このページでは、Dataflow でサポートされている GPU 指標について説明します。これらの指標を使用して、GPU の健全性と使用状況をモニタリングできます。ほとんどの指標はすべての Dataflow ジョブでサポートされていますが、一部の指標では多くの GPU モデルで追加の構成が必要になります。
前提条件
GPU 指標は、GPU を明示的にリクエストした Dataflow ジョブでのみ収集されます。詳細については、 GPU のサポートをご覧ください。
概要
Dataflow は多くの GPU 指標をレポートしますが、主な指標は合計メモリと使用済みメモリです。これらは RAM 指標に相当します。また、ストリーミング マルチプロセッサ(SM)アクティビティと SM 占有率は、Dataflow CPU 指標に最も近い指標です。その他の指標については、 一般的な指標と GPM 指標をご覧ください。
ジョブのすべての GPU デバイスの合計メモリと使用済みメモリは、デフォルトでレポートされます。Dataflow モニタリング インターフェースでは、[基本的な GPU 使用率] に表示されます。これらの指標は、基本的な GPU 指標にもある [メモリアクセス率] とは異なりますが、GPU デバイスのメモリがアクセスされた時間の割合をレポートします。
SM アクティビティと SM 占有率は GPM 指標です。これらの指標は P4 デバイスと P100 デバイスではサポートされておらず、H100 デバイス以降ではデフォルトでサポートされています。T4 デバイスや L4 デバイスなど、他のすべてのデバイスでは、追加の設定が必要です。 有効にする手順については、GPM の収集をご覧ください。ジョブで収集された場合、これらの指標は Dataflow モニタリング インターフェースの [GPU の GPM 使用率] に表示されます。
Dataflow GPU 指標の基本
すべての GPU 指標は、Dataflow ワーカーによって Cloud Monitoring に送信されます。デバイスごとの指標は、dataflow.googleapis.com/worker/accelerator/gpu にあります。これらの指標はすべて、使用率や温度などの一般的なカテゴリにグループ化されており、すべてに次のラベルが付いています。
- device_uuid: ワーカーや パイプラインに関係なく、GPU デバイスを一意に識別します。
- device_number: ワーカーのデバイスに割り当てられた番号。 範囲は [0, N) です。N はワーカーの GPU デバイスの数です。
- device_model: GPU のモデル(「Tesla T4」など)。
device_uuid と device_model はどちらもワーカーに依存せず、同じ実機では常に同じです。device_number は、ワーカーでの識別方法に関連付けられています。
Dataflow の一般的な GPU 指標
一般的な指標は、GPU を使用するすべての Dataflow ジョブによってレポートされます。 Monitoring では、すべて次の形式を使用します。
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
次の表に、各指標とそのカテゴリ、名前、単位、目的を示します。
| 指標 | カテゴリ | 名前 | ユニット | 説明 |
|---|---|---|---|---|
| カーネルの実行率 | 使用率 | device_kernel_runtime | Percent | GPU で 1 つ以上のカーネルが実行されていた時間の割合。これは、GPU が使用されていたことを示しているだけで、処理リソースが効率的に使用されているかどうかは示していません。 |
| メモリアクセス率 | 使用率 | device_memory_access | Percent | デバイスメモリが読み取りまたは書き込みされた時間の割合。これは、メモリがアクセスされたことを示しているだけで、使用中のメモリの割合は示していません。 |
| メモリ制限 | メモリ | device_limit | MiB | GPU で使用可能なメモリ量。 |
| メモリ使用量 | メモリ | device_usage | MiB | GPU で使用されているメモリ量。これには、Dataflow ジョブで使用されるメモリとファームウェア用に予約されたメモリの両方が含まれます。そのため、まだ GPU にメモリが転送されていない場合でも、ある程度の使用量が想定されます。 |
| 訂正可能な揮発性 ECC エラー | memory/ecc/volatile | device_correctable_total | カウント | 最後のドライバの再読み込み以降に発生した、訂正可能な(シングルビット)ECC エラーの数。Dataflow の場合、ドライバの再読み込みはワーカーの起動時にのみ行われるため、これはワーカーのライフサイクル全体にわたるエラーに相当します。 |
| 訂正不可能な揮発性 ECC エラー | memory/ecc/volatile | device_uncorrectable_total | カウント | 最後のドライバの再読み込み以降に発生した、訂正不可能な(ダブルビット)ECC エラーの数。Dataflow の場合、ドライバの再読み込みはワーカーの起動時にのみ行われるため、これはワーカーのライフサイクル全体にわたるエラーに相当します。 |
| 電力制限 | power | device_limit | ワット | デバイスが使用するように設定されている最大電力。Dataflow では、デフォルトから変更されません。 |
| 電力消費量 | power | device_usage | ワット | デバイスで使用されている電力。 |
| 現在の温度 | 温度 | device_current | 摂氏 | GPU の現在の温度。 |
| 最高動作温度 | 温度 | device_max_op | 摂氏 | GPU が維持される温度。現在の温度がこの温度を超えると、GPU ドライバはこの温度を下回るまで GPU を冷却しようとします。Dataflow はこれを制御しません。 |
| スローダウン温度 | 温度 | device_slowdown | 摂氏 | GPU がスロットリングを開始する温度。現在の温度がこの温度を超えると、冷却されるまでパフォーマンスが低下します。Dataflow はこれを制御しません。 |
| シャットダウン温度 | 温度 | device_shutdown | 摂氏 | GPU がシャットダウンする温度。現在の温度がこの温度を超えると、デバイスは使用できなくなります。Dataflow はこの温度を制御しません。また、温度が高すぎるためにシャットダウンした GPU を復旧しようとすることもありません。 |
| 現在の SM クロック | 時計 | device_sm_current | MHz | SM クロックの現在の速度。温度がスローダウンのしきい値を超えると、冷却関連のスロットリングの一環として低下する可能性があります。 |
| 最大 SM クロック | 時計 | device_sm_max | MHz | SM クロックの最大速度。 |
| 現在のメモリ クロック | 時計 | device_memory_current | MHz | メモリ クロックの現在の速度。温度がスローダウンのしきい値を超えると、冷却関連のスロットリングの一環として低下する可能性があります。 |
| 最大メモリ クロック | 時計 | device_memory_max | MHz | メモリ クロックの最大速度。 |
Dataflow の GPM 指標
Dataflow は GPM 指標をサポートしています。サポートのレベルは、GPU モデルとアクセラレータの構成によって異なります。デフォルトでは、GPU を使用するほとんどの Dataflow ジョブで追加の構成が必要になります。
GPM 指標は、一般的な指標と同じ基本に従います。
サポートされている指標
一般的な指標と同様に、GPM 指標パスの形式は次のとおりです。
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
これらの指標の一部は、一般的な指標と同じカテゴリにあります。
| 指標 | カテゴリ | 名前 | ユニット | 説明 |
|---|---|---|---|---|
| SM アクティビティ | 使用率 | device_sm_activity | Percent | デバイス上のすべての SM で、Warp がアクティブだった時間の割合の平均。これはカーネルの実行率に似ていますが、GPU のリソースが効率的に使用されているかどうかをより詳細に把握できます。NVIDIA は、80% 以上を効果的な使用、50% 以下を非効率的な使用と定義しています。 |
| SM 占有率 | 使用率 | device_sm_occupancy | Percent | 最大値に対するデバイス上のアクティブな Warp の割合。メモリ制限のあるジョブは、コンピューティング制限のあるジョブよりも占有率が高くする必要があります。メモリアクセス率の指標で、これを確認できます。詳細については、NVIDIA のドキュメントの達成された占有率をご覧ください。 |
| Tensor パイプ アクティビティ | 使用率 | device_tensor_pipe_activity | Percent | Tensor Core パイプが使用されていた時間の割合。値が高いほど、行列演算に重要な GPU の Tensor Core の使用量が多くなります。 |
| FP64 パイプ アクティビティ | 使用率 | device_fp64_pipe_activity | Percent | FP64 Core パイプが使用されていた時間の割合。値が高いほど、64 ビット浮動小数点値のスカラー演算を処理する GPU の FP64 Core の使用量が多くなります。 |
| FP32 パイプ アクティビティ | 使用率 | device_fp32_pipe_activity | Percent | FP32 Core パイプが使用されていた時間の割合。値が高いほど、32 ビット浮動小数点値のスカラー演算を処理する GPU の FP32 Core の使用量が多くなります。 |
| FP16 パイプ アクティビティ | 使用率 | device_fp16_pipe_activity | Percent | FP16 パイプが使用されていた時間の割合。FP64 と FP32 はそれぞれ 64 ビットと 32 ビットの CUDA コアに関連付けられていますが、FP16 は Tensor Core の半精度機能を活用することに関連付けられています。 |
| PCIe 読み取り | pcie | device_read | MiB/秒 | PCIe 経由で GPU がホスト VM から読み取るデータの速度。 |
| PCIe 転送 | pcie | device_transfer | MiB/秒 | PCIe 経由で GPU からホスト VM に転送されるデータの速度。 |
| NVLink 読み取り | nvlink | device_read | MiB/秒 | NVLink 経由で GPU が読み取るデータの速度。NVLink は GPU 間通信のみを対象としているため、各ワーカーに GPU が 1 つしかない場合は関係ありません。 |
| NVLink 転送 | nvlink | device_transfer | MiB/秒 | NVLink 経由で GPU から転送されるデータの速度。NVLink は GPU 間通信のみを対象としているため、各ワーカーに GPU が 1 つしかない場合は関係ありません。 |
GPM 指標の収集
Hopper アーキテクチャ以降(H100、H100 Mega など)を使用する GPU を搭載した Dataflow ジョブは、デフォルトで GPM 指標を収集するため、追加の構成は必要ありません。ただし、Pascal アーキテクチャ以前(P4、P100 など)を使用するジョブでは、これらの指標はサポートされていません。
他のすべてのモデルでこれらの指標を収集するには、ワーカー アクセラレータ構成に install-gke-dcgm-exporter を追加する必要があります。次に例を示します。
--experiment="worker_accelerator=type:TYPE;count:COUNT;install-nvidia-driver;install-gke-dcgm-exporter"
このフラグは、 NVIDIA DCGM エクスポータに相当する GKE マネージドをインストールします。次のタイプでは、このオプションがサポートされています。
- nvidia-l4
- nvidia-tesla-a100
- nvidia-a100-80gb
- nvidia-tesla-t4
- nvidia-tesla-v100
別のタイプを指定すると、Dataflow サービスはジョブの作成時にエラーを返します。このチェックにより、指標の収集に役立たないジョブでコンテナを実行することを回避できます。
以前の指標
Monitoring では、dataflow.googleapis.com/job/gpu_utilization と dataflow.googleapis.com/job/gpu_memory_utilization という 2 つの指標が表示されることがあります。これらの指標は、それぞれ
カーネルの実行率とメモリアクセス率
に似ていますが、ワーカーはワーカーの GPU 全体で平均してレポートします。特にワーカーが複数の GPU を持つように構成されている場合は、デバイスごとの同等の指標を使用することをおすすめします。
Dataflow UI
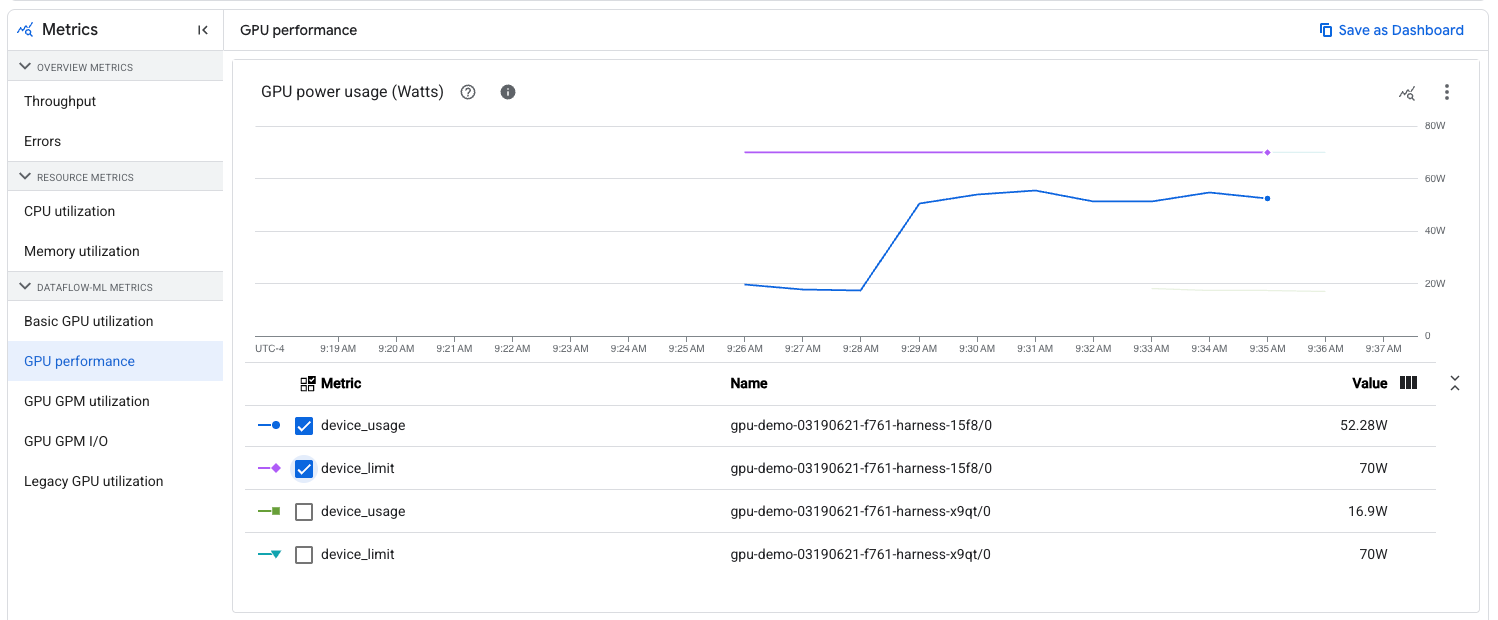
Dataflow ジョブのワーカーに GPU が接続されている場合、指標はジョブページの [ジョブの指標] タブの [Dataflow ML] カテゴリに表示されます。このカテゴリは、GPU を使用しないジョブには表示されません。また、指標がジョブに関連していることを最初に確認するため、読み込みに数秒かかります。
[Dataflow ML] には、次のサブカテゴリが表示されます。
| サブカテゴリ | 指標 | 条件 |
|---|---|---|
| 基本的な GPU 使用率 | カーネルの実行率 メモリアクセス率 合計メモリ/使用済みメモリ |
すべての GPU ジョブ |
| GPU パフォーマンス | 電力消費/制限 温度の読み取り/制限 現在の SM クロック/最大 SM クロック 現在のメモリ クロック/最大メモリ クロック 訂正可能な揮発性 ECC エラー/訂正不可能な揮発性 ECC エラー |
すべての GPU ジョブ |
| GPU の GPM 使用率 | SM アクティビティ SM 占有率 CUDA/Tensor パイプ アクティビティ |
GPM 指標が有効 |
| GPU の GPM I/O | PCIe 読み取り/転送 NVLink 読み取り/転送 |
GPM 指標が有効 |
| 以前の GPU 使用率 | 以前の指標 | すべての GPU ジョブ |
以前の指標以外の指標を表示する場合は、グラフを特定のワーカー名と GPU デバイス番号でフィルタできます。Compute Engine で表示する場合、ワーカー名は VM と同じ名前です。GPU デバイス番号は、指標ラベルと同じです 。このフィルタリングを使用して、特定の GPU デバイスの指標を確認できます。たとえば、電力使用量が制限にどの程度近いかを確認できます。