
Mit Konvertierungsarbeitsbereichen können Sie das Schema und die Objekte aus der Quelldatenbank leichter in die mit der Zieldatenbank kompatible SQL-Syntax konvertieren. Auf dieser Seite finden Sie eine Übersicht über die Konvertierungsarbeitsbereiche von Database Migration Service:
Conversion-Übersichten bieten einen Querschnitt des Fortschritts der Schema-Conversion.
Unter Von der deterministischen Code- und Schemakonvertierung unterstützte Objekte werden Oracle-Objekte aufgeführt, die für die deterministische Schemakonvertierung unterstützt werden.
Unter Interaktiver SQL-Editor wird beschrieben, welche Objekte Sie direkt im Editor des Konvertierungsarbeitsbereichs ändern können.
Gemini-basierte Konvertierungsfunktionen beschreibt, wie Sie Unterstützung durch generative KI integrieren können, um die Schema-Konvertierung zu beschleunigen.
Im Abschnitt Dateien für die Conversion-Zuordnung finden Sie eine Übersicht über die Anpassungsanweisungen, mit denen Sie die Regeln der deterministischen Schema-Conversion überschreiben können.
Unter Legacy-Konvertierungsarbeitsbereiche werden die Legacy-Arbeitsbereiche beschrieben, die den interaktiven SQL-Editor nicht unterstützen.
Bestimmte Datentypen werden für Oracle-Migrationen nicht unterstützt. Weitere Informationen finden Sie unter Bekannte Einschränkungen für Datentypen.
Übersichten zum Konvertierungsfortschritt
Konvertierungsarbeitsbereiche bieten robuste Übersichtsinformationen, mit denen Sie Einblicke in die Gesamtzahl der ausstehenden oder behobenen Konvertierungsprobleme, von Gemini unterstützte Erweiterungen und den allgemeinen Zustand Ihres Konvertierungsprozesses erhalten.
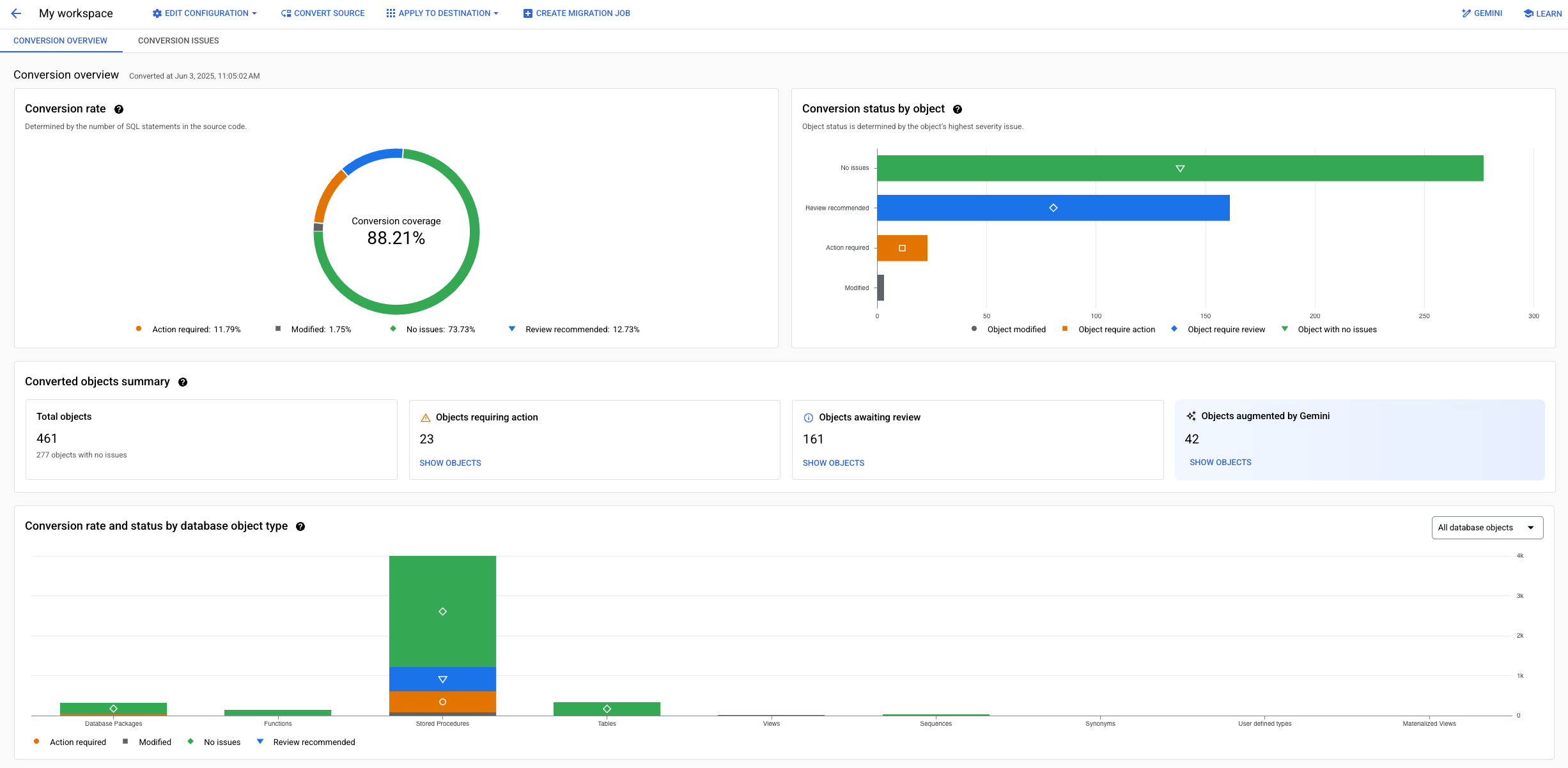
In dieser Ansicht können Sie Objekte in Ihrem Schema nach Typ, Schweregrad des Problems, erforderlichen Maßnahmen oder Umwandlungsstatus filtern.

