
Integration mit Campaign Manager 360
Auf dieser Seite werden die erforderlichen Konfigurationen beschrieben, um Daten aus Campaign Manager 360 als Datenquelle für die Marketing-Arbeitslast der Cortex Framework Data Foundation zu verwenden.
Campaign Manager 360 (CM360) ist eine webbasierte Plattform zur Anzeigenverwaltung von Google, die speziell für Werbetreibende und Agenturen entwickelt wurde. Sie dient als zentraler Hub für die Verwaltung und Optimierung aller Ihrer digitalen Werbekampagnen über verschiedene Kanäle hinweg. Cortex Framework bietet die Tools und die Plattform, um CM360-Daten zu analysieren, mit Daten aus anderen Marketingkanälen zu kombinieren und mithilfe von KI fundiertere Erkenntnisse zu gewinnen und Ihre gesamte Marketingstrategie zu optimieren.
Das folgende Diagramm zeigt, wie CM360-Daten über die Marketing-Arbeitslast von Cortex Framework Data Foundation verfügbar sind:
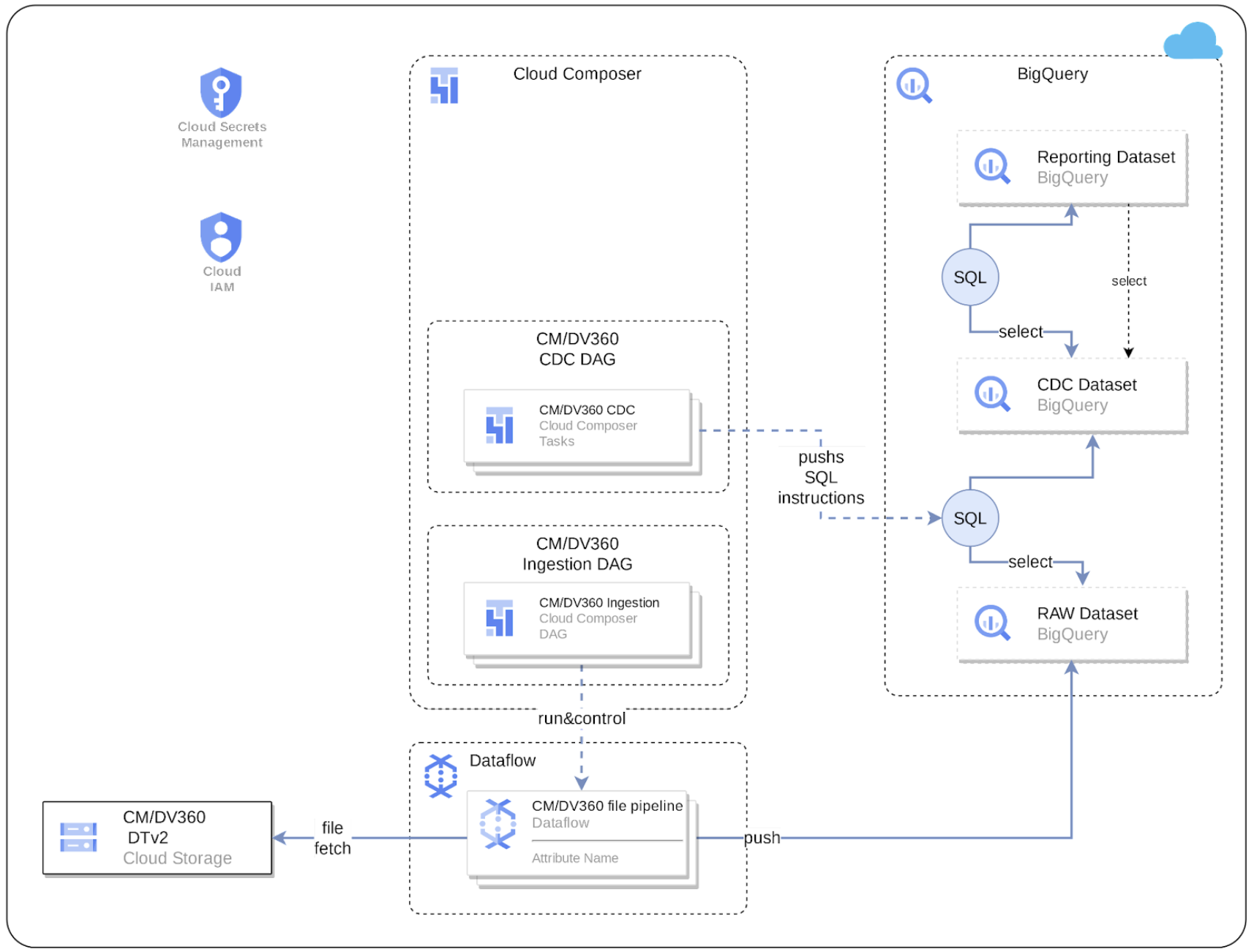
Konfigurationsdatei
In der Datei config.json werden die Einstellungen konfiguriert, die für die Verbindung zu Datenquellen zum Übertragen von Daten aus verschiedenen Arbeitslasten erforderlich sind. Diese Datei enthält die folgenden Parameter für CM360:
"marketing": {
"deployCM360": true,
}
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
}
In der folgenden Tabelle wird der Wert für jeden Marketingparameter beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
marketing.deployCM360
|
CM360 bereitstellen | true
|
Führen Sie die Bereitstellung für die CM360-Datenquelle aus. |
marketing.CM360.deployCDC
|
CDC-Scripts für CM360 bereitstellen | true
|
CM360-Scripts für die Verarbeitung von Kundendaten erstellen, die als DAGs in Managed Service for Apache Airflow ausgeführt werden. |
marketing.CM360.dataTransferBucket
|
Bucket mit Data Transfer Service-Ergebnissen | - | Bucket, in dem DTv2-Dateien gespeichert sind. |
marketing.CM360.datasets.cdc
|
CDC-Dataset für CM360 | CDC-Dataset für CM360. | |
marketing.CM360.datasets.raw
|
Rohdatensatz für CM360 | Rohdatensatz für CM360. | |
marketing.CM360.datasets.reporting
|
Berichtsdataset für CM360 | "REPORTING_CM360"
|
Berichtsdataset für CM360. |
Datenmodell
In diesem Abschnitt wird das CM360-Datenmodell anhand des Entity-Relationship-Diagramms (ERD) beschrieben.
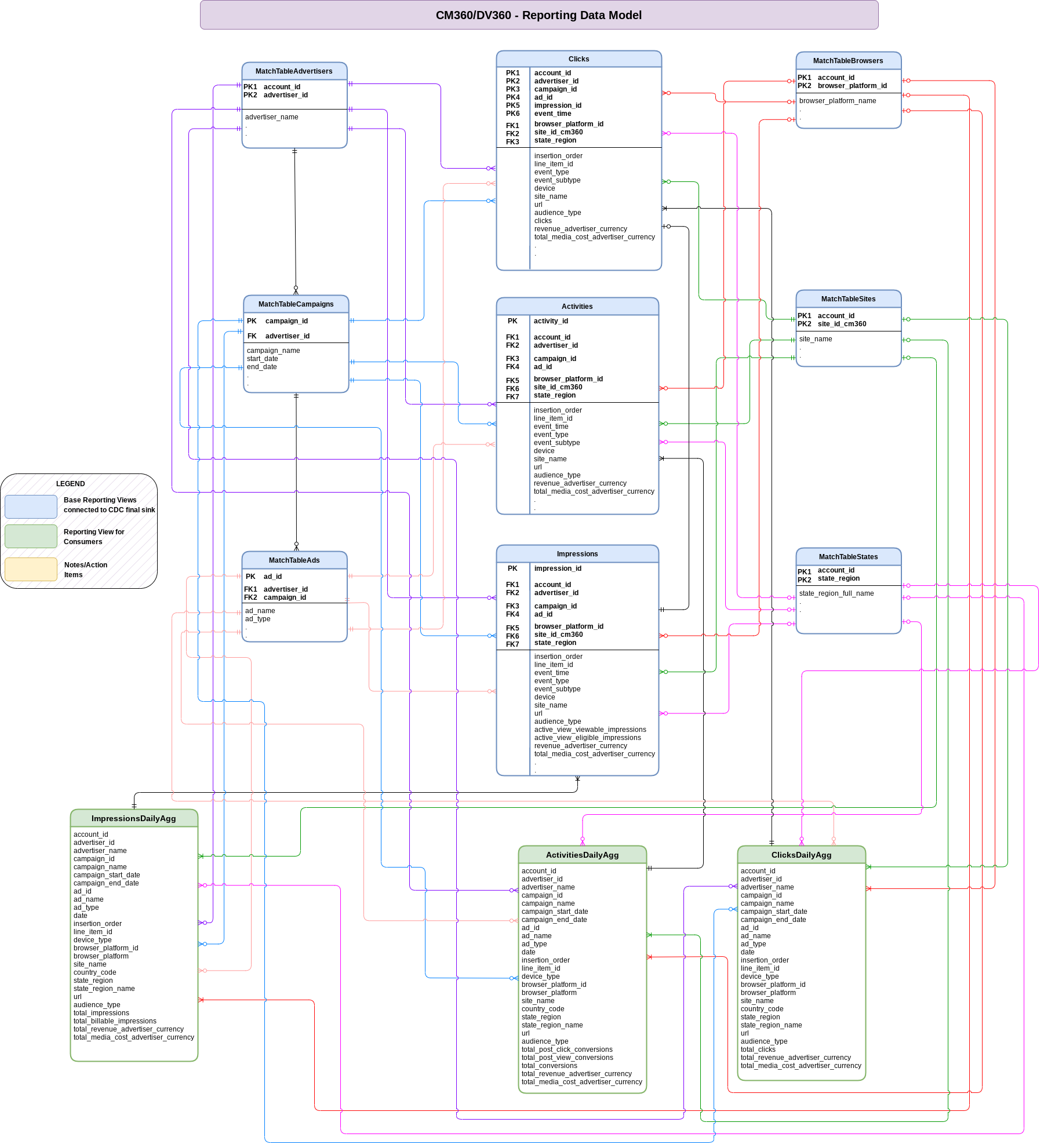
Basisansichten
Das sind die blauen Objekte im ERD. Sie sind Ansichten von CDC-Tabellen ohne Transformationen, abgesehen von einigen Aliasen für Spaltennamen. Scripts finden Sie unter src/marketing/src/CM360/src/reporting/ddls.
Berichtsdatenansichten
