
本文档介绍了可用于监控和排查 Serverless for Apache Spark 批量工作负载问题的工具和文件。
通过 Google Cloud 控制台排查工作负载问题
当批量作业失败或性能不佳时,建议您首先打开 其批次详情页面,然后从控制台的批次 页面打开。 Google Cloud
使用“摘要”标签页:您的故障排查中心
批次详情 页面 打开后,系统默认选择摘要 标签页,该标签页会显示关键指标和经过过滤的日志,帮助您快速 初步评估批次的运行状况。完成初步评估后,您可以使用 批次详情页面中提供的更专业的工具(例如 Spark 界面、Logs Explorer 和 Gemini Cloud Assist)执行更深入的分析。
批量指标亮点
批次详情 页面上的摘要 标签页包含显示 重要批量工作负载指标值的图表。指标图表会在 完成后填充,并直观地指示潜在问题,例如资源 争用、数据倾斜或内存压力。

下表列出了控制台的 Google Cloud 批次详情 页面上显示的 Spark 工作负载指标,并介绍了指标 值如何提供对工作负载状态和性能的洞见。
| 指标 | 所显示的信息 |
|---|---|
| 执行程序级指标 | |
| JVM GC 时间与运行时之比 | 此指标显示每个执行程序的 JVM GC(垃圾回收)时间与运行时之比。比率较高可能表示在特定执行程序上运行的任务中存在内存泄漏或数据结构效率低下,这可能会导致对象流失率较高。 |
| 溢出的磁盘字节数 | 此指标显示不同执行程序中溢出的磁盘字节总数。如果某个执行程序显示溢出的磁盘字节数较高,则可能表示存在数据倾斜。如果该指标随时间推移而增加,则可能表示存在内存压力或内存泄漏的阶段。 |
| 读取和写入的字节数 | 此指标显示每个执行程序写入的字节数与读取的字节数。读取或写入的字节数存在较大差异可能表示存在以下情况:复制的联接会导致特定执行程序上的数据放大。 |
| 读取和写入的记录数 | 此指标显示每个执行程序读取和写入的记录数。读取的记录数较多但写入的记录数较少可能表示特定执行程序上的处理逻辑存在瓶颈,导致记录在等待时被读取。读取和写入始终滞后的执行程序可能表示这些节点上存在资源争用,或者执行程序专用代码效率低下。 |
