
AI 可用区是专门用于人工智能和机器学习 (AI 和 ML) 训练和推理工作负载的可用区。它们可提供充足的机器学习加速器(GPU 和 TPU)容量。
在区域内,AI 可用区在地理位置上与标准(非 AI)可用区相距较远。下图展示了一个 AI 可用区 (us-central1-ai1a) 的示例,该可用区相对于 us-central1 区域中的标准可用区而言距离更远。
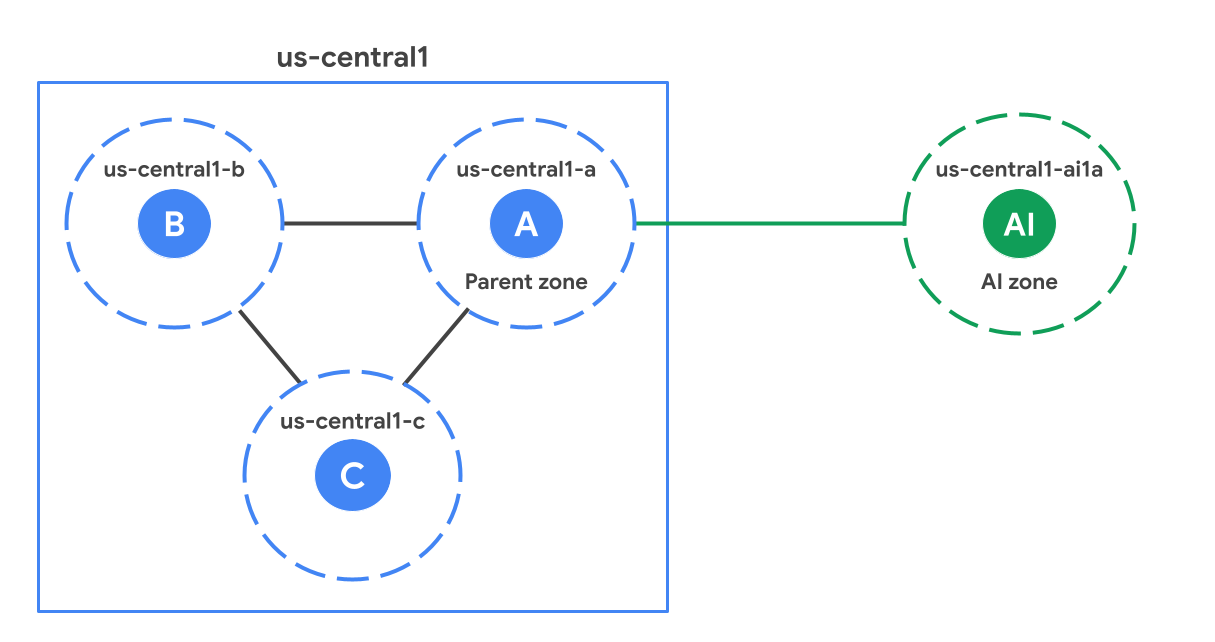
家长专区
每个 AI 可用区都与相应区域中的一个标准可用区相关联,后者称为其父可用区。父级可用区是与 AI 可用区具有相同后缀的标准可用区。例如,在图中,us-central1-a 是 us-central1-ai1a 的父可用区。它们共享软件更新时间表,有时还共享基础设施。这意味着,影响父可用区的任何软件或基础架构问题也可能会影响 AI 可用区。在设计高可用性解决方案时,请查看高可用性 (HA) 注意事项,以考虑对父可用区的依赖关系。
何时使用 AI 可用区
AI 可用区针对 AI 和机器学习工作负载进行了优化。请根据以下指南确定哪些工作负载最适合 AI 可用区,哪些工作负载更适合标准可用区。
建议用于:
大规模训练:非常适合大规模训练工作负载,例如大语言模型 (LLM) 和基础模型训练,因为有大量加速器可用。
小规模训练、微调、批量推理和重新训练:AI 区域非常适合需要大量加速器容量的工作负载。
实时机器学习推理:AI 区域支持实时推理工作负载。性能取决于应用设计和模型延迟时间要求,尤其是当工作负载需要向父区域发送往返请求时。
不建议用于:
- 非机器学习工作负载:由于 AI 可用区未在本地提供所有 Google Cloud 服务,因此我们建议您在标准可用区中运行非机器学习工作负载。
从 AI 可用区访问服务
您可以从 Google Cloud 地区的 AI 区域访问该地区的所有 Google Cloud 产品。不过,从 AI 可用区访问 Google Cloud 区域中的服务可能会增加网络延迟,因为 AI 可用区在物理上与该区域的标准可用区位置是分开的。
部分产品支持在 AI 区域中本地创建或访问可用区级资源。如需详细了解这些服务,请参阅下表:
| 产品 | 说明 |
|---|---|
| Google Kubernetes Engine (GKE) | 设置在 GKE 集群中使用 AI 加速区,包括使用 ComputeClasses、节点自动预配和 GKE Standard 节点池进行配置。 在 GKE 中使用 AI 加速区 |
| Cloud Storage | 针对 AI 区域中的工作负载配置对象存储,包括区域存储(可在活跃作业期间最大限度地提高性能)和持久存储(用于存储数据集和模型检查点)。 将 AI 区域与 Cloud Storage 搭配使用 |
| Compute Engine | 介绍如何使用控制台、Google Cloud CLI 和 REST API 识别可用的 AI 可用区,包括如何按命名惯例、加速器类型或机器类型进行过滤 查找可用的 AI 可用区 |
位置
AI 区域可在以下位置使用:
| AI 可用区 | AI 可用区位置 | Google Cloud 区域 | Google Cloud 区域位置 | 父区域 |
|---|---|---|---|---|
us-south1-ai1b |
北美洲德克萨斯州奥斯汀 | us-south1 |
北美洲德克萨斯州达拉斯 | us-south1-b |
us-central1-ai1a |
北美洲内布拉斯加州林肯 | us-central1 |
北美洲爱荷华州康瑟布拉夫斯 | us-central1-a |
使用 AI 可用区
您可以通过 Google Cloud 控制台、Google Cloud CLI 或 REST 访问 AI 可用区。不过,当您使用Google Cloud 控制台创建虚拟机时,必须手动选择 AI 可用区。与标准可用区不同,系统不会为您选择此可用区。如需将 AI 可用区与以下功能搭配使用,您必须在设置这些资源时明确选择 AI 可用区。
某些 Compute Engine 和 GKE 功能:在某些 Compute Engine 和 GKE 区域级功能(例如区域级代管式实例组、区域级 GKE 集群)中,系统不会自动选择 AI 可用区。如需详细了解 GKE,请参阅 GKE 文档。
非加速器工作负载限制:在 AI 可用区中运行仅使用 CPU 的虚拟机时,请注意 Compute Engine 强制执行的限制。这些可能包括对 GPU:CPU 比率和预留的要求。
Vertex AI:基于 GKE 的 Vertex AI 区域性产品必须配置 GKE,以在区域性集群中包含 AI 可用区。您无需选择启用 Vertex AI。Vertex AI 会管理此配置。
Google Cloud Service Metadata Locations API:使用 locations.list API 时,您必须启用
--extraLocationTypes标志,以确保 AI 区域仅向打算使用它们的用户显示。
在 GKE 中使用 AI 可用区
默认情况下,GKE 不会在 AI 可用区中部署工作负载。如需使用 AI 区域,请配置以下选项之一:
ComputeClass:将最高优先级设置为在 AI 地区请求按需 TPU。ComputeClass 可帮助您为工作负载定义硬件配置的优先级列表。如需查看示例,请参阅 ComputeClass 简介。
节点自动预配:在 pod 规范中使用
nodeSelector或nodeAffinity,指示节点自动预配功能在 AI 可用区中创建节点池。如果工作负载未明确指定 AI 可用区,则节点自动预配在创建新节点池时仅考虑标准可用区。此配置可确保不运行 AI/机器学习模型的工作负载保留在标准可用区中,除非您明确配置其他可用区。如需查看使用nodeSelector的清单示例,请参阅为自动创建的节点设置默认可用区。GKE Standard:如果您直接管理节点池,请在创建节点池时使用
--node-locations标志中的 AI 区域。如需查看示例,请参阅在 GKE Standard 中部署 TPU 工作负载。
限制
以下功能在 AI 区域中不可用:
使用 AI 可用区时的设计注意事项
在设计应用以使用 AI 区域时,请考虑以下事项。
高可用性 (HA) 注意事项
AI 区域与其父区域共享软件发布和基础设施。为确保工作负载的高可用性,在选择可用区时(无论是自动选择还是手动选择),请避免以下部署模式:
避免跨 AI 可用区及其父可用区部署 HA 工作负载。
避免在共享同一父可用区的两个 AI 可用区中部署高可用性工作负载。
存储最佳实践
我们建议采用分层存储架构,以平衡成本、持久性和性能:
- 冷存储层:使用标准区域中的区域级 Cloud Storage 存储分区来持久存储高度耐用的训练数据集和模型检查点。
性能层:使用专用区域存储服务作为高速缓存或临时暂存空间。这种方法可消除地区间延迟,并在作业处于活跃状态时最大限度地提高有效吞吐量。
为确保 GPU 和 TPU 始终处于饱和状态,从而最大限度地提高有效吞吐量,请在与计算资源相同的 AI 区域中预配性能层。
建议使用以下存储解决方案,通过 AI 区域优化 AI 和机器学习系统性能:
| 存储服务 | 说明 | 使用场景 |
|---|---|---|
| Cloud Storage 的 Anywhere Cache 功能 | 一种全托管式、由 SSD 提供支持的可用区级读取缓存,可将存储分区中频繁读取的数据引入 AI 可用区。 | 建议用于:
|