
Integration mit Salesforce (SFDC)
Auf dieser Seite werden die Integrationsschritte für die operative Arbeitslast von Salesforce (SFDC) in der Cortex Framework Data Foundation beschrieben. Cortex Framework integriert Daten aus Salesforce über Dataflow-Pipelines in BigQuery. Managed Service for Apache Airflow plant und überwacht diese Dataflow-Pipelines, um Erkenntnisse aus Ihren Daten zu gewinnen.
Konfigurationsdatei
In der Datei config.json
im
Cortex Framework Data Foundation-Repository
werden die Einstellungen konfiguriert, die für die Übertragung von Daten aus
einer beliebigen Datenquelle, einschließlich Salesforce, erforderlich sind. Diese Datei enthält die folgenden Parameter für operative Salesforce-Arbeitslasten:
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
}
In der folgenden Tabelle wird der Wert für jeden operativen SFDC-Parameter beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
SFDC.deployCDC
|
CDC bereitstellen | true
|
CDC-Verarbeitungsskripts generieren, die als DAGs in Managed Service for Apache Airflow ausgeführt werden. Informationen zu verschiedenen Erfassungsoptionen für Salesforce Sales Cloud |
SFDC.createMappingViews
|
Zuordnungsansichten erstellen | true
|
Die bereitgestellten DAGs zum Abrufen neuer Datensätze
aus den Salesforce APIs aktualisieren Datensätze bei der Landung. Wenn dieser Wert auf „true“ gesetzt ist
werden Ansichten im verarbeiteten CDC-Dataset generiert, um Tabellen mit
der „aktuellsten Version der Wahrheit“ aus dem Rohdaten-Dataset verfügbar zu machen. Wenn der Wert „false“ ist und
SFDC.deployCDC auf true gesetzt ist, werden DAGs mit CDC-Verarbeitung (Change Data Capture) basierend auf SystemModstamp generiert. Weitere Informationen
zu CDC-Verarbeitung für Salesforce.
|
SFDC.createPlaceholders
|
Platzhalter erstellen | true
|
Leere Platzhaltertabellen erstellen, falls sie nicht durch den Erfassungsprozess generiert werden, damit die nachgelagerte Berichtsbereitstellung ohne Fehler ausgeführt werden kann. |
SFDC.datasets.raw
|
Dataset für Rohdaten | - | Wird vom CDC-Prozess verwendet. Hier werden die Daten aus Salesforce vom Replikationstool abgelegt. Wenn Sie Testdaten verwenden, erstellen Sie ein leeres Dataset. |
SFDC.datasets.cdc
|
Verarbeitetes CDC-Dataset | - | Dataset, das als Quelle für die Berichtsansichten und als Ziel für die DAGs für verarbeitete Datensätze dient. Wenn Sie Testdaten verwenden, erstellen Sie ein leeres Dataset. |
SFDC.datasets.reporting
|
Berichts-Dataset SFDC | "REPORTING_SFDC"
|
Name des Datasets, auf das Endnutzer für die Berichterstellung zugreifen können . Hier werden Ansichten und nutzerorientierte Tabellen bereitgestellt. |
SFDC.currencies
|
Währungen filtern | [ "USD" ]
|
Wenn Sie keine Testdaten verwenden, geben Sie eine
einzelne Währung (z. B. [ "USD" ]) oder mehrere Währungen
(z. B. [ "USD", "CAD" ]) ein, die für Ihr Unternehmen relevant sind.
Diese Werte werden verwendet, um Platzhalter in SQL in Analytikmodellen
sofern verfügbar zu ersetzen.
|
Datenmodell
In diesem Abschnitt wird das Salesforce-Datenmodell (SFDC) anhand des Entity-Relationship-Diagramms (ERD) beschrieben.