Weitere Informationen zur Verwendung von Conversion-Übersichten zum Untersuchen von Conversion-Ergebnissen finden Sie unter Mit Konvertierungsarbeitsbereichen arbeiten.
Deterministischer Code und Schemakonvertierung
Wenn Sie einen Konvertierungsarbeitsbereich erstellen, führt Database Migration Service sofort die erste Schemakonvertierung mit einer Reihe deterministischer Konvertierungsregeln durch, bei denen bestimmte Oracle-Datentypen und -Objekte bestimmten PostgreSQL-Datentypen und -Objekten zugeordnet werden. Dieser Prozess unterstützt eine sehr spezifische Teilmenge der verfügbaren Oracle-Datenbankobjekte.
Die deterministische Codekonvertierung unterstützt die folgenden Oracle-Datenbankobjekte:
Unterstützte Oracle-Schemaelemente
- Einschränkungen
- Indexe (nur Indexe, die im selben Schema wie ihre Tabelle erstellt werden)
- Materialisierte Ansichten
- Objekttypen (teilweise Unterstützung)
- Sequenzen
- Synonyme
- Tabellen
- Aufrufe
Unterstützte Oracle-Codeelemente
- Trigger (nur auf Tabellenebene)
- Pakete
- Funktionen
- Gespeicherte Prozeduren
Interaktiver SQL-Editor
Mit dem interaktiven SQL-Editor können Sie die konvertierte PostgreSQL-Syntax direkt in Database Migration Service ändern. Sie können damit Conversion-Probleme beheben oder das Schema an Ihre Anforderungen anpassen. Einige Objekte können im integrierten Editor nicht geändert werden.
Bearbeitbare Oracle-Objekte
Nachdem Sie den Code und das Schema der Quelldatenbank konvertiert haben, können Sie den interaktiven Editor verwenden, um den generierten SQL-Code für bestimmte Objekttypen zu ändern. Die folgenden Oracle-Objekte werden vom Editor unterstützt:
- Tabellentrigger (Berechtigung erforderlich)
- Materialisierte Ansichten
- Pakete
- Funktionen, gespeicherte Prozeduren
- Synonyme
- Aufrufe
- Einschränkungen
- Indexe
- Sequenzen
Außerdem werden einige Objekte konvertiert, können aber nicht direkt im Database Migration Service bearbeitet werden. Wenn Sie solche Objekte ändern möchten, müssen Sie die Aktualisierungen direkt in der Zieldatenbank vornehmen, nachdem Sie das konvertierte Schema und den konvertierten Code angewendet haben.
Objekte, die nicht bearbeitet werden können:
- Benutzerdefinierte Objekttypen
- Tabellen
- Schemas
Code- und Schemakonvertierung mit Gemini beschleunigen
Gemini für Google Cloud ist in die Konvertierungsarbeitsbereiche von Database Migration Service integriert, um den Konvertierungsprozess in den folgenden Bereichen zu beschleunigen und zu verbessern:
Verbessern Sie die deterministischen Konvertierungsergebnisse mit der automatischen Konvertierung auf Basis von Gemini, um die Leistungsfähigkeit von KI zu nutzen und die Anzahl der manuellen Anpassungen in Ihrem PostgreSQL-Code deutlich zu reduzieren.
Mit Gemini-basierten Qualitätsbewertungen können Sie die Qualität und funktionale Äquivalenz Ihres konvertierten Codes sicherstellen. Bei diesen Bewertungen wird der konvertierte Code analysiert und Feedback zu seiner Richtigkeit und Funktionalität im Vergleich zum Quellcode gegeben.
Funktionen zur Code-Erklärbarkeit mit dem Konvertierungsassistenten bereitstellen: eine Reihe von speziellen Prompts, mit denen Sie die Konvertierungslogik besser nachvollziehen, Korrekturen für Konvertierungsprobleme vorschlagen oder konvertierten Code optimieren können.
Mit Gemini-Codekonvertierungsvorschlägen können Sie Korrekturen für Konvertierungsprobleme beschleunigen. Dabei lernt das Gemini-Modell, während Sie Konvertierungsprobleme beheben, und schlägt Änderungen für andere fehlerhafte Objekte im Arbeitsbereich vor.
