
Os espaços de trabalho de conversão ajudam a converter o esquema e os objetos do banco de dados de origem na sintaxe SQL compatível com o banco de dados de destino. Nesta página, você encontra uma visão geral dos espaços de trabalho de conversão do Database Migration Service:
As visões gerais de conversão oferecem uma seção transversal do progresso da conversão do esquema.
Objetos compatíveis com a conversão determinística de código e esquema lista os objetos do Oracle compatíveis com a conversão determinística de esquema.
O editor interativo de SQL descreve quais objetos podem ser modificados diretamente no editor do espaço de trabalho de conversão.
Os recursos de conversão com tecnologia do Gemini mostram como integrar o suporte da IA generativa para acelerar o processo de conversão de esquema.
A seção Arquivos de mapeamento de conversão oferece uma visão geral das diretivas de personalização que podem ser usadas para substituir as regras de conversão determinística de esquema.
Espaços de trabalho de conversão legados descreve os espaços de trabalho legados que não oferecem suporte ao editor interativo de SQL.
Alguns tipos de dados não são compatíveis com migrações do Oracle. Para mais informações, consulte Limitações conhecidas para tipos de dados.
Visão geral do progresso da conversão
Informações gerais robustas dos espaços de trabalho de conversão, em que você pode receber insights sobre o número total de problemas de conversão pendentes ou resolvidos, aumentos assistidos pelo Gemini e a integridade geral do seu processo de conversão.
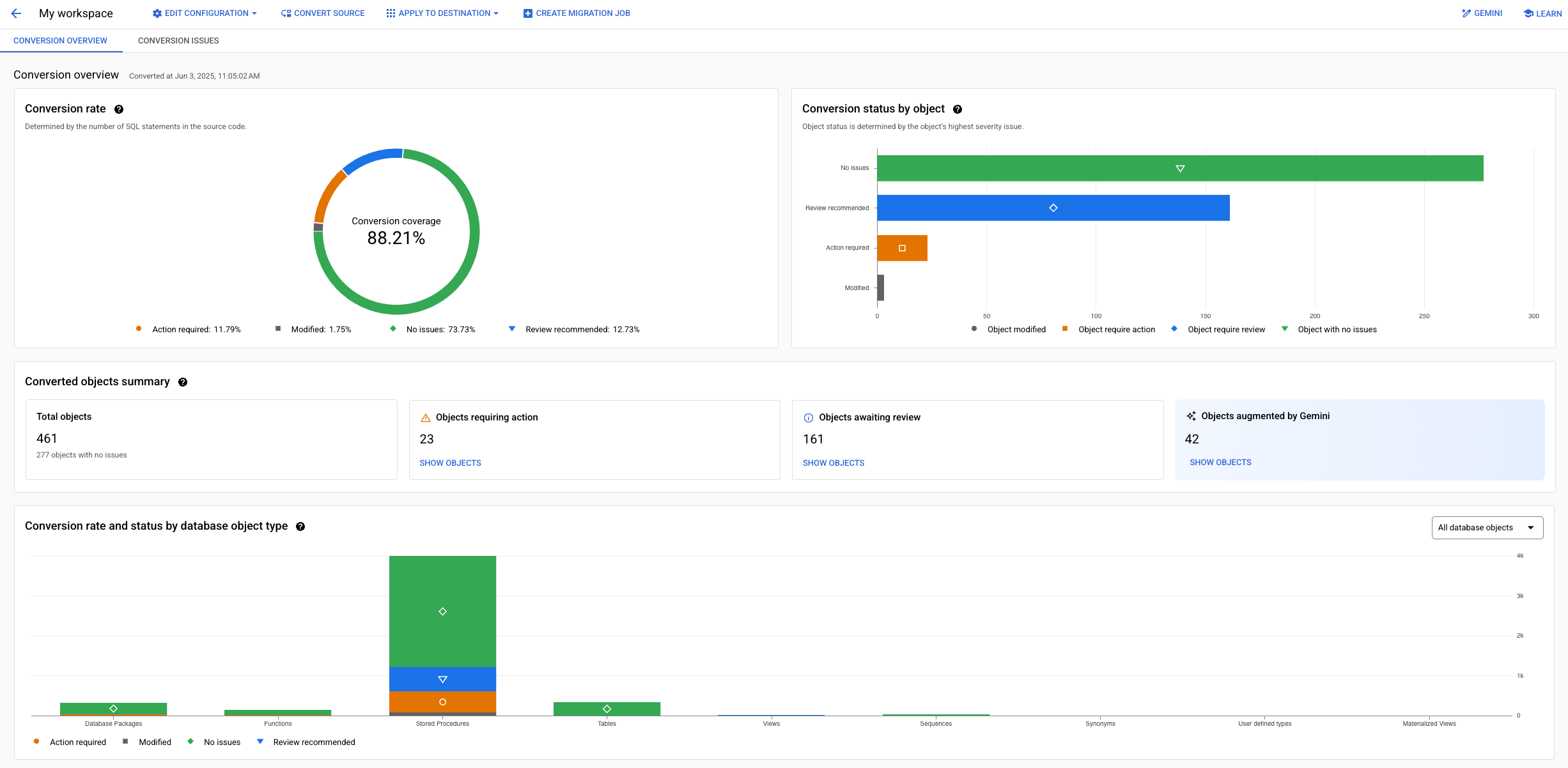
Use essa visualização para filtrar objetos no seu esquema por tipo, gravidade do problema, ações necessárias ou status da conversão.

