
In diesem Dokument finden Sie Informationen zum automatischen Optimieren von Batcharbeitslasten für Managed Service for Apache Spark. Das Optimieren einer Spark-Arbeitslast für Leistung und Stabilität kann aufgrund der Anzahl der Spark-Konfigurationsoptionen und der Schwierigkeit, die Auswirkungen dieser Optionen auf eine Arbeitslast zu bewerten, eine Herausforderung sein. Die automatische Optimierung von Managed Service for Apache Spark bietet eine Alternative zur manuellen Konfiguration von Arbeitslasten. Dabei werden Spark-Konfigurationseinstellungen automatisch auf eine wiederkehrende Spark-Arbeitslast angewendet. Grundlage sind die Best Practices für die Spark-Optimierung und eine Analyse von Arbeitslastläufen (sogenannte „Kohorten“).
Für das automatische Tuning von Managed Service for Apache Spark registrieren
Wenn Sie sich für den Zugriff auf die auf dieser Seite beschriebene Vorabversion der automatischen Optimierung von Managed Service for Apache Spark registrieren möchten, füllen Sie das Registrierungsformular für den Vorabzugriff auf Managed Service for Apache Spark aus und senden Sie es ab. Nachdem das Formular genehmigt wurde, haben die im Formular aufgeführten Projekte Zugriff auf Vorschaufunktionen.
Vorteile
Die automatische Optimierung von Managed Service for Apache Spark bietet folgende Vorteile:
- Automatische Optimierung: Ineffiziente Batch- und Spark-Konfigurationen für Managed Service for Apache Spark werden automatisch optimiert, was die Laufzeit von Jobs verkürzen kann.
- Verlaufslernen: Aus wiederkehrenden Läufen lernen, um Empfehlungen anzuwenden, die auf Ihre Arbeitslast zugeschnitten sind.
Autotuning-Kohorten
Die automatische Optimierung wird auf wiederkehrende Ausführungen (Kohorten) einer Batcharbeitslast angewendet.
Der Kohortenname, den Sie beim Einreichen einer Batcharbeitslast angeben, kennzeichnet sie als einen der aufeinanderfolgenden Läufe der wiederkehrenden Arbeitslast.
Die automatische Optimierung wird auf Kohorten von Batcharbeitslasten angewendet:
Die automatische Optimierung wird für die zweite und die nachfolgenden Kohorten eines Workloads berechnet und angewendet. Autotuning wird nicht auf den ersten Lauf einer wiederkehrenden Arbeitslast angewendet, da beim Autotuning von Managed Service for Apache Spark der Arbeitslastverlauf zur Optimierung verwendet wird.
Die automatische Optimierung wird nicht rückwirkend auf laufende Arbeitslasten angewendet, sondern nur auf neu eingereichte Arbeitslasten.
Die automatische Optimierung lernt und verbessert sich im Laufe der Zeit, indem sie die Kohortenstatistiken analysiert. Damit das System genügend Daten erfassen kann, empfehlen wir, die automatische Optimierung mindestens fünf Ausführungen lang aktiviert zu lassen.
Kohortennamen: Es wird empfohlen, Kohortennamen zu verwenden, die den wiederkehrenden Arbeitslasttyp identifizieren. Sie können beispielsweise daily_sales_aggregation als Kohortennamen für eine geplante Arbeitslast verwenden, mit der täglich eine Aufgabe zur Aggregation von Verkaufsdaten ausgeführt wird.
Szenarien für die automatische Abstimmung
Falls zutreffend, werden beim automatischen Tuning die folgenden scenarios oder Zielvorhaben automatisch ausgewählt und ausgeführt, um eine Batcharbeitslast zu optimieren:
- Skalierung: Einstellungen für die Spark-Autoscaling-Konfiguration.
- Join-Optimierung: Spark-Konfigurationseinstellungen zur Optimierung der Leistung von SQL-Broadcast-Joins.
Autotuning für Managed Service for Apache Spark verwenden
Sie können die automatische Optimierung von Managed Service for Apache Spark für einen Batch-Arbeitslast aktivieren, indem Sie die Google Cloud -Konsole, die Google Cloud CLI, die Dataproc API oder die Cloud-Clientbibliotheken verwenden.
Console
Führen Sie die folgenden Schritte aus, um das automatische Optimieren von Managed Service for Apache Spark bei jeder Einreichung einer wiederkehrenden Batcharbeitslast zu aktivieren:
Rufen Sie in der Google Cloud Console die Seite Batches für Managed Service for Apache Spark auf.
Klicken Sie auf Erstellen, um eine Batch-Arbeitslast zu erstellen.
Im Abschnitt Automatische Abstimmung:
Klicken Sie auf den Ein/Aus-Button Aktivieren, um die automatische Abstimmung für die Spark-Arbeitslast zu aktivieren.
Kohorte:Geben Sie den Namen der Kohorte ein, der den Batch als eine von mehreren wiederkehrenden Arbeitslasten identifiziert. Die automatische Optimierung wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise
daily_sales_aggregationals Kohortennamen für eine geplante Batcharbeitslast an, mit der täglich eine Aufgabe zur Umsatzaggregation ausgeführt wird.
Füllen Sie nach Bedarf die anderen Abschnitte der Seite Batch erstellen aus und klicken Sie dann auf Senden. Weitere Informationen zu diesen Feldern finden Sie unter Batch-Arbeitslast einreichen.
gcloud
Wenn Sie das automatische Optimieren von Managed Service for Apache Spark bei jeder Einreichung einer wiederkehrenden Batcharbeitslast aktivieren möchten, führen Sie den folgenden gcloud CLI-Befehl gcloud dataproc batches submit lokal in einem Terminalfenster oder in Cloud Shell aus.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=auto \ other arguments ...
Ersetzen Sie Folgendes:
- COMMAND: der Spark-Arbeitslasttyp, z. B.
Spark,PySpark,Spark-SqloderSpark-R. - REGION: die Region, in der Ihre Batcharbeitslast ausgeführt wird.
- COHORT: Der Name der Kohorte, der den Batch als einen von einer Reihe wiederkehrender Arbeitslasten identifiziert.
Die automatische Optimierung wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise
daily_sales_aggregationals Kohortennamen für eine geplante Batcharbeitslast an, mit der täglich eine Aufgabe zur Umsatzaggregation ausgeführt wird. --autotuning-scenarios=auto: Autotuning aktivieren.
API
Wenn Sie das automatische Optimieren von Managed Service for Apache Spark bei jeder Einreichung einer wiederkehrenden Batcharbeitslast aktivieren möchten, senden Sie eine batches.create-Anfrage mit den folgenden Feldern:
RuntimeConfig.cohort: Der Name der Kohorte, der den Batch als einen von einer Reihe wiederkehrender Arbeitslasten identifiziert. Autotuning wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweisedaily_sales_aggregationals Kohortennamen für eine geplante Batcharbeitslast an, mit der täglich eine Aufgabe zur Umsatzaggregation ausgeführt wird.AutotuningConfig.scenarios: Geben SieAUTOan, um die automatische Optimierung für den Spark-Batch-Arbeitslast zu aktivieren.
Beispiel:
...
runtimeConfig:
cohort: COHORT_NAME
autotuningConfig:
scenarios:
- AUTO
...
Java
Folgen Sie der Einrichtungsanleitung für Java in der Kurzanleitung zur Verwendung von Clientbibliotheken, bevor Sie dieses Beispiel anwenden. Weitere Informationen finden Sie in der Referenzdokumentation zur Managed Service for Apache Spark Java API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Managed Service for Apache Spark zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Wenn Sie das automatische Optimieren von Managed Service for Apache Spark bei jeder Einreichung einer wiederkehrenden Batcharbeitslast aktivieren möchten, rufen Sie BatchControllerClient.createBatch mit einer CreateBatchRequest auf, die die folgenden Felder enthält:
Batch.RuntimeConfig.cohort: Der Name der Kohorte, der den Batch als eine von mehreren wiederkehrenden Arbeitslasten identifiziert. Autotuning wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Sie können beispielsweisedaily_sales_aggregationals Kohortennamen für einen geplanten Batch-Arbeitslast angeben, der eine tägliche Aufgabe zur Umsatzaggregation ausführt.Batch.RuntimeConfig.AutotuningConfig.scenarios: Geben SieAUTOan, um die automatische Abstimmung für den Spark-Batch-Workload zu aktivieren.
Beispiel:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.AUTO))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Wenn Sie die API verwenden möchten, benötigen Sie die Clientbibliothek google-cloud-dataproc in Version 4.43.0 oder höher. Sie können eine der folgenden Konfigurationen verwenden, um die Bibliothek Ihrem Projekt hinzuzufügen.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Folgen Sie der Einrichtungsanleitung für Python in der Kurzanleitung zur Verwendung von Clientbibliotheken, bevor Sie dieses Beispiel anwenden. Weitere Informationen finden Sie in der Referenzdokumentation zur Managed Service for Apache Spark Python API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei Managed Service for Apache Spark zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Wenn Sie das automatische Optimieren von Managed Service for Apache Spark bei jeder Einreichung einer wiederkehrenden Batcharbeitslast aktivieren möchten, rufen Sie BatchControllerClient.create_batch mit einem Batch auf, das die folgenden Felder enthält:
batch.runtime_config.cohort: Der Name der Kohorte, der den Batch als eine von mehreren wiederkehrenden Arbeitslasten identifiziert. Autotuning wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Sie können beispielsweisedaily_sales_aggregationals Kohortennamen für eine geplante Batcharbeitslast angeben, mit der täglich eine Aufgabe zur Umsatzaggregation ausgeführt wird.batch.runtime_config.autotuning_config.scenarios: Geben SieAUTOan, um die automatische Abstimmung für den Spark-Batch-Workload zu aktivieren.
Beispiel:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.AUTO
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Wenn Sie die API verwenden möchten, müssen Sie die Clientbibliothek google-cloud-dataproc in Version 5.10.1 oder höher verwenden. Um sie Ihrem Projekt hinzuzufügen, können Sie die folgende Anforderung verwenden:
google-cloud-dataproc>=5.10.1
Airflow
Anstatt jede automatisch optimierte Batchkohorte manuell einzureichen, können Sie Airflow verwenden, um die Einreichung jeder wiederkehrenden Batcharbeitslast zu planen. Rufen Sie dazu BatchControllerClient.create_batch mit einem Batch auf, das die folgenden Felder enthält:
batch.runtime_config.cohort: Der Name der Kohorte, der den Batch als eine von mehreren wiederkehrenden Arbeitslasten identifiziert. Autotuning wird auf die zweite und die nachfolgenden Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Sie können beispielsweisedaily_sales_aggregationals Kohortennamen für einen geplanten Batch-Arbeitslast angeben, der eine tägliche Aufgabe zur Umsatzaggregation ausführt.batch.runtime_config.autotuning_config.scenarios: Geben SieAUTOan, um die automatische Abstimmung für den Spark-Batch-Workload zu aktivieren.
Beispiel:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.AUTO,
]
}
},
},
batch_id="BATCH_ID",
)
Wenn Sie die API verwenden möchten, müssen Sie die Clientbibliothek google-cloud-dataproc in Version 5.10.1 oder höher verwenden. Sie können die folgende Anforderung für die Airflow-Umgebung verwenden:
google-cloud-dataproc>=5.10.1
Informationen zum Aktualisieren des Pakets in Managed Service for Apache Airflow finden Sie unter Python-Abhängigkeiten für Managed Airflow installieren .
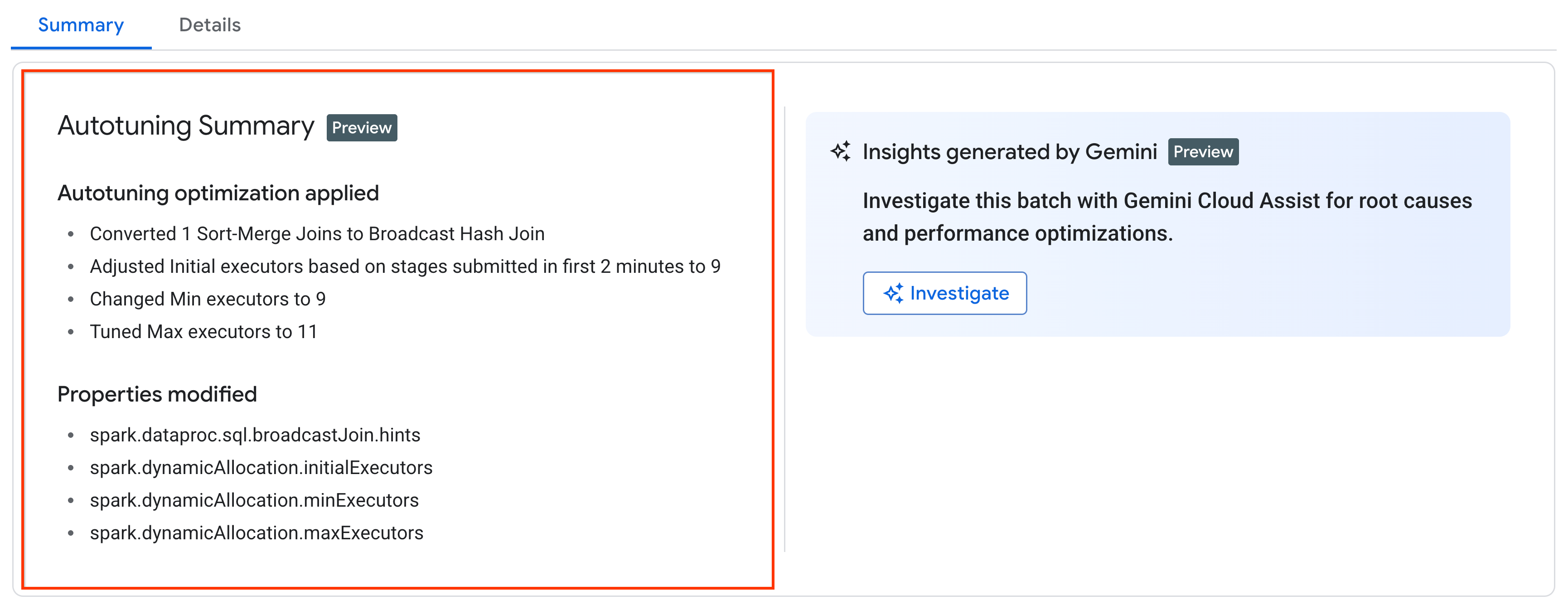
Änderungen bei der automatischen Optimierung ansehen
Wenn Sie die Änderungen durch die automatische Optimierung von Managed Service for Apache Spark an einer Batcharbeitslast ansehen möchten, führen Sie den Befehl gcloud dataproc batches describe aus.
Beispiel: Die gcloud dataproc batches describe-Ausgabe sieht etwa so aus:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties:
spark.dataproc.sql.broadcastJoin.hints:
annotation: Converted 1 Sort-Merge Joins to Broadcast Hash Join
value: v2;Inner,<hint>
spark.dynamicAllocation.initialExecutors:
annotation: Adjusted Initial executors based on stages submitted in first
2 minutes to 9
overriddenValue: '2'
value: '9'
spark.dynamicAllocation.maxExecutors:
annotation: Tuned Max executors to 11
overriddenValue: '5'
value: '11'
spark.dynamicAllocation.minExecutors:
annotation: Changed Min executors to 9
overriddenValue: '2'
value: '9'
...
Die letzten Änderungen, die durch die automatische Optimierung an einer laufenden, abgeschlossenen oder fehlgeschlagenen Arbeitslast vorgenommen wurden, finden Sie in der Google Cloud Console auf der Seite Batchdetails auf dem Tab Zusammenfassung.
Preise
Die automatische Optimierung von Managed Service for Apache Spark wird während der privaten Vorschau ohne zusätzliche Kosten angeboten. Es gelten die Standardpreise für Managed Service for Apache Spark.