
ノートブック ギャラリーを使用してノートブックを作成して実行する
BigQuery Studio のノートブック ギャラリーを使用して、データの分析を開始します。
始める前に
- Google Cloud アカウントにログインします。 Google Cloudを初めて使用する場合は、 アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
BigQuery API を有効にします。
API を有効にするために必要なロール
API を有効にするには、
serviceusage.services.enable権限が必要です。プロジェクトを作成した場合は、オーナーロール(roles/owner)を介してこの権限がすでに付与されている可能性があります。それ以外の場合は、Service Usage 管理者ロール(roles/serviceusage.serviceUsageAdmin)を介してこの権限を取得できます。ロールを付与する方法をご覧ください。新しいプロジェクトでは、BigQuery API が自動的に有効になります。
- (省略可)プロジェクトに対する課金を有効にします。課金を有効にしない場合や、クレジット カードを指定しない場合でも、このドキュメントの手順は行えます。BigQuery には、この手順を実施するためのサンドボックスが用意されています。詳細については、BigQuery サンドボックスを有効にするをご覧ください。
必要なロール
ノートブックの実行に必要な権限を取得するには、プロジェクトに対する次の IAM ロールを付与するよう管理者に依頼してください。
- BigQuery 読み取りセッション ユーザー (
roles/bigquery.readSessionUser) - BigQuery Studio ユーザー (
roles/bigquery.studioUser)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
BigQuery のノートブックを初めて使用する場合は、ノートブックの作成ページの必要な権限をご覧ください。
ノートブック ギャラリー
ノートブック ギャラリーは、事前作成済みのノートブック テンプレートを見つけて使用するための中央ハブです。これらのテンプレートを使用すると、データの準備、データ分析、可視化などの一般的なタスクを実行できます。ノートブック テンプレートは、BigQuery Studio の機能の探索、ワークフローの管理、ベスト プラクティスの推進にも貢献します。
ノートブック ギャラリー テンプレートを使用すると、データの取り込みや探索、高度な分析と BigQuery ML など、データ ライフサイクルの各段階で目的から分析情報創出までのワークフロー全体を効率化できます。
ノートブック ギャラリーには、あらゆるスキルレベルに対応したテンプレートが用意されています。ギャラリーには SQL、Python、Apache Spark、DataFrame の基本的なテンプレートが含まれています。BigQuery の生成 AI やマルチモーダル データ分析などのトピックについても学習できます。
ノートブック ギャラリー テンプレートの使用の詳細については、ノートブック ギャラリーを使用してノートブックを作成するをご覧ください。
ノートブック ギャラリーのテンプレートからノートブックを作成する
