
Batcharbeitslasten und interaktive Sitzungen von Managed Service for Apache Spark werden entweder mit Anmeldedaten von Endnutzern oder Dienstkonten ausgeführt. Wenn Anmeldedaten für Dienstkonten verwendet werden, hängt das Dienstkonto, das zum Ausführen von Batcharbeitslasten oder interaktiven Sitzungen verwendet wird, von der Batch- oder Sitzungs-Laufzeitversion ab.
Dienstkonten für Laufzeitversionen vor 3.0
Bei Spark-Laufzeitversionen vor 3.0 mit Anmeldedaten für Dienstkonten wird das
Compute Engine-Standarddienstkonto oder ein vom Nutzer angegebenes
benutzerdefiniertes Dienstkonto verwendet, um eine Batcharbeitslast zu senden oder eine interaktive Sitzung zu erstellen.
Dienstkonten für Laufzeitversionen ab 3.0
Bei Spark-Laufzeitversionen ab 3.0 mit Anmeldedaten für Dienstkonten wird ein vom Nutzer angegebenes benutzerdefiniertes Dienstkonto verwendet, um eine Batcharbeitslast zu senden oder eine interaktive Sitzung zu erstellen.
Bei Managed Service for Apache Spark-Laufzeitversionen ab 3.0 wird das
Dienstkonto „Dataproc Resource Manager Node Service Agent“ (service-project-number@gcp-sa-dataprocrmnode.iam.gserviceaccount.com) mit der
Rolle „Dataproc Resource Manager Node Service Agent“
in einem Managed Service for Apache Spark-Nutzer Google Cloud projekt erstellt. Dieses Dienstkonto führt die folgenden Systemvorgänge für Managed Service for Apache Spark-Ressourcen aus, die sich in dem Projekt befinden, in dem eine Arbeitslast erstellt wird:
- Cloud Logging und Cloud Monitoring
- Grundlegende Vorgänge für den Managed Service for Apache Spark Resource Manager-Knoten wie
get,heartbeatundmintOAuthToken
IAM-Dienstkontorollen ansehen und verwalten
So sehen Sie die Rollen an, die dem Dienstkonto für die Batcharbeitslast oder Sitzung zugewiesen sind, und verwalten sie:
Rufen Sie in der Google Cloud Console die Seite IAM auf.
Klicken Sie auf Von Google bereitgestellte Rollenzuweisungen einschließen.
Sehen Sie sich die Rollen an, die für das Standard- oder benutzerdefinierte Dienstkonto für die Batcharbeitslast oder Sitzung aufgeführt sind.
Die folgende Abbildung zeigt die erforderliche Managed Service for Apache Spark Worker Rolle für das Compute Engine-Standarddienstkonto,
project_number-compute@developer.gserviceaccount.com, das von Managed Service for Apache Spark standardmäßig als Dienstkonto für Arbeitslasten oder Sitzungen verwendet wird.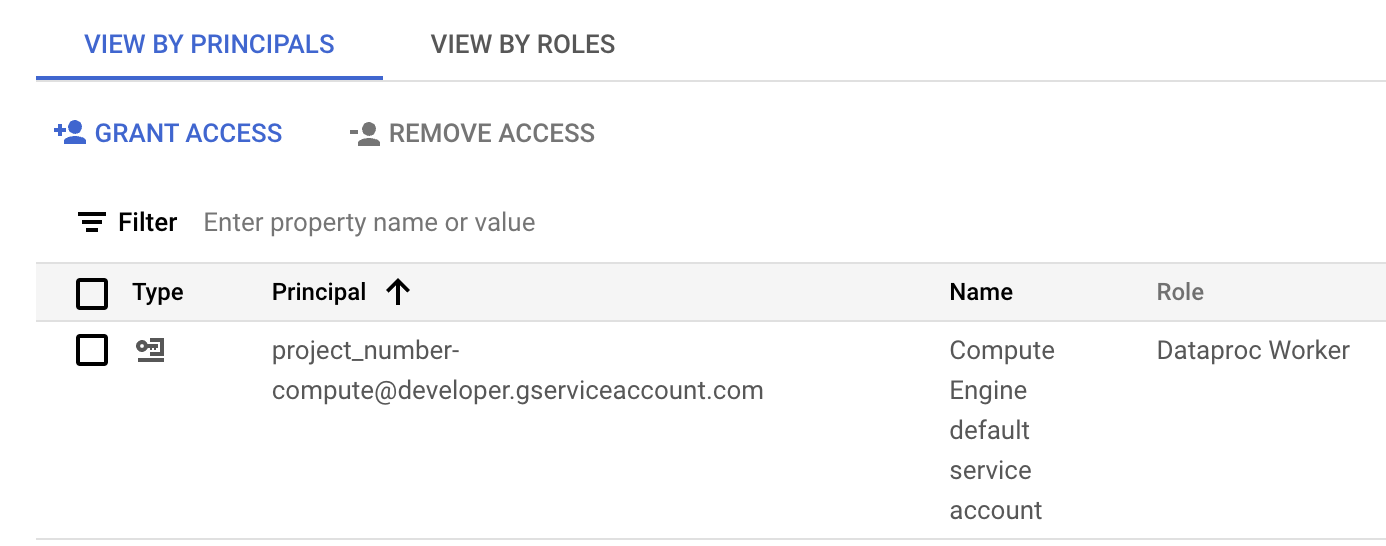
Die Rolle „Managed Service for Apache Spark Worker“ ist dem Compute Engine-Standarddienstkonto im IAM-Bereich der Google Cloud Console zugewiesen. Sie können auf das Stiftsymbol in der Dienstkontenzeile klicken, um Dienstkontorollen zuzuweisen oder zu entfernen.