Das sind die grünen Objekte im ERD. Sie sind Berichtsansichten, die aggregierte Messwerte enthalten. Scripts finden Sie unter src/marketing/src/CM360/src/reporting/ddls.
Speicher von DTv2-Dateien
DTv2-Dateien (Data Transfer Version 2) sind ein bestimmtes Format, das von CM360 verwendet wird, um Leistungsdaten von Kampagnen bereitzustellen. Richten Sie die Datenübertragung ein, indem Sie der Dokumentation zur Datenübertragung Version 2 folgen, um CM360 mit dem Cortex Framework zu verwenden.
Erstellen oder fügen Sie einen Cloud Storage-Bucket zum Speichern Ihrer DTV2-Dateien aus CM360 hinzu. Prüfen Sie, ob die Dateien im Bucket vom Dienstkonto gelesen werden können, mit dem DAGs in Managed Airflow ausgeführt werden. Weitere Informationen finden Sie unter Storage-Buckets erstellen.
Datenaktualität und ‑verzögerung
Im Allgemeinen wird die Datenaktualität für Cortex Framework-Datenquellen durch die Upstream-Verbindung und die Häufigkeit der DAG-Ausführung begrenzt. Passen Sie die Ausführungshäufigkeit Ihres DAG an die Upstream-Häufigkeit, Ressourcenbeschränkungen und Ihre geschäftlichen Anforderungen an.
Mit Data Transfer v2 für CM360 werden Daten zu Impressionen und Klicks 24-mal täglich (stündlich) bereitgestellt. Die Bearbeitungszeit kann je nach Datei variieren. Daher werden Dateien möglicherweise in falscher Reihenfolge angezeigt. Aktivitätsdateien werden täglich bereitgestellt.
Managed Airflow-Verbindungen
Erstellen Sie die folgenden Verbindungen in Managed Airflow. Weitere Informationen finden Sie in der Dokumentation zum Verwalten von Airflow-Verbindungen.
| Verbindungsname | Purpose |
cm360_raw_dataflow
|
Für CM360 DTv2-Dateien > BigQuery Rohdatensatz |
cm360_cdc_bq
|
Für die Übertragung von Rohdaten-Datasets in CDC-Datasets |
cm360_reporting_bq
|
Für die Übertragung von CDC-Dataset > Reporting-Dataset |
Berechtigungen für das Dienstkonto von Managed Service for Apache Airflow
Gewähren Sie dem Dienstkonto, das in Managed Airflow verwendet wird (wie in der cm360_raw_dataflow-Verbindung konfiguriert), Dataflow-Berechtigungen.
Eine Anleitung finden Sie in der Dataflow-Dokumentation.
Aufnahmeeinstellungen
Sie können Source to Raw- und Raw to CDC-Datenpipelines über die Einstellungen in der Datei src/CM360/config/ingestion_settings.yaml steuern. In diesem Abschnitt werden die Parameter der einzelnen Datenpipelines beschrieben.
Von Quell- zu Rohdatentabellen
In diesem Abschnitt wird beschrieben, wie Einträge funktionieren, mit denen gesteuert wird, welche Dateien aus DTv2 verarbeitet werden. Jeder Eintrag entspricht Dateien, die mit einer Einheit verknüpft sind. Basierend auf dieser Konfiguration erstellt das Cortex Framework Airflow-DAGs, mit denen Dataflow-Pipelines ausgeführt werden, um Daten aus den DTv2-Dateien zu verarbeiten.
Die folgenden Parameter steuern die Einstellungen für Source to Raw für jeden Eintrag:
| Parameter | Beschreibung |
base_table
|
Tabelle im Rohdatensatz, in der die Daten für eine Entität gespeichert sind (z. B. „Klicks“-Daten). |
load_frequency
|
Wie oft ein DAG für diese Einheit ausgeführt wird, um die CDC-Tabelle zu füllen. Weitere Informationen zu möglichen Werten finden Sie in der Airflow-Dokumentation. |
file_pattern
|
Basierend auf Dateinamenmustern, die einer Entität entsprechen. |
schema_file
|
Schemadatei im Verzeichnis src/table_schema, in der DTv2-Felder den Spaltennamen und Datentypen der Zieltabelle zugeordnet werden.
|
partition_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Leistungsgründen partitioniert wird. Weitere Informationen finden Sie unter Tabellenpartition. |
cluster_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Leistungsgründen gruppiert wird. Weitere Informationen finden Sie unter Clustereinstellungen. |
Rohdaten- in CDC-Tabellen
Dieser Abschnitt enthält Einträge, mit denen gesteuert wird, wie Daten aus Rohdatentabellen in CDC-Tabellen verschoben werden. Jeder Eintrag entspricht einer Rohdatentabelle, die wiederum der oben erwähnten DTv2-Einheit entspricht.
Die folgenden Parameter steuern die Einstellungen für Raw to CDC für jeden Eintrag:
| Parameter | Beschreibung |
base_table
|
Tabelle im CDC-Dataset, in der die Rohdaten nach der CDC-Transformation gespeichert werden (z. B. customer).
|
load_frequency
|
Wie oft ein DAG für diese Einheit ausgeführt wird, um die CDC-Tabelle zu füllen. Weitere Informationen zu möglichen Werten finden Sie in der Airflow-Dokumentation. |
row_identifiers
|
Liste der Spalten (durch Komma getrennt), die einen eindeutigen Datensatz für diese Tabelle bilden. |
partition_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Leistungsgründen partitioniert wird. Weitere Informationen finden Sie unter Tabellenpartition. |
cluster_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Leistungsgründen gruppiert wird. Weitere Informationen finden Sie unter Clustereinstellungen. |
Berichtseinstellungen
Sie können konfigurieren und steuern, wie das Cortex Framework Daten für die CM360-Berichtsebene generiert. Dazu verwenden Sie die Datei mit den Berichtseinstellungen (src/CM360/config/reporting_settings.yaml). Mit dieser Datei wird gesteuert, wie BigQuery-Objekte der Berichtsebene (Tabellen, Ansichten, Funktionen oder gespeicherte Prozeduren) generiert werden.
Weitere Informationen finden Sie unter Datei mit Berichtseinstellungen anpassen.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen finden Sie unter Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.