| Shuffle 写入时间与运行时之比 | 该指标显示执行程序在 Shuffle 运行时花费的时间与总运行时之比。如果某些执行程序的此值较高,则可能表示存在数据倾斜或数据序列化效率低下。 您可以在 Spark 界面中识别 Shuffle 写入时间较长的阶段。在这些阶段中查找完成时间超过平均值的离群任务。检查 Shuffle 写入时间较长的执行程序是否也显示较高的磁盘 I/O 活动。更高效的序列化和额外的分区步骤可能会有所帮助。与记录读取相比,记录写入非常多可能表示由于联接效率低下或转换不正确而导致意外的数据重复。 |
| 应用级指标 | |
| 阶段进程 | 此指标显示失败、等待和运行阶段中的阶段数。失败或等待阶段的数量较多可能表示存在数据倾斜。检查数据分区,并使用 Spark 界面中的阶段 标签页调试阶段失败的原因。 |
| 批量 Spark 执行程序 | 此指标显示可能需要的执行程序数量与 正在运行的执行程序数量。所需执行程序与正在运行的执行程序之间存在较大差异 可能表示存在自动扩缩问题。 |
| 虚拟机级指标 | |
| 使用的内存 | 此指标显示正在使用的虚拟机内存百分比。如果主实例百分比很高,则可能表示驱动程序存在内存压力。对于其他虚拟机节点,百分比很高可能表示执行程序内存不足,这可能会导致磁盘溢出较多,工作负载运行时速度较慢。使用 Spark 界面分析执行程序,以检查 GC 时间是否较长以及任务失败次数是否较多。此外,还要调试 Spark 代码,以了解是否存在大型数据集缓存和不必要的变量广播。 |
作业日志
批次详情 页面包含作业日志 部分,其中列出了从作业(批量工作负载)日志中过滤出的警告和错误。借助此功能,您可以快速识别关键问题,而无需手动解析大量日志文件。您可以从下拉菜单中选择日志严重程度 (例如 Error),并添加文本过滤条件 以缩小结果范围。如需执行更深入的分析,请点击 在 Logs Explorer 中查看 图标
,以在 Logs Explorer 中打开所选的批量日志。
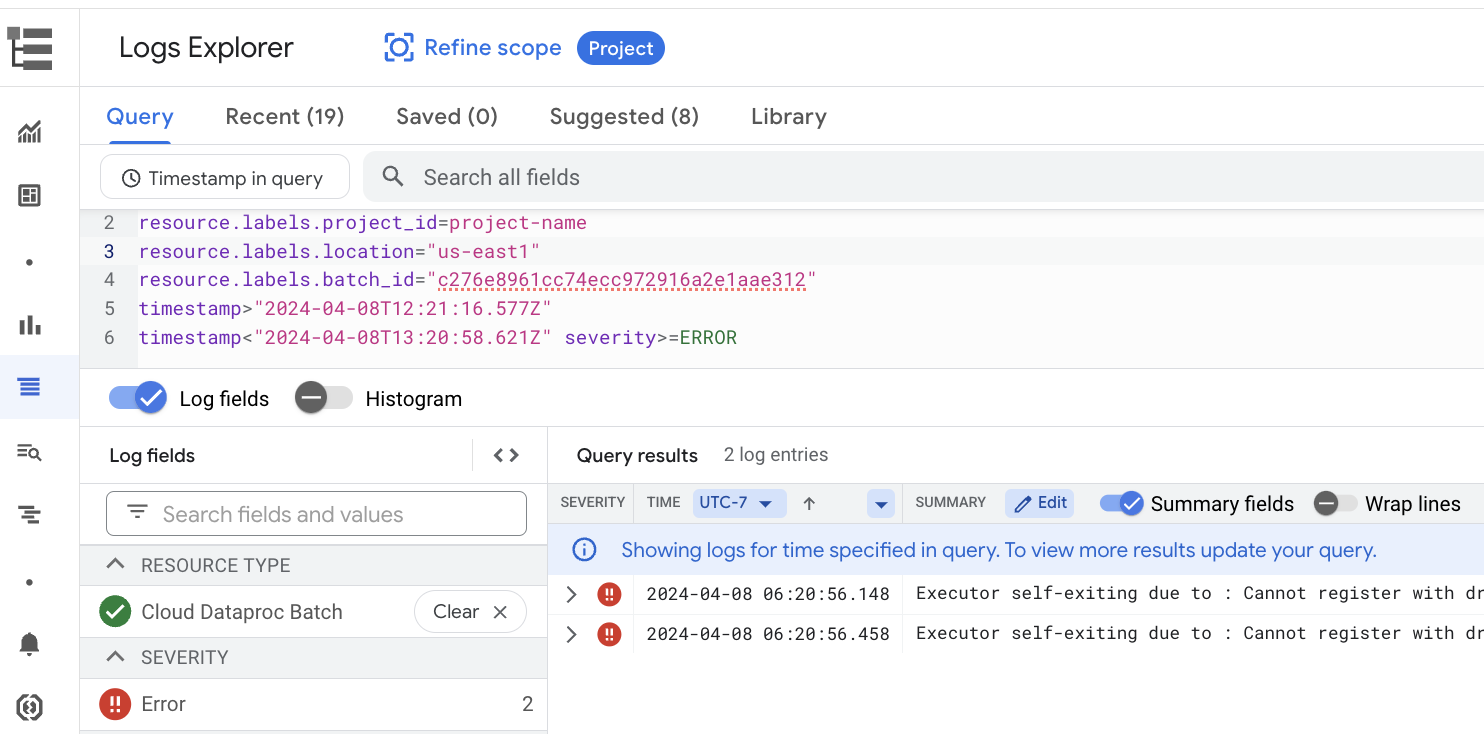
示例:在控制台的批次详情 页面上从“严重程度”
选择器中选择 Errors 后,Logs Explorer 会打开。 Google Cloud
Spark 界面
Spark 界面从 Serverless for Apache Spark 批量工作负载收集 Apache Spark 执行详情。Spark 界面功能免费提供,默认处于 启用状态。
Spark 界面功能收集的数据会保留 90 天。您可以使用此 网页界面监控和调试 Spark 工作负载,而无需创建 Persistent History Server。
所需的 Identity and Access Management 权限和角色
如需将 Spark 界面功能与批量 工作负载搭配使用,您需要具备以下权限。
数据收集权限:
dataproc.batches.sparkApplicationWrite。必须向运行批量工作负载的服务账号授予此 权限。 此权限包含在Dataproc Worker角色中,该角色会自动授予 Serverless for Apache Spark 默认使用的 Compute Engine 默认服务账号 (请参阅 Serverless for Apache Spark 服务账号)。 但是,如果您为批量工作负载指定 自定义服务账号 ,则必须向该服务账号添加dataproc.batches.sparkApplicationWrite权限(通常是通过向该服务账号授予 DataprocWorker角色)。Spark 界面访问权限:
dataproc.batches.sparkApplicationRead。必须向用户授予此 权限,才能在 Google Cloud 控制台中访问 Spark 界面。此权限包含在Dataproc Viewer、Dataproc Editor和Dataproc Administrator角色中。如需在 Google Cloud 控制台中打开 Spark 界面,您必须拥有 其中一个角色,或者拥有包含此权限的自定义角色。
打开 Spark 界面
Spark 界面页面位于 Google Cloud 控制台批量工作负载中。
前往 Serverless for Apache Spark 交互式会话 页面。
点击批次 ID 以打开批次详情 页面。
点击顶部菜单中的查看 Spark 界面 。
在以下情况下,查看 Spark 界面 按钮处于停用状态:
- 如果未授予所需权限
- 如果您在批次详情 页面上清除启用 Spark 界面 复选框
- 如果您在
提交批量工作负载时将
spark.dataproc.appContext.enabled属性设置为false
Serverless for Apache Spark 日志
Serverless for Apache Spark 中默认启用日志记录,工作负载日志会在工作负载完成后保留。Serverless for Apache Spark 在 Cloud Logging 中收集工作负载日志。
您可以在 Logs Explorer 的
Cloud Dataproc Batch 资源下访问 Serverless for Apache Spark 日志。
查询 Serverless for Apache Spark 日志
控制台中的 Logs Explorer 提供了一个查询窗格,可帮助您构建查询来检查批量工作负载日志。 Google Cloud 您可以按照以下步骤构建查询来检查批量工作负载 日志:
- 系统会选择您当前的项目。您可以点击优化范围项目 以 选择其他项目。
定义批量日志查询。
使用过滤条件菜单 过滤批量工作负载。
在所有资源下,选择Cloud Dataproc 批次资源。
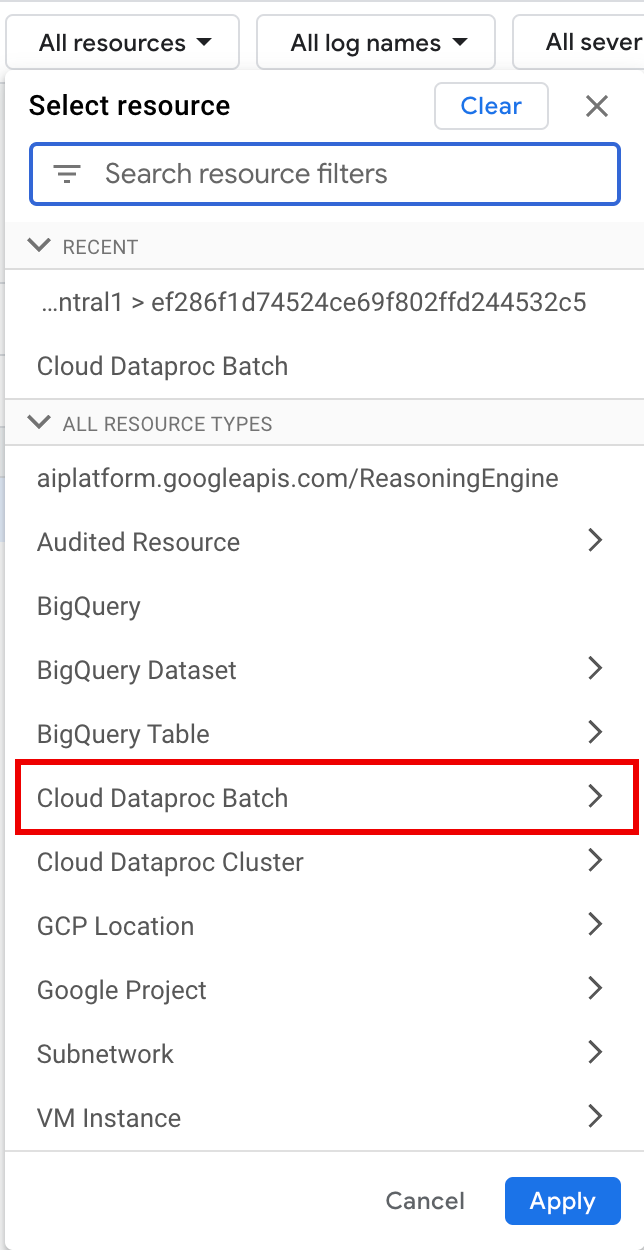
在选择资源 面板中,选择批次的位置 ,然后选择 批次 ID 。这些批量参数列在 控制台的 Dataproc 批次 页面上。 Google Cloud

点击应用。
在选择日志名称 下,输入
dataproc.googleapis.com在搜索日志名称 框中,以限制要查询的日志类型。选择 列出的一个或多个日志文件名。
使用查询编辑器过滤特定于虚拟机的日志。
指定资源类型和虚拟机资源名称,如以下示例所示:
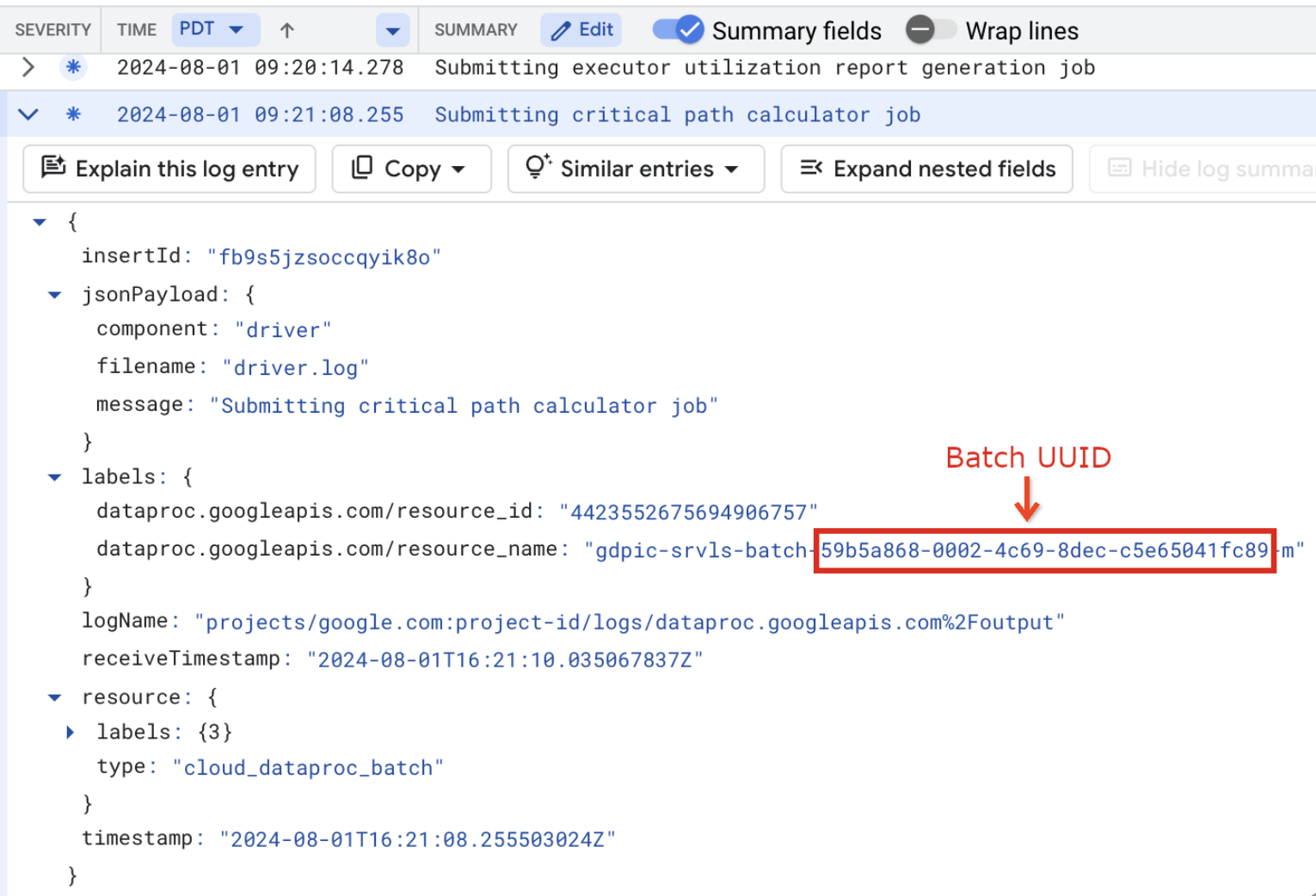
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID::批次 UUID 列在控制台的“批次详情”
页面中,当您点击
**批次** 页面上的批次 ID 时,该页面会打开。
Google Cloud
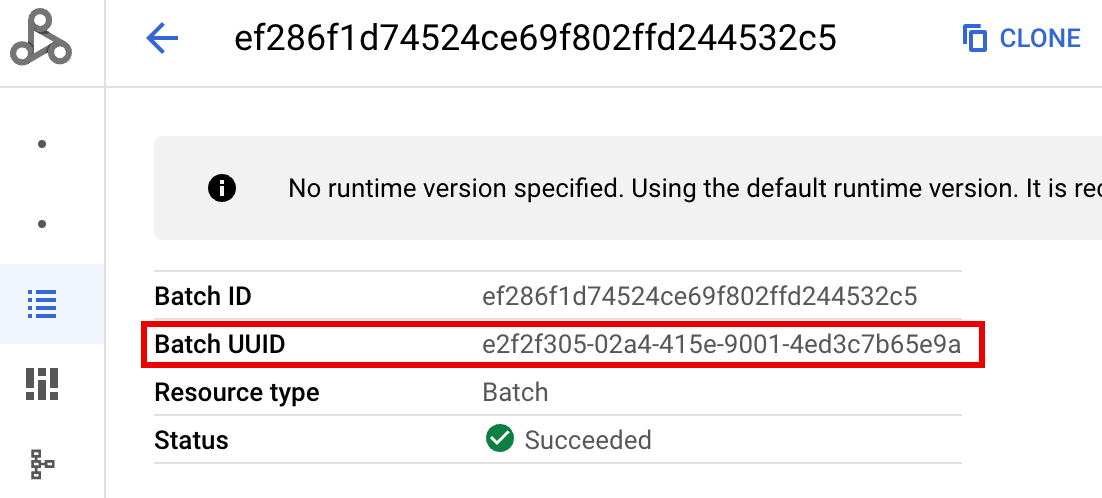
批量日志还在虚拟机资源名称中列出了批次 UUID。 以下是来自批量 driver.log 的示例:
- BATCH_UUID::批次 UUID 列在控制台的“批次详情”
页面中,当您点击
**批次** 页面上的批次 ID 时,该页面会打开。
Google Cloud
点击运行查询。
Serverless for Apache Spark 日志类型和查询示例
以下列表介绍了不同的 Serverless for Apache Spark 日志类型,并 为每种日志类型提供了 Logs Explorer 查询示例。
dataproc.googleapis.com/output:此日志文件包含批量工作负载输出。 Serverless for Apache Spark 将批量输出流式传输到output命名空间, 并将文件名设置为JOB_ID.driver.log。输出日志的 Logs Explorer 查询示例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark:spark命名空间汇总了在 Dataproc 集群主实例和工作器虚拟机上运行的守护程序和执行程序的 Spark 日志。每个日志条目都包含master、worker或executor组件标签,用于标识 日志来源,如下所示:executor:来自用户代码执行程序的日志。通常,这些是分布式日志。master:来自 Spark 独立资源管理器主实例的日志,类似于 Dataproc on Compute Engine YARN 日志。ResourceManagerworker:来自 Spark 独立资源管理器工作器的日志, 类似于 Dataproc on Compute Engine YARNNodeManager日志。
spark命名空间中所有日志的 Logs Explorer 查询示例:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
`
spark` 命名空间中 Spark 独立组件日志的 Logs Explorer 查询示例:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup:startup命名空间包含 批量(集群)启动日志。其中包含任何初始化脚本日志。 组件由标签标识,例如:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent:agent命名空间汇总了 Dataproc 代理日志。每个日志条目都包含用于标识日志来源的文件名标签 。由指定工作器虚拟机生成的代理日志的 Logs Explorer 查询示例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler:autoscaler命名空间汇总了 Serverless for Apache Spark 自动扩缩器日志。由指定工作器虚拟机生成的代理日志的 Logs Explorer 查询示例:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
如需了解详情, 请参阅 Dataproc 日志。
如需了解 Serverless for Apache Spark 审核日志,请参阅 Dataproc 审核日志记录。
工作负载指标
Serverless for Apache Spark 提供批量和 Spark 指标,您可以在 Metrics Explorer 或 批次详情 页面中查看这些指标。 Google Cloud
批量指标
Dataproc batch 资源指标可提供对批量资源的洞见,
例如批量执行程序的数量。批量指标以
dataproc.googleapis.com/batch为前缀。

Spark 指标
默认情况下,Serverless for Apache Spark 会启用 可用 Spark 指标的收集, 除非您使用 Spark 指标收集属性 停用或替换一个或多个 Spark 指标的收集。
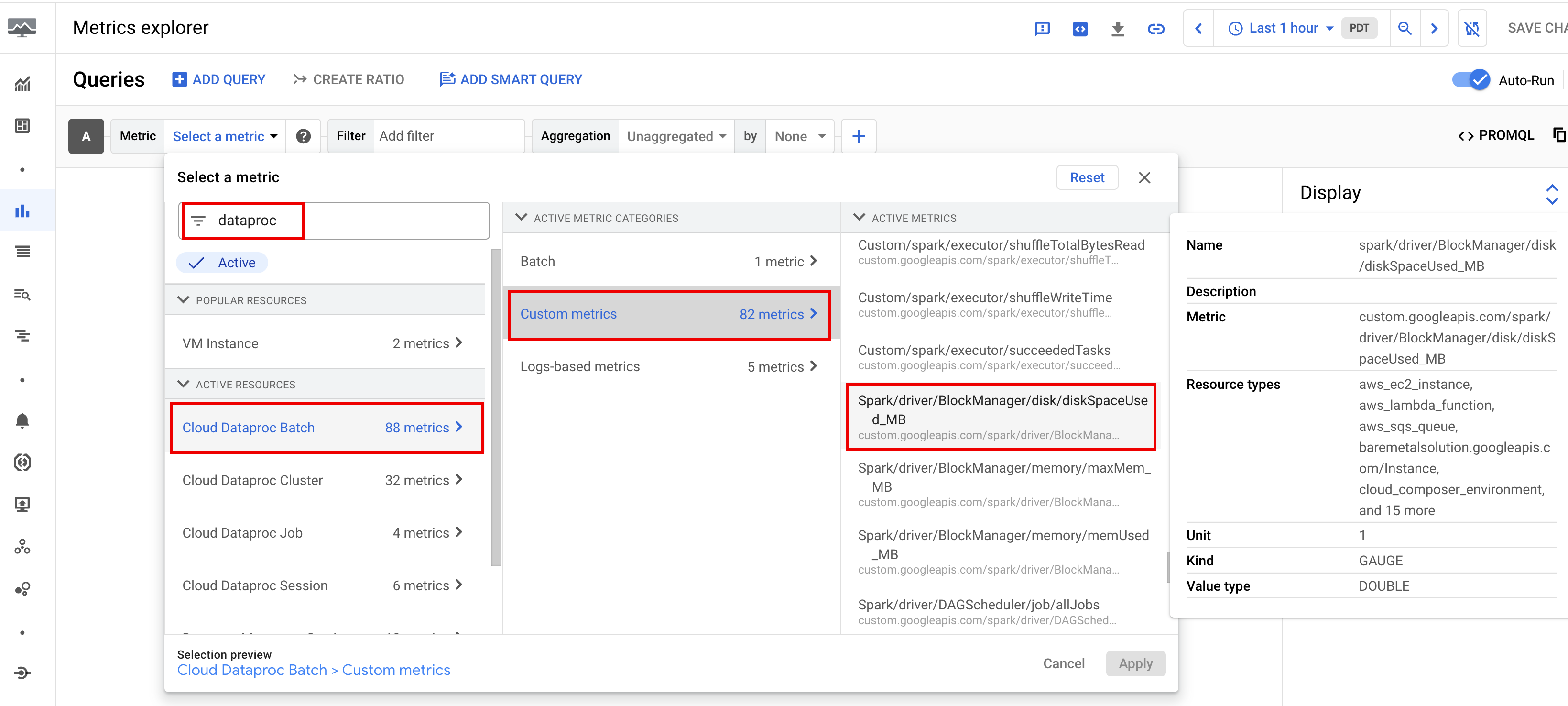
可用的 Spark 指标
包括 Spark 驱动程序和执行程序指标以及系统指标。可用的 Spark 指标以
custom.googleapis.com/为前缀。
设置指标提醒
您可以创建 Dataproc 指标提醒 以便收到工作负载问题的通知。
创建图表
您可以使用
Metrics Explorer 在
Google Cloud 控制台中创建图表,以直观呈现工作负载指标。例如,您可以
创建一个图表来显示 disk:bytes_used,然后按 batch_id 进行过滤。
Cloud Monitoring
Monitoring 使用工作负载元数据和指标来提供对 Serverless for Apache Spark 工作负载的运行状况和性能的洞见 。 工作负载指标包括 Spark 指标、批量指标和操作指标。
您可以在 Google Cloud 控制台 中使用 Cloud Monitoring 探索指标、添加图表、创建信息中心和创建提醒。
创建信息中心
您可以创建一个信息中心,以使用来自多个 项目和不同 Google Cloud 产品的指标来监控工作负载。如需了解详情,请参阅 创建和管理自定义信息中心。
Persistent History Server
Serverless for Apache Spark 会创建运行工作负载所需的计算资源, 在这些资源上运行工作负载,然后在工作负载完成后删除这些资源。 工作负载指标和事件在工作负载完成后不会保留。但是,您可以使用 Persistent History Server (PHS) 在 Cloud Storage 中保留工作负载应用历史记录(事件 日志)。
如需将 PHS 与批量工作负载搭配使用,请执行以下操作:
使用 组件网关 连接到 PHS,以查看应用详情、调度器阶段、任务级详情以及 环境和执行程序信息。
自动调节
- 为 Serverless for Apache Spark 启用自动调节 :您可以使用 Google Cloud 控制台、gcloud CLI 或 Dataproc API 提交每个重复性 Spark 批量工作负载时,为 Serverless for Apache Spark 启用自动调节。
控制台
请执行以下步骤,为每个重复性 Spark 批量工作负载启用自动调节:
在 Google Cloud 控制台中,前往 Dataproc 批次 页面。
如需创建批量工作负载,请点击创建。
在容器 部分中,填写 群组 名称,该名称将批次标识为一系列重复性工作负载之一。 Gemini 辅助分析适用于使用此群组名称提交的第二个及后续工作负载 。例如,为运行 每天 TPC-H 查询的计划工作负载指定
TPCH-Query1作为群组名称。根据需要填写创建批次 页面的其他部分,然后点击 提交。如需了解详情,请参阅 提交批量工作负载。
gcloud
在终端窗口或 Cloud Shell
中以本地方式运行以下 gcloud CLI
gcloud dataproc batches submit
命令,为每个重复性 Spark 批量工作负载启用自动调节:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
替换以下内容:
- COMMAND:Spark 工作负载类型,例如
Spark、PySpark、Spark-Sql或Spark-R。 - REGION:工作负载运行所在的 区域 。
- COHORT:群组名称,该名称将批次标识为一系列重复性工作负载之一。Gemini 辅助分析适用于使用此群组名称提交的第二个及后续工作负载
。例如,为每天运行 TPC-H 查询的计划工作负载指定
TPCH Query 1作为群组名称。
API
在 batches.create
请求中添加 RuntimeConfig.cohort
名称,为每个重复性 Spark
批量工作负载启用自动调节。自动调节适用于使用此群组名称提交的第二个及后续工作负载。例如,为每天运行 TPC-H 查询的计划工作负载指定 TPCH-Query1 作为群组名称。
示例:
...
runtimeConfig:
cohort: TPCH-Query1
...