Para mais informações sobre como usar as visões gerais de conversão para inspecionar os resultados de conversão, consulte Trabalhar com espaços de trabalho de conversão.
Conversão determinista de código e esquema
Ao criar um espaço de trabalho de conversão, o Database Migration Service realiza imediatamente a conversão inicial do esquema usando um conjunto de regras de conversão determinísticas em que tipos de dados e objetos específicos do Oracle são mapeados para tipos de dados e objetos específicos do PostgreSQL. Esse processo é compatível com um subconjunto muito específico de objetos de banco de dados Oracle disponíveis.
A conversão determinística de código oferece suporte aos seguintes objetos de banco de dados Oracle:
Elementos de esquema do Oracle compatíveis
- Restrições
- Índices (apenas os criados no mesmo esquema da tabela)
- Visualizações materializadas
- Tipos de objeto (suporte parcial)
- Sequências
- Sinônimos
- Tabelas
- Visualizações
Elementos de código do Oracle compatíveis
- Gatilhos (somente no nível da tabela)
- Pacotes
- Funções
- Procedimentos armazenados
Editor de SQL interativo
O editor interativo de SQL permite modificar a sintaxe convertida do PostgreSQL diretamente no Database Migration Service. Você pode usar esse recurso para corrigir problemas de conversão ou ajustar o esquema de acordo com suas necessidades. Alguns objetos não podem ser modificados no editor integrado.
Objetos editáveis do Oracle
Depois de converter o código e o esquema do banco de dados de origem, use o editor interativo para modificar o SQL gerado para determinados tipos de objetos. O editor é compatível com os seguintes objetos do Oracle:
- Gatilhos de tabela (requer permissão)
- Visualizações materializadas.
- Pacotes
- Funções, procedimentos armazenados
- Sinônimos
- Visualizações
- Restrições
- Índices
- Sequências
Além disso, alguns objetos são convertidos, mas não podem ser editados diretamente no Database Migration Service. Para modificar esses objetos, faça as atualizações diretamente no banco de dados de destino depois de aplicar o esquema e o código convertidos.
Objetos que não podem ser editados:
- Tipos de objeto definidos pelo usuário
- Tabelas
- Esquemas
Acelere a conversão de código e esquema com o Gemini
O Database Migration Service integra o Gemini para Google Cloud aos espaços de trabalho de conversão para ajudar você a acelerar e melhorar o processo de conversão nas seguintes áreas:
Melhore os resultados da conversão determinística com a conversão automática com tecnologia do Gemini para usar o poder da IA e reduzir significativamente o número de ajustes manuais necessários no seu código PostgreSQL.
Garanta a qualidade e a equivalência funcional do código convertido com as avaliações de qualidade do Gemini. Essas avaliações analisam o código convertido e fornecem feedback sobre a correção e a funcionalidade dele em comparação com o código-fonte.
Ofereça recursos de explicabilidade de código com o assistente de conversão: um conjunto de comandos dedicados que ajudam você a entender melhor a lógica de conversão, propor correções para problemas de conversão ou otimizar o código convertido.
Agilize a aplicação de correções para problemas de conversão com as sugestões de conversão de código do Gemini: um mecanismo em que o modelo do Gemini pode aprender à medida que você corrige problemas de conversão e sugere mudanças em outros objetos com falhas no espaço de trabalho.
Para mais informações sobre a conversão com tecnologia do Gemini, consulte as seguintes páginas:
Arquivos de mapeamento de conversão
É possível personalizar a lógica de conversão com um arquivo de mapeamento de conversão. O arquivo de mapeamento de conversão é um arquivo de texto que contém instruções precisas (chamadas de diretivas de conversão) sobre como seus objetos do Oracle devem ser convertidos em objetos do PostgreSQL.
Diretivas de conversão compatíveis
O Database Migration Service oferece suporte às seguintes diretivas de conversão para arquivos de mapeamento de conversão:
EXPORT_SCHEMA
EXPORT_SCHEMA é uma diretiva obrigatória para todos os arquivos de mapeamento de conversão. O Database Migration Service exige essa instrução para garantir
que os esquemas de origem sejam convertidos nos esquemas de destino corretos.
Verifique se os arquivos de mapeamento de conversão incluem esta linha:
EXPORT_SCHEMA 1
SCHEMA
O Database Migration Service precisa determinar qual esquema contém os objetos que devem ser modificados com suas diretivas de conversão.
A diretiva SCHEMA faz com que todas as outras diretivas de personalização
fornecidas no arquivo sejam aplicadas a objetos neste esquema específico.
- Ao usar essa diretiva, outros esquemas contidos no banco de dados também são convertidos, mas os objetos deles não estão sujeitos a modificações.
- Se você incluir essa diretiva no arquivo de mapeamento de conversão, todas as personalizações serão aplicadas apenas aos objetos contidos nesse esquema específico.
- Se você pular essa diretiva, forneça nomes de objetos totalmente qualificados
que incluam o nome do esquema para objetos modificados por outras diretivas de conversão.
Por exemplo, em vez de usar
SOURCE_TABLE_NAMEpara a diretivaREPLACE_TABLES, use"SCHEMA_NAME.SOURCE_TABLE_NAME". - Para personalizar objetos em esquemas diferentes, faça o seguinte:
- Crie arquivos de mapeamento de conversão separados para outros esquemas e faça upload deles no espaço de trabalho de conversão.
- Use nomes de objetos totalmente qualificados que incluam o nome do esquema para objetos que residem em esquemas diferentes daquele fornecido à diretiva
SCHEMA.
Use o seguinte formato:
SCHEMA SCHEMA_NAME
Em que SCHEMA_NAME é o nome do seu esquema no banco de dados de origem.
CASE_HANDLING
Por padrão, o Database Migration Service converte todos os nomes de objetos em letras minúsculas.
Você pode usar a diretiva CASE_HANDLING para modificar esse
comportamento.
- Essa diretiva não é afetada pela diretiva
SCHEMA. Ele funciona no mundo todo e afeta todos os objetos no espaço de trabalho de conversão. - As diretivas
RENAME_*,MOVE_*eREPLACE_*têm precedência sobre a diretivaCASE_HANDLINGe renomeiam seus objetos exatamente, independente da propriedadeCASE_HANDLING. - Se essa diretiva existir em vários arquivos de configuração com valores conflitantes, o Database Migration Service vai gerar um erro durante a importação do esquema.
Use o seguinte formato:
CASE_HANDLING OPTION
Em que OPTION pode ser um dos seguintes:
UPPERCASE: converte todos os nomes de objetos para maiúsculas.LOWERCASE: converte todos os nomes de objetos para minúsculas (comportamento padrão).PRESERVE_ORIGINAL: mantém o uso de maiúsculas e minúsculas original do esquema de origem. Isso é útil se seus aplicativos usarem identificadores que diferenciam maiúsculas de minúsculas.
Exemplo:
CASE_HANDLING PRESERVE_ORIGINAL
GENERATE_MISSING_PK
Tabelas sem chaves primárias não garantem uma replicação consistente. O Database Migration Service migra apenas tabelas com chaves primárias. Por padrão, os espaços de trabalho de conversão do Database Migration Service criam automaticamente as chaves primárias ausentes nas tabelas de destino quando você converte seu código-fonte e esquema.
É possível controlar a geração automática de chave primária com a diretiva
GENERATE_MISSING_PK. Para desativar a geração automática de chaves, defina essa diretiva como 0.
Exemplo:
GENERATE_MISSING_PK 0
Essa diretiva afeta todos os objetos em um espaço de trabalho de conversão específico. Não é possível desativar a geração automática de chave primária apenas para uma tabela específica.
O Database Migration Service só pode migrar tabelas que têm restrições de chave primária nas versões convertidas do PostgreSQL. Se você desativar a geração automática de chave primária, será necessário criar manualmente chaves primárias ou restrições exclusivas nas tabelas convertidas no banco de dados de destino depois de aplicar o esquema convertido. Expanda as seções a seguir para ver exemplos de comandos SQL.
Criar chaves primárias usando colunas atuais
Sua tabela já pode ter uma chave primária lógica com base em uma coluna ou uma combinação de colunas. Por exemplo, pode haver colunas com uma restrição ou um índice exclusivo configurado. Use essas colunas para gerar uma nova chave primária para tabelas no banco de dados de origem. Exemplo:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME);
Criar uma chave primária usando todas as colunas
Se você não tiver uma restrição preexistente que possa servir como uma chave primária, crie chaves primárias usando todas as colunas da tabela. Verifique se você não excedeu o comprimento máximo da chave primária permitido pelo cluster do PostgreSQL. Exemplo:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME_1, COLUMN_NAME_2, COLUMN_NAME_3, ...);
Ao criar uma chave primária composta como esta, é necessário listar explicitamente todos os nomes de colunas que você quer usar. Não é possível usar uma instrução para recuperar todos os nomes de coluna para essa finalidade.
Criar uma restrição exclusiva com a pseudocoluna ROWID
Os bancos de dados Oracle usam a
pseudocoluna ROWID para armazenar a localização de cada linha em uma tabela. Para migrar tabelas do Oracle
que não têm chaves primárias, adicione uma coluna ROWID
no banco de dados PostgreSQL de destino. O Database Migration Service
preenche a coluna com os valores numéricos correspondentes da
pseudocoluna ROWID do Oracle de origem.
Para adicionar a coluna e defini-la como chave primária, execute o seguinte comando:
ALTER TABLE TABLE_NAME ADD COLUMN rowid numeric(33,0) NOT NULL; CREATE SEQUENCE TABLE_NAME_rowid_seq INCREMENT BY -1 START WITH -1 OWNED BY TABLE_NAME.rowid; ALTER TABLE TABLE_NAME ALTER COLUMN rowid SET DEFAULT nextval('TABLE_NAME_rowid_seq'); ALTER TABLE TABLE_NAME ADD CONSTRAINT CONSTRAINT_DISPLAY_NAME PRIMARY KEY (rowid);
Como renomear objetos (RENAME_*)
É possível renomear diferentes objetos de banco de dados durante a conversão. O Database Migration Service atualiza automaticamente todas as referências de código (em visualizações, procedimentos armazenados, funções etc.) para usar os novos nomes.
Sintaxe geral
RENAME_OBJECT_TYPE SOURCE_NAME1:DESTINATION_NAME1 SOURCE_NAME2:DESTINATION_NAME2 ...
Considerações importantes
-
As diretivas
RENAME_*diferenciam maiúsculas de minúsculas para o nome do objeto de destino e têm precedência sobre a diretivaCASE_HANDLING. Por exemplo, se você usar as duas diretivas:SCHEMA MySchema CASE_HANDLING PRESERVE_ORIGINAL # Destination objects are renamed exactly # to 'SoMe_tAbLe' and 'RenamedView', respecting the case # despite the CASE_HANDLING directive RENAME_TABLES some_table:SoMe_tAbLe RENAME_VIEWS MyView:RenamedView
-
Para o
SOURCE_NAME, sempre consulte o nome original do objeto, mesmo que você use outras diretivas, comoMOVE_*. Por exemplo, se você quiser renomear um dos objetos de visualização e movê-lo para um novo esquema, consulte o nome da visualização original para as duas diretivas:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- A diretiva
RENAME_TABLESsubstitui a diretivaREPLACE_TABLESem um único arquivo. Se você quiser renomear e mover uma tabela, recomendamos usar a diretivaMOVE_*. -
O formato completo da variável
SOURCE_NAMEdepende de você usar também a diretivaSCHEMA:- Com a diretiva
SCHEMA:use nomes não qualificados, por exemplo,MyTable. - Sem a diretiva
SCHEMA:use nomes totalmente qualificados, por exemplo,MySchema.MyTable.
- Com a diretiva
Diretivas RENAME_* compatíveis
RENAME_SCHEMA: renomeia um esquema.
Um único arquivo de configuração pode conter apenas uma diretivaRENAME_SCHEMA. Se a diretivaSCHEMAfor fornecida,RENAME_SCHEMApoderá renomear apenas esse esquema específico.RENAME_TABLES: renomeia tabelas. Substitui oREPLACE_TABLESno mesmo arquivo.RENAME_COLUMNS: renomeia colunas em tabelas. Substitui a diretivaREPLACE_COLSno mesmo arquivo. Use o seguinte formato:RENAME_COLUMNS TABLE1.SRC_COL:DEST_COL TABLE2.SRC_COL:DEST_COL
Se você usar a diretiva
SCHEMA, use nomes de tabela não qualificados. Se você não usar a diretivaSCHEMA, inclua os nomes de tabela totalmente qualificados, como SCHEMA.TABLE1.RENAME_VIEWSRENAME_MATERIALIZED_VIEWSRENAME_SEQUENCESRENAME_FUNCTIONSRENAME_STORED_PROCEDURESRENAME_TRIGGERS-
RENAME_PACKAGES: o Database Migration Service converte pacotes do Oracle em esquemas do PostgreSQL. Se o esquema tiver pacotes com nomes iguais, o código do PostgreSQL poderá encontrar conflitos de nomes ao tentar criar dois esquemas com o mesmo nome. Você pode usar essa diretiva para evitar esses conflitos.Por exemplo, se você tiver pacotes como
SALES.REPORTING_PKGeHR.REPORTING_PKG, renomeie-os para nomes distintos:RENAME_PACKAGES SALES.UTILS:SALES_UTILS RENAME_PACKAGES HR.UTILS:HR_UTILS
RENAME_USER_DEFINED_TYPESAlias disponível:
RENAME_UDTS.
Objetos em movimento (MOVE_*)
É possível mover objetos para esquemas diferentes no banco de dados de destino. Isso é útil para reorganizar a estrutura do banco de dados durante a migração. O Database Migration Service atualiza automaticamente todas as referências de código em visualizações, procedimentos armazenados, funções etc.
Sintaxe geral
MOVE_OBJECT_TYPE SOURCE_NAME1:DESTINATION_SCHEMA1 SOURCE_NAME2:DESTINATION_SCHEMA2 ...
Considerações importantes
-
Para o
SOURCE_NAME, sempre consulte o nome original do objeto, mesmo que você use outras diretivas, comoRENAME_*. Por exemplo, se você quiser renomear um dos objetos de visualização e movê-lo para um novo esquema, consulte o nome da visualização original para as duas diretivas:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- A diretiva espera apenas o nome
DESTINATION_SCHEMA, não o nome completo do objeto. -
O formato completo da variável
SOURCE_NAMEdepende de você usar também a diretivaSCHEMA:- Com a diretiva
SCHEMA:use nomes não qualificados, por exemplo,MyTable. - Sem a diretiva
SCHEMA:use nomes totalmente qualificados, por exemplo,MySchema.MyTable.
- Com a diretiva
Diretivas MOVE_* compatíveis
MOVE_TABLES: move tabelas para um esquema diferente. Tem precedência sobreREPLACE_TABLESpara mudanças de esquema em um único arquivo de configuração.MOVE_VIEWSMOVE_MATERIALIZED_VIEWSMOVE_SEQUENCESMOVE_FUNCTIONSMOVE_STORED_PROCEDURESMOVE_USER_DEFINED_TYPESAlias disponível:
MOVE_UDTS.
Exemplo: reorganização de esquemas
SCHEMA LegacyApp # Moves the 'LegacyApp.Users' and 'LegacyApp.Orders' tables # to the 'data' schema. MOVE_TABLES Users:data Orders:data # Moves the 'LegacyApp.CreateUser' and 'LegacyApp.ProcessOrder' # stored procedures to the 'api' schema MOVE_STORED_PROCEDURES CreateUser:api ProcessOrder:api # Moves the 'LegacyApp.SalesSummary' views to the 'reporting' schema MOVE_VIEWS SalesSummary:reporting
DATA_TYPE
Use essa diretiva para mapear explicitamente qualquer tipo de dados compatível entre a sintaxe do Oracle e do PostgreSQL. Essa diretiva
espera uma lista de mapeamentos separados por vírgulas. A definição inteira precisa ser fornecida em uma única linha, mas é possível incluir várias diretivas DATA_TYPE no arquivo de configuração. Use o seguinte formato:
DATA_TYPE ORACLE_DATA_TYPE1:PGSQL_DATA_TYPE1 DATA_TYPE ORACLE_DATA_TYPE2:PGSQL_DATA_TYPE2...
Em que ORACLE_DATA_TYPE e PGSQL_DATA_TYPE são tipos de dados compatíveis com as respectivas versões do Oracle e do PostgreSQL usadas na migração. Para informações sobre as versões compatíveis, consulte Visão geral do cenário.
Exemplo:
DATA_TYPE REAL:double precision,SMALLINT:integer
Para mais informações sobre tipos de dados do Oracle e do PostgreSQL, consulte:
- Tipos de dados do Oracle na documentação do Oracle.
- Tipos de dados do PostgreSQL na documentação do PostgreSQL.
MODIFY_TYPE
A diretiva MODIFY_TYPE permite controlar para qual
tipo de dados o Database Migration Service converte uma coluna específica na tabela de origem.
Essa diretiva espera uma lista de mapeamentos separados por vírgulas.
Toda a definição precisa ser fornecida em uma única linha, mas você pode incluir várias diretivas MODIFY_TYPE no arquivo de configuração.
Use o seguinte formato:
MODIFY_TYPE SOURCE_TABLE_NAME1:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE MODIFY_TYPE SOURCE_TABLE_NAME2:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE...
Em que:
- SOURCE_TABLE_NAME é o nome da tabela que contém a coluna em que você quer mudar o tipo de dados.
- COLUMN_NAME é o nome da coluna para a qual você quer personalizar o mapeamento de conversão.
- EXPECTED_END_RESULT_DATA_TYPE é o tipo de dados do PostgreSQL que você quer que a coluna convertida use.
Exemplo:
MODIFY_TYPE events:dates_and_times:DATETIME,users:pseudonym:TEXT
PG_INTEGER_TYPE
Por padrão,o Database Migration Service converte os tipos NUMBER(p,s) para o tipo DECIMAL(p,s) do PostgreSQL.
É possível modificar esse comportamento com a diretiva PG_INTEGER_TYPE. Defina o valor como 1 e force todos os tipos NUMBER com precisão e escala (NUMBER(p,s)) a serem convertidos em tipos smallint, integer ou bigint do PostgreSQL com base no número de dígitos de precisão.
Inclua a seguinte configuração no arquivo de mapeamento de conversão:
PG_INTEGER_TYPE 1
PG_NUMERIC_TYPE
Defina essa diretiva como 1 se quiser converter todos os tipos NUMBER com precisão e escala (NUMBER(p,s)) em tipos real ou float do PostgreSQL (com base no número de dígitos de precisão).
Se você definir essa diretiva como 0, os valores NUMBER(p,s) vão preservar o valor original exato e usar o tipo de dados interno do PostgreSQL.
Inclua a seguinte configuração no arquivo de mapeamento de conversão:
PG_NUMERIC_TYPE 1
DEFAULT_NUMERIC
A conversão padrão para NUMBERs sem precisão muda se você também usa a diretiva
PG_INTEGER_TYPE:
- Se você usar a diretiva
PG_INTEGER, osNUMBERs sem precisão serão convertidos em valoresDECIMAL. - Se você não usar a diretiva
PG_INTEGER, osNUMBERs sem precisão serão convertidos em valoresBIGINT.
É possível modificar esse comportamento e usar a diretiva DEFAULT_NUMERIC para especificar qual tipo de dados deve ser usado para tipos NUMBER sem pontos de precisão especificados.
Use o seguinte formato:
DEFAULT_NUMERIC POSTGRESQL_NUMERIC_DATA_TYPE
em que POSTGRESQL_NUMERIC_DATA_TYPE é um dos seguintes: integer, smallint, bigint.
Exemplo:
DEFAULT_NUMERIC integer
REPLACE_COLS
Use a diretiva REPLACE_COLS para renomear colunas no esquema convertido. Essa diretiva espera uma lista de mapeamentos separados por vírgulas.
Use o seguinte formato:
REPLACE_COLS SOURCE_TABLE_NAME1(SOURCE1_TABLE1_COLUMN_NAME1:DESTINATION_TABLE1_COLUMN_NAME1,SOURCE_TABLE1_COLUMN_NAME2:DESTINATION_TABLE1_COLUMN_NAME2),SOURCE_TABLE_NAME2(SOURCE_TABLE2_COLUMN_NAME1:DESTINATION_TABLE2_COLUMN_NAME1,SOURCE_TABLE2_COLUMN_NAME2:DESTINATION_TABLE2_COLUMN_NAME2)...
Em que:
- SOURCE_TABLE_NAME é o nome da tabela
que contém a coluna cujo nome você quer mudar. Se você não usar a diretiva SCHEMA, use o nome totalmente qualificado da tabela:
SCHEMA_NAME.SOURCE_TABLE_NAME - SOURCE_COLUMN_NAME é o nome da coluna na sua fonte que você quer mudar.
- DESTINATION_COLUMN_NAME é o novo nome da coluna que você quer usar no esquema convertido.
Exemplo:
REPLACE_COLS events(dates_and_times:event_dates),users(pseudonym:nickname)
REPLACE_TABLES
Use a diretiva REPLACE_TABLES para renomear tabelas ou movê-las para um novo esquema. Essa diretiva espera uma lista de mapeamentos separados por espaços. Para mais informações sobre a sintaxe de cada caso de uso, abra as seções a seguir.
Se você não usar a diretiva SCHEMA, use os nomes de tabela totalmente qualificados entre aspas para as variáveis de origem e destino:
"SCHEMA_NAME.SOURCE_TABLE_NAME""SCHEMA_NAME.DESTINATION_TABLE_NAME"
Como renomear tabelas
Para renomear tabelas no esquema convertido, use o seguinte formato:
REPLACE_TABLES SOURCE_TABLE_NAME1:DESTINATION_TABLE_NAME1 SOURCE_TABLE_NAME2:DESTINATION_TABLE_NAME2
Em que:
- SOURCE_TABLE_NAME é o nome da tabela de origem que você quer renomear no esquema convertido.
- DESTINATION_TABLE_NAME é o novo nome da tabela que você quer usar no esquema convertido.
Exemplo:
REPLACE_TABLES "events:login_events" "users:platform_users"
Como mover tabelas entre esquemas
Use essa diretiva para mover tabelas entre esquemas adicionando o prefixo do esquema ao novo nome da tabela. Esse mecanismo pode ser usado independente de como você usa a diretiva SCHEMA para todo o arquivo de conversão. Exemplo:
REPLACE_TABLES "events:NEW_SCHEMA_NAME.login_events"
Pseudônimos para personalizar tipos de dados
Ao usar diretivas de conversão para modificar como o Database Migration Service converte
diferentes tipos de dados (por exemplo, com as diretivas
DATA_TYPE,
MODIFY_TYPE ou
PG_NUMERIC_TYPE), é possível usar
aliases em vez dos tipos de dados SQL de origem.
Expanda a seção a seguir para conferir a lista de aliases de tipos de dados compatíveis com o Database Migration Service.
Aliases de tipo de dados
| Alias | Convertido para o tipo PostgreSQL |
|---|---|
bigint, int8 |
BIGINT |
bool, boolean |
BOOLEAN |
bytea |
BYTEA |
char, character |
CHAR |
character varying, varchar |
VARCHAR |
date |
DATE |
decimal, numeric |
DECIMAL |
double precision, float8 |
DOUBLE PRECISION |
real, float4 |
REAL |
int, integer, int4 |
INTEGER |
int2 |
SMALLINT |
interval |
INTERVAL |
json |
JSON |
smallint |
SMALLINT |
text |
TEXT |
time |
TIME |
timestamp |
TIMESTAMP |
timestamptz |
TIMESTAMPTZ |
timetz |
TIMETZ |
uuid |
UUID |
XML |
XML |
Exemplo de arquivo de mapeamento de conversão
Confira o exemplo de arquivo de mapeamento de conversão a seguir, que usa algumas das diretivas de conversão de esquema compatíveis:
EXPORT_SCHEMA 1 SCHEMA root # Preserve original casing for all objects CASE_HANDLING PRESERVE_ORIGINAL # Data type conversions PG_NUMERIC_TYPE 0 PG_INTEGER_TYPE 1 DEFAULT_NUMERIC integer DATA_TYPE NUMBER(4\,0):integer MODIFY_TYPE events:dates_and_times:TIMESTAMP # Renaming objects using the RENAME_* directives # These allow case-sensitive destination names RENAME_TABLES events:LoginEvents users:PlatformUsers RENAME_COLUMNS events.dates_and_times:EventDates users.pseudonym:Nickname RENAME_VIEWS InternalReport:FinInternalReport # Moving objects to new schemas using the MOVE_* directives MOVE_TABLES audit_log:archive MOVE_VIEWS InternalReport:reporting
Os resultados do uso desse arquivo são os seguintes:
EXPORT_SCHEMA 1é uma diretiva obrigatória.SCHEMA rootfaz com que as outras diretivas sejam aplicadas a objetos no esquemaroot, a menos que nomes totalmente qualificados sejam usados.CASE_HANDLING PRESERVE_ORIGINALgarante que todos os nomes de objetos do esquemarootde origem mantenham o uso de maiúsculas e minúsculas original no destino, a menos que sejam substituídos por uma diretivaRENAME_*.- O
PG_INTEGER_TYPE 1faz com que o Database Migration Service converta todos os tipos de dados numéricos do Oracle encontrados em tabelas no esquemarootpara tipos específicos do PostgreSQL em vez de tipos numéricos portáteis ANSI. DEFAULT_NUMERIC integerfaz com que o Database Migration Service converta valoresNUMBERque não têm um ponto de precisão especificado no tipoINTEGERdo PostgreSQL.DATA_TYPE NUMBER(4\,0):integerfaz com que o Database Migration Service converta valoresNUMBER(4,0)específicos paraINTEGERdo PostgreSQL.- A diretiva
MODIFY_TYPE events:dates_and_times:TIMESTAMPfaz com que o Database Migration Service converta os dados na colunadates_and_timesda tabela de origemeventsespecificamente para o tipoTIMESTAMPdo PostgreSQL. RENAME_TABLES events:LoginEvents users:PlatformUsersrenomeia tabelas, preservando o caso especificado:- A tabela
eventsfoi renomeada comoLoginEvents. - A tabela
usersfoi renomeada comoPlatformUsers.
- A tabela
RENAME_COLUMNS events.dates_and_times:EventDates user.pseudonym:Nicknamerenomeia colunas, preservando o caso especificado no destino:- Na tabela
LoginEvents(nome originalevents), a colunadates_and_timesé renomeada comoEventDates. - Na coluna
PlatformUsers(nome originalusers),pseudonymé renomeada comoNickname.
- Na tabela
RENAME_VIEWS InternalReport:FinInternalReportrenomeia a visualizaçãoInternalReportcomoFinInternalReport.MOVE_TABLES audit_log:archivemove a tabelaaudit_logdo esquemarootpara o esquemaarchive.MOVE_VIEWS InternalReport:reportingmove a visualizaçãoInternalReportpara o esquemareporting. Essa visualização também é renomeada comoFinInternalReportdevido à diretivaRENAME_VIEWS. O Database Migration Service processa a dependência: primeiro o objeto é renomeado e depois movido.
Espaços de trabalho de conversão legados
Os espaços de trabalho de conversão legados são um tipo mais antigo e limitado de espaços de trabalho de conversão. Os espaços de trabalho de conversão legados não são compatíveis com os recursos de conversão aprimorados com o Gemini nem com o editor interativo de SQL. Você só pode usá-los para converter o esquema de origem com a ferramenta de migração Ora2Pg.
Não recomendamos usar o tipo legado de espaços de trabalho de conversão para suas migrações. Se o seu cenário exigir o uso de espaços de trabalho de conversão legados, consulte Trabalhar com espaços de trabalho de conversão legados.
A seguir
Para saber como usar os espaços de trabalho de conversão, consulte: