
Serverless for Apache Spark 批处理工作负载和交互式会话使用 最终用户或服务账号凭据运行。如果使用服务账号 凭据,则用于运行批处理工作负载或 交互式会话的服务账号取决于批处理或会话运行时版本。
3.0 之前的运行时服务账号
使用服务账号凭据的 3.0 之前的 Spark 运行时版本使用
Compute Engine 默认服务账号 或用户指定的
自定义服务账号来提交批处理工作负载或创建交互式会话。
3.0 及更高版本的运行时服务账号
使用服务账号凭据的 3.0 及更高版本的 Spark 运行时版本使用
用户指定的自定义服务账号来提交批处理工作负载或创建
交互式会话。
Serverless for Apache Spark 3.0 及更高版本的运行时会在 Dataproc 用户 Google Cloud 项目中创建
Dataproc Resource Manager Node Service Agent 服务账号 service-project-number@gcp-sa-dataprocrmnode.iam.gserviceaccount.com,并具有
Dataproc Resource Manager Node Service Agent
角色。此服务
账号对创建工作负载的项目中的 Serverless for Apache Spark
资源执行以下系统操作:
- Cloud Logging 和 Cloud Monitoring
- Dataproc Resource Manager Node 基本操作,例如
get、heartbeat和mintOAuthToken
查看和管理 IAM 服务账号角色
如需查看和管理向批处理工作负载或会话服务 账号授予的角色,请执行以下操作:
在 Google Cloud 控制台中,前往 IAM 页面。
点击包括 Google 提供的角色授权。
查看为批处理工作负载或会话默认或自定义服务 默认或自定义服务账号列出的角色。
下图显示了为 Compute Engine 默认服务账号
project_number-compute@developer.gserviceaccount.com列出的必需的 Dataproc Worker 角色,Serverless for Apache Spark 在默认情况下将该账号用作工作负载或会话服务账号。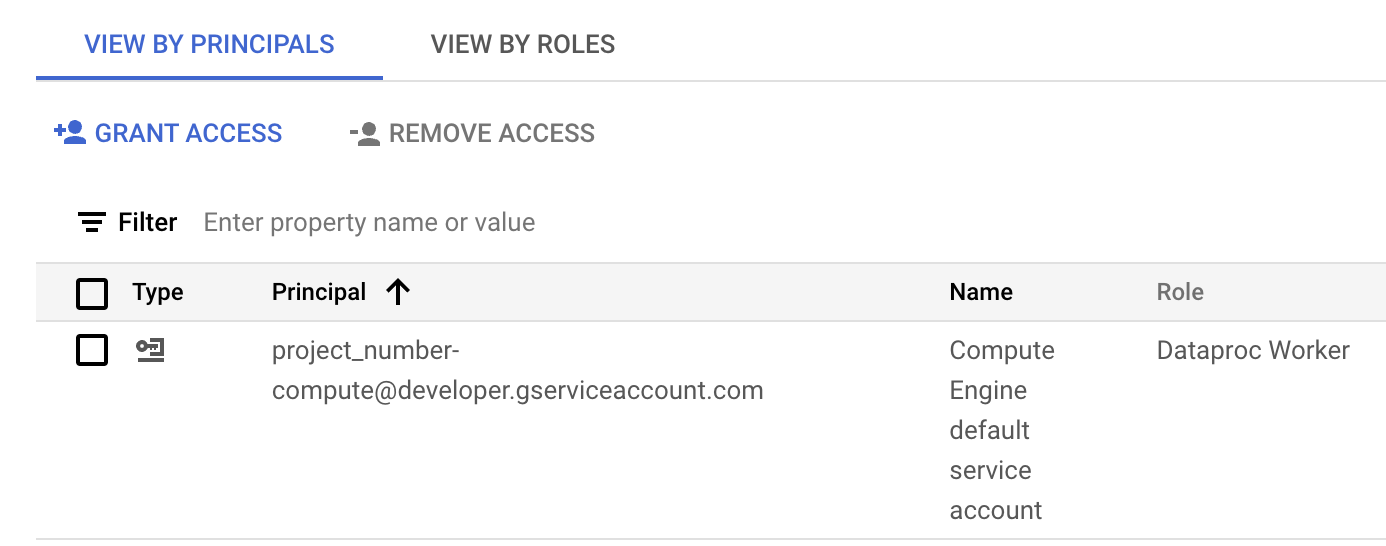
在控制台的 IAM 部分向 Compute Engine 默认服务账号分配的 Dataproc Worker 角色。 Google Cloud 您可以点击服务账号行上显示的铅笔图标,以 授予或移除服务账号角色。
如何使用跨项目服务账号
您可以提交使用与批处理工作负载项目
(提交批处理的项目)不同的项目中的服务账号的批处理工作负载。在本部分中,服务账号所在的项目称为service account project,提交批处理的项目称为batch project。
为何使用跨项目服务账号来运行批处理工作负载?一种 可能的原因是,其他项目中的服务账号已被分配 IAM 角色,这些角色可提供对 该项目中的资源的精细访问权限。
设置步骤
本部分中的示例适用于提交使用 3.0 之前的运行时版本执行的批处理工作负载
。
在服务账号项目中:
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.向您的电子邮件账号(创建集群的用户)授予适用于服务账号项目的 Service Account User角色 ,或者向服务账号项目中的服务账号授予该角色,以实现更精细的控制。
如需了解详情,请参阅 管理对项目、文件夹和组织的访问权限 ,以便在项目级别授予角色,并参阅 管理对服务账号的访问权限 ,以便在服务账号级别授予角色。
gcloud CLI 示例:
以下示例命令会在项目级别向用户授予 Service Account User 角色:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
注意:
USER_EMAIL:提供您的用户账号电子邮件地址, 格式为:user:user-name@example.com。
以下示例命令会在服务账号级别向用户授予 Service Account User 角色:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
注意:
USER_EMAIL:提供您的用户账号电子邮件地址,格式为:user:user-name@example.com。
向服务账号授予适用于批处理项目的 Dataproc Worker 角色。
gcloud CLI 示例:
gcloud projects add-iam-policy-binding BATCH_PROJECT_ID \ --member=serviceAccount:SERVICE_ACCOUNT_NAME@SERVICE_ACCOUNT_PROJECT_ID.iam.gserviceaccount.com \ --role="roles/dataproc.worker"
在批处理项目中:
向 Dataproc 服务代理服务账号 授予适用于服务账号项目的 Service Account User 和 Service Account Token Creator 角色,或者向服务账号项目中的服务账号授予这些角色,以实现更精细的控制。通过执行此操作, 您使 批处理项目中的 Dataproc 服务代理服务账号可以为 服务账号项目中的服务账号创建令牌。
如需了解详情,请参阅 管理对项目、文件夹和组织的访问权限 ,以便在项目级别授予角色,并参阅 管理对服务账号的访问权限 ,以便在服务账号级别授予角色。