次の例では、BigQuery Studio のノートブックの概要テンプレートを使用します。このノートブックでは、次のタスクを行う方法について説明します。
- データのクエリ: SQL セルを使用してクエリを実行します。
- クエリ結果を可視化する: 可視化セルを使用して、コードなしで可視化を作成します。
- データをクリーンアップして変換する: BigQuery DataFrames(pandas)API を使用して、データを並べ替え、重複除去、フィルタします。
- AI 予測を実行する: BigQuery DataFrames の(
AI.FORECAST関数)を使用して予測を生成します。AI.FORECAST関数は、TimesFM 基盤モデルを使用して、モデルのトレーニングを必要としないデータセットから直接予測を生成します。 - データをプロットする: Python の組み込み可視化ライブラリを使用してデータをプロットします。Matplotlib と Pandas を利用した BigQuery DataFrames 可視化ライブラリを使用して、データをプロットします。
ノートブックを使用するには、テンプレートを開いて実行可能なノートブックに変換し、ノートブックのランタイム環境に接続して、ノートブックを実行します。
テンプレートを開き、実行可能なノートブックに変換する
ノートブック ギャラリー テンプレートから作成したノートブックを使用する前に、テンプレートを実行可能なノートブックに変換する必要があります。
ノートブック ギャラリーで BigQuery Studio のノートブックの概要テンプレートを開き、実行可能なノートブックに変換する手順は次のとおりです。
[Studio] ページに移動します。
矢印のプルダウンをクリックし、[Notebook > All templates] を選択します。
または、BigQuery Studio のホームページで、[ノートブック ギャラリーを表示] をクリックします。
![BigQuery Studio のホームページにある [ノートブック ギャラリーを表示] リンク。](https://docs.cloud.google.com/bigquery/images/template-gallery.png?hl=ja)
[BigQuery Studio のノートブックの概要] カードをクリックするか、ギャラリーで検索します。
テンプレートが開いたら、[このテンプレートを使う] をクリックして、テンプレートを実行可能なノートブックに変換します。
デフォルトのランタイムに接続する
ノートブックを実行する前に、Gemini Enterprise Agent Platform ランタイムに接続する必要があります。ランタイムはノートブックでコードを実行するコンピューティング リソースであり、ノートブックと同じリージョンに存在する必要があります。
ランタイムの詳細については、ランタイムとランタイム テンプレートをご覧ください。リージョン設定の構成の詳細については、コードアセットにデフォルトのリージョンを設定するをご覧ください。
エラーを返します。このチュートリアルでは、デフォルトのランタイムを使用します。デフォルトのランタイムは、最小限の設定が必要なプリセット ランタイムです。デフォルトのランタイムに接続する手順は次のとおりです。
ノートブックを開いた状態で、[接続] をクリックします。
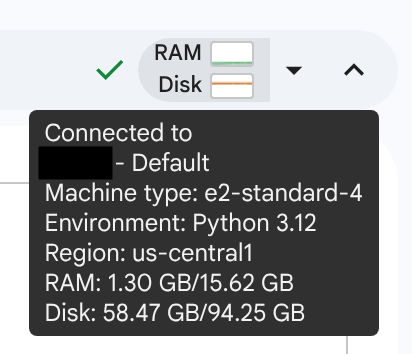
アクティブなランタイムがない場合、デフォルトのランタイムへの接続に数分かかることがあります。
ランタイムの準備が整うと、RAM とディスクのグラフが表示されたチェックマークが表示されます。グラフにカーソルを合わせると、ランタイムのタイプとランタイムの構成が表示されます。
ノートブックを実行する
BigQuery Studio のノートブックの概要には、テキスト、SQL、可視化、コードのセルが含まれています。テキストセル以外のセルは個別に実行することも、最初から最後まで順番に実行することもできます。
このチュートリアルでは、ノートブックのセルを個別に実行して、結果を段階的に確認します。ノートブックを実行するには:
[SQL セルを使用してデータにクエリを実行する] セクションで、SQL セルにカーソルを合わせて [セルを実行] をクリックします。
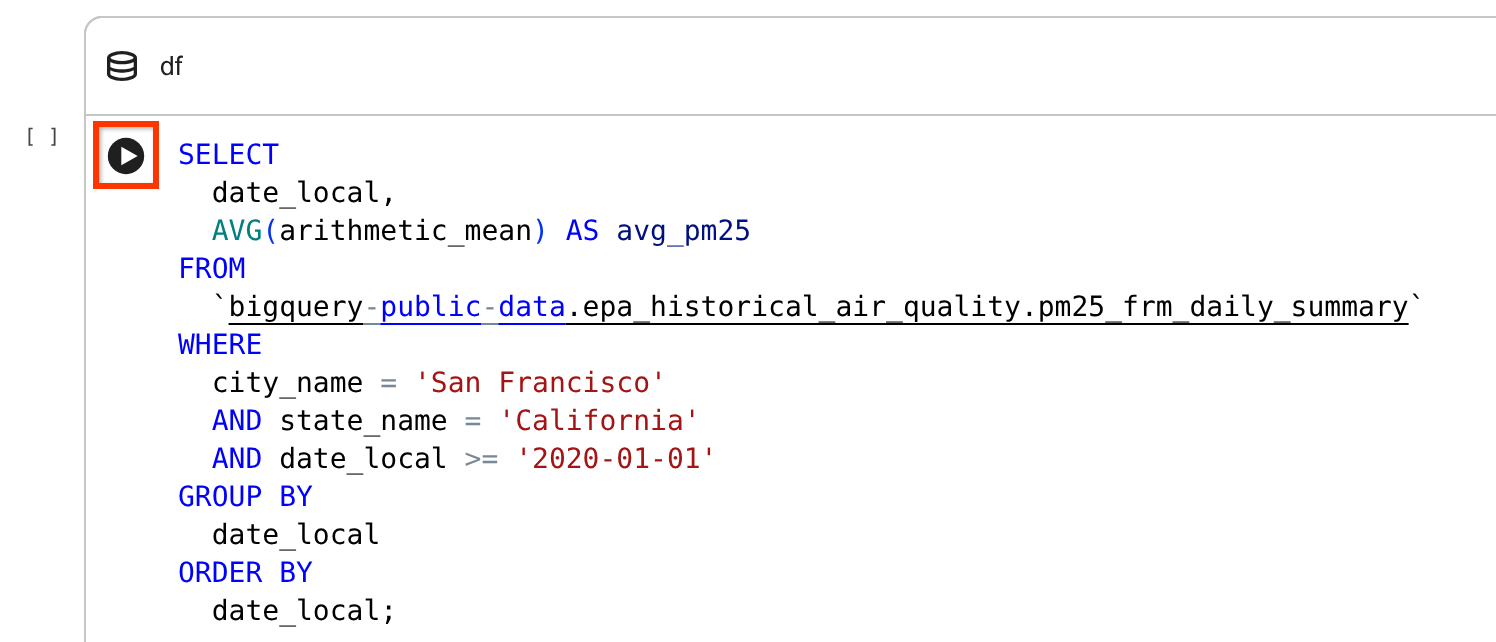
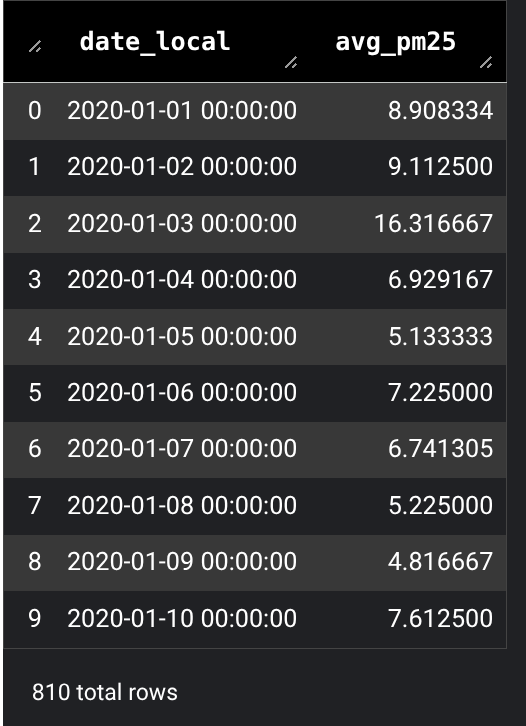
この SQL セルは、過去の大気質に関する一般公開データセットの
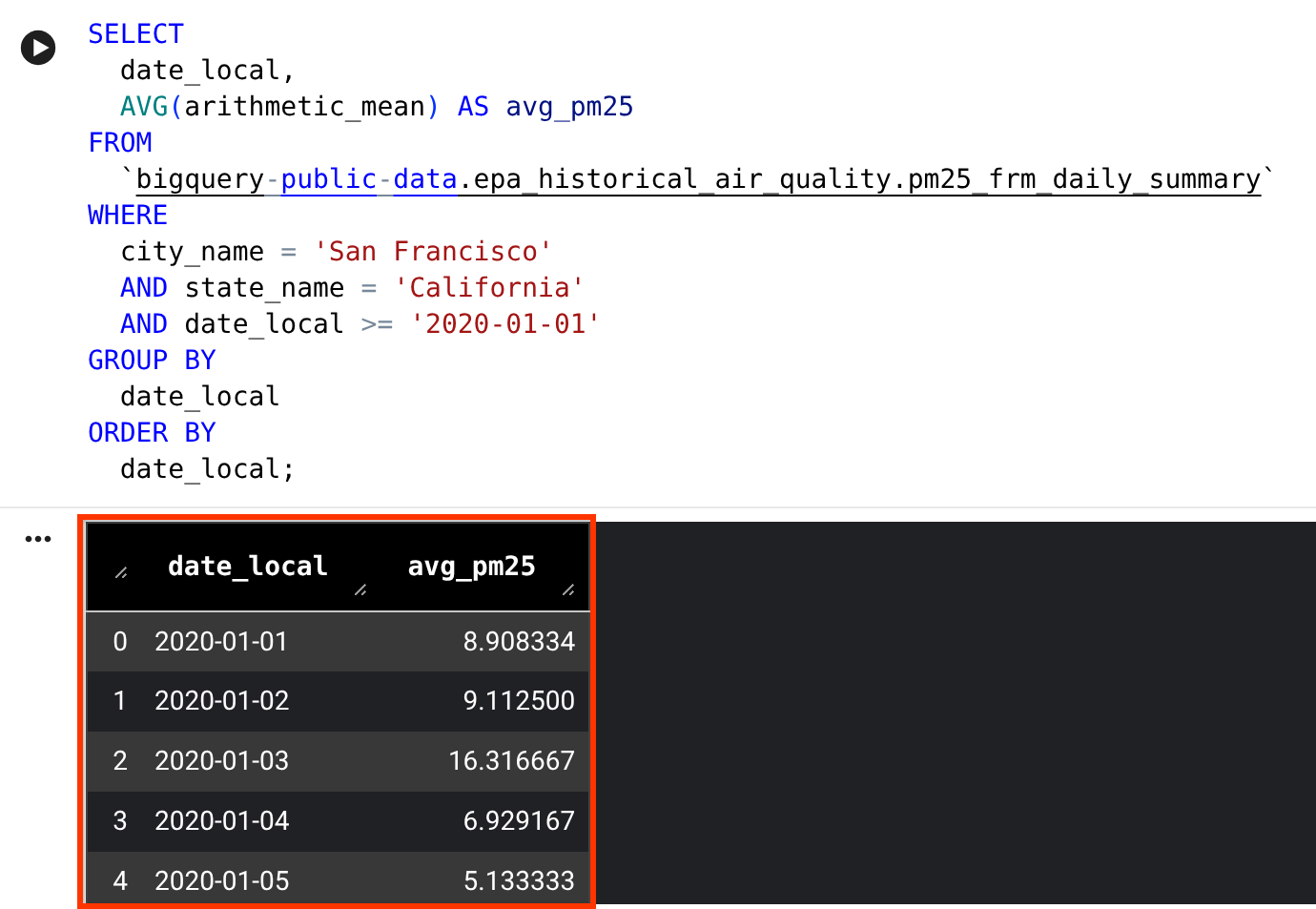
bigquery-public-data.epa_historical_air_quality.pm25_frm_daily_summaryテーブルをクエリし、過去数年間のサンフランシスコの 1 日の平均 PM2.5(一般的な大気質指標)を返します。結果を確認します。クエリ結果が DataFrame に表示されます。
[Visualize data] セクションで、可視化セルにカーソルを合わせ、 [Run cell] をクリックします。
生成された可視化を表示します。
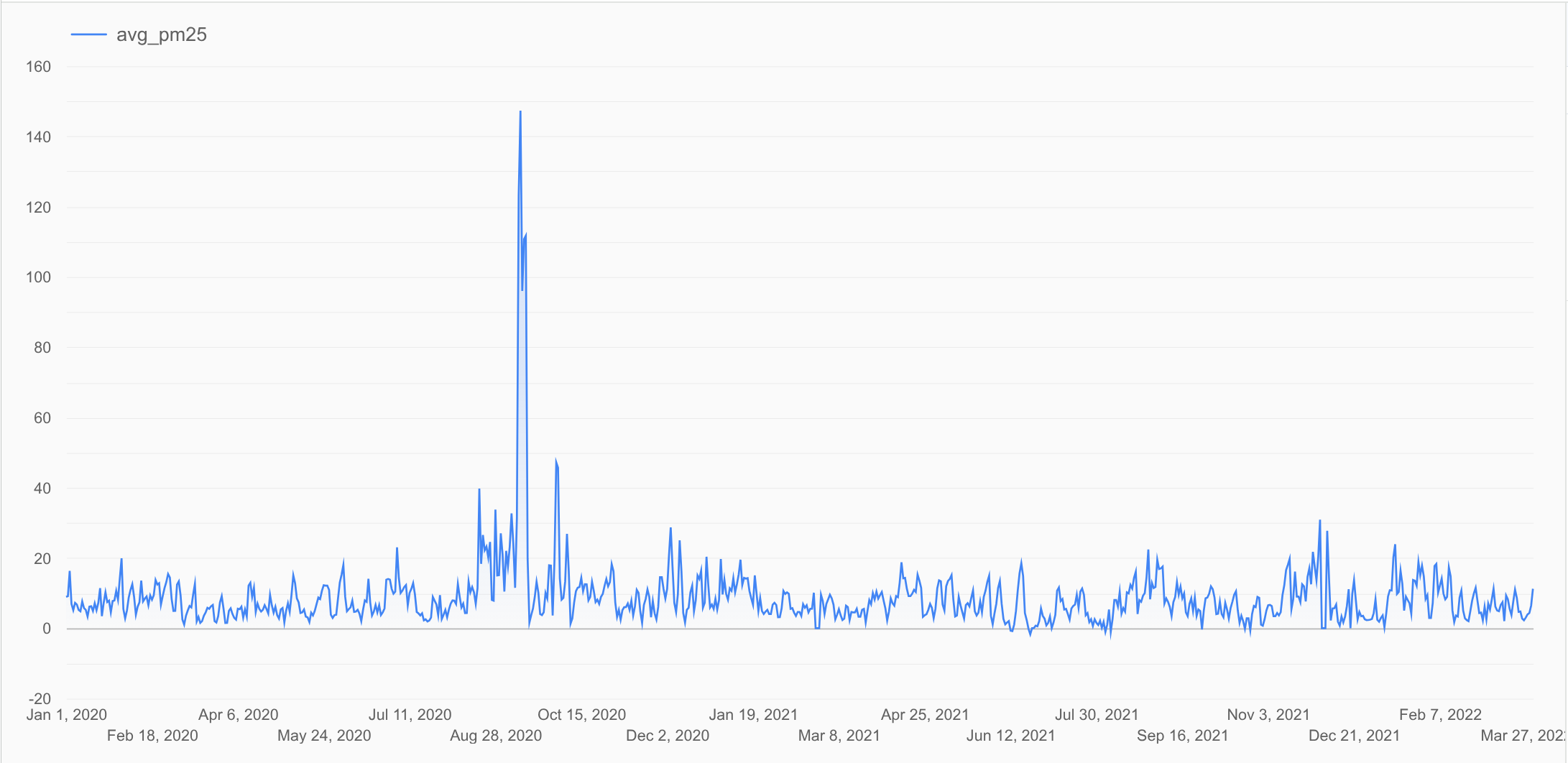
結果には、前に生成した
dfDataFrame の 1 日あたりの平均 PM2.5 値をプロットした時系列グラフが表示されます。このグラフは、PM2.5 レベルの推移を示しています。[データをクリーンアップする] セクションで、コードセルにカーソルを合わせて、 [セルを実行] をクリックします。
結果を確認します。結果は DataFrame に表示されます。
コードは次の処理を行います。
bigframes.pandasライブラリをインポートします。date_localフィールドがタイムスタンプであることを確認します。- 予測に必要な日付で結果を並べ替えます。
- 重複する行を削除します。
avg_pm25がnullの行を削除します。- 外れ値をフィルタします。
- 結果を
df_cleanedという名前の BigQuery DataFrames に表示します。
[
AI.FORECASTを使用して値を予測する] セクションで、SQL セルにカーソルを合わせて、 [セルを実行] をクリックします。結果を確認します。クエリ結果が DataFrame に表示されます。
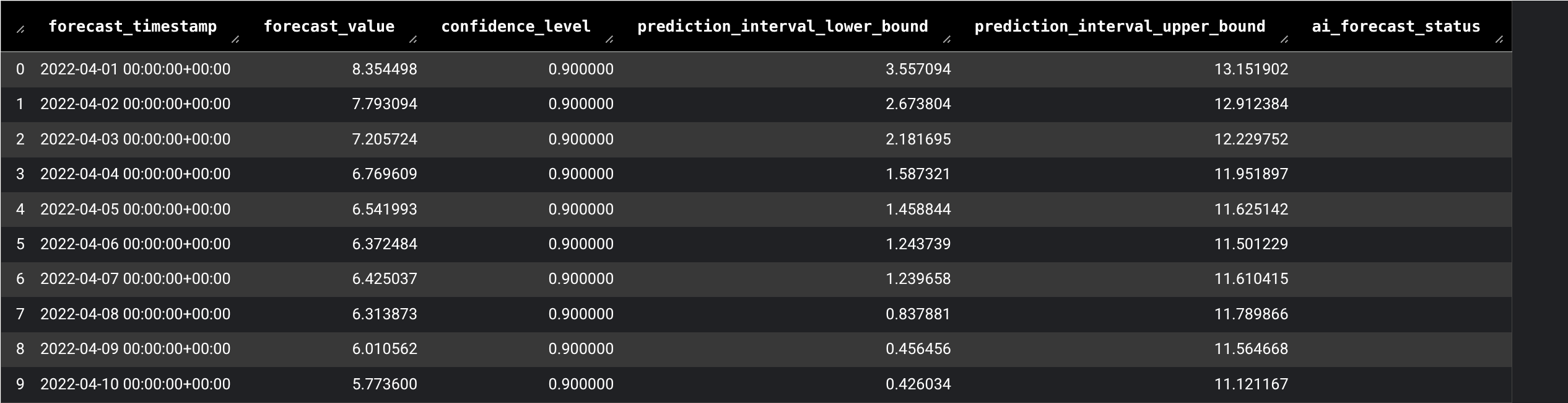
この SQL セルは、
AI.FORECAST関数を使用して、以前に生成したdf_cleanedDataFrame を使用して将来の 1 日の平均 PM2.5 を予測するクエリを実行します。[Python を使用してデータを可視化する] セクションで、コードセルにカーソルを合わせて、 [セルを実行] をクリックします。
結果を確認します。結果はグラフに表示されます。
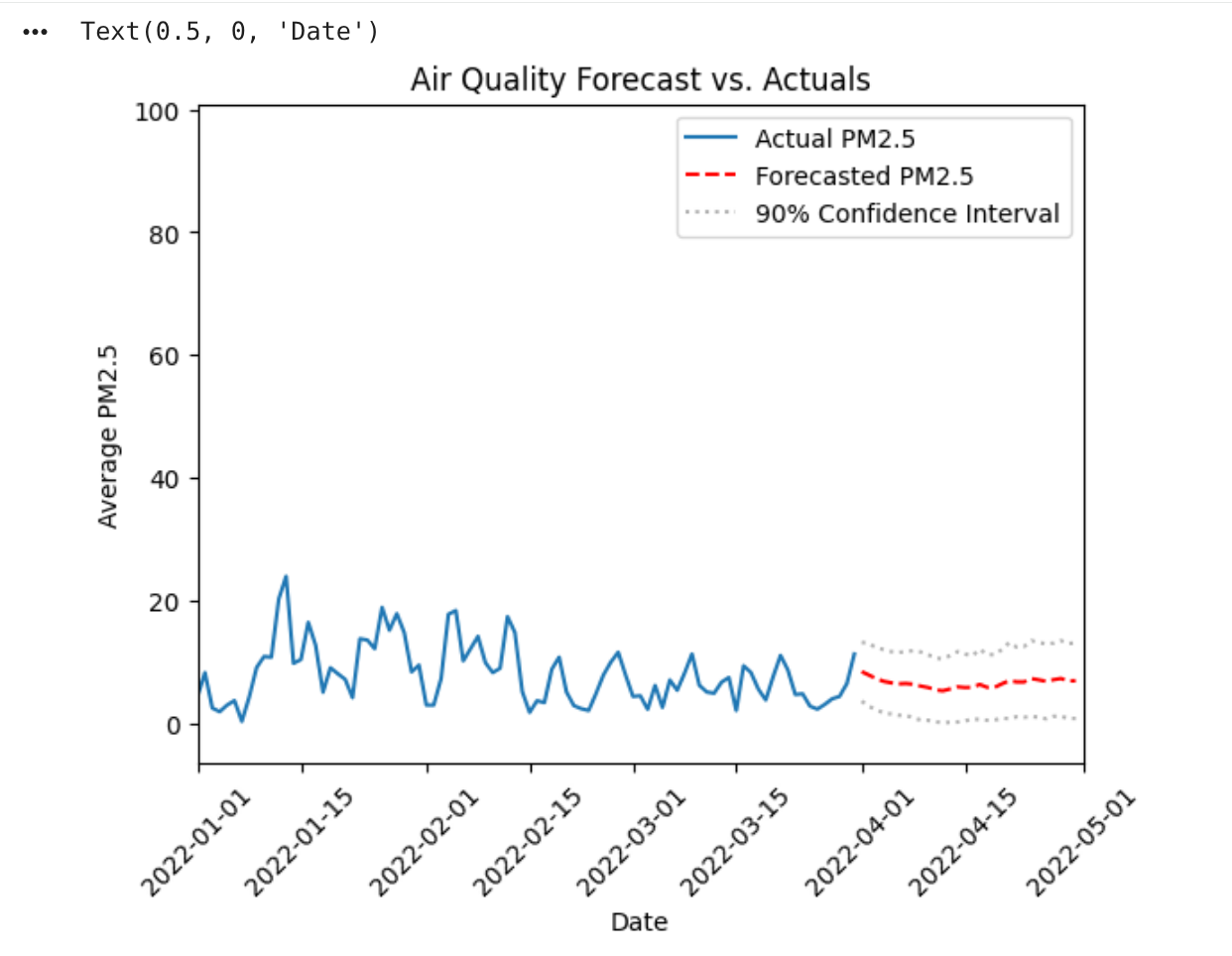
Python コードは次の処理を行います。
datetimeモジュールをインポートします。- まず過去のデータをプロットして軸を取得します。
- 予測データを同じ軸にプロットします。
- 信頼区間をプロットします。
この可視化は標準の Python プロットに似ていますが、
df_cleaned.plotは BigQuery DataFrames コマンドです。このコマンドは、データセット全体ではなく、グラフのレンダリングに必要なデータ(サンプル)のみを取得します。
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。
- Google Cloud コンソールで [リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
または、プロジェクトを保持してこのチュートリアルで使用したリソースを削除するには、次の操作を行います。
[Studio] ページに移動します。
左側のペインで、プロジェクトを開き、[ノートブック] をクリックします。
削除するノートブックの (アクションを開く)> [削除] をクリックします。
[ノートブックを削除] ダイアログで、[削除] をクリックして確定します。
次のステップ
ノートブック ギャラリーで他のサンプル ノートブック テンプレートを実行するには、以下をご覧ください。DataFrame の詳細については、以下をご覧ください。
BigQuery の生成 AI 関数と ML 関数の詳細については、生成 AI の概要をご覧ください。