
Knowledge Catalog ist ein auf Gemini basierender Datenkatalog, der universellen geschäftlichen Kontext und Governance für Ihren gesamten Datenbestand bietet. Durch das automatische Extrahieren von Semantik aus strukturierten und unstrukturierten Daten wird ein dynamischer Kontextgraph erstellt, der KI-Agents auf Unternehmenswahrheit basiert und Halluzinationen reduziert. Datenteams und KI-Entwickler verwenden Knowledge Catalog, um Daten zu ermitteln, Richtlinien durchzusetzen und umfassenden Kontext für Analysen und autonome Anwendungen abzurufen. Eine detaillierte Anleitung zu Knowledge Catalog finden Sie im eingebetteten Video.
Dataplex Universal Catalog ist jetzt Knowledge Catalog
Um die Vision, die Daten-Governance mit generativen KI-Funktionen zu vereinheitlichen, besser widerzuspiegeln, heißt Dataplex Universal Catalog jetzt Knowledge Catalog. Diese Weiterentwicklung des Produktnamens steht für den Übergang von einer herkömmlichen, passiven Metadatenregistrierung zu einem aktiven, KI-gestützten Kontextdiagramm.
Warum wurde Dataplex zu Knowledge Catalog?
Da Unternehmen die Einführung generativer KI beschleunigen, benötigen KI-Agents einen umfassenden geschäftlichen Kontext, um genaue, fundierte Antworten zu liefern. Knowledge Catalog schließt die Lücke zwischen der Daten-Governance für Unternehmen und KI-Agenten-Workflows.
Was ist der Unterschied zwischen Dataplex und Knowledge Catalog?
Knowledge Catalog-Updates spiegeln neue KI-basierte Funktionen wider. Im Gegensatz zu herkömmlichen passiven Katalogen werden in Knowledge Catalog Metadaten, Geschäftslogik und Datenbeziehungen automatisch in einem einheitlichen Kontextdiagramm zusammengeführt. Dieses Diagramm liefert die zuverlässigen Unternehmensdaten, die KI-Agenten benötigen, um komplexe Aufgaben präzise auszuführen. Dabei werden Funktionen wie die automatische Kontextzusammenstellung, geprüfte Beispielanfragen sowie lokale und Remote-MCP-Integrationen (Model Context Protocol) genutzt.
Was sich nicht ändert
Ihre vorhandenen Dataplex-Bereitstellungen, APIs und Konfigurationen bleiben betriebsbereit. Kernfunktionen wie Datenermittlung, Lineage, Datenqualität und Unternehmensglossare sind unverändert und werden weiterhin unterstützt. Ihre vorhandenen Metadaten, Aspekte und Konfigurationen werden ohne manuelle Migration, Datenübertragung oder Ausfallzeiten in den neuen Knowledge Catalog übertragen.
APIs und Clientbibliotheken
Durch das Rebranding zu Knowledge Catalog werden vorhandene API-Endpunkte, gcloud dataplex-Befehle oder Clientbibliotheken nicht geändert. Sie können die Knowledge Catalog APIs und Clientbibliotheken weiterhin verwenden, um mit dem Knowledge Catalog zu interagieren:
REST API Weitere Informationen finden Sie in der Knowledge Catalog REST API-Dokumentation.
Clientbibliotheken: Erste Schritte mit dem Knowledge Catalog in Ihrer bevorzugten Sprache mit den Knowledge Catalog-Clientbibliotheken
gcloud-Befehle Knowledge Catalog-Ressourcen mit der Befehlsgruppe
gcloud dataplexverwalten Weitere Informationen finden Sie in der gcloud-Befehlsreferenz für Dataplex.
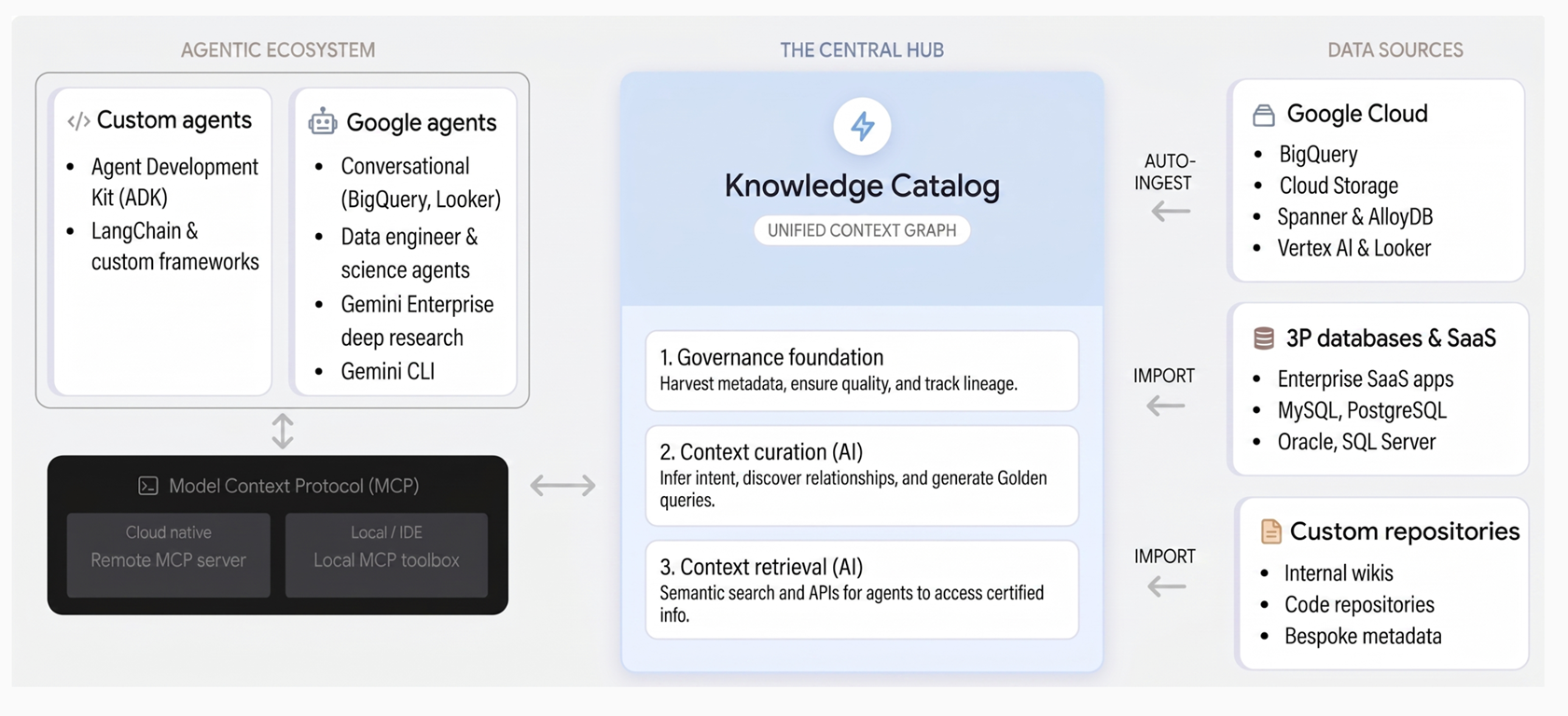
So funktioniert Knowledge Catalog
Knowledge Catalog vereint Governance und Kontext durch drei Kernsäulen:
Grundlage für Governance: Knowledge Catalog erfasst automatisch technische Metadaten aus Google Cloud -Diensten wie BigQuery, AlloyDB for PostgreSQL und Spanner sowie aus Drittanbietersystemen. Sie schafft eine vertrauenswürdige Datengrundlage durch ein zentrales Unternehmensglossar, Datenqualitätsprüfungen, Anomalieerkennung und richtlinienbasierte Governance.
Kontextualisierung: Gemini analysiert Schemas, Abfragelogs und semantische Modelle in Ihren Daten, um die geschäftliche Absicht zu ermitteln. Es generiert Beschreibungen in natürlicher Sprache, erkennt Beziehungen und schlägt geprüfte SQL-Muster in Form von Beispielabfragen vor, die komplexe Geschäftslogik erfassen.
Kontextabruf: KI-Agenten und ‑Anwendungen können Assets sofort finden und angereicherten Kontext über die semantische Suche und Tools abrufen, die das Model Context Protocol (MCP) unterstützen. So können Agenten auf die „Source of Truth“ der Organisation zugreifen, um zuverlässige Entscheidungen zu treffen.
Das folgende Diagramm veranschaulicht die Architektur von Knowledge Catalog und wie damit die Datenverwaltung mit generativen KI-Workflows vereinheitlicht wird:
Gängige Anwendungsfälle
Knowledge Catalog unterstützt Data Engineers, Data Scientists und KI-Entwickler bei der Bewältigung von Herausforderungen in den Bereichen Datenverwaltung und KI-Entwicklung:
Daten für KI anreichern: Mit Datenanalysen für unstrukturierte Daten lassen sich Metadaten und Entitäten automatisch aus unstrukturierten Dateien wie PDFs in Cloud Storage extrahieren. So werden Dark Data und Organisationswissen für KI-Modelle zugänglich.
KI-Halluzinationen reduzieren: Stellen Sie KI-Agents vorab geprüfte Beispielanfragen und semantische Schutzmaßnahmen zur Verfügung, damit sie komplexe Datenabrufe mit deterministischer Genauigkeit ausführen können.
Data Discovery beschleunigen: Mit der semantischen Suche und einem zentralen Kontextdiagramm können Sie relevante Daten-Assets aus unterschiedlichen Quellen für Analyse- und Data-Science-Workflows finden.
Erstellung von Datenprodukten automatisieren: Beziehungen in Ihren Daten ableiten, um Assets in eigenständige Datenprodukte mit integrierten Service Level Agreements (SLAs) und Governance-Einschränkungen zu verpacken.
Beispiel-Workflows in Knowledge Catalog
Um zu sehen, wie Sie Ihren Kontextgraphen erstellen und Ihre Datenbestände verwalten können, sehen Sie sich an, wie ein Onlinehändler die folgenden Knowledge Catalog-Funktionen nutzen könnte:
Daten ermitteln und katalogisieren: Der Einzelhändler nimmt automatisch Transaktionsdaten auf und erfasst Metadaten aus Google Cloud -Diensten wie BigQuery, Pub/Sub und Cloud Storage. Der Dienst importiert auch Metadaten aus benutzerdefinierten Inventardatenbanken, um eine ganzheitliche Übersicht aller Einzelhandelsdaten zu erstellen. Weitere Informationen finden Sie unter Daten ermitteln.
Nach Datenassets suchen Ein Data Scientist findet die benötigten Kundendaten-Assets mithilfe der Knowledge Catalog-Suchmaschine mit facettierter Filterung, semantischer Suche in natürlicher Sprache und logischen Operatoren. Weitere Informationen finden Sie unter Nach Daten-Assets suchen.
Daten mit geschäftlichem Kontext anreichern: Das Team für Data Governance definiert Einzelhandelsterminologie (z. B. „Lifetime-Wert“ oder „Artikelnummer“) mithilfe von Geschäftsglossaren und verwendet KI-basierte Datenstatistiken, um automatisch Beschreibungen für neue Produkttabellen zu generieren. Außerdem wenden sie manuell strukturierte benutzerdefinierte Metadaten und Tags (Aspekte) einheitlich auf ihre Assets an. Weitere Informationen finden Sie unter Aspekte verwalten und Metadaten anreichern und Unternehmensglossar verwalten.
Datenbeziehungen mit Lineage nachvollziehen: Das Engineering-Team verfolgt automatisch die Datenherkunft, um zu sehen, wie sich Bestelldaten in den Systemen bewegen, transformiert und genutzt werden. Sie verwenden Herkunftsgrafiken, um Fehler in Berichtspipelines zu beheben, die Ursache von Fehlern an der Kasse zu analysieren und die Einhaltung von Richtlinien zu gewährleisten. Weitere Informationen finden Sie unter Übersicht über die Datenherkunft.
Datenprofil erstellen und Qualität messen: Der Einzelhändler verwendet die automatische Datenprofilerstellung, um Muster und Anomalien in seinen BigQuery-Preistabellen zu erkennen. Sie definieren und führen Datenqualitätsprüfungen durch, um sicherzustellen, dass die Versandadressen der Kunden für nachgelagerte KI- und Fulfillment-Workloads genau, vollständig und zuverlässig sind. Weitere Informationen finden Sie unter Datenprofilerstellung – Übersicht und Automatische Datenqualität – Übersicht.
Datenprodukte kuratieren und teilen: Das Team der Datenplattform verpackt regionale Vertriebs-Assets und die zugehörigen Metadaten, Qualitätsbewertungen und Herkunft in kuratierte „Customer 360“-Datenprodukte, die von Marketing- und Inventarteams ermittelt und genutzt werden. Weitere Informationen finden Sie unter Datenprodukte – Übersicht.
Knowledge Catalog im Google Cloud -Ökosystem
Beim Aufbau einer Datenbasis ist es wichtig zu verstehen, wie Knowledge Catalog in die zugehörigenGoogle Cloud -Dienste eingebunden wird:
| Dienst | Primäre Rolle | Geeignet für |
|---|---|---|
| Knowledge Catalog | Kontext und Data Governance von KI-Agenten | Zum Katalogisieren von Metadaten, Verwalten der Datenqualität und Bereitstellen einer semantischen Grundlage für KI-Agents. |
| BigQuery | Data Warehouse der Enterprise-Stufe | Zum Speichern, Abfragen und Analysieren großer Datasets. Knowledge Catalog reichert BigQuery-Daten mit Geschäftskontext an. |
| Vertex AI | Plattform für KI und maschinelles Lernen | Damit können Sie ML-Modelle und KI-Agents erstellen und bereitstellen. Agents verwenden Knowledge Catalog APIs, um genauen Unternehmenskontext abzurufen. |
| Cloud Storage | Speicherung unstrukturierter Daten | Zum Speichern von RAW-Dateien. Knowledge Catalog scannt Cloud Storage-Buckets, um durchsuchbare Metadaten und Entitäten zu extrahieren. |
Wichtige Konzepte
Damit Sie den Knowledge Catalog effektiv nutzen können, sollten Sie die folgenden wichtigen Konzepte kennen:
Kontextdiagramm: Eine dynamische, einheitliche Karte, die zeigt, wie Daten mit Ihrem Unternehmen zusammenhängen. Sie verbindet technische Schemas mit Geschäftseinheiten und unstrukturiertem Wissen.
Beispielabfragen Vorgefertigte, geprüfte SQL-Muster, die komplexe Geschäftslogik erfassen. Mit diesen Abfragen können sowohl Menschen als auch KI-Agents Daten genau abfragen, ohne komplexe Tabellenverknüpfungen neu zu erstellen.
Model Context Protocol (MCP) Ein offener Standard, mit dem KI-Agents verfügbare Tools erkennen und adaptiv nutzen können. Knowledge Catalog verwendet MCP-Tools, um zertifizierte Organisationsinformationen direkt an Agents zu senden. Dabei werden sowohl Remote- als auch lokale MCP-Server verwendet, um den Anforderungen an Barrierefreiheit und Sicherheit gerecht zu werden.
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
Aufnahmen
Knowledge Catalog nimmt automatisch Metadaten aus den folgendenGoogle Cloud -Quellen auf. Bei einigen Diensten wie AlloyDB for PostgreSQL und Cloud SQL müssen Sie zuerst die Knowledge Catalog-Integration aktivieren, bevor Metadaten aufgenommen werden können:
Analyse und Lakehouse
- BigQuery-Datasets, -Tabellen, -Ansichten, -Modelle, -Routinen, -Verbindungen und verknüpfte Datasets
- Datenpools und Einträge in BigQuery Sharing (früher Analytics Hub)
- Dataform-Repositories und Code-Assets
- Dataproc Metastore-Dienste, -Datenbanken und -Tabellen
Iceberg-REST-Katalogtabellen (einschließlich Google Cloud Lakehouse-Laufzeitkatalog-IRC, Databricks Unity-IRC, AWS Glue Data Catalog-IRC und Snowflake Horizon-IRC)
KI und maschinelles Lernen
- Vertex AI-Modelle, ‑Datasets, ‑Featuregruppen, ‑Featureansichten und ‑Onlinespeicherinstanzen
Business Intelligence
- Looker (Google Cloud Core)-Instanzen, Dashboards, Dashboardelemente, Looks, LookML-Projekte, Modelle, Explores und Ansichten (Vorschau)
Datenbanken
- Bigtable-Instanzen, ‑Cluster und ‑Tabellen (einschließlich Details zur Spaltenfamilie)
- Spanner-Instanzen, ‑Datenbanken, ‑Tabellen und ‑Ansichten
Streaming und Messaging
- Pub/Sub-Themen
Unstrukturierte Daten
Operative Datenbanken
- AlloyDB for PostgreSQL-Cluster, -Instanzen, -Datenbanken, -Schemas, -Tabellen und ‑Ansichten (Vorabversion). Knowledge Catalog ruft Metadaten nur aus primären AlloyDB for PostgreSQL-Instanzen, nicht aus Lesereplikaten ab. Weitere Informationen finden Sie unter AlloyDB for PostgreSQL-Ressourcen mit Knowledge Catalog verwalten.
- Cloud SQL-Instanzen, ‑Datenbanken, ‑Schemas, ‑Tabellen und ‑Ansichten. Knowledge Catalog ruft Metadaten nur aus primären Cloud SQL-Instanzen, nicht aus Lesereplikaten ab. Weitere Informationen finden Sie unter Cloud SQL-Ressourcen mit Knowledge Catalog verwalten.
Wenn Sie Metadaten aus einer Drittanbieterquelle in Knowledge Catalog importieren möchten, können Sie Knowledge Catalog-Connectors oder eine Pipeline für verwaltete Verbindungen verwenden. Weitere Informationen finden Sie unter Knowledge Catalog-Connectors und Übersicht über verwaltete Verbindungen.
Beschränkungen
Beachten Sie bei der Planung der Bereitstellung die folgenden Einschränkungen:
Unterstützte Integrationen. Der Knowledge Catalog unterstützt zwar wichtige Drittanbietersysteme, bestimmte automatisierte semantische Extraktionen sind jedoch möglicherweise auf integrierte Google Cloud Dienste beschränkt.
Kontingentlimits Für Vorgänge zum Abrufen von Kontext und zum Extrahieren von Metadaten gelten die Standard- Google Cloud API-Kontingente.
Nächste Schritte
Lesen Sie die Einführung in Knowledge Catalog for AI.
Weitere Informationen zur Metadatenverwaltung in Knowledge Catalog