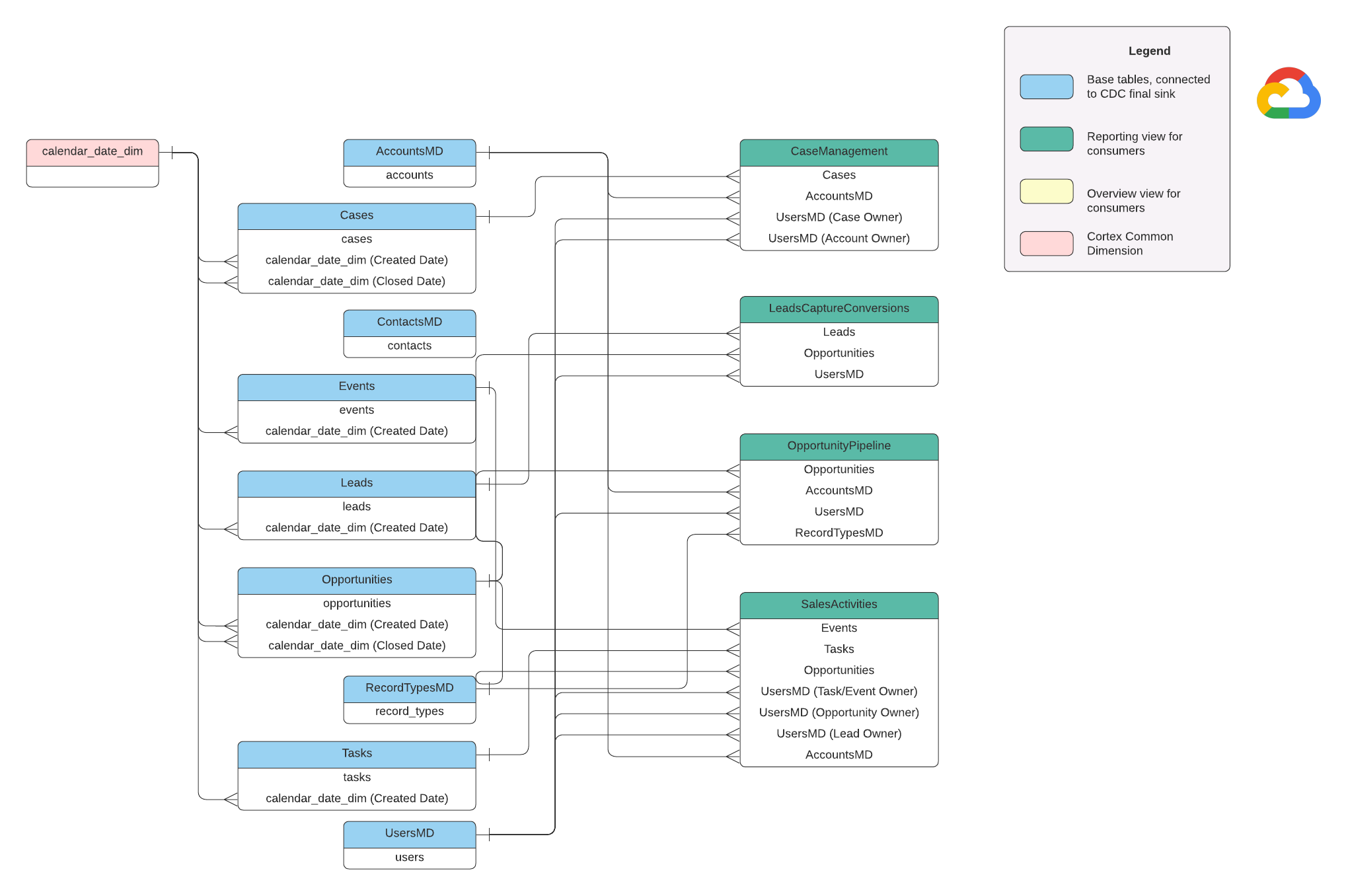
Basisansichten
Das sind die blauen Objekte im ERD. Sie sind Ansichten von CDC-Tabellen ohne Transformationen außer einigen Aliasen für Spaltennamen. Siehe Skripts in
src/SFDC/src/reporting/ddls.
Berichtsdatenansichten
Das sind die grünen Objekte im ERD. Sie enthalten die relevanten Dimensionsattribute, die von den Berichtstabellen verwendet werden. Siehe Skripts in
src/SFDC/src/reporting/ddls.
Salesforce-Datenanforderungen
In diesem Abschnitt werden die Besonderheiten der Struktur Ihrer Salesforce-Daten für die Verwendung mit Cortex Framework beschrieben.
- Tabellenstruktur:
- Benennung:Tabellennamen verwenden
snake_case(Kleinbuchstaben, die durch Unterstriche getrennt sind) und sind im Plural. Beispiel:some_objects. - Datentypen:Die Spalten behalten dieselben Datentypen wie in Salesforce.
- Lesbarkeit:Einige Feldnamen werden möglicherweise leicht angepasst, um die Übersichtlichkeit in der Berichtsebene zu verbessern.
- Benennung:Tabellennamen verwenden
- Leere Tabellen und Bereitstellung:Alle erforderlichen Tabellen, die im Rohdaten-Dataset fehlen, werden während der Bereitstellung automatisch als leere Tabellen erstellt. So wird eine reibungslose Ausführung des CDC-Bereitstellungsschritts gewährleistet.
- CDC-Anforderungen: Die
IdundSystemModstampFelder sind entscheidend dafür, dass CDC-Skripts Änderungen an Ihren Daten nachverfolgen können. Sie können genau diese oder andere Namen haben. Die bereitgestellten Skripts zur Rohdatenverarbeitung rufen diese Felder automatisch aus den APIs ab und aktualisieren die Zielreplikationstabelle.Id: Dient als eindeutige Kennung für jeden Datensatz.SystemModstamp: In diesem Feld wird ein Zeitstempel gespeichert, der angibt, wann ein Datensatz zuletzt geändert wurde.
- Skripts zur Rohdatenverarbeitung:Für die bereitgestellten Skripts zur Rohdatenverarbeitung ist keine zusätzliche (CDC-)Verarbeitung erforderlich. Dieses Verhalten wird standardmäßig während der Bereitstellung festgelegt.
Quelltabelle für die Währungsumrechnung
In Salesforce können Sie Währungen auf zwei Arten verwalten:
- Einfach:Dies ist die Standardeinstellung, bei der alle Daten eine einzige Währung verwenden.
- Erweitert: Hier werden mehrere Währungen basierend auf Wechsel kursen umgerechnet (erfordert die Aktivierung der erweiterten Währungsverwaltung).
Wenn Sie die erweiterte Währungsverwaltung verwenden, verwendet Salesforce zwei spezielle Tabellen:
- CurrencyTypes: Diese Tabelle enthält Informationen zu den verschiedenen Währungen, die Sie verwenden (z. B. USD, EUR usw.).
- DatedConversionRates: Diese Tabelle enthält die Wechselkurse zwischen Währungen im Zeitverlauf.
Cortex Framework erwartet, dass diese Tabellen vorhanden sind, wenn Sie die erweiterte Währungsverwaltung verwenden. Wenn Sie die erweiterte Währungsverwaltung nicht verwenden, können Sie
Einträge zu diesen Tabellen aus einer Konfigurationsdatei
(src/SFDC/config/ingestion_settings.yaml) entfernen.
So werden unnötige Versuche verhindert, Daten aus nicht vorhandenen
Tabellen zu extrahieren.
SFDC-Daten in BigQuery laden
Cortex Framework bietet eine Replikationslösung, die auf Python-Skripts basiert, die in Apache Airflow geplant sind, und auf der Salesforce Bulk API 2.0. Diese Python-Skripts können angepasst und in Ihrem bevorzugten Tool geplant werden. Weitere Informationen finden Sie unter SFDC-Extraktionsmodul.
Cortex Framework bietet außerdem drei verschiedene Methoden zum Einbinden Ihrer Daten, je nachdem, woher die Daten stammen und wie sie verwaltet werden:
- API-Aufrufe:Diese Option ist für Daten vorgesehen, auf die direkt über eine API zugegriffen werden kann. Cortex Framework kann die API aufrufen, die Daten abrufen und in einem „Rohdaten“-Dataset in BigQuery speichern. Wenn im Dataset bereits Datensätze vorhanden sind, kann Cortex Framework sie mit den neuen Daten aktualisieren.
- Ansichten für die Strukturzuordnung:Diese Methode ist nützlich, wenn Sie Ihre Daten bereits mit einem anderen Tool in BigQuery geladen haben, die Datenstruktur jedoch nicht mit den Anforderungen von Cortex Framework übereinstimmt. Cortex Framework verwendet „Ansichten“ (ähnlich virtuellen Tabellen), um die vorhandene Datenstruktur in das Format zu übersetzen, das von den Berichtsfunktionen von Cortex Framework erwartet wird.
CDC-Verarbeitungsskripts (Change Data Capture):Diese Option wurde speziell für Daten entwickelt, die sich ständig ändern. CDC-Skripts verfolgen diese Änderungen und aktualisieren die Daten entsprechend in BigQuery. Diese Skripts basieren auf zwei speziellen Feldern in Ihren Daten:
Id: eindeutige Kennung für jeden Datensatz.SystemModstamp: Zeitstempel, der angibt, wann ein Datensatz geändert wurde.
Wenn Ihre Daten nicht genau diese Namen haben, können die Skripts so angepasst werden, dass sie sie mit anderen Namen erkennen. Sie können Ihrem Datenschema während dieses Prozesses auch benutzerdefinierte Felder hinzufügen. Die Quelltabelle mit Daten des Account-Objekts sollte beispielsweise die ursprünglichen Felder
IdundSystemModstampenthalten. Wenn diese Felder andere Namen haben, muss die Dateisrc/SFDC/src/table_schema/accounts.csvaktualisiert werden. Der Name des FeldsIdmussAccountIdzugeordnet werden und das Feld für den Zeitstempel der Systemänderung mussSystemModstampzugeordnet werden. Weitere Informationen finden Sie in der Dokumentation zu SystemModStamp.
Wenn Sie bereits Daten mit einem anderen Tool geladen haben (und diese ständig aktualisiert werden), können sie trotzdem von Cortex verwendet werden. Die CDC-Skripts enthalten Zuordnungsdateien, mit denen Sie Ihre vorhandene Datenstruktur in das Format übersetzen können, das für Cortex Framework erforderlich ist. Sie können Ihren Daten während dieses Prozesses sogar benutzerdefinierte Felder hinzufügen.
API-Integration und CDC konfigurieren
So können Sie Ihre Salesforce-Daten in BigQuery einbinden:
- Cortex-Skripts für API-Aufrufe: Bietet Replikationsskripts für Salesforce oder ein Tool zur Datenreplikation Ihrer Wahl.Wichtig ist, dass die Daten, die Sie einbinden, so aussehen, als würden sie aus den Salesforce APIs stammen.
- Replikationstool und immer anhängen : Wenn Sie ein Tool für die Replikation verwenden, ist diese Methode für ein Tool geeignet, mit dem entweder neue Datensätze hinzugefügt (_appendalways_pattern) oder vorhandene Datensätze aktualisiert werden können.
- Replikationstool und neue Datensätze hinzufügen: Wenn das Tool die Datensätze nicht aktualisiert und alle Änderungen als neue Datensätze in eine Zieltabelle (Rohdaten) repliziert, bietet Cortex Data Foundation die Möglichkeit, CDC-Verarbeitungsskripts zu erstellen. Weitere Informationen finden Sie unter CDC-Prozess.

Damit Ihre Daten den Erwartungen von Cortex Framework entsprechen, können Sie die Zuordnungskonfiguration anpassen, um Ihr Replikationstool oder vorhandene Schemas zuzuordnen. So werden Zuordnungsansichten generiert, die mit der von der Cortex Framework Data Foundation erwarteten Struktur kompatibel sind.
Verwenden Sie die ingestion_settings.yaml Datei, um
die Generierung von Skripts zum Aufrufen der Salesforce APIs und zum Replizieren der
Daten in das Rohdaten-Dataset zu konfigurieren (Abschnitt salesforce_to_raw_tables) und
Skripts zu generieren, um Änderungen zu verarbeiten, die in das Rohdaten-Dataset und
in das verarbeitete CDC-Dataset eingehen (Abschnitt raw_to_cdc_tables).
