
Integrazione con Salesforce (SFDC)
Questa pagina descrive i passaggi di integrazione per il workload operativo di Salesforce (SFDC) in Cortex Framework Data Foundation. Cortex Framework integra i dati di Salesforce con le pipeline Dataflow in BigQuery, mentre Managed Service for Apache Airflow pianifica e monitora queste pipeline Dataflow per ottenere insight dai dati.
File di configurazione
Il config.json
file nel
repository di Cortex Framework Data Foundation
configura le impostazioni necessarie per trasferire i dati da
qualsiasi origine dati, inclusa Salesforce. Questo file contiene i seguenti parametri per i workload operativi di Salesforce:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
La tabella seguente descrive il valore di ogni parametro operativo di SFDC:
| Parametro | Significato | Valore predefinito | Descrizione |
SFDC.deployCDC
|
Esegui il deployment di CDC | true
|
Genera script di elaborazione CDC da eseguire come DAG in Managed Service for Apache Airflow. Consulta la documentazione per le diverse opzioni di importazione per Salesforce Sales Cloud. |
SFDC.createMappingViews
|
Crea viste di mapping | true
|
I DAG forniti per recuperare i nuovi record
dalle API di Salesforce aggiornano i record al momento dell'importazione. Se questo valore è impostato su true
genera viste nel set di dati elaborato da CDC per esporre le tabelle con
la "versione più recente della verità" dal set di dati non elaborati. Se è impostato su false e
SFDC.deployCDC è true, i DAG vengono generati
con l'elaborazione Change Data Capture (CDC) basata su SystemModstamp. Consulta i dettagli
su elaborazione CDC per Salesforce.
|
SFDC.createPlaceholders
|
Crea segnaposto | true
|
Crea tabelle segnaposto vuote nel caso in cui non vengano generate dal processo di importazione per consentire l'esecuzione del deployment dei report downstream senza errori. |
SFDC.datasets.raw
|
Set di dati di importazione non elaborati | - | Utilizzato dal processo CDC, è il punto in cui lo strumento di replica importa i dati da Salesforce. Se utilizzi dati di test, crea un set di dati vuoto. |
SFDC.datasets.cdc
|
Set di dati elaborato da CDC | - | Set di dati che funge da origine per le viste dei report e da target per i DAG dei record elaborati. Se utilizzi dati di test, crea un set di dati vuoto. |
SFDC.datasets.reporting
|
Set di dati dei report SFDC | "REPORTING_SFDC"
|
Nome del set di dati accessibile agli utenti finali per i report, in cui vengono eseguito il deployment di viste e tabelle rivolte agli utenti. |
SFDC.currencies
|
Filtra le valute | [ "USD" ]
|
Se non utilizzi dati di test, inserisci una
singola valuta (ad esempio, [ "USD" ]) o più valute
(ad esempio,[ "USD", "CAD" ]) in base alle esigenze della tua attività.
Questi valori vengono utilizzati per sostituire i segnaposto in SQL nei modelli di analisi
se disponibili.
|
Modello dati
Questa sezione descrive il modello dati di Salesforce (SFDC) utilizzando il diagramma entità-relazione (ERD).