gcloud CLI 示例:
以下命令会在项目级别向批处理项目中的 Dataproc 服务代理 服务账号授予 Service Account User 角色和 Service Account Token Creator 角色:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
以下示例命令会在服务账号级别向批处理项目中的 Dataproc Service Agent 服务账号授予 Service Account User 角色和 Service Account Token Creator 角色:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
向批处理项目中的 Compute Engine Service Agent 服务账号 授予适用于服务账号项目的 Service Account Token Creator 角色,或者向服务账号项目中的服务账号授予该角色,以实现更精细的控制。通过执行此操作,您使批处理 项目中的 Compute Engine Service Agent 服务账号有能力为服务 账号项目中的服务 账号创建令牌。
如需了解详情,请参阅 管理对项目、文件夹和组织的访问权限 ,以便在项目级别授予角色,并参阅 管理对服务账号的访问权限 ,以便在服务账号级别授予角色。
gcloud CLI 示例:
以下示例命令会在项目级别为批处理项目中的 Compute Engine Service Agent 服务账号授予 Service Account Token Creator 角色:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
以下示例命令会在服务账号级别向集群项目中的 Compute Engine Service Agent 服务账号 授予 Service Account Token Creator 角色:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
提交批处理工作负载
完成 设置步骤 后,您可以 提交批处理工作负载。 请务必在服务账号项目中指定服务账号,作为 批处理工作负载要使用的服务账号。
排查基于权限的故障
如果批处理工作负载或会话使用的服务账号的权限不正确或不足,可能会导致批处理或会话 创建失败,并报告“Driver compute node failed to initialize for batch in 600 seconds”错误消息。此错误表示 Spark 驱动程序 无法在分配的超时期限内启动,通常是由于缺少 对 Google Cloud 资源的必要访问权限所致。
如需排查此问题,请验证您的服务账号是否具有以下 最低角色或权限:
- Dataproc Worker 角色 (
roles/dataproc.worker):此角色授予 Serverless for Apache Spark 管理和 执行 Spark 工作负载和会话所需的权限。 - Storage Object Viewer (
roles/storage.objectViewer)、Storage Object Creator (roles/storage.objectCreator) 或Storage Object Admin (roles/storage.admin):如果您的 Spark 应用从 Cloud Storage 存储分区读取数据或向其写入数据,则服务账号需要具有访问存储分区的相应权限。例如,如果您的输入数据 位于 Cloud Storage 存储分区中,则需要Storage Object Viewer。如果您的 应用将输出写入 Cloud Storage 存储分区,则需要Storage Object Creator或Storage Object Admin。 - BigQuery Data Editor (
roles/bigquery.dataEditor) 或 BigQuery Data Viewer (roles/bigquery.dataViewer):如果您的 Spark 应用与 BigQuery 交互,请验证服务账号是否具有相应的 BigQuery 角色。 - Cloud Logging 权限:服务账号需要具有将日志写入 Cloud Logging 的权限
,以便进行有效的调试。通常,
Logging Writer角色 (roles/logging.logWriter) 就足够了。
与权限或访问权限相关的常见故障
缺少
dataproc.worker角色:如果没有此核心角色, Serverless for Apache Spark 基础架构将无法正确预配和 管理驱动程序节点。Cloud Storage 权限不足:如果您的 Spark 应用 尝试从 Cloud Storage 存储分区读取输入数据或向其写入输出数据,但没有 必要的服务账号权限,则驱动程序可能会因缺少对关键资源的访问权限而无法 初始化。
网络或防火墙问题:VPC Service Controls 或防火墙规则可能会 无意中阻止服务账号访问 Google Cloud API 或资源。
如需验证和更新服务账号权限,请执行以下操作:
- 在 Google Cloud 控制台中,前往 IAM 和管理 > IAM 页面。
- 找到用于批处理工作负载或会话的服务账号。
- 验证是否已分配必要的角色。如果未分配,请添加这些角色。
如需查看 Serverless for Apache Spark 角色和权限的列表,请参阅 Serverless for Apache Spark 权限和 IAM 角色。