
当您将数据存储在不同的存储系统中时,管理分散的安全性可能会成为一项重大挑战。您需要确保财务记录等敏感信息受到保护,即使您将其以 Apache Iceberg 等开放格式存储在 Google Cloud 存储空间 中也是如此。
至关重要的是,您的安全措施必须在各种查询引擎(如 BigQuery SQL 和 Apache Spark)之间无缝运行。在此架构中,Knowledge Catalog 通过充当通用上下文引擎来解决此问题。它包含所需的元数据,以确保无论哪个引擎查询数据,您的安全上下文都会得到一致应用。
在本教程中,您将构建一个安全的数据湖仓一体,以解决这些挑战。您将使用脚本定义安全政策,并了解 Knowledge Catalog(以前称为 Dataplex Universal Catalog)和 Lakehouse for Apache Iceberg 如何协同工作,以在不同的查询引擎中强制执行这些政策。
架构概览
如需对 Apache Iceberg 等开放表格式设置精细的访问权限控制,您必须创建严格的统一安全架构。
在此设计中,Knowledge Catalog 充当中央控制平面。Knowledge Catalog 会在所有受支持的引擎中动态强制执行您的安全上下文。
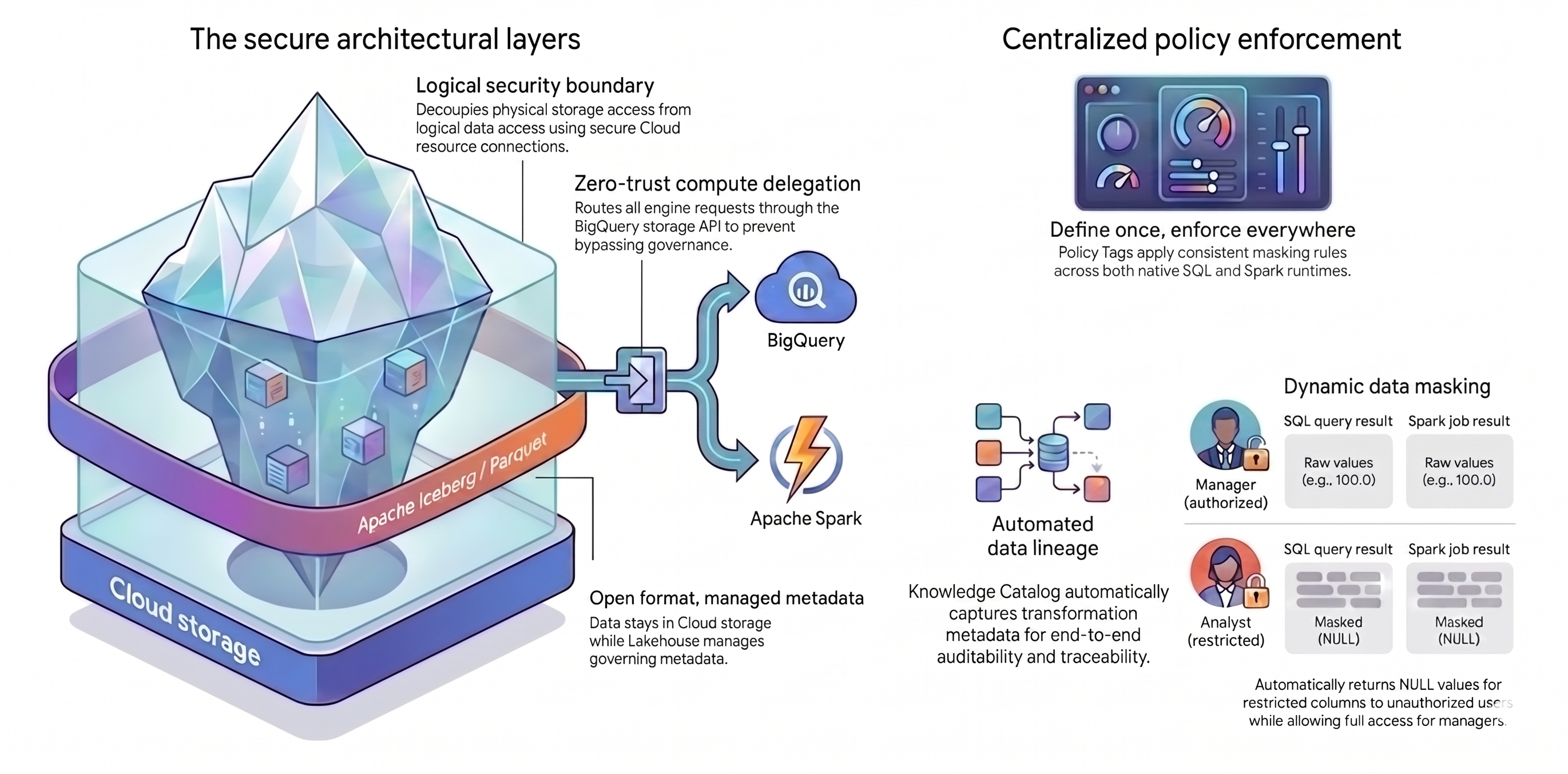
本教程依赖于两个主要概念来创建此统一架构:
- 安全架构层: 您可以构建基于以下属性的安全分层基础,而不是让用户或查询引擎直接访问您的 Cloud Storage 存储分区:
- 具有托管元数据的开放格式: 您的数据以开放的 Apache Iceberg (Parquet) 格式存储在 Cloud Storage 中,而 Lakehouse for Apache Iceberg 管理表元数据。
- 逻辑安全边界: 您可以使用安全的 Cloud 资源连接将存储权限与数据查询分离。您绝不会向最终用户授予对文件的直接访问权限。
- 计算委托: 为防止查询引擎绕过您的规则,您可以通过 BigQuery Storage API 路由所有数据请求。通过 BigQuery Storage API 路由请求可确保 Knowledge Catalog 能够拦截和强制执行政策,即使对于外部处理引擎也是如此。
- 集中式政策执行: 在安全基础就绪后,您可以使用 Knowledge Catalog 普遍应用您的规则:
- 一次定义,处处执行: 您只需在 Knowledge Catalog 中定义一次政策标记,该平台就会在所有受支持的查询引擎中应用一致的遮盖规则。
- 动态数据遮盖: 系统会在查询期间评估用户身份。经过授权的用户会看到原始值,而受限用户会在所有查询引擎中收到
NULL输出。 - 自动数据沿袭: Knowledge Catalog 会自动跟踪数据转换,无需自定义日志记录代码即可创建审核跟踪。
目标
- 创建由 BigQuery 管理的 Apache Iceberg 表。Lakehouse 管理 Iceberg 元数据。
- 使用 政策标记 设置中央安全规则,以遮盖和保护敏感列。
- 使用 Cloud 资源连接将物理存储权限与逻辑数据查询分离。
- 通过 Managed Service for Apache Spark 安全地路由查询,以便外部引擎无法绕过您的安全规则。
- 使用数据沿袭探索数据的交互式地图。
准备工作
在开始之前,请执行以下操作:
- 为此教程选择一个 Google Cloud 项目。
- 确认您的项目已启用结算功能。
准备环境
本教程使用 Cloud Shell,它是在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标。
设置项目变量:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"为两个用户角色(零售分析师和零售经理)定义变量:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)启用必需的 Google Cloud API。
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
下载教程源代码
从 Google Cloud DevRel 代码库下载本教程的 Python 脚本:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
创建存储桶
创建一个新存储桶来存放 Iceberg 表文件:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
准备身份和安全性
在此步骤中,您将通过创建 Cloud 资源连接来设置计算委托。此连接充当 BigQuery 用于管理和读取 Iceberg 文件的安全委托身份。这有助于确保个人用户永远无法直接访问您的 Cloud Storage 存储桶。
运行以下命令以创建连接、检索其自动生成的服务帐号,并向该账号授予管理 Iceberg 数据所需的权限:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
为两个角色(分析师 和经理 )创建服务账号。以下命令将设置这些服务账号,允许当前用户模拟这些账号进行测试,并向其授予运行查询和查看数据的特定角色。
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
创建 Apache Iceberg 表
使用 BigQuery SQL 引擎创建 Apache Iceberg 表。虽然您使用 BigQuery 运行创建命令,但 Lakehouse 充当管理层,用于存储表元数据并保护 Cloud Storage 中的底层 Parquet 文件。
创建表后,您可以运行快速转换,了解 Knowledge Catalog 如何处理安全性并自动跟踪数据历程。
创建 BigQuery 数据集
首先,创建一个 BigQuery 数据集,将您的表分组在一起:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
创建 Iceberg 表
运行以下命令以创建库存表和交易表:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
插入示例数据
将示例数据插入到表中:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
现在,您有两个包含原始示例数据的 Iceberg 表。Lakehouse 管理元数据,但实际的 Parquet 文件位于您的 Cloud Storage 存储桶中。
转换数据以实现自动沿袭
将原始交易汇总为每日销售额摘要。此转换会创建一个新表,并生成 Knowledge Catalog 用于自动映射数据历程的元数据。
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
定义访问权限治理政策
在生产环境中,将安全规则编写为代码(基础架构即代码)可使您的政策可重复使用、受版本控制且更易于维护。在本部分中,您将使用 Google Cloud Python SDK 自动定义和强制执行规则。
准备 Python 虚拟环境
设置隔离的 Python 虚拟环境,以管理依赖项并确保脚本可靠运行:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
定义安全分类和标记
首先为安全规则构建基础。在此步骤中,您将创建一个 分类 作为容器,并创建一个 政策标记 作为敏感数据的特定安全标签。
运行该脚本以创建资源:
python 1_create_taxonomy.py
查看 1_create_taxonomy.py 以了解核心逻辑:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
通过显式设置 FINE_GRAINED_ACCESS_CONTROL 政策类型,您可以将标准元数据标记转换为严格的默认拒绝安全边界。默认情况下,任何带有此标记的列都会拒绝所有用户的访问。
创建动态数据遮盖政策
现在,定义没有权限的用户查询带标记的列时会发生什么情况。创建一个 数据遮盖政策 ,该政策会自动将 分析师 角色的敏感值替换为 NULL。
运行该脚本以配置遮盖规则:
python 2_create_masking.py
在 2_create_masking.py 中,该脚本会查找您创建的政策标记的 ID,并将数据政策应用于 分析师 服务帐号:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
授予对数据的特权访问权限
由于您设置了默认拒绝,因此没有人可以读取带标记的列。您需要明确授予经过授权的用户访问权限。向 经理 角色和您自己的账号授予 Fine-Grained Reader 角色。这样,这些特定用户就可以绕过遮盖规则并读取未遮盖的数据。
运行该脚本以授予访问权限:
python 3_grant_access.py
