
Integrazione con Meta
Questa pagina descrive le configurazioni richieste per importare i dati da Meta (Facebook e Instagram Ads) come origine dati del workload di marketing di Cortex Framework Data Foundation.
Meta è una società tecnologica proprietaria di diverse piattaforme online famose. Cortex Framework integra i dati degli annunci di Instagram e Facebook per analizzarli, combinarli con altre origini dati e utilizzare l'AI per ottenere approfondimenti più approfonditi e ottimizzare la strategia di marketing.
Il seguente diagramma descrive come i dati di marketing di Meta sono disponibili tramite il workload di marketing di Cortex Framework Data Foundation:
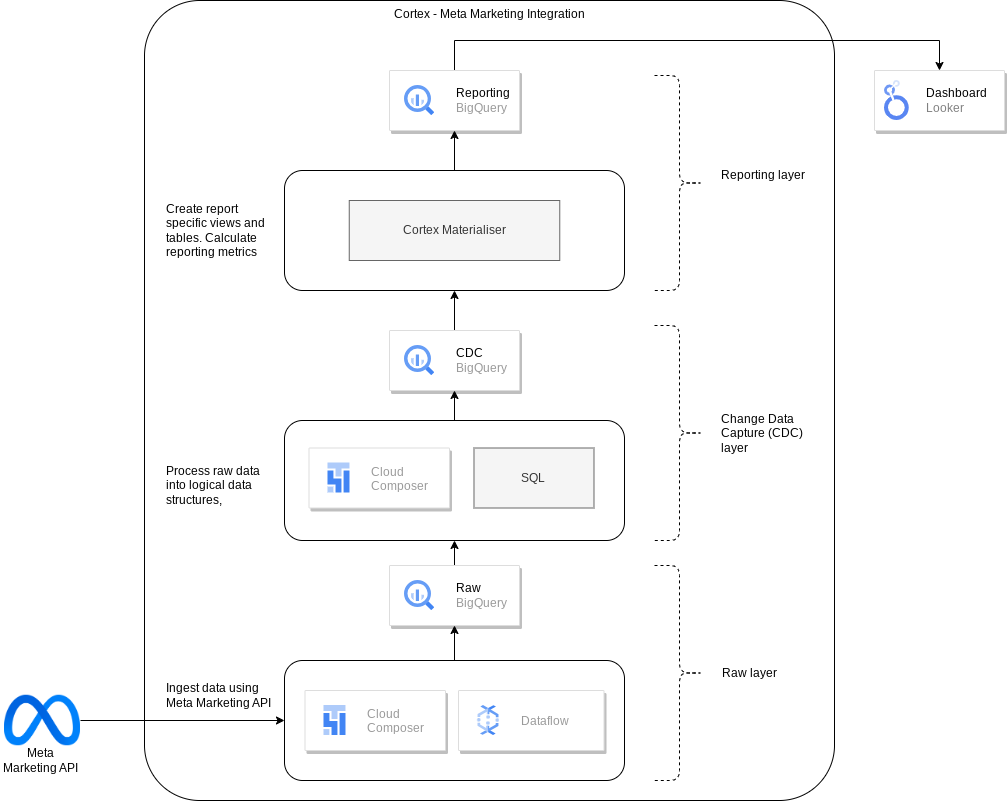
File di configurazione
Il file config.json configura le impostazioni necessarie per connettersi alle origini dati per il trasferimento
dei dati da vari workload. Questo file contiene i seguenti parametri per Meta:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
La seguente tabella descrive il valore di ogni parametro di marketing:
| Parametro | Significato | Valore predefinito | Descrizione |
marketing.deployMeta
|
Esegui il deployment di Meta | true
|
Esegui il deployment per l'origine dati di Meta. |
marketing.Meta.deployCDC
|
Esegui il deployment degli script CDC per Meta | true
|
Genera script di elaborazione CDC di Meta da eseguire come DAG in Cloud Composer. |
marketing.Meta.datasets.cdc
|
Set di dati CDC per Meta | Set di dati CDC per Meta. | |
marketing.Meta.datasets.raw
|
Set di dati non elaborati per Meta | Set di dati non elaborati per Meta. | |
marketing.Meta.datasets.reporting
|
Set di dati di reporting per Meta | "REPORTING_Meta"
|
Set di dati di reporting per Meta. |
Modello dati
Questa sezione descrive il modello dati di Meta utilizzando il diagramma entità relazione (ERD).
