
I workspace di conversione consentono di trasformare lo schema e gli oggetti del database di origine nella sintassi SQL compatibile con il database di destinazione. Questa pagina fornisce una panoramica degli spazi di lavoro di conversione di Database Migration Service:
Le panoramiche delle conversioni forniscono una sezione trasversale dello stato di avanzamento della conversione dello schema.
Oggetti supportati dalla conversione deterministica di codice e schema elenca gli oggetti Oracle supportati per la conversione deterministica dello schema.
Editor SQL interattivo descrive gli oggetti che puoi modificare direttamente nell'editor dell'area di lavoro di conversione.
Le funzionalità di conversione basate su Gemini mostrano come integrare il supporto dell'AI generativa per accelerare il processo di conversione dello schema.
La sezione File di mappatura delle conversioni fornisce una panoramica delle direttive di personalizzazione che puoi utilizzare per eseguire l'override delle regole di conversione deterministica dello schema.
Workspace di conversione legacy descrive le workspace legacy che non forniscono supporto per l'editor SQL interattivo.
Esistono alcuni tipi di dati non supportati per le migrazioni Oracle. Per ulteriori informazioni, vedi Limitazioni note per i tipi di dati.
Panoramiche dello stato di avanzamento della conversione
Informazioni di riepilogo dettagliate delle aree di lavoro di conversione, dove puoi ottenere approfondimenti sul numero totale di problemi di conversione in sospeso o risolti, sui miglioramenti assistiti da Gemini e sullo stato generale del processo di conversione.
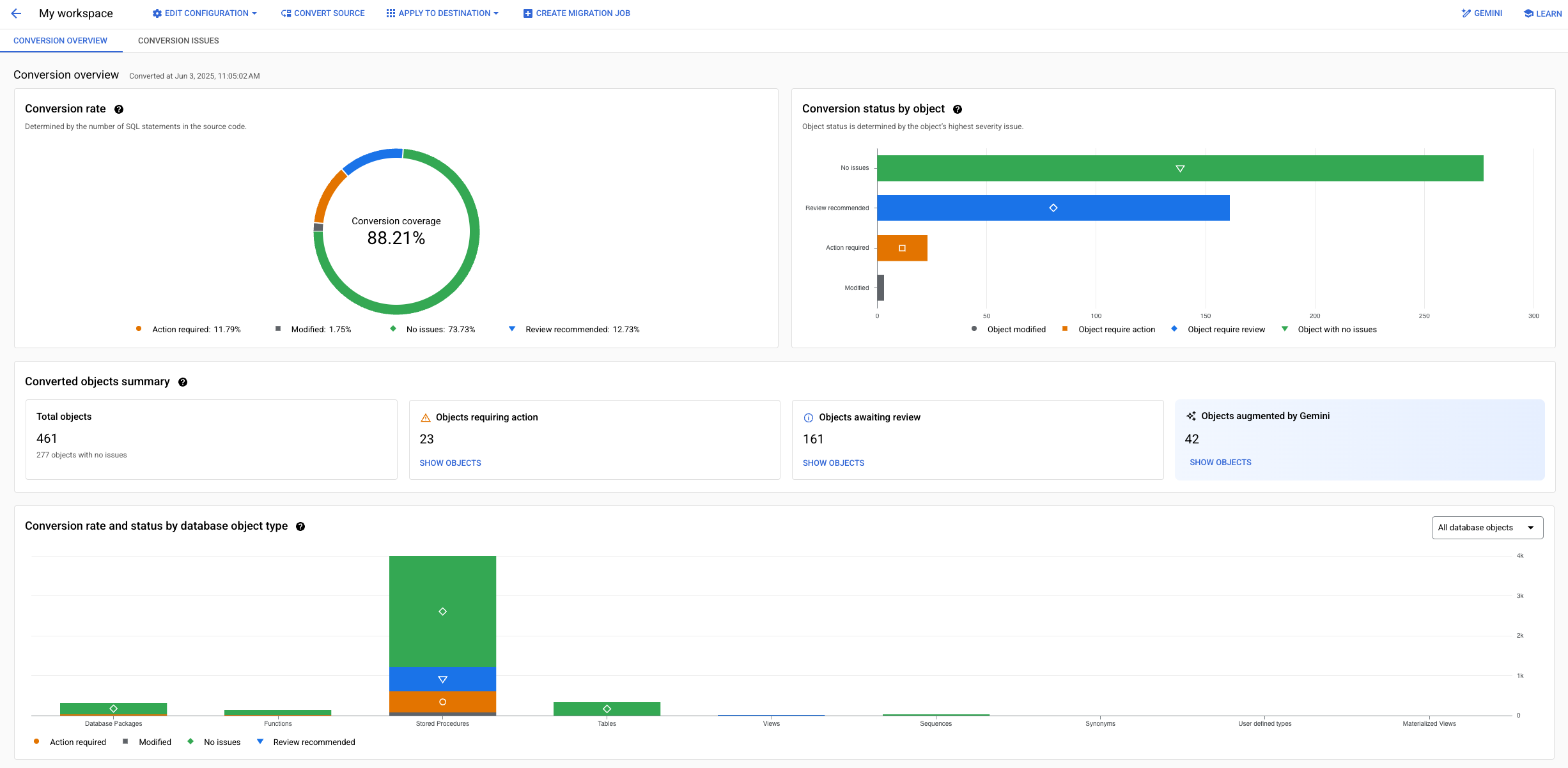
Puoi utilizzare questa visualizzazione per filtrare gli oggetti nello schema in base a tipo, gravità del problema, azioni necessarie o stato della conversione.