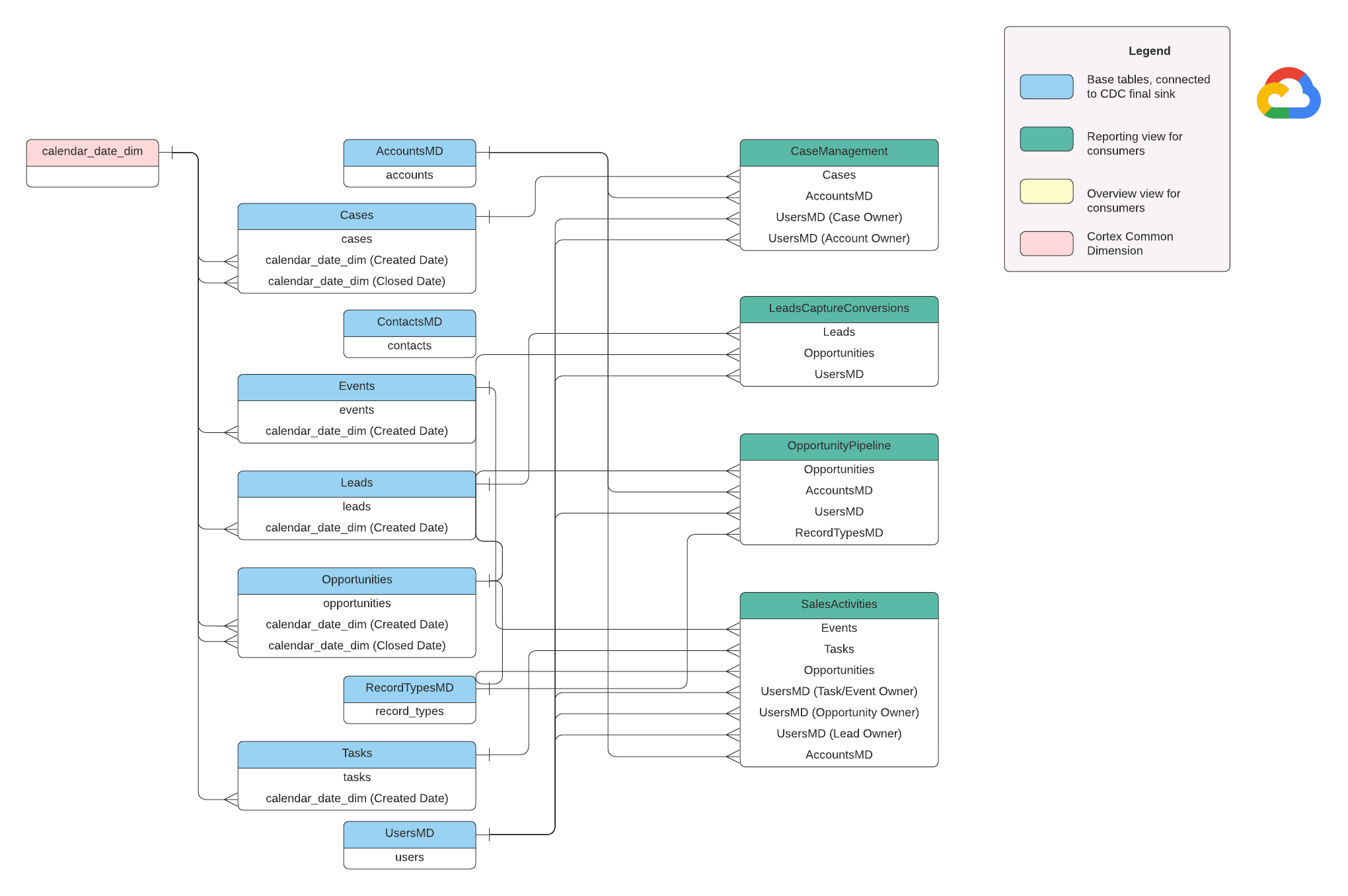
Viste di base
Questi sono gli oggetti blu nel diagramma ERD e sono viste delle tabelle CDC senza trasformazioni, ad eccezione di alcuni alias dei nomi delle colonne. Consulta gli script in
src/SFDC/src/reporting/ddls.
Viste report
Questi sono gli oggetti verdi nel diagramma ERD e contengono gli attributi dimensionali pertinenti utilizzati dalle tabelle dei report. Consulta gli script in
src/SFDC/src/reporting/ddls.
Requisiti dei dati di Salesforce
Questa sezione illustra le specifiche della struttura dei dati di Salesforce per l'utilizzo con Cortex Framework.
- Struttura della tabella:
- Denominazione:i nomi delle tabelle utilizzano
snake_case(parole in minuscolo separate da trattini bassi) e sono al plurale. Ad esempio,some_objects. - Tipi di dati:le colonne mantengono gli stessi tipi di dati rappresentati in Salesforce.