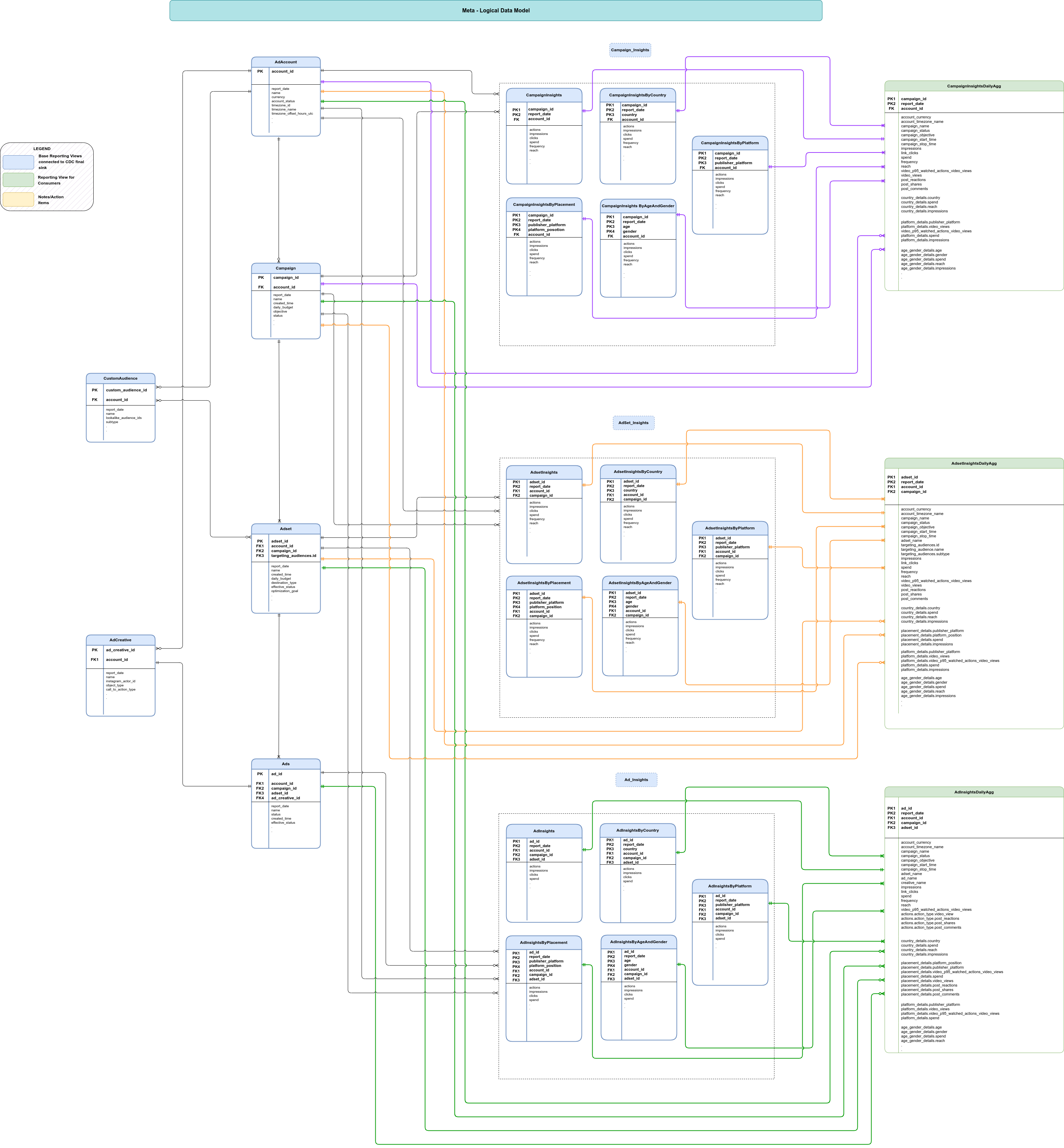
Visualizzazioni di base
Questi sono gli oggetti blu nell'ERD e sono visualizzazioni delle tabelle CDC con
trasformazioni minime per decomprimere strutture di dati complesse. Consulta gli script in
src/marketing/src/Meta/src/reporting/ddls.
Viste report
Questi sono gli oggetti verdi nell'ERD e sono viste report che contengono
metriche aggregate. Consulta gli script in
src/marketing/src/Meta/src/reporting/ddls.
Connessione API
I modelli di importazione in Cortex Framework per Meta utilizzano l' API Meta Marketing per recuperare attributi e metriche di reporting. I modelli attuali utilizzano la versione v25.0.
