
本教程介绍了如何使用 Apache Beam YAML 语法创建 Dataflow 数据处理流水线。您将学习如何使用 Google Cloud 控制台中的作业构建器界面从文件中读取数据、应用转换并将结果写入另一个文件。本教程适用于刚开始使用 Apache Beam 或想要了解如何使用 YAML API 构建流水线的开发者。
下表显示了 Google Cloud 控制台中的流水线图及其对应的 YAML 规范。
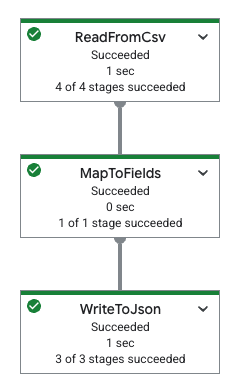
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
目标
在本教程中,您将学习如何执行以下操作:
- 创建可读取、写入和转换数据的 Beam YAML 流水线。
- 根据内容过滤数据。
- 使用 Python 表达式映射字段。
- 使用 SQL 查询和汇总数据。
- 使用 Google Cloud 控制台中的作业构建器界面中的构建器表单构建并运行 Beam YAML 流水线。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用情况来估算费用,请使用价格计算器。
完成本文档中描述的任务后,您可以通过删除所创建的资源来避免继续计费。如需了解详情,请参阅清理。
准备工作
在运行流水线之前,请完成以下步骤。
设置项目
- 登录您的 Google Cloud 账号。如果您是 Google Cloud新手,请 创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.
创建 Cloud Storage 存储桶
您必须先创建一个 Cloud Storage 存储桶,然后才能运行流水线。
创建 Cloud Storage 存储分区,请运行以下命令:
- 在 Google Cloud 控制台中,前往 Cloud Storage 存储分区页面。
- 点击 创建。
- 在创建存储桶页面上,输入您的存储桶信息。要转到下一步,请点击继续。
- 在指定存储桶的名称中,输入唯一的存储桶名称。请勿在存储桶名称中添加敏感信息,因为存储桶命名空间是全局性的,公开可见。
- 在选择数据存储位置部分,执行以下操作:
-
在选择数据存储方式部分中,执行以下操作:
- 在设置默认类别部分,选择以下选项: 标准。
- 如需启用分层命名空间,请在针对数据密集型工作负载优化存储部分中,选择在此存储桶上启用分层命名空间。
- 在选择如何控制对对象的访问权限部分中,选择存储桶是否强制执行禁止公开访问,然后为存储桶对象选择访问权限控制方法。
- 在选择如何保护对象数据部分中,执行以下操作:
- 点击创建。
在后续部分中根据需要复制以下内容:
- 您的 Cloud Storage 存储桶名称。
- 您的 Google Cloud 项目 ID。
如需查找此 ID,请参阅识别项目。
VPC 网络
默认情况下,每个新项目起初都有一个默认网络。如果您的项目的默认网络已停用或者已被删除,则您需要在自己的用户账号具备 Compute Network User 角色 (roles/compute.networkUser) 的项目中拥有网络。
读取、写入和转换数据
本部分展示了如何将 Beam YAML 语法与 Dataflow 结合使用,通过以下方式读取、写入和过滤数据:
- 通过界面驱动的开发,在 Google Cloud 控制台的作业构建器界面中构建和运行作业。具体来说,您将使用作业构建器界面中的构建器表单,因此无需手动创建 YAML 文件。
存储在可公开查看的 Cloud Storage 存储桶中的 CSV 文件数据。此数据包含模拟餐厅菜单数据,如下所示:
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
读取和过滤数据
以下示例展示了如何从 CSV 文件中读取数据、过滤掉特定信息,并将过滤后的数据写入 JSON 文件。
此示例使用 Filter 转换,可让您有选择地保留符合特定条件的数据。以下示例会过滤数据集,仅保留 Price 大于或等于 20.00 的记录。
如需读取 CSV 数据并输出过滤后的 JSON 内容,请完成以下步骤:
在 Google Cloud 控制台中,前往 Dataflow 作业页面。
点击通过构建器创建作业。
在作业构建器标签页上,使构建器表单处于选中状态。
在作业名称字段中,输入
filter-python-job。对于服务类型,请使 批处理处于选中状态。
在来源部分中:
在新来源面板的来源名称字段中,将名称更改为
ReadCsv。在来源类型列表中,选择 Cloud Storage 中的 CSV。
在 CSV 位置字段中,输入:
cloud-samples-data/dataflow/tutorials/restaurant-data.csv点击完成。
在转换部分中:
点击添加转换。
在转换名称字段中,输入
FilterPrice。在转换类型列表中,选择过滤 (Python)。
在 Python 过滤表达式字段中,输入
Price >= 20.00。在转换的输入步骤列表中,保持
ReadCsv处于选中状态。点击完成。
在 Sinks 部分中:
在接收器名称字段中,将名称更改为
WriteJson。在接收器类型列表中,选择 Cloud Storage 中的 JSON 文件。
在 JSON 位置字段中,输入:
BUCKET_NAME/output/restaurant-data_filtered.json将
BUCKET_NAME替换为您的 Cloud Storage 存储分区的名称。在接收器的输入步骤列表中,保持
FilterPrice处于选中状态。点击完成。
在 Dataflow 选项部分中,点击运行作业图标 。
检查作业输出
作业完成后,请完成以下步骤来查看流水线的输出:
在 Google Cloud 控制台中,前往 Cloud Storage 存储桶页面。
在存储桶列表中,点击您在创建 Cloud Storage 存储桶中创建的存储桶的名称。
点击名为
restaurant-data_filtered.json-00000-of-00001的文件。在对象详情页面中,点击经过身份验证的网址以查看流水线输出。
输出应类似如下所示:
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
使用 Python 映射字段
借助 MapToFields 转换,您可以根据现有字段创建新字段。以下示例创建了菜单项的小写版本,计算了总价,并将这些值附加到现有值之后。
前往Google Cloud 控制台中的 Dataflow 作业页面。
点击 通过构建器创建作业。
在作业构建器标签页上,使构建器表单处于选中状态。
在作业名称字段中,输入
map-python-job。对于服务类型,请使 批处理处于选中状态。
在来源部分中:
在新来源面板的来源名称字段中,将名称更改为
ReadFromCsvPy。在来源类型列表中,选择 Cloud Storage 中的 CSV。
在 CSV 位置字段中,输入:
cloud-samples-data/dataflow/tutorials/restaurant-data.csv点击完成。
在转换部分中:
点击添加转换。
在转换名称字段中,输入
MapToFieldsPy。在转换类型列表中,选择映射字段 (Python)。
保持选中保留现有字段。
在映射的字段部分中,点击添加字段。
在随即打开的新字段面板中,将
Lowercase_menu_item作为字段名称。在 Python 表达式字段中,输入
Item.lower()。点击完成。
在同一映射字段部分中,再次点击添加字段。
在随即打开的新字段面板中,将
Total_price作为字段名称。在 Python 表达式字段中,输入
Price + Tax。在此新字段面板中,点击完成。
在此新建转换面板中,点击完成。
在接收器部分中:
在接收器名称字段中,将名称更改为
WriteToJsonPy。在接收器类型列表中,选择 Cloud Storage 中的 JSON 文件。
在 JSON 位置字段中,输入:
BUCKET_NAME/output/restaurant-data_map-fields.json将
BUCKET_NAME替换为您的 Cloud Storage 存储分区的名称。在接收器的输入步骤列表中,保持
MapToFieldsPy处于选中状态。点击完成。
在 Dataflow 选项部分中,点击运行作业图标 。
检查作业输出
作业完成后,请完成以下步骤来查看流水线的输出:
在 Google Cloud 控制台中,前往 Cloud Storage 存储桶页面。
在存储桶列表中,点击您在创建 Cloud Storage 存储桶中创建的存储桶的名称。
点击名为
restaurant-data_map-fields.json-00000-of-00001的文件。在对象详情页面中,点击经过身份验证的网址以查看流水线输出。
输出应类似如下所示:
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
使用 SQL 转换数据
借助 Sql 转换,您可以对数据运行 SQL 查询。以下示例按类别(例如 Entree、Beverage 或 Dessert)对菜单项进行分组,并添加一个列来显示每个类别中的项目数量。
如需使用作业构建器界面创建流水线,请按以下步骤操作:
前往 Google Cloud 控制台中的 Dataflow 作业页面。
点击 通过构建器创建作业。
在作业构建器标签页的作业名称字段中,输入
sql-transform-job。对于服务类型,请使 批处理处于选中状态。
在来源部分中:
在来源名称字段中,将名称更改为
SqlTransformSource。在新来源标签页中,对于来源类型,选择 Cloud Storage 中的 CSV。系统会打开 CSV 位置字段。
对于 CSV 位置,输入:
cloud-samples-data/dataflow/tutorials/restaurant-data.csv点击完成。
在转换部分中:
点击添加转换。
在转换名称字段中,将名称更新为
SqlTransform。对于转换类型,请选择 SQL 转换。系统会打开 SQL 转换选项。
在 SQL 表达式字段中,输入:
select Category, count(*) as category_count from PCOLLECTION group by Category点击完成。
在接收器部分中:
对于接收器名称,输入
SqlTransformSink。对于接收器类型,选择 Cloud Storage 中的 JSON 文件。系统会打开将数据写入 Cloud Storage 中的 JSON 文件选项。
对于 JSON 位置,输入:
BUCKET_NAME/output/restaurant-data_transform-sql.json将
BUCKET_NAME替换为您的 Cloud Storage 存储分区的名称。点击完成。
可选:查看为此流水线生成的 YAML 定义。
前往作业构建器标签页的顶部。
选择 YAML 编辑器。您应该会看到 YAML 定义。它应如下所示:
生成的 YAML 规范
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
在 Dataflow 选项部分中,点击运行作业。
检查作业输出
作业完成后,请完成以下步骤来查看流水线的输出:
在 Google Cloud 控制台中,前往 Cloud Storage 存储桶页面。
在存储桶列表中,点击您在创建 Cloud Storage 存储桶中创建的存储桶的名称。
点击名为
restaurant-data_transform-sql.json-00000-of-00001的文件。在对象详情页面中,点击经过身份验证的网址以查看流水线输出。
输出应类似如下所示:
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
清理
为避免因本教程中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留项目但删除各个资源。
删除项目
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
逐个删除资源
如果您希望以后重复使用该项目,可以保留该项目,但删除在本教程中创建的资源。
停止 Dataflow 流水线
在 Google Cloud 控制台中,前往 Dataflow 作业页面。
点击要停止的作业。
要停止作业,作业状态必须为正在运行。
在作业详情页面上,点击停止。
点击取消。
要确认您的选择,请点击停止作业。
删除您的 Cloud Storage 存储桶
- 在 Google Cloud 控制台中,前往 Cloud Storage 存储分区页面。
- 点击要删除的存储分区对应的复选框。
- 如需删除存储分区,请点击删除,然后按照说明操作。
后续步骤
- 如需详细了解如何使用 Google Cloud 控制台中的作业构建器界面概览创建作业,请参阅相关文档。
- 如需了解作业构建器自定义作业,请参阅通过作业构建器创建自定义作业。
- 阅读 Beam YAML API 概览。
- 查看更多 Beam YAML 示例。