在 3_grant_access.py 中,该脚本会修改政策标记的 IAM 政策:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
将安全标记附加到表架构
最后,您可以将逻辑规则连接到实际数据。更新 Iceberg 表架构,将政策标记直接附加到 amount 列。完成此操作后,Lakehouse 会立即在存储桶中的 Iceberg 表文件中强制执行保护措施。
运行该脚本以附加政策标记:
python 4_attach_tag.py
查看 4_attach_tag.py。该脚本会提取 BigQuery 表架构,遍历字段,并将标记专门附加到 amount 列:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
验证安全政策
运行一些测试查询,确保权限按预期运行。为了证明 Knowledge Catalog 在您切换查询引擎时会强制执行相同的安全政策,从而充当通用上下文引擎,您可以使用 BigQuery 和 Apache Spark 运行这些测试。
使用 BigQuery SQL 进行测试
首先,直接在 BigQuery 中检查政策。这是确认遮盖规则和权限是否处于活动状态的最快方法。
以经理身份进行检查
经理 角色拥有特权、精细的读取器访问权限。他们应该能够看到表中的每个详细信息,包括 amount 列中的值。
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
由于经理拥有 Fine-Grained Reader 角色,因此查询会显示原始金额值:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
以分析师身份进行检查
切换到 分析师 角色并运行相同的查询。
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
即使您运行相同的查询,Knowledge Catalog 也会遮盖 amount 列中的敏感值:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
返回您的账号
清理 Cloud Shell 身份验证状态,以返回到管理员用户。
gcloud config unset auth/impersonate_service_account
使用 Apache Spark 进行测试
当用户直接访问 Cloud Storage 中的数据文件时,安全性通常会受到破坏。如果数据科学家使用 Apache Spark 直接读取 Iceberg 表文件,他们通常会绕过您的规则,因为 Cloud Storage 仅了解存储桶级权限。
为防止这种情况,请使用计算委托。通过使用 Spark-BigQuery 连接器,您可以创建一个安全桥梁,将所有 Spark 请求通过 BigQuery Storage API 路由。这可确保 Knowledge Catalog 在任何数据到达 Spark 集群之前检查权限并应用遮盖规则。
将 read_transactions.py 脚本上传到 Cloud Storage 存储桶,以便 Managed Service for Apache Spark 可以访问该脚本:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
查看您上传的脚本中的核心逻辑:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
该脚本不会将 Spark 指向 Iceberg 文件的 gs:// 路径。通过指定 .format("bigquery"),BigQuery Storage API 会拦截读取请求,检查运行 Spark 作业的用户的身份,应用 Knowledge Catalog 遮盖规则,并仅将经过授权的数据返回到 Spark DataFrame。
以经理身份运行 Spark
以 经理 角色提交 Spark 作业。使用 Managed Service for Apache Spark,这是一种代管式服务,可让您运行 Spark 工作负载,而无需管理自己的集群:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
在终端中查看作业输出日志。由于经理拥有 Fine-Grained Reader 角色,因此 Spark 成功检索了未遮盖的金额:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
以分析师身份运行 Spark
最后,以 分析师 角色运行相同的 Spark 代码:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
再次查看日志。即使分析师运行了相同的 Spark 代码,BigQuery Storage API 也会拦截请求并强制执行 Knowledge Catalog 政策。分析师的 Spark DataFrame 显示金额为 null。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
您刚刚证明,作为中央控制平面,无论您使用哪个查询引擎,Knowledge Catalog 都会一致地强制执行安全政策。
通过自动沿袭查看数据历程
符合政策的湖仓一体不仅需要访问权限控制,还需要清晰的审核跟踪。数据沿袭 可帮助您了解数据的来源及其转换方式。回答“哪些原始表用于生成此销售报告?”等基本问题有助于您保持合规性、快速调试数据流水线并构建可靠的数据基础。
Knowledge Catalog 会自动跟踪架构中的整个生命周期,而无需手动编写复杂的日志记录代码。例如,当您在本教程前面创建摘要表时,BigQuery 会立即捕获转换详细信息并将其发送到 Knowledge Catalog。这会动态更新数据的上下文和历史记录。
探索交互式沿袭图
查看 Knowledge Catalog 生成的交互式地图。它显示了原始数据如何从 transactions 表流入 transactions_summary 表。由于 Knowledge Catalog 作为动态上下文引擎收集元数据,因此此图显示了数据审核所需的可靠实时可追溯性。
- 在 Google Cloud 控制台中,依次前往 Knowledge Catalog > 搜索。
- 在搜索栏中输入
lakehouse_retail_demo.transactions_summary,然后点击表格。 - 点击沿袭 标签页。
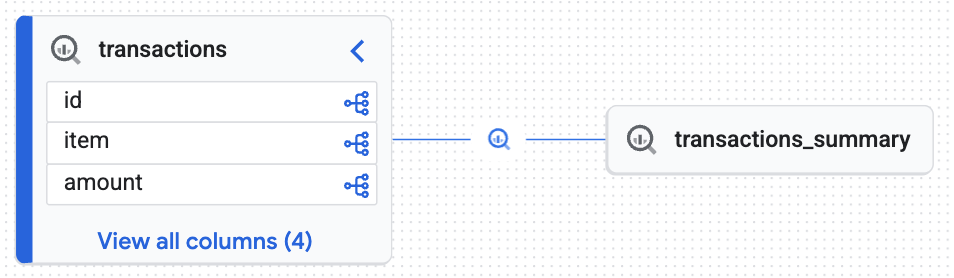
交互式图表确认目标表 (transactions_summary) 源自原始受治理的 Iceberg 表 (transactions)。此可视化图表展示了数据的端到端可追溯性。
清理
为避免持续产生费用,请移除您为此教程创建的资源。
移除政策和元数据资产
您必须先删除数据治理政策和元数据资产,然后才能删除 BigQuery 数据集或 Cloud Storage 存储桶。
运行 Python 清理脚本:
python cleanup_governance.py
查看代码库中的 cleanup_governance.py 脚本,找到以下拆解逻辑。删除顺序至关重要。首先,您需要删除数据遮盖政策。然后,删除父级分类,这会自动移除所有底层政策标记并避免资源依赖项错误。
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
移除身份、存储和计算资产
删除 BigQuery 表、Cloud Storage 存储分区、服务账号和本地 Python 虚拟环境。
在 Cloud Shell 中复制并运行以下清理脚本:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
清理项目文件:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
总结
您已成功构建安全的数据湖仓一体!通过使用 Lakehouse for Apache Iceberg 管理 Iceberg 表,您可以在 Cloud Storage 中确保底层表文件的安全。通过将 Knowledge Catalog 确立为通用上下文引擎,您可以在中心位置定义政策标记,并在不同的查询引擎(如 BigQuery SQL 和 Apache Spark)中一致地应用这些标记。最后,您可以使用实时数据沿袭自动跟踪数据的整个历程。
后续步骤
- 检索 AI 智能体的数据上下文: 使用上下文 API 检索数据上下文。
- 深入了解数据沿袭: 查看数据沿袭信息。
- 探索高级访问权限控制: 如需实现更复杂的安全场景,请查看有关使用其他功能自定义 Lakehouse的官方文档。
- Managed Service for Apache Spark: 在 Serverless Spark 文档页面上了解如何在不预配集群的情况下扩缩数据流水线。
- 尝试其他应用场景:尝试其他 Knowledge Catalog 应用场景。