Meta impone un limite di frequenza dinamico quando esegui query sull'API Marketing. Quando viene raggiunto il limite di frequenza, i DAG di importazione da origine a non elaborati potrebbero non essere completati correttamente. In questi casi, puoi visualizzare i messaggi di errore pertinenti nel log e la successiva esecuzione dei DAG caricherà retroattivamente tutti i dati mancanti.
L'API Meta Marketing ha due livelli di accesso: Base e Standard. Il livello Standard offre un limite molto più elevato ed è consigliato se prevedi di utilizzare l' importazione da origine a non elaborati in modo intensivo. Per ulteriori dettagli su questi limiti e su come ottenere un livello di accesso più elevato, consulta la documentazione di Meta.
Se hai accesso al livello Standard, puoi ridurre il valore di
next_request_delay_sec impostazione in src/Meta/src/raw/pipelines/config.ini
per tempi di caricamento più rapidi.
Accesso API e token di accesso
I seguenti passaggi sono necessari in Meta Business Manager e nella Developer Console per importare correttamente i dati da Meta in Cortex Framework.
- Identifica un'app da utilizzare. Puoi creare una nuova app
collegata all'account aziendale. Assicurati che l'app sia di tipo
Business. - Configura le autorizzazioni app. Prima di poter creare token, devi essere assegnato all'app come un amministratore. Consulta la documentazione sui ruoli dell'app. Assicurati di assegnare le risorse (account) pertinenti alla tua app.
Crea un token di accesso. I token di accesso sono necessari per accedere all'API Meta Marketing e sono sempre associati a un'app e a un utente. Puoi creare il token con un utente di sistema o con le tue credenziali di accesso.
- Crea un utente di sistema amministratore.
- Genera un token. Assicurati di annotare il token non appena viene generato, perché non sarà più recuperabile una volta che esci dalla pagina.
- Concedi le autorizzazioni
ads_readebusiness_managemental token, per accedere agli oggetti supportati.
Segui la documentazione di Cloud Composer per attivare Secret Manager in Cloud Composer. Poi, crea un secret denominato
cortex_meta_access_tokene memorizza il token generato nel passaggio precedente come contenuti.
Aggiornamento e ritardo dei dati
In generale, l'aggiornamento dei dati per le origini dati di Cortex Framework è limitato da ciò che consente la connessione upstream, nonché dalla frequenza di esecuzione del DAG. Modifica la frequenza di esecuzione del DAG in modo che sia in linea con la frequenza upstream, i vincoli delle risorse e le esigenze aziendali.
Con l'API Meta Marketing, la maggior parte dei dati (escluse le conversioni) è disponibile quasi in tempo reale, anche se potrebbe essere modificata fino a 28 giorni dopo l'evento.
Autorizzazioni delle connessioni di Cloud Composer
Crea le seguenti connessioni in Cloud Composer. Per ulteriori dettagli, consulta la documentazione Gestire le connessioni Airflow.
| Nome connessione | Purpose |
meta_raw_dataflow
|
Per l'API Meta Marketing > Set di dati non elaborati BigQuery |
meta_cdc_bq
|
Per il trasferimento del set di dati non elaborati > set di dati CDC |
meta_reporting_bq
|
Per il trasferimento del set di dati CDC > set di dati di reporting |
Autorizzazioni del account di servizio di Cloud Composer
Concedi le autorizzazioni Dataflow al account di servizio utilizzato in
Cloud Composer (come configurato nella meta_raw_dataflow connessione).
Consulta le istruzioni nella documentazione di Dataflow. Il account di servizio richiede anche l'autorizzazione
Secret Manager Secret Accessor Per maggiori dettagli, consulta la documentazione sul controllo dell'accesso
.
Parametri di richiesta
La directory src/Meta/config/request_parameters contiene un file di specifiche delle richieste API per ogni entità estratta dall'API Meta Marketing. Ogni file di richiesta contiene un elenco di campi da recuperare dall'API Meta Marketing, un campo per riga. Per ulteriori informazioni, consulta il riferimento dell'API Meta Marketing.
Impostazioni di importazione
Controlla le pipeline di dati Source to Raw e Raw to CDC tramite le
impostazioni nel file src/Meta/config/ingestion_settings.yaml.
Questa sezione descrive i parametri di ogni pipeline di dati.
Tabelle da origine a non elaborate
Questa sezione contiene voci che controllano quali entità vengono recuperate dalle API e in che modo. Ogni voce corrisponde a un'entità dell'API Meta Marketing. In base a questa configurazione, Cortex Framework crea DAG Airflow che eseguono pipeline Dataflow per recuperare i dati utilizzando le API Meta Marketing.
