
Integração com o Salesforce (SFDC)
Esta página descreve as etapas de integração da carga de trabalho operacional do Salesforce (SFDC) na Data Foundation do Cortex Framework. O Cortex Framework integra dados do Salesforce com pipelines do Dataflow ao BigQuery, enquanto o Serviço Gerenciado para Apache Airflow programa e monitora esses pipelines do Dataflow para gerar insights dos seus dados.
Arquivo de configuração
O config.json
arquivo no
repositório da Data Foundation do Cortex Framework
configura as definições necessárias para transferir dados de
qualquer fonte de dados, incluindo o Salesforce. Esse arquivo contém os seguintes parâmetros para cargas de trabalho operacionais do Salesforce:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
A tabela a seguir descreve o valor de cada parâmetro operacional do SFDC:
| Parâmetro | Significado | Valor padrão | Descrição |
SFDC.deployCDC
|
Implantar CDC | true
|
Gere scripts de processamento de CDC para serem executados como DAGs no Serviço Gerenciado para Apache Airflow. Consulte a documentação para conferir diferentes opções de ingestão do Salesforce Sales Cloud. |
SFDC.createMappingViews
|
Criar visualizações de mapeamento | true
|
Os DAGs fornecidos para buscar novos registros
das APIs do Salesforce atualizam os registros no destino. Esse valor definido como "true"
gera visualizações no conjunto de dados processado pelo CDC para expor tabelas com
a "versão mais recente da verdade" do conjunto de dados bruto. Se for falso e
SFDC.deployCDC for true, os DAGs serão gerados
com o processamento de captura de dados alterados (CDC) com base no SystemModstamp. Confira detalhes
sobre o processamento de CDC para o Salesforce.
|
SFDC.createPlaceholders
|
Criar marcadores | true
|
Crie tabelas de marcador vazias caso elas não sejam geradas pelo processo de ingestão para permitir que a implantação de relatórios downstream seja executada sem falhas. |
SFDC.datasets.raw
|
Conjunto de dados de destino bruto | - | Usado pelo processo de CDC, é aqui que a ferramenta de replicação coloca os dados do Salesforce. Se você estiver usando dados de teste, crie um conjunto de dados vazio. |
SFDC.datasets.cdc
|
Conjunto de dados processado pelo CDC | - | Conjunto de dados que funciona como uma fonte para as visualizações de relatórios e como destino para os DAGs de registros processados. Se você estiver usando dados de teste, crie um conjunto de dados vazio. |
SFDC.datasets.reporting
|
Conjunto de dados de relatórios SFDC | "REPORTING_SFDC"
|
Nome do conjunto de dados acessível aos usuários finais para relatórios, em que as visualizações e as tabelas voltadas ao usuário são implantadas. |
SFDC.currencies
|
Filtrar moedas | [ "USD" ]
|
Se você não estiver usando dados de teste, insira uma
única moeda (por exemplo, [ "USD" ]) ou várias moedas
(por exemplo,[ "USD", "CAD" ]) relevantes para sua empresa.
Esses valores são usados para substituir marcadores em SQL em modelos de análise
quando disponíveis.
|
Modelo de dados
Esta seção descreve o modelo de dados do Salesforce (SFDC) usando o diagrama de entidade-relacionamento (ERD, na sigla em inglês).
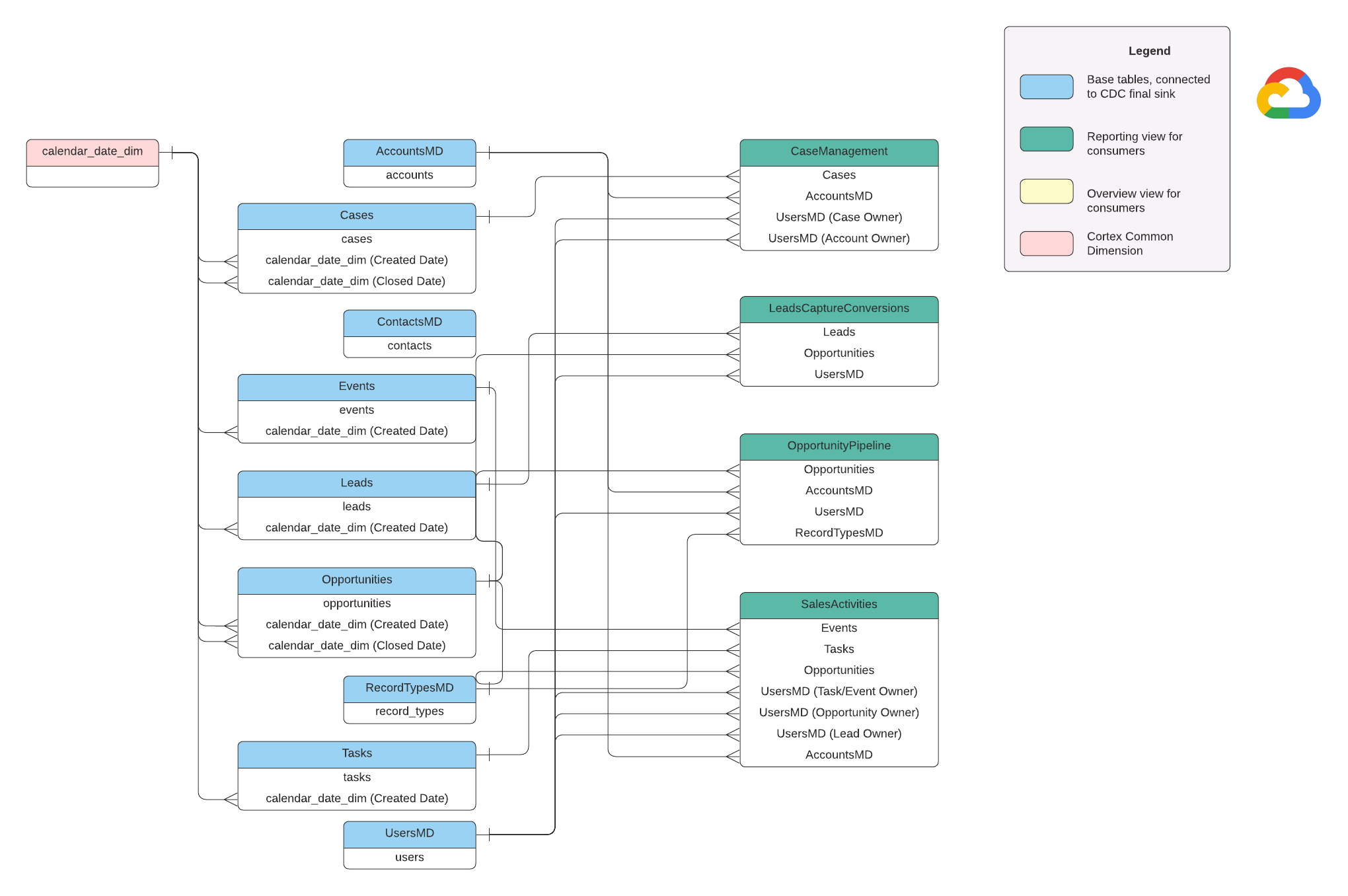
Visualizações básicas
Esses são os objetos azuis no ERD e são visualizações em tabelas de CDC sem transformações, exceto alguns aliases de nome de coluna. Consulte os scripts em
src/SFDC/src/reporting/ddls.
Vista de relatórios
Esses são os objetos verdes no ERD e contêm os atributos dimensionais relevantes usados pelas tabelas de relatórios. Consulte os scripts em
src/SFDC/src/reporting/ddls.
Requisitos de dados do Salesforce
Esta seção descreve os detalhes de como os dados do Salesforce precisam ser estruturados para uso com o Cortex Framework.
- Estrutura da tabela:
- Nomenclatura:os nomes das tabelas usam
snake_case(palavras em letras minúsculas separadas por sublinhados) e são plurais. Por exemplo,some_objects. - Tipos de dados:as colunas mantêm os mesmos tipos de dados representados no Salesforce.
- Legibilidade:alguns nomes de campos podem ser ligeiramente ajustados para maior clareza na camada de relatórios.
- Nomenclatura:os nomes das tabelas usam
- Tabelas vazias e implantação:todas as tabelas necessárias ausentes do conjunto de dados bruto são criadas automaticamente como tabelas vazias durante o processo de implantação. Isso garante a execução tranquila da etapa de implantação do CDC.
- Requisitos de CDC: Os campos
IdeSystemModstampsão essenciais para que os scripts de CDC rastreiem as mudanças nos seus dados. Eles podem ter esses nomes exatos ou diferentes. Os scripts de processamento bruto fornecidos buscam esses campos automaticamente nas APIs e atualizam a tabela de replicação de destino.Id: funciona como um identificador exclusivo para cada registro.SystemModstamp: esse campo armazena um carimbo de data/hora que indica a última vez que um registro foi modificado.
- Scripts de processamento bruto:os scripts de processamento bruto fornecidos não exigem processamento adicional (CDC). Esse comportamento é definido durante a implantação por padrão.
Tabelas de origem para conversão de moeda
O Salesforce permite gerenciar moedas de duas maneiras:
- Básico:é o padrão, em que todos os dados usam uma única moeda.
- Avançado: converte entre várias moedas com base nas taxas de câmbio (requer a ativação do gerenciamento avançado de moedas).
Se você usar o gerenciamento avançado de moedas, o Salesforce usará duas tabelas especiais:
- CurrencyTypes: essa tabela armazena informações sobre as diferentes moedas que você usa (por exemplo, USD, EUR etc.).
- DatedConversionRates: essa tabela contém as taxas de câmbio entre moedas ao longo do tempo.
O Cortex Framework espera que essas tabelas estejam presentes se você usar o gerenciamento avançado de moedas. Se você não usar o gerenciamento avançado de moedas, poderá
remover as entradas relacionadas a essas tabelas de um arquivo de configuração
(src/SFDC/config/ingestion_settings.yaml).
Essa etapa evita tentativas desnecessárias de extrair dados de tabelas inexistentes.
Como carregar dados do SFDC no BigQuery
O Cortex Framework oferece uma solução de replicação com base em scripts Python programados em Apache Airflow e API Bulk 2.0 do Salesforce. Esses scripts Python podem ser adaptados e programados na ferramenta de sua escolha. Para mais informações, consulte o módulo de extração do SFDC.
O Cortex Framework também oferece três métodos diferentes para integrar seus dados, dependendo de onde eles vêm e como são gerenciados:
- Chamadas de API:essa opção é para dados que podem ser acessados diretamente por uma API. O Cortex Framework pode chamar a API, extrair os dados e armazená-los em um conjunto de dados "bruto" no BigQuery. Se houver registros no conjunto de dados, o Cortex Framework poderá atualizá-los com os novos dados.
- Visualizações de mapeamento de estrutura:esse método é útil se você já tiver carregado seus dados no BigQuery usando outra ferramenta, mas a estrutura de dados não corresponder ao que o Cortex Framework precisa. O Cortex Framework usa "visualizações" (como tabelas virtuais) para traduzir a estrutura de dados atual para o formato esperado pelos recursos de relatórios do Cortex Framework.
Scripts de processamento de CDC (captura de dados alterados):essa opção foi projetada especificamente para dados que estão em constante mudança. Os scripts de CDC rastreiam essas mudanças e atualizam os dados no BigQuery de acordo. Esses scripts dependem de dois campos especiais nos seus dados:
Id: identificador exclusivo para cada registro.SystemModstamp: um carimbo de data/hora que indica quando um registro foi alterado.
Se os dados não tiverem esses nomes exatos, os scripts poderão ser ajustados para reconhecê-los com nomes diferentes. Também é possível adicionar campos personalizados ao esquema de dados durante esse processo. Por exemplo, a tabela de origem com dados do objeto da conta precisa ter os campos
IdeSystemModstamporiginais. Se esses campos tiverem nomes diferentes, osrc/SFDC/src/table_schema/accounts.csvarquivo precisará ser atualizado com o nome do campoIdmapeado paraAccountIde qualquer campo de carimbo de data/hora de modificação do sistema mapeado paraSystemModstamp. Para mais informações, consulte a documentação do SystemModStamp.
Se você já tiver carregado dados usando outra ferramenta (e eles forem atualizados constantemente), o Cortex ainda poderá usá-los. Os scripts de CDC vêm com arquivos de mapeamento que podem traduzir sua estrutura de dados atual para o formato necessário para o Cortex Framework. Você pode até adicionar campos personalizados aos seus dados durante esse processo.
Configurar a integração da API e o CDC
Para trazer seus dados do Salesforce para o BigQuery, use as seguintes maneiras:
- Scripts do Cortex para chamadas de API: fornece scripts de replicação para o Salesforce ou uma ferramenta de replicação de dados de sua escolha.A chave é que os dados que você traz precisam ser iguais aos que vieram das APIs do Salesforce.
- Ferramenta de replicação e anexar sempre : se você estiver usando uma ferramenta de replicação, essa maneira é para uma ferramenta que pode adicionar novos registros de dados (_appendalways_pattern) ou atualizar registros atuais.
- Ferramenta de replicação e adicionar novos registros: se a ferramenta não atualizar os registros e replicar as mudanças como novos registros em uma tabela de destino (bruta), a Data Foundation do Cortex oferece a opção de criar scripts de processamento de CDC. Para mais informações, consulte Processo de CDC.

Para garantir que seus dados correspondam ao que o Cortex Framework espera, ajuste a configuração de mapeamento para mapear sua ferramenta de replicação ou esquemas atuais. Isso gera visualizações de mapeamento compatíveis com a estrutura esperada pela Data Foundation do Cortex Framework.
Use o arquivo ingestion_settings.yaml para configurar
a geração de scripts para chamar as APIs do Salesforce e replicar os
dados no conjunto de dados bruto (seção salesforce_to_raw_tables) e a
geração de scripts para processar as mudanças recebidas no conjunto de dados bruto e
no conjunto de dados processado pelo CDC (seção raw_to_cdc_tables).
Por padrão, os scripts fornecidos para leitura de APIs atualizam as mudanças no conjunto de dados bruto. Portanto, os scripts de processamento de CDC não são necessários, e as visualizações de mapeamento para alinhar o esquema de origem ao esquema esperado são criadas.
A geração de scripts de processamento de CDC não é executada se SFDC.createMappingViews=true
em config.json (comportamento padrão). Se os scripts de CDC forem necessários, defina SFDC.createMappingViews=false. Essa segunda etapa também permite o mapeamento entre os esquemas de origem nos esquemas necessários, conforme exigido pela Data Foundation do Cortex Framework.
O exemplo a seguir de um arquivo de configuração setting.yaml ilustra a geração de visualizações de mapeamento quando uma ferramenta de replicação atualiza os dados diretamente no conjunto de dados replicado, conforme ilustrado na option 3 (ou seja, nenhum CDC é necessário, apenas o remapeamento de tabelas e nomes de campos). Como nenhum CDC é necessário, essa opção é executada enquanto o parâmetro SFDC.createMappingViews no arquivo config.json permanecer true.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
Neste exemplo, a remoção da configuração de uma tabela base ou de todas elas das seções ignora a geração de DAGs dessa tabela base ou de toda a seção, conforme ilustrado para salesforce_to_raw_tables. Para esse cenário, definir o parâmetro deployCDC : False tem o mesmo efeito, já que nenhum script de processamento de CDC precisa ser gerado.
Mapeamento de dados
É necessário mapear os campos de dados recebidos para o formato esperado pela Data Foundation do Cortex. Por exemplo, um campo chamado unicornId do seu sistema de dados de origem precisa ser renomeado e reconhecido como AccountId (com um tipo de dados de string) na Data Foundation do Cortex:
- Campo de origem:
unicornId(nome usado no sistema de origem) - Campo do Cortex:
AccountId(nome esperado pelo Cortex) - Tipo de dados:
String(tipo de dados esperado pelo Cortex)
Mapear campos polimórficos
A Data Foundation do Cortex Framework oferece suporte ao mapeamento de campos polimórficos, que são campos cujo nome pode variar, mas a estrutura permanece consistente. Os nomes de tipos de campos polimórficos (por exemplo, Who.Type) podem ser replicados adicionando um item [Field Name]_Type nos arquivos CSV de mapeamento respectivos:
src/SFDC/src/table_schema/tasks.csv. Por exemplo, se você precisar que o campo Who.Type do objeto Task seja replicado, adicione a linha Who_Type,Who_Type,STRING. Isso define um novo campo chamado Who.Type que é mapeado para si mesmo (mantém o mesmo nome) e tem um tipo de dados de string.
Modificar modelos de DAG
Talvez seja necessário ajustar os modelos de DAG para CDC ou para processamento de dados brutos, conforme exigido por sua instância do Airflow ou do Airflow Gerenciado. Para mais informações, consulte Coletar configurações do Airflow Gerenciado.
Se você não precisar de CDC ou geração de dados brutos de chamadas de API, defina deployCDC=false. Como alternativa, remova o conteúdo das
seções em ingestion_settings.yaml. Se as estruturas de dados forem conhecidas como consistentes com as esperadas pela Data Foundation do Cortex Framework, você poderá ignorar a geração de visualizações de mapeamento definindo SFDC.createMappingViews=false.
Configurar o módulo de extração
Esta seção apresenta as etapas para usar o módulo de extração do Salesforce para o BigQuery fornecido pela Data Foundation. Seus requisitos e fluxo podem variar dependendo do seu sistema e da configuração atual. Como alternativa, você pode usar outras ferramentas disponíveis.
Configurar credenciais e app conectado
Faça login como administrador na sua instância do Salesforce para concluir as seguintes etapas:
- Crie ou identifique um perfil no Salesforce que atenda aos seguintes requisitos:
Permission for Apex REST Services and API Enabledé concedida em Permissões do sistema.- A permissão
View Allé concedida para todos os objetos que você quer replicar. Por exemplo, conta e casos. Verifique se há restrições ou problemas com o administrador de segurança. - Nenhuma permissão concedida para relacionada ao login da interface do usuário, como Salesforce Anywhere no Lightning Experience, Salesforce Anywhere no celular, usuário do Lightning Experience e usuário do Lightning Login. Verifique se há restrições ou problemas com o administrador de segurança.
- Crie ou use um usuário atual no Salesforce. Você precisa saber
o nome de usuário, a senha e o token de segurança do usuário. Considere o seguinte:
- O ideal é que seja um usuário dedicado a executar essa replicação.
- O usuário precisa ser atribuído ao perfil que você criou ou identificou na etapa 1.
- Você pode conferir o nome de usuário e redefinir a senha aqui.
- É possível redefinir o token de segurança se você não o tiver e ele não for usado por outro processo.
- Crie um App conectado. É o único canal de comunicação para estabelecer conexão
com o Salesforce do mundo externo com a ajuda do perfil, da API do Salesforce, das credenciais de usuário padrão e do token de segurança.
- Siga as instruções para ativar as configurações do OAuth para integração de API.
- Verifique se
Require Secret for Web Server FloweRequire Secretfor Refresh Token Flowestão ativados na seção API (configurações do OAuth ativadas). - Consulte a documentação sobre como receber seu token do cliente (que será usado posteriormente como seu ID do cliente). Verifique com o administrador de segurança se há problemas ou restrições.
- Atribua seu app conectado ao perfil criado.
- Selecione Configuração no canto superior direito da tela inicial do Salesforce.
- Na caixa Pesquisa rápida , insira
profilee selecione Perfil. Pesquise o perfil criado na etapa 1. - Abra o perfil.
- Clique no link Apps conectados atribuídos.
- Clique em Editar.
- Adicione o app conectado recém-criado.
- Clique no botão Salvar.
Configurar o Secret Manager
Configure o Secret Manager para armazenar detalhes da conexão. O módulo do Salesforce para o BigQuery depende do Secret Manager para armazenar com segurança as credenciais necessárias para se conectar ao Salesforce e ao BigQuery. Essa abordagem evita a exposição de informações sensíveis, como senhas, diretamente no código ou nos arquivos de configuração, aumentando a segurança.
Crie um secret com as seguintes especificações. Para mais instruções detalhadas, consulte Criar um secret.
- Nome do secret:
airflow-connections-salesforce-conn Valor do secret:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`Substitua:
USERNAMEpelo seu nome de usuário.PASSWORDpela sua senha.INSTANCE_NAMEpelo nome da instância.CLIENT_IDpelo ID do cliente.SECRET_TOKENpelo seu token secreto.
Para mais informações, consulte Como encontrar o nome da instância.
Bibliotecas do Airflow Gerenciado para replicação
Para executar os scripts Python nos DAGs fornecidos pela Data Foundation do Cortex Framework, é necessário instalar algumas dependências. Para a versão 1.10 do Airflow, siga a documentação Instalar dependências do Python para o Serviço Gerenciado para Apache Airflow 1 para instalar os seguintes pacotes, em ordem:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Para a versão 2.x do Airflow, consulte a documentação Instalar dependências do Python para o Serviço Gerenciado para Apache Airflow 2 para instalar apache-airflow-providers-salesforce~=5.2.0.
Use o comando a seguir para instalar cada pacote necessário:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
Substitua:
ENVIRONMENT_NAMEpelo nome do ambiente atribuído.LOCATIONpelo local.PACKAGE_NAMEpelo nome do pacote escolhido.EXTRAS_AND_VERSIONpelas especificações dos extras e da versão.
O comando a seguir é um exemplo de instalação de pacote necessária:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Ativar o Secret Manager como back-end
Ative o Google Secret Manager como back-end de segurança. Esta etapa instrui você a ativar o Secret Manager como o local de armazenamento principal para informações sensíveis, como senhas e chaves de API usadas pelo seu ambiente do Serviço Gerenciado para Apache Airflow. Isso aumenta a segurança centralizando e gerenciando credenciais em um serviço dedicado. Para mais informações, consulte Secret Manager.
Permitir que a conta de serviço do Composer acesse secrets
Essa etapa garante que a conta de serviço associada ao Serviço Gerenciado para Apache Airflow tenha as permissões necessárias para acessar secrets armazenados no Secret Manager.
Por padrão, o Serviço Gerenciado para Apache Airflow usa a conta de serviço do Compute Engine.
A permissão necessária é Secret Manager Secret Accessor.
Essa permissão permite que a conta de serviço recupere e use secrets armazenados
no Secret Manager.Para um guia abrangente sobre como configurar controles de acesso
no Secret Manager, consulte
a documentação de controle de acesso.
Conexão do BigQuery no Airflow
Crie a conexão sfdc_cdc_bq de acordo com
Coletar configurações do Airflow Gerenciado. Essa conexão provavelmente é usada pelo módulo do Salesforce para o BigQuery para estabelecer comunicação com o BigQuery.
A seguir
- Para mais informações sobre outras fontes de dados e cargas de trabalho, consulte Fontes de dados e cargas de trabalho.
- Para mais informações sobre as etapas de implantação em ambientes de produção, consulte Pré-requisitos de implantação da Data Foundation do Cortex Framework.