Server dengan Dataproc di GKE:
Pilih atau tentukan cluster PHS saat Anda membuat cluster virtual Dataproc di GKE.
Antarmuka web Component Gateway
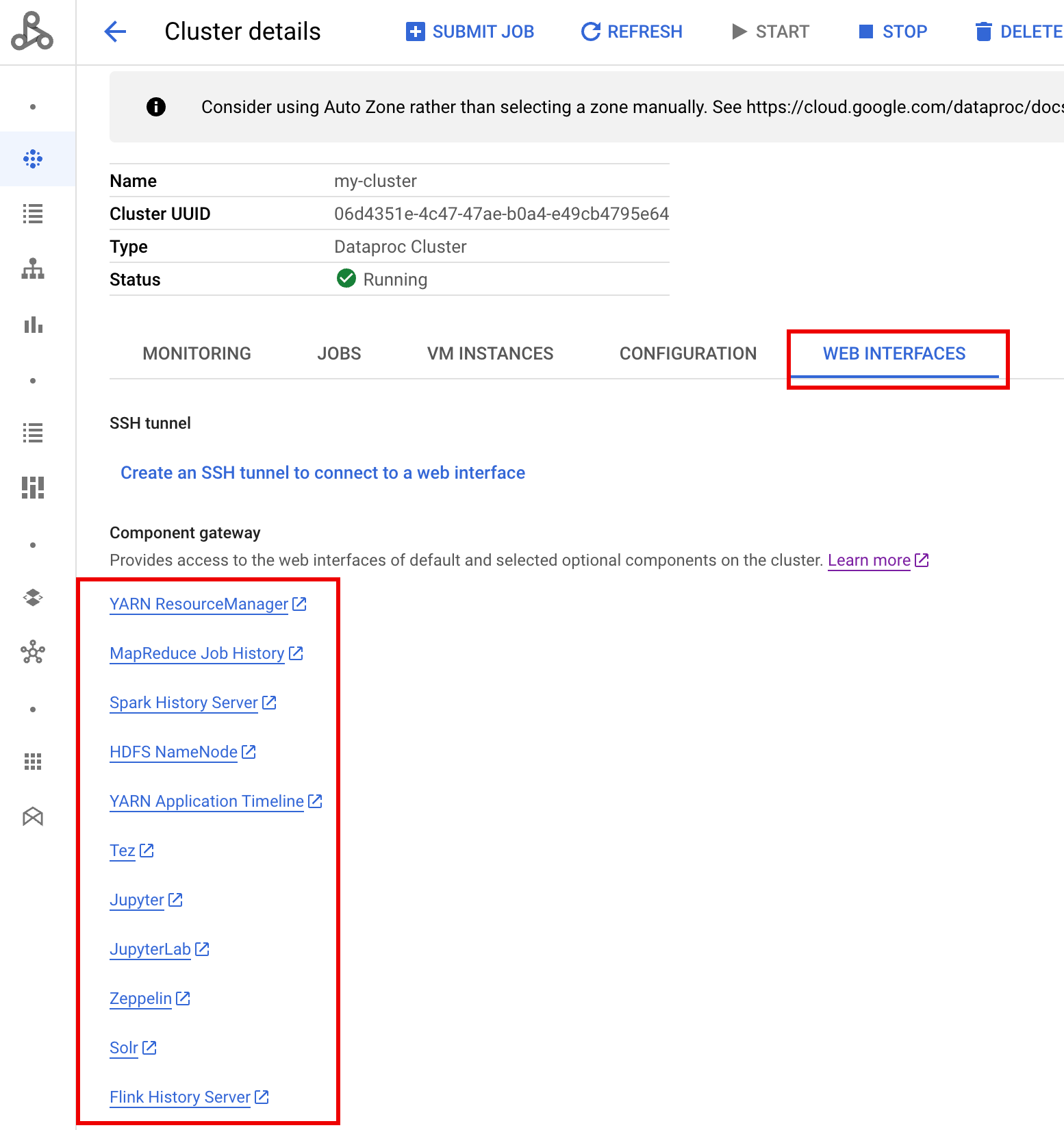
Di konsol Google Cloud , dari halaman Clusters Dataproc, klik nama cluster PHS untuk membuka halaman Cluster details. Di tab Web Interfaces, pilih link Component gateway untuk membuka antarmuka web yang berjalan di cluster PHS.
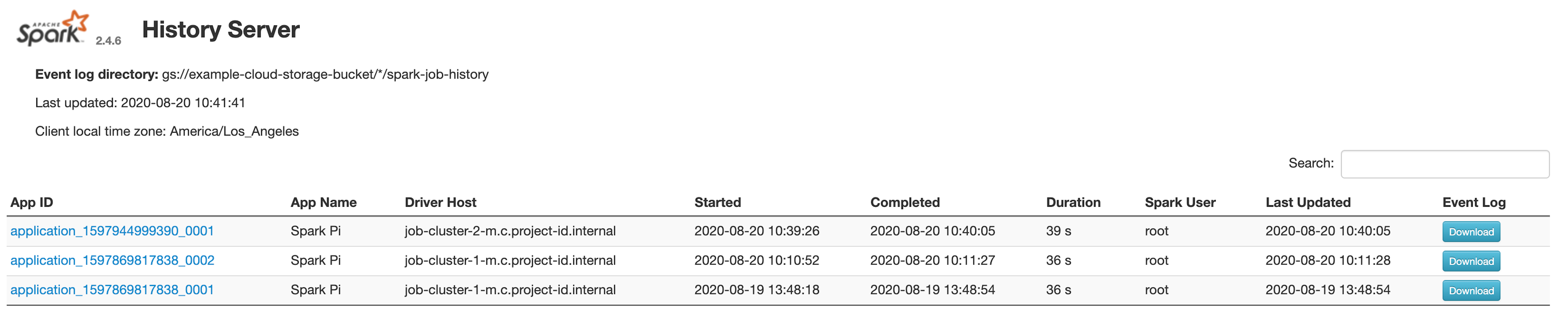
Antarmuka web Spark History Server
Screenshot berikut menunjukkan antarmuka web Spark History Server yang menampilkan link
ke tugas Spark yang dijalankan di job-cluster-1 dan job-cluster-2 setelah menyiapkan
lokasi spark.history.fs.logDirectory dan spark:spark.eventLog.dir cluster tugas
dan spark.history.fs.logDirectory cluster PHS sebagai berikut:
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |
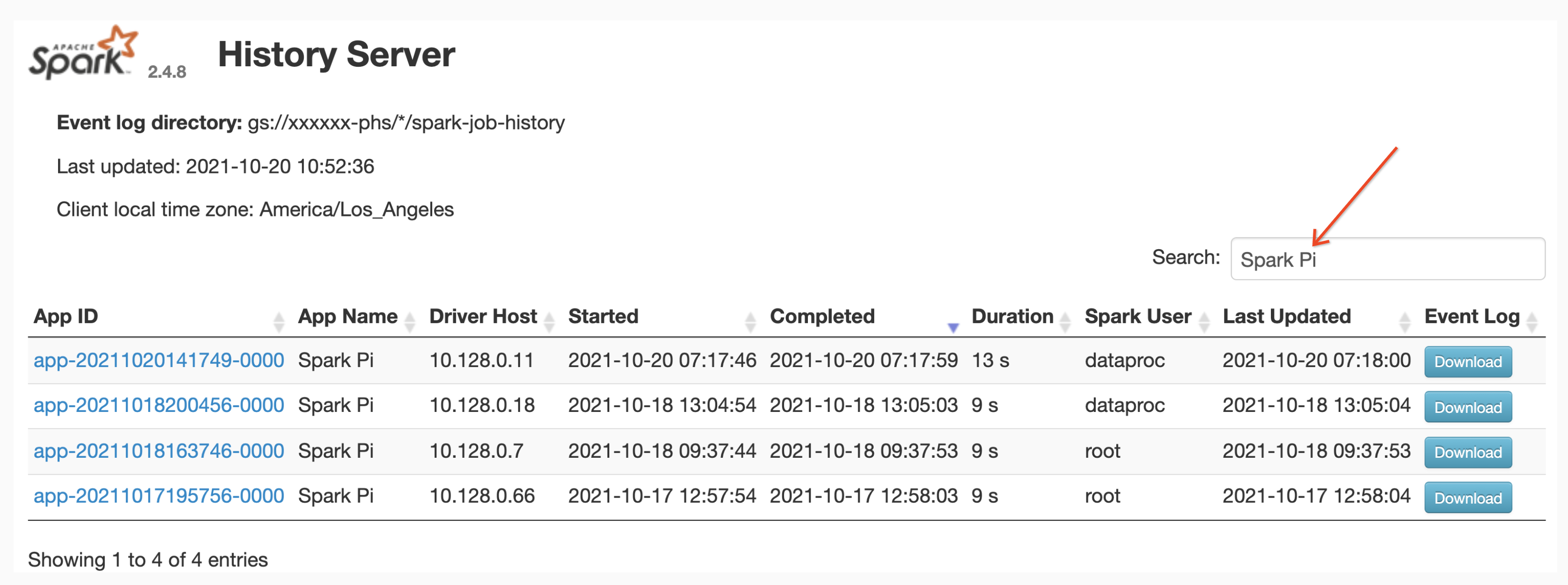
Penelusuran nama aplikasi
Anda dapat mencantumkan tugas berdasarkan Nama Aplikasi di antarmuka web Spark History Server dengan memasukkan nama aplikasi di kotak penelusuran. Nama aplikasi dapat ditetapkan dengan salah satu cara berikut (dicantumkan berdasarkan prioritas):
- Ditetapkan di dalam kode aplikasi saat membuat konteks spark
- Ditetapkan oleh properti spark.app.name saat tugas dikirimkan
- Ditetapkan oleh Dataproc sebagai nama resource REST lengkap untuk
tugas (
projects/project-id/regions/region/jobs/job-id)
Pengguna dapat memasukkan istilah nama aplikasi atau resource di kotak Penelusuran untuk menemukan dan mencantumkan tugas.
Log aktivitas
Antarmuka web Spark History Server menyediakan tombol Event Log yang dapat Anda klik untuk mendownload log peristiwa Spark. Log ini berguna untuk memeriksa siklus proses aplikasi Spark.
Tugas Spark
Aplikasi Spark dibagi menjadi beberapa tugas, yang selanjutnya dibagi lagi menjadi beberapa tahap. Tiap tahap dapat memiliki beberapa tugas, yang dijalankan di node executor (worker).
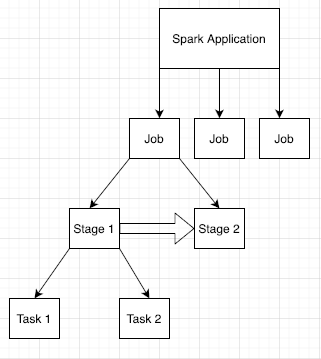
Klik Spark App ID di antarmuka web untuk membuka halaman Spark Jobs, yang menampilkan linimasa peristiwa dan ringkasan tugas dalam aplikasi.
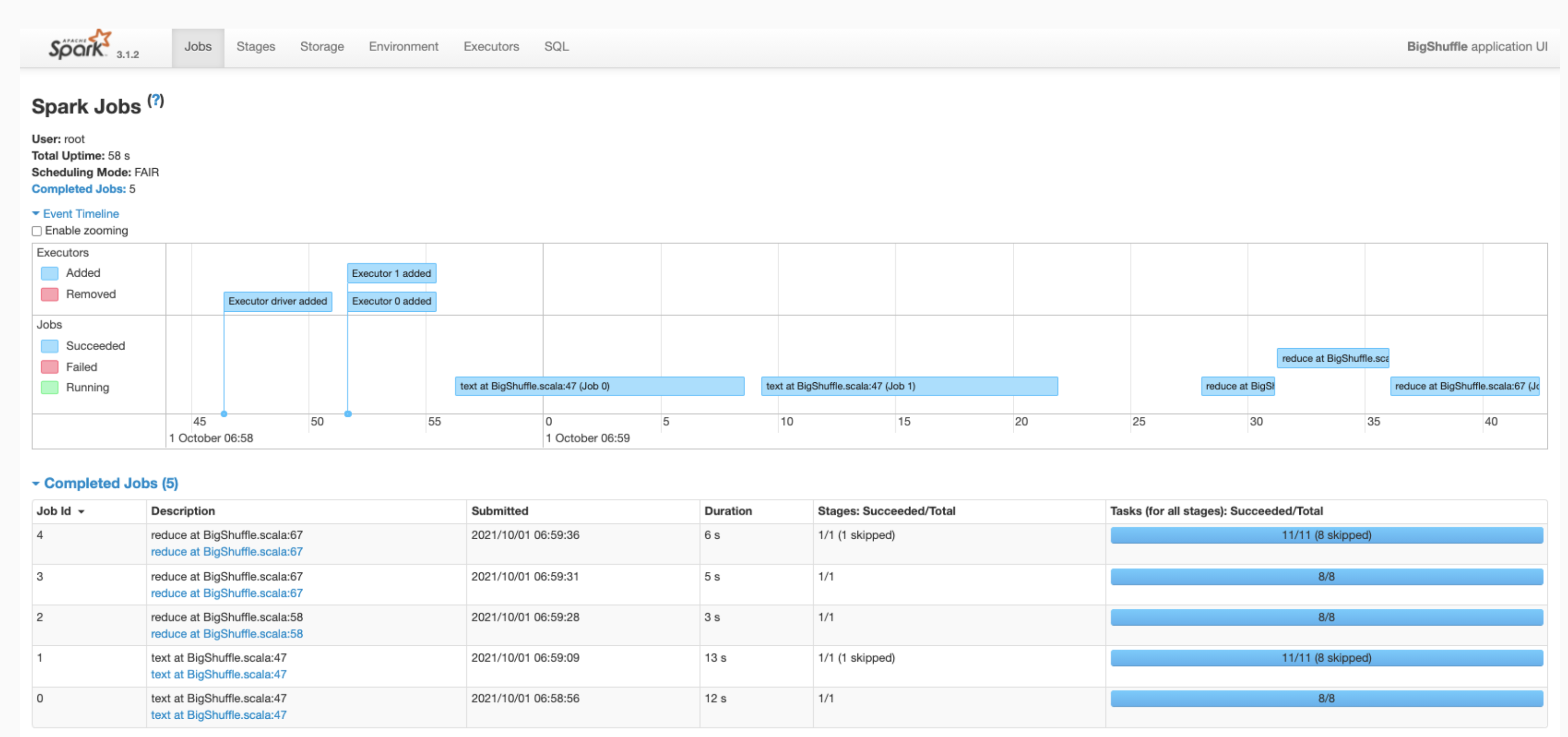
Klik sebuah tugas untuk membuka halaman Job Details dengan Directed Acyclic Graph (DAG) dan ringkasan tahap dalam tugas.
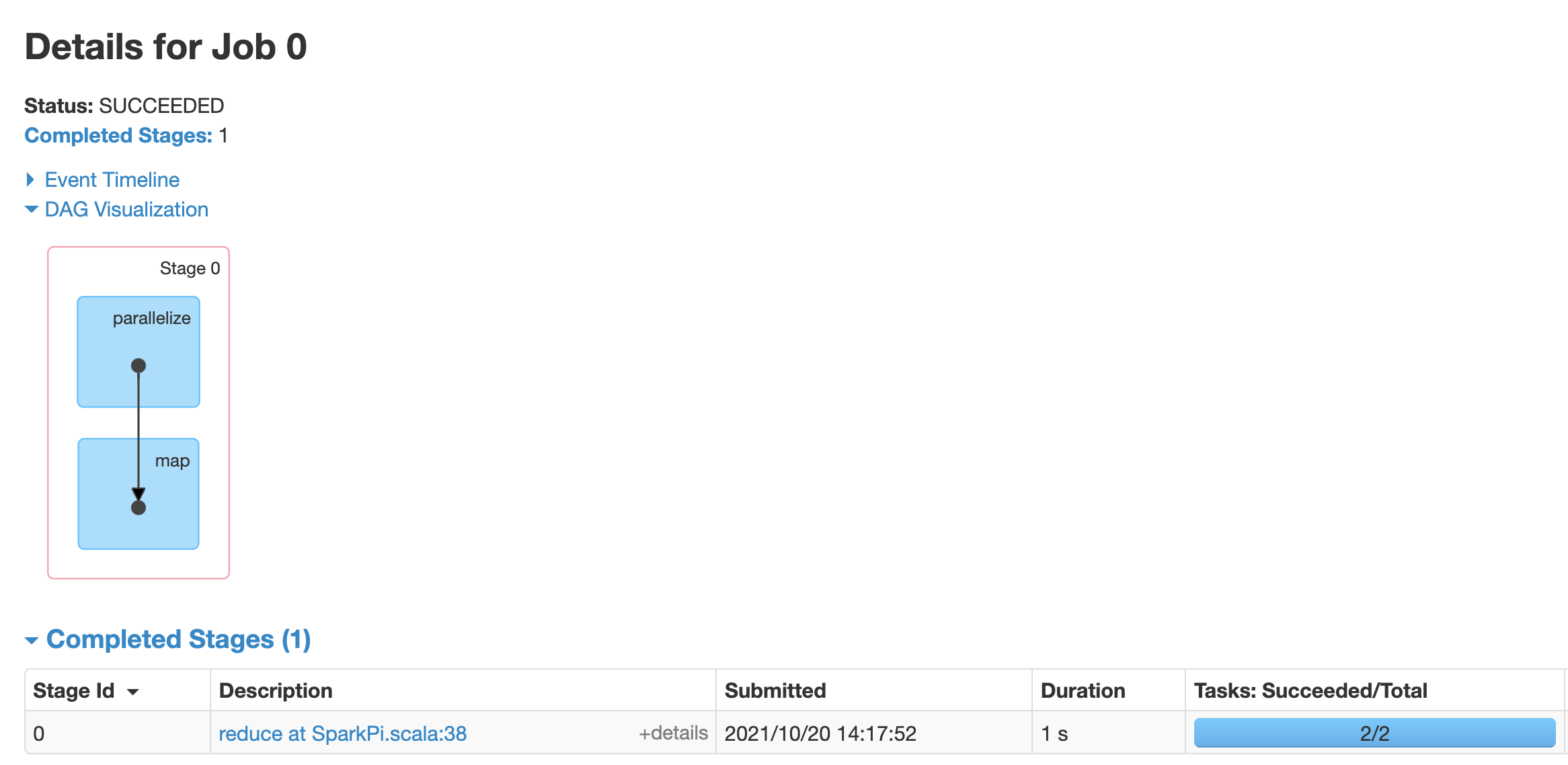
Klik sebuah tahap atau gunakan tab Stages untuk memilih tahap dan membuka halaman Stage Details
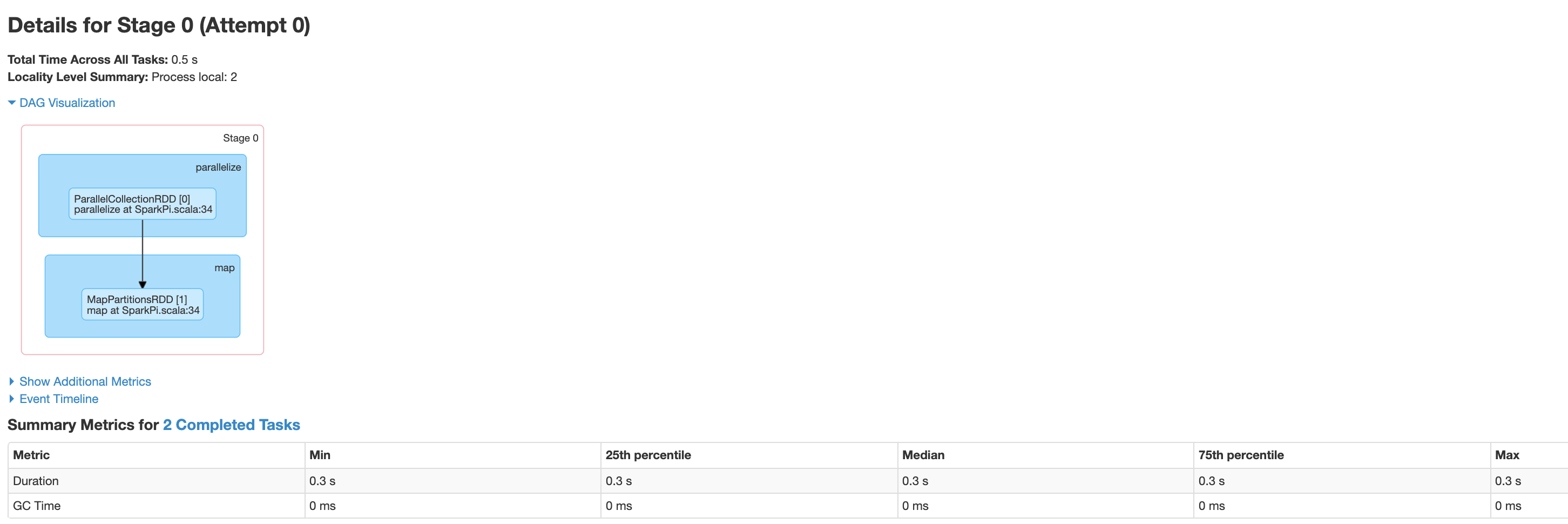
Halaman Stage Details memuat visualisasi DAG, linimasa peristiwa, dan metrik untuk tugas dalam tahap. Anda dapat menggunakan halaman ini untuk memecahkan masalah terkait tugas yang dibatasi, penundaan scheduler, dan error kehabisan memori. Visualisasi DAG menampilkan baris kode asal tahap, sehingga membantu Anda melacak masalah kembali ke kode sumber.
Klik tab Executors untuk mengetahui informasi tentang node driver dan executor aplikasi Spark.
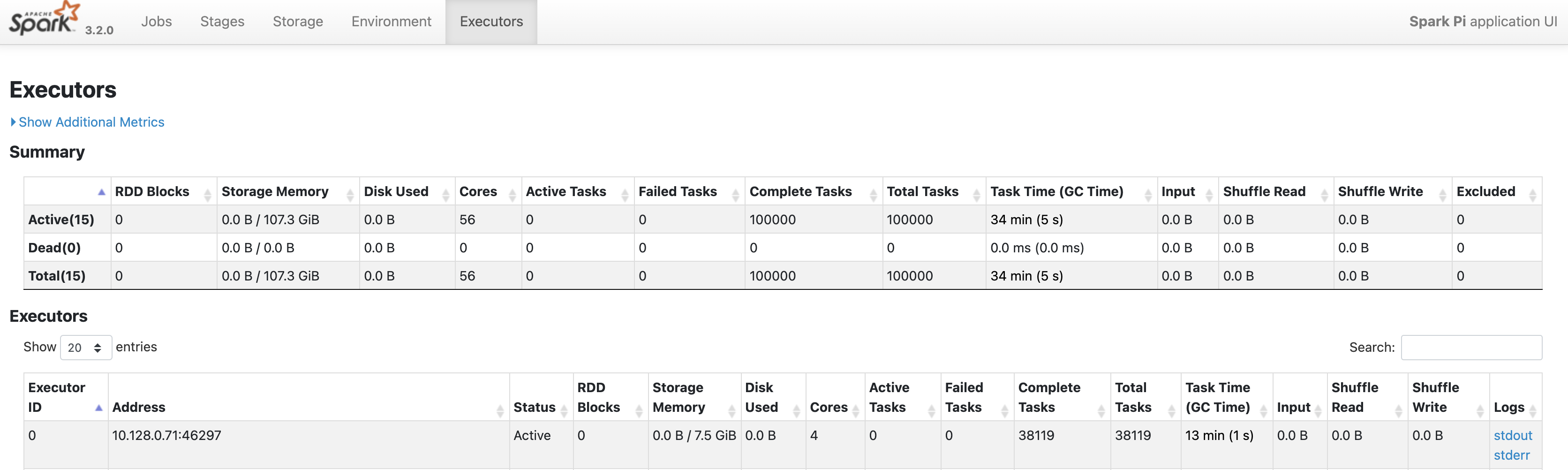
Informasi penting di halaman ini mencakup jumlah core dan jumlah tugas yang dijalankan di tiap executor.
Antarmuka web Tez
Tez adalah engine eksekusi default untuk Hive dan Pig di Dataproc. Mengirimkan tugas Hive di cluster tugas Dataproc akan meluncurkan aplikasi Tez.
Jika Anda mengonfigurasi Yarn Timeline Service v2 dan menetapkan properti dataproc:yarn.atsv2.bigtable.instance saat membuat cluster PHS dan cluster tugas Dataproc, YARN akan menulis
data linimasa tugas Hive dan Pig yang dihasilkan ke instance Bigtable
yang ditentukan untuk diambil dan ditampilkan di antarmuka web Tez yang berjalan
di server PHS.

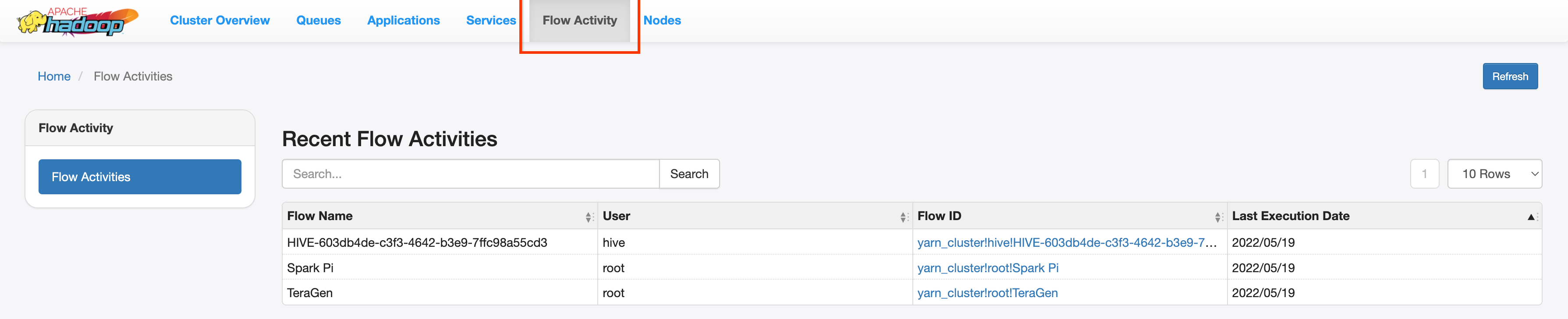
Antarmuka web YARN Application Timeline V2
Jika Anda mengonfigurasi Yarn Timeline Service v2
dan menetapkan properti dataproc:yarn.atsv2.bigtable.instance saat Anda
membuat cluster PHS dan cluster tugas Dataproc, YARN akan menulis
data linimasa tugas yang dihasilkan ke instance Bigtable yang ditentukan untuk diambil dan
ditampilkan di antarmuka web YARN Application Timeline Service yang berjalan di
server PHS. Tugas Dataproc dicantumkan di tab Flow Activity
di antarmuka web.
Mengonfigurasi Yarn Timeline Service v2
Untuk mengonfigurasi Yarn Timeline Service v2, siapkan instance Bigtable dan, jika diperlukan, periksa peran akun layanan, sebagai berikut:
Periksa peran akun layanan, jika diperlukan. Akun layanan VM default yang digunakan oleh VM cluster Dataproc memiliki izin yang diperlukan untuk membuat dan mengonfigurasi instance Bigtable untuk YARN Timeline Service. Jika Anda membuat tugas atau cluster PHS dengan akun layanan VM kustom, akun tersebut harus memiliki peran Bigtable
AdministratoratauBigtable User.
Skema tabel yang diperlukan
Dukungan PHS Dataproc untuk
YARN Timeline Service v2
memerlukan skema tertentu yang dibuat di
instance Bigtable. Dataproc membuat skema
yang diperlukan saat cluster tugas atau cluster PHS dibuat dengan
properti dataproc:yarn.atsv2.bigtable.instance yang ditetapkan untuk mengarah ke
instance Bigtable.
Berikut adalah skema instance Bigtable yang diperlukan:
| Tabel | Grup kolom |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Pembersihan sampah memori Bigtable
Anda dapat mengonfigurasi Pembersihan Sampah Memori Bigtable berbasis usia untuk tabel ATSv2:
Instal cbt, (termasuk pembuatan
.cbrtc file).Buat kebijakan pembersihan sampah memori berbasis usia ATSv2:
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
Catatan:
NUMBER_OF_DAYS: Jumlah hari maksimum adalah 30d.