Il file src/Meta/src/raw/pipelines/config.ini controlla alcuni comportamenti
del DAG di Cloud Composer e il modo in cui vengono utilizzate le API Meta Marketing.
Trova le descrizioni di ogni parametro nel file.
I seguenti parametri controllano le impostazioni di Source to Raw
per ogni voce:
| Parametro | Descrizione |
base_table
|
Tabella nel set di dati non elaborati in cui vengono archiviati i dati recuperati (ad esempio, customer).
|
load_frequency
|
Con quale frequenza viene eseguito un DAG per recuperare i dati da Meta. Per ulteriori informazioni sui valori possibili, consulta la documentazione di Airflow. |
object_endpoint
|
Percorso dell'endpoint API (ad esempio,
campaigns per l'endpoint /{account_id}/campaigns).
|
entity_type
|
Tipo di tabella (deve essere uno tra
fact, dimension o addaccount).
|
object_id_column
|
Colonne (separate da virgole) che
formano un record univoco per questa tabella. Obbligatorio solo
quando entity_type è fact.
|
breakdowns
|
Facoltativo: colonne di suddivisione
(separate da virgole) per gli endpoint di approfondimenti. Applicabile solo
quando entity_type è fact.
|
action_breakdowns
|
Facoltativo: colonne di suddivisione delle azioni
(separate da virgole) per gli endpoint di approfondimenti. Applicabile solo
quando entity_type è fact.
|
partition_details
|
Facoltativo: se vuoi che questa tabella sia partizionata per motivi di prestazioni. Per ulteriori informazioni, consulta Partizionamento delle tabelle. |
cluster_details
|
Facoltativo: se vuoi che questa tabella sia raggruppata per motivi di prestazioni. Per ulteriori informazioni, consulta Impostazioni cluster. |
Tabelle da non elaborate a CDC
Questa sezione descrive le voci che controllano il modo in cui i dati vengono spostati dalle tabelle non elaborate alle tabelle CDC. Ogni voce corrisponde a una tabella non elaborata (che a sua volta corrisponde all'entità API Meta, come indicato).
I seguenti parametri controllano le impostazioni di Raw to CDC per ogni voce:
| Parametro | Descrizione |
base_table
|
Tabella su cui sono stati replicati i dati non elaborati. Una tabella con lo stesso nome nel set di dati CDC memorizza
i dati non elaborati dopo la trasformazione CDC (ad esempio, campaign_insights).
|
row_identifiers
|
Colonne (separate da virgole) che formano un record univoco per questa tabella. |
load_frequency
|
Con quale frequenza viene eseguito un DAG per questa entità per popolare la tabella CDC. Per ulteriori informazioni sui valori possibili, consulta la documentazione di Airflow. |
partition_details
|
Facoltativo: se vuoi che questa tabella sia partizionata per motivi di prestazioni. Per ulteriori informazioni, consulta Partizionamento delle tabelle. |
cluster_details
|
Facoltativo: se vuoi che questa tabella sia raggruppata per motivi di prestazioni. Per ulteriori informazioni, consulta Impostazioni cluster. |
Schema della tabella CDC
Per Meta, tutti i campi vengono archiviati in formato stringa nel livello non elaborato. Nel livello CDC, i tipi primitivi vengono convertiti in tipi di dati aziendali pertinenti, e tutti i tipi complessi vengono archiviati in formato JSON BigQuery.
Per abilitare questa conversione, la directory src/Meta/config/table_schema
contiene un file di schema per ogni entità specificata nella sezione raw_to_cdc_tables
che spiega come tradurre correttamente ogni tabella non elaborata BigQuery in tabella CDC.
Ogni file di schema contiene tre colonne:
SourceField: nome del campo della tabella non elaborata per questa entità.TargetField: nome della colonna nella tabella CDC per questa entità.DataType: tipo di dati di ogni campo della tabella CDC.
Impostazioni report
Puoi configurare e controllare il modo in cui Cortex genera i dati per il livello di reporting finale di Meta
utilizzando il file delle impostazioni di reporting
(src/Meta/config/reporting_settings.yaml). Questo file controlla
la generazione degli oggetti BigQuery del livello di reporting (tabelle, viste, funzioni
o procedure memorizzate).
Per ulteriori informazioni, consulta Personalizzare il file delle impostazioni di reporting.
Passaggi successivi
- Per ulteriori informazioni su altre origini dati e altri workload, consulta Origini dati e workload.
- Per ulteriori informazioni sui passaggi per il deployment negli ambienti di produzione, vedi Prerequisiti per il deployment di Cortex Framework Data Foundation.