Per ulteriori informazioni sull'utilizzo delle panoramiche delle conversioni per esaminare i risultati delle conversioni, consulta Utilizzare i workspace di conversione.
Conversione deterministica di codice e schema
Quando crei un workspace di conversione, Database Migration Service esegue immediatamente la conversione iniziale dello schema utilizzando un insieme di regole di conversione deterministiche in cui tipi di dati e oggetti Oracle specifici vengono mappati a tipi di dati e oggetti PostgreSQL specifici. Questa procedura supporta un sottoinsieme molto specifico degli oggetti di database Oracle disponibili.
La conversione deterministica del codice fornisce il supporto per i seguenti oggetti del database Oracle:
Elementi dello schema Oracle supportati
- Vincoli
- Indici (solo gli indici creati nello stesso schema della tabella)
- Viste materializzate
- Tipi di oggetti (supporto parziale)
- Sequenze
- Sinonimi
- Tabelle
- Visualizzazioni
Elementi di codice Oracle supportati
- Trigger (solo a livello di tabella)
- Pacchetti
- Funzioni
- Stored procedure
Editor SQL interattivo
L'editor SQL interattivo ti consente di modificare la sintassi PostgreSQL convertita direttamente in Database Migration Service. Puoi utilizzarlo per risolvere i problemi di conversione o modificare lo schema in base alle tue esigenze. Alcuni oggetti non possono essere modificati nell'editor integrato.
Oggetti Oracle modificabili
Dopo aver convertito il codice e lo schema del database di origine, puoi utilizzare l'editor interattivo per modificare il codice SQL generato per determinati tipi di oggetti. I seguenti oggetti Oracle sono supportati dall'editor:
- Trigger di tabella (richiede l'autorizzazione)
- Viste materializzate
- Pacchetti
- Funzioni, stored procedure
- Sinonimi
- Visualizzazioni
- Vincoli
- Indici
- Sequenze
Inoltre, alcuni oggetti vengono convertiti, ma non sono disponibili per la modifica diretta in Database Migration Service. Per modificare questi oggetti, devi eseguire gli aggiornamenti direttamente sul database di destinazione dopo aver applicato lo schema e il codice convertiti.
Oggetti non supportati per la modifica:
- Tipi di oggetti definiti dall'utente
- Tabelle
- Schemi
Accelerare la conversione di codice e schema con Gemini
Database Migration Service integra Gemini per Google Cloud negli workspace di conversione per aiutarti ad accelerare e migliorare il processo di conversione nelle seguenti aree:
Migliora i risultati della conversione deterministica con la conversione automatica basata su Gemini per sfruttare la potenza dell'AI e ridurre significativamente il numero di aggiustamenti manuali necessari nel codice PostgreSQL.
Garantisci la qualità e l'equivalenza funzionale del codice convertito con le valutazioni della qualità basate su Gemini. Queste valutazioni analizzano il codice convertito, fornendo feedback sulla sua correttezza e funzionalità rispetto al codice sorgente.
Fornisci funzionalità di spiegabilità del codice con l'assistente alla conversione: un insieme di prompt dedicati che possono aiutarti a comprendere meglio la logica di conversione, proporre correzioni per i problemi di conversione o ottimizzare il codice convertito.
Accelera l'applicazione delle correzioni per i problemi di conversione con i suggerimenti per la conversione del codice di Gemini: un meccanismo in cui il modello Gemini può imparare mentre correggi i problemi di conversione e suggerire modifiche ad altri oggetti difettosi nello spazio di lavoro.
Per ulteriori informazioni sulla conversione basata su Gemini, consulta le seguenti pagine:
File di mappatura delle conversioni
Puoi personalizzare la logica di conversione con un file di mappatura delle conversioni. Il file di mappatura della conversione è un file di testo che contiene istruzioni precise (denominate direttive di conversione) su come convertire gli oggetti Oracle in oggetti PostgreSQL.
Direttive sulle conversioni supportate
Database Migration Service supporta le seguenti direttive di conversione per i file di mapping della conversione:
EXPORT_SCHEMA
EXPORT_SCHEMA è una direttiva obbligatoria per tutti i file di mappatura delle conversioni. Database Migration Service richiede questa istruzione per garantire
che gli schemi di origine vengano convertiti negli schemi di destinazione corretti.
Assicurati che i file di mappatura delle conversioni includano questa riga:
EXPORT_SCHEMA 1
SCHEMA
Database Migration Service deve essere in grado di determinare quale schema contiene
gli oggetti da modificare con le direttive di conversione.
La direttiva SCHEMA fa sì che tutte le altre direttive di personalizzazione
fornite nel file vengano applicate agli oggetti di questo schema specifico.
- Quando utilizzi questa direttiva, vengono convertiti anche altri schemi contenuti nel database, ma i relativi oggetti non sono soggetti ad alcuna modifica.
- Se includi questa direttiva nel file di mappatura delle conversioni, tutte le personalizzazioni vengono applicate solo agli oggetti contenuti in questo schema specifico.
- Se salti questa direttiva, devi fornire nomi di oggetti completi
che includano il nome dello schema per gli oggetti modificati da altre direttive di conversione.
Ad esempio, invece di utilizzare
SOURCE_TABLE_NAMEper la direttivaREPLACE_TABLES, dovrai utilizzare"SCHEMA_NAME.SOURCE_TABLE_NAME". - Per personalizzare gli oggetti in schemi diversi, prova a seguire questi passaggi:
- Crea file di mapping della conversione separati per altri schemi e caricali nell'area di lavoro della conversione.
- Utilizza nomi di oggetti completi che includano il nome dello schema per gli oggetti che si trovano in schemi diversi da quello fornito alla direttiva
SCHEMA.
Utilizza il formato seguente:
SCHEMA SCHEMA_NAME
Dove SCHEMA_NAME è il nome dello schema nel database di origine.
CASE_HANDLING
Per impostazione predefinita, Database Migration Service converte tutti i nomi degli oggetti in minuscolo.
Puoi utilizzare la direttiva CASE_HANDLING per modificare questo
comportamento.
- Questa direttiva non è interessata dalla direttiva
SCHEMA. Funziona a livello globale e interessa tutti gli oggetti nell'area di lavoro di conversione. - Le direttive
RENAME_*,MOVE_*eREPLACE_*hanno la precedenza sulla direttivaCASE_HANDLINGe rinominano gli oggetti esattamente, indipendentemente dalla proprietàCASE_HANDLING. - Se questa direttiva esiste in più file di configurazione con valori in conflitto, Database Migration Service genera un errore durante l'importazione dello schema.
Utilizza il formato seguente:
CASE_HANDLING OPTION
Dove OPTION può essere uno dei seguenti valori:
UPPERCASE: converte tutti i nomi degli oggetti in maiuscolo.LOWERCASE: converte tutti i nomi degli oggetti in minuscolo (comportamento predefinito).PRESERVE_ORIGINAL: mantiene la formattazione originale dello schema di origine. Questo è utile se le tue applicazioni utilizzano identificatori sensibili alle maiuscole.
Esempio:
CASE_HANDLING PRESERVE_ORIGINAL
GENERATE_MISSING_PK
Le tabelle senza chiavi primarie non garantiscono una replica coerente. Database Migration Service esegue la migrazione solo delle tabelle con chiavi primarie. Per impostazione predefinita, gli spazi di lavoro della conversione di Database Migration Service creano automaticamente le chiavi primarie mancanti nelle tabelle di destinazione quando converti il codice sorgente e lo schema.
Puoi controllare la generazione automatica della chiave primaria con la
direttiva GENERATE_MISSING_PK. Per disattivare la generazione
automatica delle chiavi, imposta questa direttiva su 0.
Esempio:
GENERATE_MISSING_PK 0
Questa direttiva influisce su tutti gli oggetti di uno specifico workspace di conversione. Non è possibile disattivare la generazione automatica della chiave primaria solo per una tabella specifica.
Database Migration Service può eseguire la migrazione solo delle tabelle che hanno vincoli di chiave primaria nelle versioni PostgreSQL convertite. Se disattivi la generazione automatica di chiave primaria, devi creare manualmente chiavi primarie o vincoli univoci nelle tabelle convertite nel database di destinazione dopo aver applicato lo schema convertito. Espandi le sezioni seguenti per visualizzare esempi di comandi SQL.
Creare chiavi primarie utilizzando le colonne esistenti
La tabella potrebbe già avere una chiave primaria logica basata su una colonna o una combinazione di colonne. Ad esempio, potrebbero esserci colonne con un vincolo o un indice univoco configurato. Utilizza queste colonne per generare una nuova chiave primaria per le tabelle nel database di origine. Ad esempio:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME);
Crea una chiave primaria utilizzando tutte le colonne
Se non hai un vincolo preesistente che possa fungere da chiave primaria, crea chiavi primarie utilizzando tutte le colonne della tabella. Assicurati di non superare la lunghezza massima della chiave primaria consentita dal cluster PostgreSQL. Ad esempio:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME_1, COLUMN_NAME_2, COLUMN_NAME_3, ...);
Quando crei una chiave primaria composita come questa, devi elencare esplicitamente tutti i nomi delle colonne che vuoi utilizzare. Non è possibile utilizzare un'istruzione per recuperare tutti i nomi delle colonne a questo scopo.
Crea un vincolo univoco con la pseudocolonna ROWID
I database Oracle utilizzano la
pseudocolonna ROWID per memorizzare
la posizione di ogni riga in una tabella. Per eseguire la migrazione delle tabelle Oracle
che non hanno chiavi primarie, puoi aggiungere una colonna ROWID
nel database PostgreSQL di destinazione. Database Migration Service
compila la colonna con i valori numerici corrispondenti della
pseudocolonna ROWID di Oracle di origine.
Per aggiungere la colonna e impostarla come chiave primaria, esegui il comando seguente:
ALTER TABLE TABLE_NAME ADD COLUMN rowid numeric(33,0) NOT NULL; CREATE SEQUENCE TABLE_NAME_rowid_seq INCREMENT BY -1 START WITH -1 OWNED BY TABLE_NAME.rowid; ALTER TABLE TABLE_NAME ALTER COLUMN rowid SET DEFAULT nextval('TABLE_NAME_rowid_seq'); ALTER TABLE TABLE_NAME ADD CONSTRAINT CONSTRAINT_DISPLAY_NAME PRIMARY KEY (rowid);
Ridenominazione degli oggetti (RENAME_*)
Puoi rinominare diversi oggetti di database durante la conversione. Database Migration Service aggiorna automaticamente tutti i riferimenti al codice (in viste, stored procedure, funzioni e così via) per utilizzare i nuovi nomi.
Sintassi generale
RENAME_OBJECT_TYPE SOURCE_NAME1:DESTINATION_NAME1 SOURCE_NAME2:DESTINATION_NAME2 ...
Considerazioni importanti
-
Le direttive
RENAME_*sono sensibili alle maiuscole per il nome dell'oggetto di destinazione e hanno la precedenza sulla direttivaCASE_HANDLING. Ad esempio, se utilizzi entrambe le direttive:SCHEMA MySchema CASE_HANDLING PRESERVE_ORIGINAL # Destination objects are renamed exactly # to 'SoMe_tAbLe' and 'RenamedView', respecting the case # despite the CASE_HANDLING directive RENAME_TABLES some_table:SoMe_tAbLe RENAME_VIEWS MyView:RenamedView
-
Per
SOURCE_NAME, fai sempre riferimento al nome originale dell'oggetto, anche se utilizzi altre direttive comeMOVE_*. Ad esempio, se vuoi rinominare uno degli oggetti della visualizzazione e spostarlo in un nuovo schema, fai riferimento al nome originale della visualizzazione per entrambe le direttive:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- L'istruzione
RENAME_TABLESesegue l'override dell'istruzioneREPLACE_TABLESin un singolo file. Se vuoi rinominare e spostare una tabella, ti consigliamo di utilizzare l'istruzioneMOVE_*. -
Il formato completo della variabile
SOURCE_NAMEdipende dal fatto che utilizzi anche la direttivaSCHEMA:- Con la direttiva
SCHEMA:utilizza nomi non qualificati, ad esempioMyTable. - Senza la direttiva
SCHEMA:utilizza nomi completi, ad esempioMySchema.MyTable.
- Con la direttiva
Direttive RENAME_* supportate
RENAME_SCHEMA: rinomina uno schema.
Un singolo file di configurazione può contenere una sola direttivaRENAME_SCHEMA. Se viene fornita la direttivaSCHEMA,RENAME_SCHEMApuò rinominare solo quello schema specifico.RENAME_TABLES: rinomina le tabelle. Esegue l'override diREPLACE_TABLESnello stesso file.RENAME_COLUMNS: rinomina le colonne all'interno delle tabelle. Esegue l'override dell'istruzioneREPLACE_COLSnello stesso file. Utilizza il formato seguente:RENAME_COLUMNS TABLE1.SRC_COL:DEST_COL TABLE2.SRC_COL:DEST_COL
Se utilizzi la direttiva
SCHEMA, utilizza nomi di tabelle non qualificati. Se non utilizzi la direttivaSCHEMA, includi i nomi completi delle tabelle, ad esempio SCHEMA.TABLE1.RENAME_VIEWSRENAME_MATERIALIZED_VIEWSRENAME_SEQUENCESRENAME_FUNCTIONSRENAME_STORED_PROCEDURESRENAME_TRIGGERS-
RENAME_PACKAGES: Database Migration Service converte i pacchetti Oracle in schemi PostgreSQL. Se lo schema contiene pacchetti che condividono i nomi, il codice PostgreSQL potrebbe riscontrare conflitti di nomi quando tenta di creare due schemi con lo stesso nome. Puoi utilizzare questa direttiva per evitare questi conflitti.Ad esempio, se hai pacchetti come
SALES.REPORTING_PKGeHR.REPORTING_PKG, puoi rinominarli con nomi distinti:RENAME_PACKAGES SALES.UTILS:SALES_UTILS RENAME_PACKAGES HR.UTILS:HR_UTILS
RENAME_USER_DEFINED_TYPESAlias disponibile:
RENAME_UDTS.
Spostamento di oggetti (MOVE_*)
Puoi spostare gli oggetti in schemi diversi nel database di destinazione. Ciò è utile per riorganizzare la struttura del database durante la migrazione. Database Migration Service aggiorna automaticamente tutti i riferimenti al codice in viste, stored procedure, funzioni e così via.
Sintassi generale
MOVE_OBJECT_TYPE SOURCE_NAME1:DESTINATION_SCHEMA1 SOURCE_NAME2:DESTINATION_SCHEMA2 ...
Considerazioni importanti
-
Per
SOURCE_NAME, fai sempre riferimento al nome originale dell'oggetto, anche se utilizzi altre direttive comeRENAME_*. Ad esempio, se vuoi rinominare uno degli oggetti della visualizzazione e spostarlo in un nuovo schema, fai riferimento al nome originale della visualizzazione per entrambe le direttive:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- La direttiva prevede solo il nome
DESTINATION_SCHEMA, non il nome completo dell'oggetto. -
Il formato completo della variabile
SOURCE_NAMEdipende dal fatto che utilizzi anche la direttivaSCHEMA:- Con la direttiva
SCHEMA:utilizza nomi non qualificati, ad esempioMyTable. - Senza la direttiva
SCHEMA:utilizza nomi completi, ad esempioMySchema.MyTable.
- Con la direttiva
Direttive MOVE_* supportate
MOVE_TABLES: sposta le tabelle in uno schema diverso. Ha la precedenza suREPLACE_TABLESper le modifiche dello schema in un singolo file di configurazione.MOVE_VIEWSMOVE_MATERIALIZED_VIEWSMOVE_SEQUENCESMOVE_FUNCTIONSMOVE_STORED_PROCEDURESMOVE_USER_DEFINED_TYPESAlias disponibile:
MOVE_UDTS.
Esempio: riorganizzazione degli schemi
SCHEMA LegacyApp # Moves the 'LegacyApp.Users' and 'LegacyApp.Orders' tables # to the 'data' schema. MOVE_TABLES Users:data Orders:data # Moves the 'LegacyApp.CreateUser' and 'LegacyApp.ProcessOrder' # stored procedures to the 'api' schema MOVE_STORED_PROCEDURES CreateUser:api ProcessOrder:api # Moves the 'LegacyApp.SalesSummary' views to the 'reporting' schema MOVE_VIEWS SalesSummary:reporting
DATA_TYPE
Puoi utilizzare questa direttiva per mappare esplicitamente qualsiasi
tipo di dati supportato tra
la sintassi Oracle e PostgreSQL. Questa direttiva
prevede un elenco di mappature separate da virgole. L'intera definizione deve essere
fornita su una singola riga, ma nel file di configurazione includi più direttive DATA_TYPE. Utilizza il formato seguente:
DATA_TYPE ORACLE_DATA_TYPE1:PGSQL_DATA_TYPE1 DATA_TYPE ORACLE_DATA_TYPE2:PGSQL_DATA_TYPE2...
Dove ORACLE_DATA_TYPE e PGSQL_DATA_TYPE sono tipi di dati supportati dalle rispettive versioni di Oracle e PostgreSQL che utilizzi nella migrazione. Per informazioni sulle versioni supportate, vedi Panoramica dello scenario.
Esempio:
DATA_TYPE REAL:double precision,SMALLINT:integer
Per saperne di più sui tipi di dati Oracle e PostgreSQL, consulta:
- Tipi di dati Oracle nella documentazione di Oracle.
- Tipi di dati PostgreSQL nella documentazione di PostgreSQL.
MODIFY_TYPE
La direttiva MODIFY_TYPE consente di controllare il tipo di dati in cui Database Migration Service converte una colonna specifica della tabella di origine.
Questa direttiva prevede un elenco di mappature separate da virgole.
L'intera definizione deve essere fornita su una singola riga, ma nel file di configurazione includi
più direttive MODIFY_TYPE.
Utilizza il formato seguente:
MODIFY_TYPE SOURCE_TABLE_NAME1:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE MODIFY_TYPE SOURCE_TABLE_NAME2:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE...
Dove:
- SOURCE_TABLE_NAME è il nome della tabella che contiene la colonna in cui vuoi modificare il tipo di dati.
- COLUMN_NAME è il nome della colonna per cui vuoi personalizzare la mappatura delle conversioni.
- EXPECTED_END_RESULT_DATA_TYPE è il tipo di dati PostgreSQL che vuoi che utilizzi la colonna convertita.
Esempio:
MODIFY_TYPE events:dates_and_times:DATETIME,users:pseudonym:TEXT
PG_INTEGER_TYPE
Per impostazione predefinita,Database Migration Service converte i tipi NUMBER(p,s)
nel tipo DECIMAL(p,s) di PostgreSQL.
Puoi modificare questo comportamento con la direttiva PG_INTEGER_TYPE. Imposta il valore su 1 e forza la conversione di tutti i tipi NUMBER con precisione e scala (NUMBER(p,s)) nei tipi PostgreSQL smallint, integer o bigint in base al numero di cifre di precisione.
Includi la seguente impostazione nel file di mappatura delle conversioni:
PG_INTEGER_TYPE 1
PG_NUMERIC_TYPE
Imposta questa direttiva su 1 se vuoi convertire tutti i tuoi tipi NUMBER con precisione e scala (NUMBER(p,s)) in tipi PostgreSQL real o float (in base al numero di cifre di precisione).
Se imposti questa direttiva su 0, i valori NUMBER(p,s)
mantengono il loro valore originale esatto e utilizzano il tipo di dati
PostgreSQL interno.
Includi la seguente impostazione nel file di mappatura delle conversioni:
PG_NUMERIC_TYPE 1
DEFAULT_NUMERIC
La conversione predefinita per NUMBER senza precisione
cambia a seconda che tu utilizzi anche la
direttiva PG_INTEGER_TYPE:
- Se utilizzi la direttiva
PG_INTEGER, i valoriNUMBERsenza precisione vengono convertiti in valoriDECIMAL. - Se non utilizzi la direttiva
PG_INTEGER, iNUMBERsenza precisione vengono convertiti in valoriBIGINT.
Puoi modificare questo comportamento e utilizzare la direttiva DEFAULT_NUMERIC
per specificare il tipo di dati da utilizzare per i tipi
NUMBER senza punti di precisione specificati.
Utilizza il formato seguente:
DEFAULT_NUMERIC POSTGRESQL_NUMERIC_DATA_TYPE
Dove POSTGRESQL_NUMERIC_DATA_TYPE è uno dei seguenti valori: integer, smallint, bigint.
Esempio:
DEFAULT_NUMERIC integer
REPLACE_COLS
Puoi utilizzare la direttiva REPLACE_COLS per rinominare le colonne
nello schema convertito. Questa direttiva prevede un elenco di mappature separate da virgole.
Utilizza il formato seguente:
REPLACE_COLS SOURCE_TABLE_NAME1(SOURCE1_TABLE1_COLUMN_NAME1:DESTINATION_TABLE1_COLUMN_NAME1,SOURCE_TABLE1_COLUMN_NAME2:DESTINATION_TABLE1_COLUMN_NAME2),SOURCE_TABLE_NAME2(SOURCE_TABLE2_COLUMN_NAME1:DESTINATION_TABLE2_COLUMN_NAME1,SOURCE_TABLE2_COLUMN_NAME2:DESTINATION_TABLE2_COLUMN_NAME2)...
Dove:
- SOURCE_TABLE_NAME è il nome della tabella
che contiene la colonna di cui vuoi modificare il nome. Se non utilizzi la direttiva
SCHEMA, assicurati di utilizzare il nome della tabella completo:
SCHEMA_NAME.SOURCE_TABLE_NAME - SOURCE_COLUMN_NAME è il nome della colonna nell'origine di cui vuoi modificare il nome.
- DESTINATION_COLUMN_NAME è il nuovo nome della colonna che vuoi utilizzare nello schema convertito.
Esempio:
REPLACE_COLS events(dates_and_times:event_dates),users(pseudonym:nickname)
REPLACE_TABLES
Puoi utilizzare la direttiva REPLACE_TABLES per rinominare le tabelle
o spostarle in un nuovo schema. Questa direttiva prevede un elenco di
mappature separate da spazi. Per ulteriori informazioni sulla sintassi per
ogni caso d'uso, espandi le sezioni seguenti.
Se non utilizzi la direttiva SCHEMA, assicurati di utilizzare i nomi delle tabelle completi tra virgolette per le variabili di origine e di destinazione:
"SCHEMA_NAME.SOURCE_TABLE_NAME""SCHEMA_NAME.DESTINATION_TABLE_NAME"
Ridenominare le tabelle
Per rinominare le tabelle nello schema convertito, utilizza il seguente formato:
REPLACE_TABLES SOURCE_TABLE_NAME1:DESTINATION_TABLE_NAME1 SOURCE_TABLE_NAME2:DESTINATION_TABLE_NAME2
Dove:
- SOURCE_TABLE_NAME è il nome della tabella di origine che vuoi rinominare nello schema convertito.
- DESTINATION_TABLE_NAME è il nuovo nome della tabella che vuoi utilizzare nello schema convertito.
Esempio:
REPLACE_TABLES "events:login_events" "users:platform_users"
Spostare le tabelle tra gli schemi
Puoi utilizzare questa direttiva per spostare le tabelle tra gli schemi aggiungendo il prefisso dello schema al nuovo nome della tabella. Questo meccanismo può essere utilizzato indipendentemente da come utilizzi la direttiva SCHEMA per l'intero file di conversione. Ad esempio:
REPLACE_TABLES "events:NEW_SCHEMA_NAME.login_events"
Alias per la personalizzazione dei tipi di dati
Quando utilizzi le direttive di conversione per modificare il modo in cui Database Migration Service converte
diversi tipi di dati (ad esempio, con le direttive
DATA_TYPE,
MODIFY_TYPE o
PG_NUMERIC_TYPE), puoi utilizzare
gli alias anziché i tipi di dati SQL di origine.
Espandi la sezione seguente per visualizzare l'elenco degli alias dei tipi di dati supportati da Database Migration Service.
Alias dei tipi di dati
| Alias | Convertito nel tipo PostgreSQL |
|---|---|
bigint, int8 |
BIGINT |
bool, boolean |
BOOLEAN |
bytea |
BYTEA |
char, character |
CHAR |
character varying, varchar |
VARCHAR |
date |
DATE |
decimal, numeric |
DECIMAL |
double precision, float8 |
DOUBLE PRECISION |
real, float4 |
REAL |
int, integer, int4 |
INTEGER |
int2 |
SMALLINT |
interval |
INTERVAL |
json |
JSON |
smallint |
SMALLINT |
text |
TEXT |
time |
TIME |
timestamp |
TIMESTAMP |
timestamptz |
TIMESTAMPTZ |
timetz |
TIMETZ |
uuid |
UUID |
XML |
XML |
File di mappatura delle conversioni di esempio
Consulta il seguente file di mapping delle conversioni di esempio che utilizza alcune delle direttive di conversione dello schema supportate:
EXPORT_SCHEMA 1 SCHEMA root # Preserve original casing for all objects CASE_HANDLING PRESERVE_ORIGINAL # Data type conversions PG_NUMERIC_TYPE 0 PG_INTEGER_TYPE 1 DEFAULT_NUMERIC integer DATA_TYPE NUMBER(4\,0):integer MODIFY_TYPE events:dates_and_times:TIMESTAMP # Renaming objects using the RENAME_* directives # These allow case-sensitive destination names RENAME_TABLES events:LoginEvents users:PlatformUsers RENAME_COLUMNS events.dates_and_times:EventDates users.pseudonym:Nickname RENAME_VIEWS InternalReport:FinInternalReport # Moving objects to new schemas using the MOVE_* directives MOVE_TABLES audit_log:archive MOVE_VIEWS InternalReport:reporting
I risultati dell'utilizzo di questo file sono i seguenti:
EXPORT_SCHEMA 1è un'istruzione obbligatoria.SCHEMA rootfa sì che le altre direttive vengano applicate agli oggetti all'interno dello schemaroot, a meno che non vengano utilizzati nomi completi.CASE_HANDLING PRESERVE_ORIGINALgarantisce che tutti i nomi degli oggetti dello schemarootmantengano la capitalizzazione originale nella destinazione (a meno che non venga sostituita da un'istruzioneRENAME_*).PG_INTEGER_TYPE 1fa in modo che Database Migration Service converta tutti i tipi di dati numerici Oracle trovati nelle tabelle dello schemarootin tipi specifici di PostgreSQL anziché in tipi numerici portabili ANSI.DEFAULT_NUMERIC integerfa sì che Database Migration Service converta i valoriNUMBERche non hanno un punto di precisione specificato nel tipoINTEGERdi PostgreSQL.DATA_TYPE NUMBER(4\,0):integerfa sì che Database Migration Service converta valoriNUMBER(4,0)specifici inINTEGERPostgreSQL.- La direttiva
MODIFY_TYPE events:dates_and_times:TIMESTAMPfa sì che Database Migration Service converta i dati nella colonnadates_and_timesdella tabella di origineeventsspecificamente nel tipoTIMESTAMPdi PostgreSQL. RENAME_TABLES events:LoginEvents users:PlatformUsersrinomina le tabelle, mantenendo la distinzione tra maiuscole e minuscole specificata:- La tabella
eventsè stata rinominata inLoginEvents. - La tabella
usersè stata rinominata inPlatformUsers.
- La tabella
RENAME_COLUMNS events.dates_and_times:EventDates user.pseudonym:Nicknamerinomina le colonne, mantenendo il formato specificato nella destinazione:- Nella tabella
LoginEvents(nome originaleevents), la colonnadates_and_timesviene rinominata inEventDates. - Nella colonna
PlatformUsers(nome originaleusers), la colonnapseudonymviene rinominata inNickname.
- Nella tabella
RENAME_VIEWS InternalReport:FinInternalReportrinomina la visualizzazioneInternalReportinFinInternalReport.MOVE_TABLES audit_log:archivesposta la tabellaaudit_logdallo schemarootallo schemaarchive.MOVE_VIEWS InternalReport:reportingsposta la visualizzazioneInternalReportnello schemareporting. Questa visualizzazione viene rinominata anche inFinInternalReporta causa dell'istruzioneRENAME_VIEWS. Database Migration Service gestisce la dipendenza: l'oggetto viene prima rinominato, poi spostato.
Workspace di conversione legacy
I workspace di conversione legacy sono un tipo di workspace di conversione precedente e più limitato. I workspace di conversione legacy non supportano le funzionalità di conversione avanzate con Gemini o l'editor SQL interattivo. Puoi utilizzarli solo per convertire lo schema di origine con lo strumento di migrazione Ora2Pg.
Non è consigliabile utilizzare il tipo legacy di spazi di lavoro per le conversioni per le migrazioni. Se il tuo scenario richiede l'utilizzo di workspace della conversione legacy, consulta Utilizzare i workspace della conversione legacy.
Passaggi successivi
Per scoprire di più sull'utilizzo dei workspace di conversione, consulta: