
了解持续查询中的窗口聚合
如需请求支持或对此功能提供反馈,请发送电子邮件至 bq-continuous-queries-feedback@google.com。
BigQuery 持续查询支持将聚合和窗口化作为有状态操作。 借助有状态操作,持续查询可以执行复杂的分析,这些分析需要跨多个行或时间间隔保留信息。借助此功能,您可以在查询运行时将必要的数据存储在内存中,从而计算随时间变化的指标(例如 30 分钟平均值)。
窗口化函数根据系统时间(表示进行更改的事务的提交时间)将数据分配到逻辑组件或窗口中。在 BigQuery 中,这些函数是表值函数 (TVF),它们返回一个表,该表包含所有原始列以及两个额外的列:window_start 和
window_end。这些列用于标识每个窗口的时间间隔。如需详细了解有状态操作,请参阅
支持的有状态操作。
窗口化 TVF 仅受 BigQuery 持续 查询支持。
窗口化 TVF 不同于 窗口函数 调用。
支持的聚合函数
支持以下聚合函数:
ANY_VALUEAPPROX_COUNT_DISTINCTAPPROX_QUANTILESAPPROX_TOP_COUNTAPPROX_TOP_SUMARRAY_AGG,但需满足以下要求:- 必须使用
LIMIT子句,且最大值为 100。 - 可以使用
ORDER BY子句,但不是必需的。
- 必须使用
ARRAY_CONCAT_AGGAVGBIT_ANDBIT_ORBIT_XORCORRCOUNTCOUNTIFCOVAR_POPCOVAR_SAMPLOGICAL_ANDLOGICAL_ORMAXMAX_BYMINMIN_BYSTDDEVSTDDEV_POPSTDDEV_SAMPSTRING_AGG,但需满足以下要求:- 必须使用
LIMIT子句,且最大值为 100。 - 可以使用
ORDER BY子句,但不是必需的。
- 必须使用
SUMVAR_POPVAR_SAMPVARIANCE
不受支持的聚合函数
以下聚合函数不受支持:
AVG(差分隐私)COUNT(差分隐私)- 包含
DISTINCT表达式的函数。 GROUPINGPERCENTILE_CONT(差分隐私)ST_CENTROID_AGGST_EXTENTST_UNION_AGGSUM(差分隐私)
TUMBLE 函数
TUMBLE 函数将数据分配到指定大小的非重叠时间间隔(翻滚窗口)中。例如,5 分钟窗口会将事件分组到
离散间隔中,例如 [2026-01-01 12:00:00, 2026-01-01 12:05:00) 和
[2026-01-01 12:05:00, 2026-01-01 12:10:00)。时间戳值为 2026-01-01 12:03:18 的行会分配到第一个窗口。由于这些窗口是不相交且不重叠的,因此每个带有时间戳的元素都只会分配到一个窗口。
下图展示了 TUMBLE 函数如何将事件分配到非重叠时间间隔中:
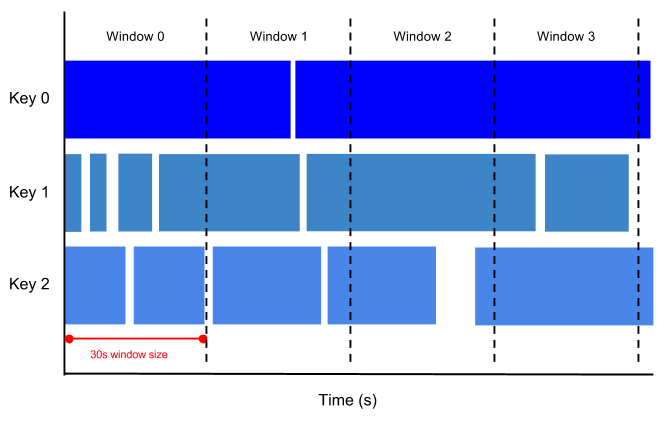
您可以在实时事件处理中使用此函数,以便在执行任何聚合之前按时间范围对事件进行分组。
语法
TUMBLE(TABLE table, "timestamp_column", window_size)
定义
table:BigQuery 表名称。这必须是封装在APPENDS函数中的 标准 BigQuery 表 。字词TABLE必须位于此实参之前。timestamp_column:一个STRING字面量,用于指定输入表中包含事件时间的列的名称。此列中的值会将每一行分配给一个窗口。定义 BigQuery 系统时间的_CHANGE_TIMESTAMP列是唯一受支持的timestamp_column。不支持用户定义的列。window_size:一个INTERVAL值,用于定义每个翻滚窗口的持续时间。窗口大小最长为 24 小时。例如:INTERVAL 30 SECOND。
输出
TUMBLE 函数返回包含以下列的输出:
查询运行时输入表的所有列。
window_start:一个TIMESTAMP值,用于指示记录所属窗口的起始时间(包含)。window_end:一个TIMESTAMP值,用于指示记录所属窗口的结束时间(不包含)。
输出具体化
在 BigQuery 持续查询中,窗口化聚合不会为特定时间间隔生成输出,直到 BigQuery 最终确定或关闭该窗口。 此行为可确保 BigQuery 仅在处理完该窗口的所有相关数据后才发出聚合结果。
例如,如果您对 user_clickstream 表执行 5 分钟的 TUMBLE 窗口聚合,则只有在查询处理完 _CHANGE_TIMESTAMP 为
10:20 或之后的记录后,才会发出 [10:15; 10:20) 间隔的结果。此时,BigQuery 会将该窗口视为已关闭。
此外,当属于该特定时间范围的第一条记录出现时,窗口会打开并开始累积数据。
在窗口保持打开状态期间,BigQuery 必须保留中间聚合结果。这需要存储状态,这意味着 BigQuery 必须保留中间聚合结果。 由于此状态必须保留在活跃内存中,直到窗口关闭,因此使用较长的窗口持续时间或处理大量流会导致更高的槽利用率,以便管理存储的上下文数量的增加。如需了解更多 信息,请参阅价格注意事项。
限制
TUMBLE函数仅在 BigQuery 持续查询中受支持。- 启动使用
TUMBLE函数的持续查询时,您只能使用APPENDS函数。不支持CHANGES函数。 - 由
_CHANGE_TIMESTAMP定义的 BigQuery 系统时间列是唯一受支持的timestamp_column。不支持用户定义的列。 - 窗口大小最长为 24 小时。
- 当
TUMBLE窗口化函数运行时,它会生成两个额外的输出列:window_start和window_end。您必须在执行窗口聚合的SELECT语句内的GROUP BY语句中至少包含其中一列。 - 将
TUMBLE函数与持续查询联接搭配使用时,您必须 遵循所有持续查询联接 限制。
价格注意事项
BigQuery 持续查询会根据 作业运行时消耗的计算容量(槽) 向您收费。这种基于计算的模型也适用于有状态操作(如窗口化)。由于窗口化需要 BigQuery 在查询处于活跃状态时存储“状态”,因此它会消耗额外的槽资源。一般来说,窗口中存储的上下文或数据越多(例如使用较长的窗口持续时间时),BigQuery 必须保留的状态就越多。这会导致更高的槽利用率。
示例
以下查询展示了如何查询出租车行程表,以获取每 30 分钟的出租车流式平均行程数、乘客数和平均车费,并将此数据导出到 BigQuery 中的一个表中:
INSERT INTO
`real_time_taxi_streaming.driver_stats`
WITH ride_completions AS (
SELECT
_CHANGE_TIMESTAMP as bq_changed_ts,
CAST(timestamp AS DATE) AS ride_date,
taxi_id,
meter_reading,
passenger_count
FROM
APPENDS(TABLE `real_time_taxi_streaming.taxirides`,
CURRENT_TIMESTAMP() - INTERVAL 10 MINUTE)
WHERE
ride_status = 'dropoff')
SELECT
ride_date,
window_end,
taxi_id,
COUNT(taxi_id) AS total_rides_per_half_hour,
ROUND(AVG(meter_reading),2) AS avg_fare_per_half_hour,
SUM(passenger_count) AS total_passengers_per_half_hour
FROM
tumble(TABLE ride_completions,"bq_changed_ts",INTERVAL 30 MINUTE)
GROUP BY
window_end,
ride_date,
taxi_id
后续步骤
- 了解如何执行联接、聚合和窗口化。
- 详细了解 BigQuery 持续查询。
- 了解如何联接来自多个流的数据。