Projektübergreifendes Dienstkonto verwenden
Sie können eine Batcharbeitslast senden, die ein Dienstkonto aus einem anderen Projekt als dem Projekt der Batcharbeitslast verwendet (dem Projekt, in dem der Batch gesendet wird). In diesem Abschnitt wird das Projekt, in dem sich das Dienstkonto befindet, als service account project bezeichnet und das Projekt, in dem der Batch gesendet wird, als batch project.
Warum ein projektübergreifendes Dienstkonto zum Ausführen einer Batcharbeitslast verwenden? Ein möglicher Grund ist, dass dem Dienstkonto im anderen Projekt zugewiesen wurden IAM-Rollen, die einen detaillierten Zugriff auf die Ressourcen in diesem Projekt ermöglichen.
Einrichtungsschritte
Die Beispiele in diesem Abschnitt gelten für das Senden einer Batcharbeitslast, die mit einer Laufzeitversion vor 3.0 ausgeführt wird.
Im Dienstkontoprojekt:
Ermöglichen Sie, dass Dienstkonten projektübergreifend angehängt werden können.
Aktivieren Sie die Dataproc API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Informationen zum Zuweisen von Rollen.Weisen Sie Ihrem E-Mail-Konto (dem Nutzer, der den Cluster erstellt) die Rolle „Dienstkontonutzer“ entweder für das Dienstkontoprojekt oder für eine detailliertere Steuerung für das Dienstkonto im Dienstkontoprojekt zu.
Weitere Informationen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten , um Rollen auf Projektebene zuzuweisen, und Zugriff auf Dienstkonten verwalten , um Rollen auf Dienstkontoebene zuzuweisen.
Beispiele für die gcloud CLI:
Mit dem folgenden Beispielbefehl wird dem Nutzer die Rolle „Dienstkontonutzer“ auf Projektebene zugewiesen:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Hinweise:
USER_EMAIL: Geben Sie die E-Mail-Adresse Ihres Nutzerkontos im Formatuser:user-name@example.coman.
Mit dem folgenden Beispielbefehl wird dem Nutzer die Rolle „Dienstkontonutzer“ auf Dienstkontoebene zugewiesen:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Hinweise:
USER_EMAIL: Geben Sie die E-Mail-Adresse Ihres Kontos im Formatuser:user-name@example.coman.
Weisen Sie dem Dienstkonto die Rolle „Managed Service for Apache Spark Worker“ für das Batchprojekt zu.
Beispiel für die gcloud CLI:
gcloud projects add-iam-policy-binding BATCH_PROJECT_ID \ --member=serviceAccount:SERVICE_ACCOUNT_NAME@SERVICE_ACCOUNT_PROJECT_ID.iam.gserviceaccount.com \ --role="roles/dataproc.worker"
Im Batchprojekt:
Weisen Sie dem Dienstkonto des Managed Service for Apache Spark-Dienst-Agents die Rollen „Dienstkontonutzer“ und „Ersteller von Dienstkonto-Tokens“ entweder für das Dienstkontoprojekt oder für eine detailliertere Steuerung für das Dienstkonto im Dienstkontoprojekt zu. Dadurch kann das Dienstkonto des Managed Service for Apache Spark-Dienst-Agents im Batchprojekt Tokens für das Dienstkonto im Dienstkontoprojekt erstellen.
Weitere Informationen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten , um Rollen auf Projektebene zuzuweisen, und Zugriff auf Dienstkonten verwalten , um Rollen auf Dienstkontoebene zuzuweisen.
Beispiele für die gcloud CLI:
Mit den folgenden Befehlen werden dem Dienstkonto des Managed Service for Apache Spark-Dienst-Agents im Batchprojekt die Rollen „Dienstkontonutzer“ und „Ersteller von Dienstkonto-Tokens“ auf Projektebene zugewiesen:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Mit den folgenden Beispielbefehlen werden dem Dienstkonto des Managed Service for Apache Spark-Dienst-Agents im Batchprojekt die Rollen „Dienstkontonutzer“ und „Ersteller von Dienstkonto-Tokens“ auf Dienstkontoebene zugewiesen:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Weisen Sie dem Dienstkonto des Compute Engine-Dienst-Agents im Batchprojekt die Rolle „Ersteller von Dienstkonto-Tokens“ entweder für das Dienstkontoprojekt oder für eine detailliertere Steuerung für das Dienstkonto im Dienstkontoprojekt zu. Dadurch kann das Dienstkonto des Compute Engine-Dienst-Agents im Batchprojekt Tokens für das Dienstkonto im Dienstkontoprojekt erstellen.