- Leggibilità:alcuni nomi dei campi potrebbero essere leggermente modificati per una maggiore chiarezza nel livello di reporting.
- Denominazione:i nomi delle tabelle utilizzano
- Tabelle vuote e deployment:le tabelle obbligatorie mancanti nel set di dati non elaborati vengono create automaticamente come tabelle vuote durante il processo di deployment. In questo modo, il passaggio di deployment di CDC viene eseguito senza problemi.
- Requisiti CDC:i campi
IdeSystemModstampsono fondamentali per gli script CDC per monitorare le modifiche ai dati. Possono avere questi nomi esatti o nomi diversi. Gli script di elaborazione non elaborati forniti recuperano automaticamente questi campi dalle API e aggiornano la tabella di replica di destinazione.Id: funge da identificatore univoco per ogni record.SystemModstamp: questo campo memorizza un timestamp che indica l'ultima volta che un record è stato modificato.
- Script di elaborazione non elaborati:gli script di elaborazione non elaborati forniti non richiedono un'elaborazione aggiuntiva (CDC). Questo comportamento è impostato per impostazione predefinita durante il deployment.
Tabelle di origine per la conversione di valuta
Salesforce consente di gestire le valute in due modi:
- Di base:è l'impostazione predefinita, in cui tutti i dati utilizzano una singola valuta.
- Avanzata: converte tra più valute in base ai tassi di cambio (richiede l'attivazione della gestione avanzata delle valute).
Se utilizzi la gestione avanzata delle valute, Salesforce utilizza due tabelle speciali:
- CurrencyTypes: questa tabella memorizza informazioni sulle diverse valute che utilizzi (ad esempio, USD, EUR e così via).
- DatedConversionRates: questa tabella contiene i tassi di cambio tra le valute nel tempo.
Cortex Framework prevede che queste tabelle siano presenti se utilizzi la gestione avanzata delle valute. Se non utilizzi la gestione avanzata delle valute, puoi
rimuovere le voci relative a queste tabelle da un file di configurazione
(src/SFDC/config/ingestion_settings.yaml).
Questo passaggio impedisce tentativi non necessari di estrarre dati da tabelle inesistenti.
Caricare i dati SFDC in BigQuery
Cortex Framework fornisce una soluzione di replica basata su script Python pianificati in Apache Airflow e sull'API Salesforce Bulk 2.0. Questi script Python possono essere adattati e pianificati nello strumento che preferisci. Per saperne di più, consulta Modulo di estrazione SFDC.
Cortex Framework offre anche tre metodi diversi per integrare i dati, a seconda della loro origine e di come vengono gestiti:
- Chiamate API:questa opzione è per i dati a cui è possibile accedere direttamente tramite un'API. Cortex Framework può chiamare l'API, recuperare i dati e archiviarli in un set di dati "non elaborati" in BigQuery. Se nel set di dati sono presenti record esistenti, Cortex Framework può aggiornarli con i nuovi dati.
- Viste di mapping della struttura:questo metodo è utile se hai già caricato i dati in BigQuery tramite un altro strumento, ma la struttura dei dati non corrisponde a quella richiesta da Cortex Framework. Cortex Framework utilizza le "viste" (come le tabelle virtuali) per tradurre la struttura dei dati esistente nel formato previsto dalle funzionalità di reporting di Cortex Framework.
Script di elaborazione CDC (Change Data Capture):questa opzione è progettata specificamente per i dati in continua evoluzione. Gli script CDC monitorano queste modifiche e aggiornano i dati in BigQuery di conseguenza. Questi script si basano su due campi speciali nei dati:
Id: identificatore univoco per ogni record.SystemModstamp: un timestamp che indica quando è stato modificato un record.
Se i dati non hanno questi nomi esatti, gli script possono essere modificati per riconoscerli con nomi diversi. Puoi anche aggiungere campi personalizzati allo schema dei dati durante questa procedura. Ad esempio, la tabella di origine con i dati dell'oggetto Account deve avere i campi
IdeSystemModstamporiginali. Se questi campi hanno nomi diversi, ilsrc/SFDC/src/table_schema/accounts.csvfile deve essere aggiornato con il nome del campoIdmappato aAccountIde il campo timestamp di modifica del sistema mappato aSystemModstamp. Per saperne di più, consulta la documentazione di SystemModStamp.
Se hai già caricato i dati tramite un altro strumento (e vengono aggiornati continuamente), Cortex può comunque utilizzarli. Gli script CDC includono file di mapping che possono tradurre la struttura dei dati esistente nel formato richiesto da Cortex Framework. Puoi anche aggiungere campi personalizzati ai dati durante questa procedura.
Configurare l'integrazione API e CDC
Per importare i dati di Salesforce in BigQuery, puoi utilizzare i seguenti metodi:
- Script Cortex per le chiamate API: fornisce script di replica per Salesforce o uno strumento di replica dei dati a tua scelta.La cosa fondamentale è che i dati importati devono avere lo stesso aspetto di quelli provenienti dalle API di Salesforce.
- Strumento di replica e aggiunta sempre : se utilizzi uno strumento per la replica, questo metodo è per uno strumento che può aggiungere nuovi record di dati (_appendalways_pattern) o aggiornare i record esistenti.
- Strumento di replica e aggiunta di nuovi record: se lo strumento non aggiorna i record e replica le modifiche come nuovi record in una tabella di destinazione (non elaborata), Cortex Data Foundation offre la possibilità di creare script di elaborazione CDC. Per saperne di più, consulta Processo CDC.

Per assicurarti che i dati corrispondano a quelli previsti da Cortex Framework, puoi modificare la configurazione del mapping per mappare lo strumento di replica o gli schemi esistenti. In questo modo vengono generate viste di mapping compatibili con la struttura prevista da Cortex Framework Data Foundation.
Utilizza il ingestion_settings.yaml file per configurare
la generazione di script per chiamare le API di Salesforce e replicare i
dati nel set di dati non elaborati (sezione salesforce_to_raw_tables) e la
generazione di script per elaborare le modifiche in arrivo nel set di dati non elaborati e
nel set di dati elaborato da CDC (sezione raw_to_cdc_tables).
Per impostazione predefinita, gli script forniti per la lettura dalle API aggiornano le modifiche nel set di dati non elaborati, quindi non sono necessari script di elaborazione CDC e vengono invece create viste di mapping per allineare lo schema di origine allo schema previsto.
La generazione di script di elaborazione CDC non viene eseguita se SFDC.createMappingViews=true
in config.json (comportamento predefinito). Se sono necessari script CDC, imposta SFDC.createMappingViews=false. Questo secondo passaggio consente anche di eseguire il mapping tra gli schemi di origine e gli schemi richiesti da Cortex Framework Data Foundation.
Il seguente esempio di file di configurazione setting.yaml illustra la generazione di viste di mapping quando uno strumento di replica aggiorna i dati direttamente nel set di dati replicato, come illustrato in option 3 (ovvero, non è necessario alcun CDC, solo il remapping di tabelle e nomi di campi). Poiché non è necessario alcun CDC, questa opzione viene eseguita a condizione che il parametro SFDC.createMappingViews nel file config.json rimanga true.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
In questo esempio, la rimozione della configurazione per una tabella di base o per tutte le tabelle dalle sezioni salta la generazione dei DAG di quella tabella di base o dell'intera sezione, come illustrato per salesforce_to_raw_tables. Per questo scenario, l'impostazione del parametro deployCDC : False ha lo stesso effetto, poiché non è necessario generare script di elaborazione CDC.
Mappatura dei dati
Devi mappare i campi dei dati in entrata al formato previsto da Cortex Data Foundation. Ad esempio, un campo denominato unicornId dal sistema di dati di origine deve essere rinominato e riconosciuto come AccountId (con un tipo di dati stringa) in Cortex Data Foundation:
- Campo di origine:
unicornId(nome utilizzato nel sistema di origine) - Campo Cortex:
AccountId(nome previsto da Cortex) - Tipo di dati:
String(tipo di dati previsto da Cortex)
Mappare i campi polimorfici
Cortex Framework Data Foundation supporta il mapping dei campi polimorfici, ovvero campi il cui nome può variare, ma la cui struttura rimane coerente. I nomi dei tipi di campi polimorfici (ad esempio, Who.Type) possono essere replicati aggiungendo un elemento [Field Name]_Type nei rispettivi file CSV di mapping:
src/SFDC/src/table_schema/tasks.csv. Ad esempio, se devi replicare il campo Who.Type dell'oggetto Task, aggiungi la riga Who_Type,Who_Type,STRING. In questo modo viene definito un nuovo campo denominato Who.Type che esegue il mapping a se stesso (mantiene lo stesso nome) e ha un tipo di dati stringa.
Modificare i modelli DAG
Potresti dover modificare i modelli DAG per CDC o per l'elaborazione dei dati non elaborati in base alle esigenze della tua istanza di Airflow o Managed Airflow. Per saperne di più, consulta Raccogliere le impostazioni di Managed Airflow.
Se non hai bisogno di CDC o della generazione di dati non elaborati dalle chiamate API, imposta deployCDC=false. In alternativa, puoi rimuovere i contenuti delle
sezioni in ingestion_settings.yaml. Se le strutture dei dati sono coerenti con quelle previste da Cortex Framework Data Foundation, puoi saltare la generazione delle viste di mapping impostando SFDC.createMappingViews=false.
Configurare il modulo di estrazione
Questa sezione illustra i passaggi per utilizzare il modulo di estrazione da Salesforce a BigQuery fornito da Data Foundation. I requisiti e il flusso possono variare a seconda del sistema e della configurazione esistente. In alternativa, puoi utilizzare altri strumenti disponibili.
Configurare le credenziali e l'app connessa
Accedi come amministratore alla tua istanza Salesforce per completare le seguenti operazioni:
- Crea o identifica un profilo in Salesforce che soddisfi i seguenti requisiti:
- L'opzione
Permission for Apex REST Services and API Enabled(Autorizzazione per i servizi REST Apex e API abilitata) è concessa in Autorizzazioni di sistema. - L'autorizzazione
View All(Visualizza tutto) è concessa per tutti gli oggetti che vuoi replicare. Ad esempio, Account e Cases. Verifica la presenza di limitazioni o problemi con l'amministratore della sicurezza. - Nessuna autorizzazione concessa per l'accesso all'interfaccia utente, come Salesforce Anywhere in Lightning Experience, Salesforce Anywhere su dispositivi mobili, Utente di Lightning Experience e Utente di Lightning Login. Verifica la presenza di limitazioni o problemi con l'amministratore della sicurezza.
- L'opzione
- Crea o utilizza un utente esistente in Salesforce. Devi conoscere
il nome utente, la password e il token di sicurezza dell'utente. Tieni presente quanto segue:
- Idealmente, dovrebbe trattarsi di un utente dedicato all'esecuzione di questa replica.
- L'utente deve essere assegnato al profilo che hai creato o identificato nel passaggio 1.
- Puoi visualizzare il nome utente e reimpostare la password qui.
- Puoi reimpostare il token di sicurezza se non lo hai e non viene utilizzato da un altro processo.
- Crea un'app connessa. È l'unico canale di comunicazione per stabilire la connessione
a Salesforce dal mondo esterno con l'aiuto del profilo, dell'API Salesforce, delle credenziali utente standard e del relativo token di sicurezza.
- Segui le istruzioni per abilitare le impostazioni OAuth per l'integrazione API.
- Assicurati che le opzioni
Require Secret for Web Server Flow(Richiedi secret per il flusso del server web) eRequire Secretfor Refresh Token Flow(Richiedi secret per il flusso del token di aggiornamento) siano attivate nella sezione API (Enabled OAuth Settings) (API (Impostazioni OAuth abilitate)). - Consulta la documentazione su come ottenere la chiave utente (che verrà utilizzata in seguito come ID client). Contatta l'amministratore della sicurezza per problemi o limitazioni.
- Assegna l'app connessa al profilo creato.
- Seleziona Impostazione in alto a destra nella schermata Home di Salesforce.
- Nella casella Ricerca rapida, inserisci
profile, quindi seleziona Profile (Profilo). Cerca il profilo creato nel passaggio 1. - Apri il profilo.
- Fai clic sul link Assigned Connected Apps (App connesse assegnate).
- Fai clic su Modifica.
- Aggiungi l'app connessa appena creata.
- Fai clic sul pulsante Salva.
Configurare Secret Manager
Configura Secret Manager per archiviare i dettagli della connessione. Il modulo da Salesforce a BigQuery si basa su Secret Manager per archiviare in modo sicuro le credenziali necessarie per connettersi a Salesforce e BigQuery. Questo approccio evita di esporre informazioni sensibili come le password direttamente nel codice o nei file di configurazione, migliorando la sicurezza.
Crea un secret con le seguenti specifiche. Per istruzioni più dettagliate, consulta Creare un secret.
- Nome secret:
airflow-connections-salesforce-conn Valore secret:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`Sostituisci quanto segue:
USERNAMEcon il tuo nome utente.PASSWORDcon la tua password.INSTANCE_NAMEcon il nome dell'istanza.CLIENT_IDcon il tuo ID client.SECRET_TOKENcon il tuo token secret.
Per saperne di più, consulta Come trovare il nome dell'istanza.
Librerie di Managed Airflow per la replica
Per eseguire gli script Python nei DAG forniti da Cortex Framework Data Foundation, devi installare alcune dipendenze. Per Airflow versione 1.10, segui la documentazione Installare le dipendenze Python per Managed Service for Apache Airflow 1 per installare i seguenti pacchetti, in ordine:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Per Airflow versione 2.x, consulta la documentazione Installare le dipendenze Python per Managed Service for Apache Airflow 2 per installare apache-airflow-providers-salesforce~=5.2.0.
Utilizza il seguente comando per installare ogni pacchetto richiesto:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
Sostituisci quanto segue:
ENVIRONMENT_NAMEcon il nome dell'ambiente assegnato.LOCATIONcon la località.PACKAGE_NAMEcon il nome del pacchetto scelto.EXTRAS_AND_VERSIONcon le specifiche degli extra e della versione.
Il seguente comando è un esempio di installazione di un pacchetto richiesto:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Abilitare Secret Manager come backend
Abilita Google Secret Manager come backend di sicurezza. Questo passaggio ti indica di attivare Secret Manager come posizione di archiviazione principale per le informazioni sensibili come password e chiavi API utilizzate dall'ambiente Managed Service for Apache Airflow. In questo modo, la sicurezza viene migliorata centralizzando e gestendo le credenziali in un servizio dedicato. Per saperne di più, consulta Secret Manager.
Consentire al account di servizio di Composer di accedere ai secret
Questo passaggio garantisce che il account di servizio associato a Managed Service for Apache Airflow disponga delle autorizzazioni necessarie per accedere ai secret archiviati in Secret Manager.
Per impostazione predefinita, Managed Service for Apache Airflow utilizza il account di servizio di Compute Engine.
L'autorizzazione richiesta è Secret Manager Secret Accessor.
Questa autorizzazione consente al account di servizio di recuperare e utilizzare i secret archiviati
in Secret Manager.Per una guida completa alla configurazione dei controlli di accesso
in Secret Manager, consulta la
documentazione sul controllo dell'accesso.
Connessione BigQuery in Airflow
Assicurati di creare la connessione sfdc_cdc_bq in base a
Raccogliere le impostazioni di Managed Airflow. È probabile che questa connessione venga utilizzata dal modulo da Salesforce a BigQuery per stabilire la comunicazione con BigQuery.
Passaggi successivi
- Per saperne di più su altre origini dati e altri workload, consulta Origini dati e workload.
- Per saperne di più sui passaggi per il deployment negli ambienti di produzione, consulta Prerequisiti per il deployment di Cortex Framework Data Foundation.