Standardmäßig werden mit den bereitgestellten Skripts zum Lesen aus APIs Änderungen in das Rohdaten-Dataset aktualisiert. Daher sind keine CDC-Verarbeitungsskripts erforderlich. Stattdessen werden Zuordnungsansichten erstellt, um das Quellschema an das erwartete Schema anzupassen.
Die Generierung von CDC-Verarbeitungsskripts wird nicht ausgeführt, wenn SFDC.createMappingViews=true
in der config.json festgelegt ist (Standardverhalten). Wenn CDC-Skripts erforderlich sind, setzen Sie SFDC.createMappingViews=false. Dieser zweite Schritt ermöglicht auch die Zuordnung zwischen den Quellschemas und den erforderlichen Schemas, wie von der Cortex Framework Data Foundation gefordert.
Das folgende Beispiel einer Konfigurationsdatei setting.yaml veranschaulicht die Generierung von Zuordnungsansichten, wenn ein Replikationstool die Daten direkt in das replizierte Dataset aktualisiert, wie in option 3 dargestellt (d.h., es ist keine CDC erforderlich, sondern nur die Neuzuordnung von Tabellen- und Feldnamen). Da keine CDC erforderlich ist, wird diese Option ausgeführt, solange der Parameter SFDC.createMappingViews in der Datei „config.json“ auf true gesetzt ist.
salesforce_to_raw_tables:
- base_table: accounts
raw_table: Accounts
api_name: Account
load_frequency: "@daily"
- base_table: cases
raw_table: cases2
api_name: Case
load_frequency: "@daily"
Wenn Sie in diesem Beispiel die Konfiguration für eine Basistabelle oder alle Basistabellen aus den Abschnitten entfernen, wird die Generierung von DAGs für diese Basistabelle oder den gesamten Abschnitt übersprungen, wie für salesforce_to_raw_tables dargestellt. In diesem Szenario hat das Festlegen des Parameters deployCDC : False denselben Effekt, da keine CDC-Verarbeitungsskripts generiert werden müssen.
Datenabgleich
Sie müssen eingehende Datenfelder dem Format zuordnen, das von der Cortex Data Foundation erwartet wird. Ein Feld mit dem Namen unicornId aus Ihrem Quelldatensystem sollte beispielsweise in AccountId umbenannt und als solches erkannt werden (mit dem Datentyp „String“) innerhalb der Cortex Data Foundation:
- Quellfeld:
unicornId(Name im Quellsystem) - Cortex-Feld:
AccountId(von Cortex erwarteter Name) - Datentyp:
String(von Cortex erwarteter Datentyp)
Zuordnung polymorpher Felder
Die Cortex Framework Data Foundation unterstützt die Zuordnung polymorpher Felder. Das sind Felder, deren Name variieren kann, deren Struktur jedoch konsistent bleibt. Polymorphe Feld
typnamen (z. B. Who.Type) können repliziert werden, indem Sie
ein Element [Field Name]_Type in den entsprechenden CSV-Zuordnungsdateien hinzufügen:
src/SFDC/src/table_schema/tasks.csv. Wenn Sie beispielsweise das Feld Who.Type des Objekts Task replizieren möchten, fügen Sie die Zeile Who_Type,Who_Type,STRING hinzu. Dadurch wird ein neues Feld mit dem Namen Who.Type definiert, das sich selbst zuordnet (behält denselben Namen) und den Datentyp „String“ hat.
DAG-Vorlagen ändern
Möglicherweise müssen Sie die DAG-Vorlagen für CDC oder für die Rohdatenverarbeitung an Ihre Instanz von Airflow oder Managed Airflow anpassen. Weitere Informationen finden Sie unter Managed Airflow-Einstellungen erfassen.
Wenn Sie keine CDC oder Rohdatengenerierung aus API-Aufrufen benötigen, setzen Sie deployCDC=false. Alternativ können Sie den Inhalt der
Abschnitte in ingestion_settings.yaml entfernen. Wenn die Datenstrukturen mit den von der Cortex Framework Data Foundation erwarteten Strukturen übereinstimmen, können Sie die Generierung von Zuordnungsansichten überspringen und SFDC.createMappingViews=false festlegen.
Extraktionsmodul konfigurieren
In diesem Abschnitt werden die Schritte zur Verwendung des von der Data Foundation bereitgestellten Salesforce-zu-BigQuery-Extraktionsmoduls beschrieben. Ihre Anforderungen und Ihr Ablauf können je nach System und vorhandener Konfiguration variieren. Alternativ können Sie auch andere verfügbare Tools verwenden.
Anmeldedaten und verbundene App einrichten
Melden Sie sich als Administrator in Ihrer Salesforce-Instanz an, um die folgenden Schritte auszuführen:
- Erstellen oder identifizieren Sie ein Profil in Salesforce, das die folgenden Anforderungen erfüllt:
Permission for Apex REST Services and API Enabledist gewährt unter Systemberechtigungen.- Für alle Objekte, die Sie replizieren möchten, ist die Berechtigung
View Allgewährt. Beispiel: „Account“ und „Cases“. Erkundigen Sie sich bei Ihrem Sicherheitsadministrator nach Einschränkungen oder Problemen. - Es wurden keine Berechtigungen für Anmeldung über die Benutzeroberfläche gewährt, z. B. für Salesforce Anywhere in Lightning Experience, Salesforce Anywhere on Mobile, Lightning Experience User und Lightning Login User. Erkundigen Sie sich bei Ihrem Sicherheitsadministrator nach Einschränkungen oder Problemen.
- Erstellen oder verwenden Sie einen vorhandenen Nutzer in Salesforce. Sie benötigen den Nutzernamen, das Passwort und das Sicherheitstoken des Nutzers. Beachten Sie Folgendes:
- Idealerweise sollte dies ein Nutzer sein, der speziell für die Ausführung dieser Replikation vorgesehen ist.
- Der Nutzer sollte dem Profil zugewiesen werden, das Sie in Schritt 1 erstellt oder identifiziert haben.
- Hier können Sie den Nutzernamen sehen und das Passwort zurücksetzen.
- Sie können das Sicherheitstoken zurücksetzen, wenn Sie es nicht haben und es nicht von einem anderen Prozess verwendet wird.
- Erstellen Sie eine verbundene App. Sie ist der einzige Kommunikationskanal, um mit dem Profil, der Salesforce
API, den Standardanmeldedaten des Nutzers und dem zugehörigen Sicherheitstoken eine Verbindung
zu Salesforce von außerhalb herzustellen.
- Folgen Sie der Anleitung, um die OAuth-Einstellungen für die API-Integration zu aktivieren.
- Achten Sie darauf, dass im Bereich API (OAuth-Einstellungen aktiviert) die Optionen
Require Secret for Web Server FlowundRequire Secretfor Refresh Token Flowaktiviert sind. - In der Dokumentation erfahren Sie, wie Sie Ihren Consumer-Key abrufen, der später als Client-ID verwendet wird. Erkundigen Sie sich bei Ihrem Sicherheitsadministrator nach Problemen oder Einschränkungen.
- Weisen Sie die erstellte verbundene App dem Profil zu.
- Wählen Sie rechts oben auf dem Salesforce-Startbildschirm Setup aus.
- Geben Sie im Feld Schnellsuche
profileein und wählen Sie Profile aus. Suchen Sie nach dem in Schritt 1 erstellten Profil. - Rufen Sie das Profil auf.
- Klicken Sie auf den Link Zugeordnete verbundene Apps.
- Klicken Sie auf Bearbeiten.
- Fügen Sie die neu erstellte verbundene App hinzu.
- Klicken Sie auf Speichern.
Secret Manager einrichten
Konfigurieren Sie Secret Manager, um Verbindungsdetails zu speichern. Das Modul „Salesforce zu BigQuery“ verwendet Secret Manager, um die Anmeldedaten, die für die Verbindung zu Salesforce und BigQuery erforderlich sind, sicher zu speichern. So werden vertrauliche Informationen wie Passwörter nicht direkt in Ihrem Code oder in Konfigurationsdateien preisgegeben, was die Sicherheit erhöht.
Erstellen Sie ein Secret mit den folgenden Spezifikationen. Eine detailliertere Anleitung finden Sie unter Secret erstellen.
- Secret-Name:
airflow-connections-salesforce-conn Secret-Wert:
http://USERNAME:PASSWORD@https%3A%2F%2FINSTANCE_NAME.lightning.force.com?client_id=CLIENT_ID&security_token=SECRET_TOKEN`Ersetzen Sie Folgendes:
USERNAMEdurch Ihren Nutzernamen.PASSWORDdurch Ihr Passwort.INSTANCE_NAMEdurch den Instanznamen.CLIENT_IDdurch Ihre Client-ID.SECRET_TOKENdurch Ihr Secret-Token.
Weitere Informationen finden Sie unter Instanznamen finden.
Managed Airflow-Bibliotheken für die Replikation
Um die Python-Skripts in den DAGs auszuführen, die von der Cortex Framework Data Foundation bereitgestellt werden, müssen Sie einige Abhängigkeiten installieren. Für Airflow Version 1.10 folgen Sie der Dokumentation Python-Abhängigkeiten für Managed Service for Apache Airflow 1 installieren um die folgenden Pakete in dieser Reihenfolge zu installieren:
tableauserverclient==0.17
apache-airflow-backport-providers-salesforce==2021.3.3
Für Airflow Version 2.x finden Sie in der Dokumentation Python-Abhängigkeiten für Managed Service for Apache Airflow 2 installieren die Anleitung zum Installieren von apache-airflow-providers-salesforce~=5.2.0.
Verwenden Sie den folgenden Befehl, um jedes erforderliche Paket zu installieren:
gcloud composer environments update ENVIRONMENT_NAME \
--location LOCATION \
--update-pypi-package PACKAGE_NAME EXTRAS_AND_VERSION
Ersetzen Sie Folgendes:
ENVIRONMENT_NAMEdurch den zugewiesenen Umgebungsnamen.LOCATIONdurch den Standort.PACKAGE_NAMEdurch den ausgewählten Paketnamen.EXTRAS_AND_VERSIONdurch die Spezifikationen der Extras und der Version.
Der folgende Befehl ist ein Beispiel für die Installation eines erforderlichen Pakets:
gcloud composer environments update my-composer-instance \
--location us-central1 \
--update-pypi-package apache-airflow-backport-providers-salesforce>=2021.3.3
Secret Manager als Backend aktivieren
Aktivieren Sie Google Secret Manager als Sicherheits-Backend. In diesem Schritt wird beschrieben, wie Sie Secret Manager als primären Speicherort für vertrauliche Informationen wie Passwörter und API-Schlüssel aktivieren, die von Ihrer Managed Service for Apache Airflow-Umgebung verwendet werden. Dies erhöht die Sicherheit, da Anmeldedaten zentralisiert und in einem dedizierten Dienst verwaltet werden. Weitere Informationen finden Sie unter Secret Manager.
Composer-Dienstkonto Zugriff auf Secrets gewähren
In diesem Schritt wird sichergestellt, dass das Dienstkonto, das mit Managed Service for Apache Airflow verknüpft ist, die erforderlichen Berechtigungen hat, um auf in Secret Manager gespeicherte Secrets zuzugreifen.
Standardmäßig verwendet Managed Service for Apache Airflow das Compute Engine-Dienstkonto.
Die erforderliche Berechtigung ist Secret Manager Secret Accessor.
Mit dieser Berechtigung kann das Dienstkonto in Secret Manager gespeicherte Secrets abrufen und verwenden.Eine umfassende Anleitung zum Konfigurieren der Zugriffssteuerung
in Secret Manager finden Sie in der
Dokumentation zur Zugriffssteuerung.
BigQuery-Verbindung in Airflow
Erstellen Sie die Verbindung sfdc_cdc_bq gemäß
den Anweisungen unter Managed Airflow-Einstellungen erfassen. Diese Verbindung wird wahrscheinlich vom Modul „Salesforce zu BigQuery“ verwendet, um die Kommunikation mit BigQuery herzustellen.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen, siehe Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.