Weitere Informationen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten , um Rollen auf Projektebene zuzuweisen, und Zugriff auf Dienstkonten verwalten , um Rollen auf Dienstkontoebene zuzuweisen.
Beispiele für die gcloud CLI:
Mit dem folgenden Beispielbefehl wird dem Dienstkonto des Compute Engine-Dienst-Agents im Batchprojekt die Rolle „Ersteller von Dienstkonto-Tokens“ auf Projektebene zugewiesen:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Mit dem folgenden Beispielbefehl wird dem Dienstkonto des Compute Engine-Dienst-Agents im Clusterprojekt die Rolle „Ersteller von Dienstkonto-Tokens“ auf Dienstkontoebene zugewiesen:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Batcharbeitslast senden
Nachdem Sie die Einrichtungsschritte ausgeführt haben, können Sie eine Batcharbeitslast senden. Geben Sie das Dienstkonto im Dienstkontoprojekt als das Dienstkonto an, das für die Batcharbeitslast verwendet werden soll.
Fehler aufgrund von Berechtigungen beheben
Falsche oder unzureichende Berechtigungen für das Dienstkonto, das von Ihrer Batcharbeitslast oder Sitzung verwendet wird, können zu Fehlern beim Erstellen von Batches oder Sitzungen führen, bei denen die Fehlermeldung „Driver compute node failed to initialize for batch in 600 seconds“ (Der Compute-Knoten des Treibers konnte für den Batch nicht innerhalb von 600 Sekunden initialisiert werden) angezeigt wird. Dieser Fehler gibt an, dass der Spark-Treiber nicht innerhalb des zugewiesenen Zeitlimits gestartet werden konnte, was häufig auf einen Mangel an erforderlichem Zugriff auf Google Cloud Ressourcen zurückzuführen ist.
Prüfen Sie zur Fehlerbehebung, ob Ihr Dienstkonto die folgenden Mindestrollen oder -berechtigungen hat:
- Rolle Managed Service for Apache Spark Worker (
roles/dataproc.worker): Diese Rolle gewährt die erforderlichen Berechtigungen für Managed Service for Apache Spark zum Verwalten und Ausführen von Spark-Arbeitslasten und -Sitzungen. - Storage-Objekt-Betrachter (
roles/storage.objectViewer), Storage-Objekt-Ersteller (roles/storage.objectCreator) oder Storage-Objekt-Administrator (roles/storage.admin): Wenn Ihre Spark-Anwendung Daten aus Cloud Storage-Buckets liest oder in diese schreibt, benötigt das Dienstkonto die entsprechenden Berechtigungen für den Zugriff auf die Buckets. Wenn sich Ihre Eingabedaten beispielsweise in einem Cloud Storage-Bucket befinden, istStorage Object Viewererforderlich. Wenn Ihre Anwendung Ausgaben in einen Cloud Storage-Bucket schreibt,Storage Object CreatoroderStorage Object Administ erforderlich. - BigQuery-Datenbearbeiter (
roles/bigquery.dataEditor) oder BigQuery-Datenbetrachter (roles/bigquery.dataViewer): Wenn Ihre Spark Anwendung mit BigQuery interagiert, prüfen Sie, ob das Dienstkonto die entsprechenden BigQuery-Rollen hat. - Cloud Logging-Berechtigungen:Das Dienstkonto benötigt Berechtigungen zum Schreiben von Logs in Cloud Logging, um Fehler effektiv beheben zu können. In der Regel ist die
Logging WriterRolle (roles/logging.logWriter) ausreichend.
Häufige Fehler im Zusammenhang mit Berechtigungen oder Zugriff
Fehlende Rolle
dataproc.worker: Ohne diese Kernrolle kann die Managed Service for Apache Spark-Infrastruktur den Treiberknoten nicht ordnungsgemäß bereitstellen und verwalten.Unzureichende Cloud Storage-Berechtigungen: Wenn Ihre Spark-Anwendung versucht, Eingabedaten aus einem Cloud Storage-Bucket zu lesen oder Ausgaben in einen Cloud Storage-Bucket zu schreiben, ohne die erforderlichen Dienstkontoberechtigungen zu haben, kann der Treiber nicht initialisiert werden, da er keinen Zugriff auf wichtige Ressourcen hat.
Netzwerk- oder Firewallprobleme: VPC Service Controls oder Firewallregeln können den Zugriff des Dienstkontos auf Google Cloud APIs oder Ressourcen versehentlich blockieren.
So prüfen und aktualisieren Sie Dienstkontoberechtigungen:
- Rufen Sie in der Google Cloud Console die IAM & Verwaltung > IAM Seite auf.
- Suchen Sie das Dienstkonto, das für Ihre Batcharbeitslasten oder Sitzungen verwendet wird.
- Prüfen Sie, ob die erforderlichen Rollen zugewiesen sind. Wenn nicht, fügen Sie sie hinzu.
Eine Liste der Managed Service for Apache Spark-Rollen und -Berechtigungen finden Sie unter Berechtigungen und IAM-Rollen für Managed Service for Apache Spark.