Weitere Informationen zur mit Gemini optimierten Konvertierung finden Sie auf den folgenden Seiten:
Oracle-Code und ‑Schema mit Unterstützung von Gemini konvertieren
Beispielworkflow zum Beheben von Codeobjekten mit Konvertierungsproblemen
Dateien für die Conversion-Zuordnung
Sie können die Conversion-Logik mit einer Conversion-Zuordnungsdatei anpassen. Die Konvertierungszuordnungsdatei ist eine Textdatei, die genaue Anweisungen (Konvertierungsanweisungen) dafür enthält, wie Ihre Oracle-Objekte in PostgreSQL-Objekte konvertiert werden sollen.
Unterstützte Conversion-Direktiven
Database Migration Service unterstützt die folgenden Konvertierungsanweisungen für Konvertierungszuordnungsdateien:
EXPORT_SCHEMA
EXPORT_SCHEMA ist eine obligatorische Direktive für alle Dateien zur Conversion-Zuordnung. Database Migration Service benötigt diese Anweisung, um sicherzustellen, dass Ihre Quellschemas in die richtigen Zielschemas konvertiert werden.
Ihre Dateien für das Conversion-Mapping müssen diese Zeile enthalten:
EXPORT_SCHEMA 1
SCHEMA
Database Migration Service muss ermitteln können, welches Schema die Objekte enthält, die mit Ihren Konvertierungsanweisungen geändert werden sollen.
Mit der Anweisung SCHEMA werden alle anderen Anpassungsanweisungen in Ihrer Datei auf Objekte in diesem Schema angewendet.
- Wenn Sie diese Direktive verwenden, werden auch andere Schemas in Ihrer Datenbank konvertiert, ihre Objekte werden jedoch nicht geändert.
- Wenn Sie diese Direktive in die Datei für die Conversion-Zuordnung aufnehmen, werden alle Anpassungen nur auf Objekte angewendet, die in diesem bestimmten Schema enthalten sind.
- Wenn Sie diese Direktive überspringen, müssen Sie vollständig qualifizierte Objektnamen angeben, die den Schemanamen für Objekte enthalten, die durch andere Konvertierungsdirektiven geändert werden.
Wenn Sie beispielsweise
SOURCE_TABLE_NAMEfür dieREPLACE_TABLES-Anweisung verwenden möchten, müssen Sie"SCHEMA_NAME.SOURCE_TABLE_NAME"verwenden. - So passen Sie Objekte in verschiedenen Schemas an:
- Erstellen Sie separate Dateien für die Conversion-Zuordnung für andere Schemas und laden Sie sie in den Konvertierungsarbeitsbereich hoch.
- Verwenden Sie vollständig qualifizierte Objektnamen, die den Schemanamen für Objekte enthalten, die sich in anderen Schemas als dem befinden, das Sie für die
SCHEMA-Anweisung angeben.
Verwenden Sie das folgende Format:
SCHEMA SCHEMA_NAME
Dabei ist SCHEMA_NAME der Name des Schemas in der Quelldatenbank.
CASE_HANDLING
Standardmäßig konvertiert Database Migration Service alle Objektnamen in Kleinbuchstaben.
Sie können dieses Verhalten mit der CASE_HANDLING-Anweisung ändern.
- Diese Anweisung wird von der Anweisung
SCHEMAnicht beeinflusst. Sie gilt weltweit und betrifft alle Objekte im Konvertierungsarbeitsbereich. - Die Anweisungen
RENAME_*,MOVE_*undREPLACE_*haben Vorrang vor der AnweisungCASE_HANDLINGund benennen Ihre Objekte unabhängig von der EigenschaftCASE_HANDLINGgenau um. - Wenn diese Direktive in mehreren Konfigurationsdateien mit widersprüchlichen Werten vorhanden ist, gibt Database Migration Service beim Schemaimport einen Fehler aus.
Verwenden Sie das folgende Format:
CASE_HANDLING OPTION
Dabei kann OPTION für folgendes stehen:
UPPERCASE: Konvertiert alle Objektnamen in Großbuchstaben.LOWERCASE: Konvertiert alle Objektnamen in Kleinbuchstaben (Standardverhalten).PRESERVE_ORIGINAL: Behält die ursprüngliche Groß-/Kleinschreibung aus dem Quellschema bei. Das ist nützlich, wenn in Ihren Anwendungen Kennungen verwendet werden, bei denen die Groß-/Kleinschreibung beachtet wird.
Beispiel:
CASE_HANDLING PRESERVE_ORIGINAL
GENERATE_MISSING_PK
Bei Tabellen ohne Primärschlüssel ist keine konsistente Replikation gewährleistet. Database Migration Service migriert nur Tabellen mit Primärschlüsseln. Standardmäßig werden in den Konvertierungsarbeitsbereichen von Database Migration Service automatisch alle fehlenden Primärschlüssel in den Zieltabelle erstellt, wenn Sie Quellcode und ‑schema konvertieren.
Sie können die automatische Generierung von Primärschlüsseln mit der Anweisung GENERATE_MISSING_PK steuern. Wenn Sie die automatische Schlüsselgenerierung deaktivieren möchten, legen Sie diese Direktive auf 0 fest.
Beispiel:
GENERATE_MISSING_PK 0
Diese Richtlinie wirkt sich auf alle Objekte in einem bestimmten Konvertierungsarbeitsbereich aus. Es ist nicht möglich, die automatische Generierung von Primärschlüsseln nur für eine bestimmte Tabelle zu deaktivieren.
Database Migration Service kann nur Tabellen migrieren, die in ihren konvertierten PostgreSQL-Versionen Primärschlüsseleinschränkungen haben. Wenn Sie die automatische Generierung von Primärschlüsseln deaktivieren, müssen Sie nach dem Anwenden des konvertierten Schemas in der Zieldatenbank manuell Primärschlüssel oder eindeutige Einschränkungen in den konvertierten Tabellen erstellen. Maximieren Sie die folgenden Abschnitte, um Beispiel-SQL-Befehle zu sehen.
Primärschlüssel aus vorhandenen Spalten erstellen
Ihre Tabelle hat möglicherweise bereits einen logischen Primärschlüssel, der auf einer Spalte oder einer Kombination von Spalten basiert. Beispielsweise kann es Spalten mit einer eindeutigen Einschränkung oder einem eindeutigen Index geben. Verwenden Sie diese Spalten, um einen neuen Primärschlüssel für Tabellen in Ihrer Quelldatenbank zu generieren. Beispiel:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME);
Primärschlüssel mit allen Spalten erstellen
Wenn Sie keine vorhandene Einschränkung haben, die als Primärschlüssel dienen könnte, erstellen Sie Primärschlüssel mit allen Spalten der Tabelle. Achten Sie darauf, dass die maximale Länge des Primärschlüssels, die von Ihrem PostgreSQL-Cluster zulässig ist, nicht überschritten wird. Beispiel:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME_1, COLUMN_NAME_2, COLUMN_NAME_3, ...);
Wenn Sie einen zusammengesetzten Primärschlüssel wie diesen erstellen, müssen Sie alle Spaltennamen, die Sie verwenden möchten, explizit auflisten. Es ist nicht möglich, mit einer Anweisung alle Spaltennamen für diesen Zweck abzurufen.
Eindeutige Beschränkung mit der Pseudospalte ROWID erstellen
In Oracle-Datenbanken wird die
Pseudospalte ROWID verwendet, um den Speicherort jeder Zeile in einer Tabelle zu speichern. Wenn Sie Oracle-Tabellen ohne Primärschlüssel migrieren möchten, können Sie in der PostgreSQL-Zieldatenbank eine ROWID-Spalte hinzufügen. Database Migration Service füllt die Spalte mit den entsprechenden numerischen Werten aus der Oracle-Pseudospalte ROWID der Quelle.
Führen Sie den folgenden Befehl aus, um die Spalte hinzuzufügen und als Primärschlüssel festzulegen:
ALTER TABLE TABLE_NAME ADD COLUMN rowid numeric(33,0) NOT NULL; CREATE SEQUENCE TABLE_NAME_rowid_seq INCREMENT BY -1 START WITH -1 OWNED BY TABLE_NAME.rowid; ALTER TABLE TABLE_NAME ALTER COLUMN rowid SET DEFAULT nextval('TABLE_NAME_rowid_seq'); ALTER TABLE TABLE_NAME ADD CONSTRAINT CONSTRAINT_DISPLAY_NAME PRIMARY KEY (rowid);
Objekte umbenennen (RENAME_*)
Sie können verschiedene Datenbankobjekte während der Konvertierung umbenennen. Database Migration Service aktualisiert automatisch alle Codeverweise (in Ansichten, gespeicherten Prozeduren, Funktionen usw.) für die Verwendung der neuen Namen.
Allgemeine Syntax
RENAME_OBJECT_TYPE SOURCE_NAME1:DESTINATION_NAME1 SOURCE_NAME2:DESTINATION_NAME2 ...
Wichtige Hinweise
-
Bei den
RENAME_*-Anweisungen wird zwischen Groß- und Kleinschreibung unterschieden. Sie haben Vorrang vor derCASE_HANDLING-Anweisung. Wenn Sie beispielsweise beide Anweisungen verwenden:SCHEMA MySchema CASE_HANDLING PRESERVE_ORIGINAL # Destination objects are renamed exactly # to 'SoMe_tAbLe' and 'RenamedView', respecting the case # despite the CASE_HANDLING directive RENAME_TABLES some_table:SoMe_tAbLe RENAME_VIEWS MyView:RenamedView
-
Verweisen Sie für die
SOURCE_NAMEimmer auf den ursprünglichen Objektnamen, auch wenn Sie andere Direktiven wieMOVE_*verwenden. Wenn Sie beispielsweise eines Ihrer Ansichtsobjekte umbenennen und in ein neues Schema verschieben möchten, verweisen Sie in beiden Direktiven auf den ursprünglichen Ansichtsnamen:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- Die
RENAME_TABLES-Anweisung überschreibt dieREPLACE_TABLES-Anweisung in einer einzelnen Datei. Wenn Sie eine Tabelle sowohl umbenennen als auch verschieben möchten, empfehlen wir stattdessen die Verwendung derMOVE_*-Anweisung. -
Das vollständige Format der Variablen
SOURCE_NAMEhängt davon ab, ob Sie auch die AnweisungSCHEMAverwenden:- Mit der
SCHEMA-Anweisung:Verwenden Sie nicht qualifizierte Namen, z. B.MyTable. - Ohne
SCHEMA-Anweisung:Verwenden Sie vollqualifizierte Namen, z. B.MySchema.MyTable.
- Mit der
Unterstützte RENAME_*-Direktiven
RENAME_SCHEMA: Benennt ein Schema um.
Eine einzelne Konfigurationsdatei kann nur eineRENAME_SCHEMA-Anweisung enthalten. Wenn dieSCHEMA-Anweisung angegeben ist, kannRENAME_SCHEMAnur dieses bestimmte Schema umbenennen.RENAME_TABLES: Benennt Tabellen um. Überschreibt dieREPLACE_TABLESin derselben Datei.RENAME_COLUMNS: Benennt Spalten in Tabellen um. Überschreibt dieREPLACE_COLS-Anweisung in derselben Datei. Verwenden Sie das folgende Format:RENAME_COLUMNS TABLE1.SRC_COL:DEST_COL TABLE2.SRC_COL:DEST_COL
Wenn Sie die
SCHEMA-Anweisung verwenden, müssen Sie nicht qualifizierte Tabellennamen verwenden. Wenn Sie dieSCHEMA-Anweisung nicht verwenden, geben Sie die voll qualifizierten Tabellennamen an, z. B. SCHEMA.TABLE1.RENAME_VIEWSRENAME_MATERIALIZED_VIEWSRENAME_SEQUENCESRENAME_FUNCTIONSRENAME_STORED_PROCEDURESRENAME_TRIGGERS-
RENAME_PACKAGES: Database Migration Service konvertiert Oracle-Pakete in PostgreSQL-Schemas. Wenn Ihr Schema Pakete mit gemeinsamen Namen enthält, kann es im PostgreSQL-Code zu Namenskonflikten kommen, wenn versucht wird, zwei Schemas mit demselben Namen zu erstellen. Mit dieser Direktive können Sie solche Konflikte vermeiden.Wenn Sie beispielsweise Pakete wie
SALES.REPORTING_PKGundHR.REPORTING_PKGhaben, können Sie sie in eindeutige Namen umbenennen:RENAME_PACKAGES SALES.UTILS:SALES_UTILS RENAME_PACKAGES HR.UTILS:HR_UTILS
RENAME_USER_DEFINED_TYPESVerfügbarer Alias:
RENAME_UDTS.
Objekte verschieben (MOVE_*)
Sie können Objekte in der Zieldatenbank in andere Schemas verschieben. Das ist nützlich, um die Datenbankstruktur während der Migration neu zu organisieren. Database Migration Service aktualisiert automatisch alle Codeverweise in Ansichten, gespeicherten Prozeduren, Funktionen usw.
Allgemeine Syntax
MOVE_OBJECT_TYPE SOURCE_NAME1:DESTINATION_SCHEMA1 SOURCE_NAME2:DESTINATION_SCHEMA2 ...
Wichtige Hinweise
-
Verweisen Sie für die
SOURCE_NAMEimmer auf den ursprünglichen Objektnamen, auch wenn Sie andere Direktiven wieRENAME_*verwenden. Wenn Sie beispielsweise eines Ihrer Ansichtsobjekte umbenennen und in ein neues Schema verschieben möchten, verweisen Sie in beiden Direktiven auf den ursprünglichen Ansichtsnamen:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- Die Richtlinie erwartet nur den Namen
DESTINATION_SCHEMA, nicht den vollständigen Objektnamen. -
Das vollständige Format der Variablen
SOURCE_NAMEhängt davon ab, ob Sie auch die AnweisungSCHEMAverwenden:- Mit der
SCHEMA-Anweisung:Verwenden Sie nicht qualifizierte Namen, z. B.MyTable. - Ohne
SCHEMA-Anweisung:Verwenden Sie vollqualifizierte Namen, z. B.MySchema.MyTable.
- Mit der
Unterstützte MOVE_*-Direktiven
MOVE_TABLES: Verschiebt Tabellen in ein anderes Schema. Hat Vorrang vorREPLACE_TABLESfür Schemaänderungen in einer einzelnen Konfigurationsdatei.MOVE_VIEWSMOVE_MATERIALIZED_VIEWSMOVE_SEQUENCESMOVE_FUNCTIONSMOVE_STORED_PROCEDURESMOVE_USER_DEFINED_TYPESVerfügbarer Alias:
MOVE_UDTS.
Beispiel: Schemas neu organisieren
SCHEMA LegacyApp # Moves the 'LegacyApp.Users' and 'LegacyApp.Orders' tables # to the 'data' schema. MOVE_TABLES Users:data Orders:data # Moves the 'LegacyApp.CreateUser' and 'LegacyApp.ProcessOrder' # stored procedures to the 'api' schema MOVE_STORED_PROCEDURES CreateUser:api ProcessOrder:api # Moves the 'LegacyApp.SalesSummary' views to the 'reporting' schema MOVE_VIEWS SalesSummary:reporting
DATA_TYPE
Mit dieser Direktive können Sie jeden unterstützten Datentyp explizit zwischen Oracle- und PostgreSQL-Syntax zuordnen. Diese Direktive erwartet eine durch Kommas getrennte Liste von Zuordnungen. Die gesamte Definition muss in einer einzigen Zeile angegeben werden. Sie können jedoch mehrere DATA_TYPE-Anweisungen in Ihre Konfigurationsdatei aufnehmen. Verwenden Sie das folgende Format:
DATA_TYPE ORACLE_DATA_TYPE1:PGSQL_DATA_TYPE1 DATA_TYPE ORACLE_DATA_TYPE2:PGSQL_DATA_TYPE2...
Dabei sind ORACLE_DATA_TYPE und PGSQL_DATA_TYPE Datentypen, die von den jeweiligen Oracle- und PostgreSQL-Versionen unterstützt werden, die Sie für die Migration verwenden. Informationen zu unterstützten Versionen finden Sie unter Szenarioübersicht.
Beispiel:
DATA_TYPE REAL:double precision,SMALLINT:integer
Weitere Informationen zu Oracle- und PostgreSQL-Datentypen finden Sie unter:
- Oracle-Datentypen in der Oracle-Dokumentation.
- PostgreSQL-Datentypen in der PostgreSQL-Dokumentation.
MODIFY_TYPE
Mit der MODIFY_TYPE-Anweisung können Sie festlegen, in welchen Datentyp Database Migration Service eine bestimmte Spalte in der Quelltabelle konvertiert.
Diese Direktive erwartet eine durch Kommas getrennte Liste von Zuordnungen.
Die gesamte Definition muss in einer einzigen Zeile angegeben werden, aber Sie können mehrere MODIFY_TYPE-Anweisungen in Ihre Konfigurationsdatei aufnehmen.
Verwenden Sie das folgende Format:
MODIFY_TYPE SOURCE_TABLE_NAME1:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE MODIFY_TYPE SOURCE_TABLE_NAME2:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE...
Wobei:
- SOURCE_TABLE_NAME ist der Name der Tabelle, die die Spalte enthält, deren Datentyp Sie ändern möchten.
- COLUMN_NAME ist der Name der Spalte, für die Sie die Conversion-Zuordnung anpassen möchten.
- EXPECTED_END_RESULT_DATA_TYPE ist der PostgreSQL-Datentyp, der für die konvertierte Spalte verwendet werden soll.
Beispiel:
MODIFY_TYPE events:dates_and_times:DATETIME,users:pseudonym:TEXT
PG_INTEGER_TYPE
Standardmäßig konvertiert Database Migration Service die NUMBER(p,s)-Typen in den PostgreSQL-Typ DECIMAL(p,s).
Sie können dieses Verhalten mit der Direktive PG_INTEGER_TYPE ändern. Legen Sie den Wert auf 1 fest und erzwingen Sie, dass alle Ihre NUMBER-Typen mit Genauigkeit und Skalierung (NUMBER(p,s)) basierend auf der Anzahl der Genauigkeitsziffern in die PostgreSQL-Typen smallint, integer oder bigint konvertiert werden.
Fügen Sie Ihrer Datei für die Conversion-Zuordnung die folgende Einstellung hinzu:
PG_INTEGER_TYPE 1
PG_NUMERIC_TYPE
Legen Sie diese Direktive auf 1 fest, wenn Sie alle Ihre NUMBER-Typen mit Genauigkeit und Skalierung (NUMBER(p,s)) in PostgreSQL-Typen real oder float konvertieren möchten (basierend auf der Anzahl der Genauigkeitsziffern).
Wenn Sie diese Direktive auf 0 festlegen, behalten Ihre NUMBER(p,s)-Werte ihren genauen Originalwert und verwenden den internen PostgreSQL-Datentyp.
Fügen Sie Ihrer Datei für die Conversion-Zuordnung die folgende Einstellung hinzu:
PG_NUMERIC_TYPE 1
DEFAULT_NUMERIC
Die Standardkonvertierung für NUMBERs ohne Genauigkeit ändert sich, je nachdem, ob Sie auch die
PG_INTEGER_TYPE-Anweisung verwenden:
- Wenn Sie die Direktive
PG_INTEGERverwenden, werdenNUMBERs ohne Genauigkeit inDECIMAL-Werte konvertiert. - Wenn Sie die
PG_INTEGER-Anweisung nicht verwenden, werdenNUMBER-Werte ohne Genauigkeit inBIGINT-Werte konvertiert.
Sie können dieses Verhalten ändern und mit der Anweisung DEFAULT_NUMERIC angeben, welcher Datentyp für NUMBER-Typen ohne angegebene Dezimalstellen verwendet werden soll.
Verwenden Sie das folgende Format:
DEFAULT_NUMERIC POSTGRESQL_NUMERIC_DATA_TYPE
Dabei steht POSTGRESQL_NUMERIC_DATA_TYPE für einen der folgenden Werte: integer, smallint, bigint.
Beispiel:
DEFAULT_NUMERIC integer
REPLACE_COLS
Mit der Anweisung REPLACE_COLS können Sie Spalten in Ihrem konvertierten Schema umbenennen. Diese Direktive erwartet eine durch Kommas getrennte Liste von Zuordnungen.
Verwenden Sie das folgende Format:
REPLACE_COLS SOURCE_TABLE_NAME1(SOURCE1_TABLE1_COLUMN_NAME1:DESTINATION_TABLE1_COLUMN_NAME1,SOURCE_TABLE1_COLUMN_NAME2:DESTINATION_TABLE1_COLUMN_NAME2),SOURCE_TABLE_NAME2(SOURCE_TABLE2_COLUMN_NAME1:DESTINATION_TABLE2_COLUMN_NAME1,SOURCE_TABLE2_COLUMN_NAME2:DESTINATION_TABLE2_COLUMN_NAME2)...
Wobei:
- SOURCE_TABLE_NAME ist der Name der Tabelle, die die Spalte enthält, deren Namen Sie ändern möchten. Wenn Sie die SCHEMA-Anweisung nicht verwenden, müssen Sie den voll qualifizierten Tabellennamen angeben:
SCHEMA_NAME.SOURCE_TABLE_NAME. - SOURCE_COLUMN_NAME ist der Name der Spalte in Ihrer Quelle, deren Namen Sie ändern möchten.
- DESTINATION_COLUMN_NAME ist der neue Name der Spalte, die Sie im konvertierten Schema verwenden möchten.
Beispiel:
REPLACE_COLS events(dates_and_times:event_dates),users(pseudonym:nickname)
REPLACE_TABLES
Mit der Direktive REPLACE_TABLES können Sie Tabellen umbenennen oder in ein neues Schema verschieben. Diese Direktive erwartet eine Liste von Zuordnungen, die durch Leerzeichen getrennt sind. Weitere Informationen zur Syntax für die einzelnen Anwendungsfälle finden Sie in den folgenden Abschnitten.
Wenn Sie die SCHEMA-Anweisung nicht verwenden, müssen Sie die vollqualifizierten Tabellennamen in Anführungszeichen für die Quell- und Zielvariablen angeben:
"SCHEMA_NAME.SOURCE_TABLE_NAME""SCHEMA_NAME.DESTINATION_TABLE_NAME"
Tabellen umbenennen
Verwenden Sie das folgende Format, um Tabellen in Ihrem konvertierten Schema umzubenennen:
REPLACE_TABLES SOURCE_TABLE_NAME1:DESTINATION_TABLE_NAME1 SOURCE_TABLE_NAME2:DESTINATION_TABLE_NAME2
Wobei:
- SOURCE_TABLE_NAME ist der Name der Quelltabelle, die Sie im konvertierten Schema umbenennen möchten.
- DESTINATION_TABLE_NAME ist der neue Name für die Tabelle, die Sie im konvertierten Schema verwenden möchten.
Beispiel:
REPLACE_TABLES "events:login_events" "users:platform_users"
Tabellen zwischen Schemas verschieben
Mit dieser Direktive können Sie Tabellen zwischen Schemas verschieben, indem Sie dem neuen Tabellennamen das Schemapräfix hinzufügen. Dieser Mechanismus kann unabhängig davon verwendet werden, wie Sie die SCHEMA-Anweisung für die gesamte Konvertierungsdatei verwenden. Beispiel:
REPLACE_TABLES "events:NEW_SCHEMA_NAME.login_events"
Aliase zum Anpassen von Datentypen
Wenn Sie Konvertierungsanweisungen verwenden, um zu ändern, wie Database Migration Service verschiedene Datentypen konvertiert (z. B. mit den Anweisungen
DATA_TYPE,
MODIFY_TYPE oder
PG_NUMERIC_TYPE), können Sie Aliase anstelle Ihrer SQL-Quelldatentypen verwenden.
Maximieren Sie den folgenden Abschnitt, um die Liste der von Database Migration Service unterstützten Datentyp-Aliase aufzurufen.
Datentyp-Aliasse
| Alias | In PostgreSQL-Typ konvertiert |
|---|---|
bigint, int8 |
BIGINT |
bool, boolean |
BOOLEAN |
bytea |
BYTEA |
char, character |
CHAR |
character varying, varchar |
VARCHAR |
date |
DATE |
decimal, numeric |
DECIMAL |
double precision, float8 |
DOUBLE PRECISION |
real, float4 |
REAL |
int, integer, int4 |
INTEGER |
int2 |
SMALLINT |
interval |
INTERVAL |
json |
JSON |
smallint |
SMALLINT |
text |
TEXT |
time |
TIME |
timestamp |
TIMESTAMP |
timestamptz |
TIMESTAMPTZ |
timetz |
TIMETZ |
uuid |
UUID |
XML |
XML |
Beispiel für eine Datei zur Conversion-Zuordnung
Unten sehen Sie eine Beispielzuordnungsdatei für die Konvertierung, in der einige der unterstützten Schema-Konvertierungsanweisungen verwendet werden:
EXPORT_SCHEMA 1 SCHEMA root # Preserve original casing for all objects CASE_HANDLING PRESERVE_ORIGINAL # Data type conversions PG_NUMERIC_TYPE 0 PG_INTEGER_TYPE 1 DEFAULT_NUMERIC integer DATA_TYPE NUMBER(4\,0):integer MODIFY_TYPE events:dates_and_times:TIMESTAMP # Renaming objects using the RENAME_* directives # These allow case-sensitive destination names RENAME_TABLES events:LoginEvents users:PlatformUsers RENAME_COLUMNS events.dates_and_times:EventDates users.pseudonym:Nickname RENAME_VIEWS InternalReport:FinInternalReport # Moving objects to new schemas using the MOVE_* directives MOVE_TABLES audit_log:archive MOVE_VIEWS InternalReport:reporting
Die Ergebnisse der Verwendung dieser Datei sind wie folgt:
EXPORT_SCHEMA 1ist eine erforderliche Anweisung.- Durch
SCHEMA rootwerden die anderen Anweisungen auf Objekte imroot-Schema angewendet, sofern keine voll qualifizierten Namen verwendet werden. CASE_HANDLING PRESERVE_ORIGINALsorgt dafür, dass alle Objektnamen aus dem Quellschemarootihre ursprüngliche Groß-/Kleinschreibung im Ziel beibehalten, sofern sie nicht durch eineRENAME_*-Anweisung überschrieben werden.- Mit
PG_INTEGER_TYPE 1werden alle numerischen Oracle-Datentypen, die in Tabellen imroot-Schema gefunden werden, von Database Migration Service in PostgreSQL-spezifische Typen anstelle von ANSI-kompatiblen numerischen Typen konvertiert. - Mit
DEFAULT_NUMERIC integerwerdenNUMBER-Werte ohne angegebene Genauigkeit von Database Migration Service in den PostgreSQL-TypINTEGERkonvertiert. DATA_TYPE NUMBER(4\,0):integerführt dazu, dass der Database Migration Service bestimmteNUMBER(4,0)-Werte in PostgreSQL-INTEGER-Werte konvertiert.- Die
MODIFY_TYPE events:dates_and_times:TIMESTAMP-Anweisung bewirkt, dass der Database Migration Service die Daten in der Spaltedates_and_timesder Quelltabelleeventsspeziell in den PostgreSQL-TypTIMESTAMPkonvertiert. RENAME_TABLES events:LoginEvents users:PlatformUsersbenennt Tabellen um und behält die angegebene Groß-/Kleinschreibung bei:- Die Tabelle
eventswird inLoginEventsumbenannt. - Die Tabelle
userswird inPlatformUsersumbenannt.
- Die Tabelle
RENAME_COLUMNS events.dates_and_times:EventDates user.pseudonym:Nicknamebenennt Spalten um und behält die angegebene Groß-/Kleinschreibung im Ziel bei:- In der Tabelle
LoginEvents(Originalnameevents) wird die Spaltedates_and_timesinEventDatesumbenannt. - In der Spalte
PlatformUsers(Originalnameusers) wirdpseudonyminNicknameumbenannt.
- In der Tabelle
- Mit
RENAME_VIEWS InternalReport:FinInternalReportwird die AnsichtInternalReportinFinInternalReportumbenannt. - Mit
MOVE_TABLES audit_log:archivewird die Tabelleaudit_logvom Schemarootin das Schemaarchiveverschoben. - Mit
MOVE_VIEWS InternalReport:reportingwird die AnsichtInternalReportzum Schemareportingverschoben. Diese Ansicht wird aufgrund der AnweisungRENAME_VIEWSauch inFinInternalReportumbenannt. Der Database Migration Service verarbeitet die Abhängigkeit: Das Objekt wird zuerst umbenannt und dann verschoben.
Alte Konvertierungsarbeitsbereiche
Legacy-Konvertierungsarbeitsbereiche sind eine ältere, eingeschränktere Art von Konvertierungsarbeitsbereichen. Legacy-Konvertierungsarbeitsbereiche unterstützen keine Gemini-basierten Konvertierungsfunktionen oder den interaktiven SQL-Editor. Sie können sie nur verwenden, um Ihr Quellschema mit dem Ora2Pg-Migrationstool zu konvertieren.
Wir empfehlen, für Ihre Migrationen nicht den alten Typ von Conversion-Arbeitsbereichen zu verwenden. Wenn Sie Legacy-Konvertierungsarbeitsbereiche benötigen, lesen Sie den Abschnitt Legacy-Konvertierungsarbeitsbereiche verwenden.
Nächste Schritte
Weitere Informationen zur Verwendung von Konvertierungsarbeitsbereichen: