
通过模型蒸馏优化 AI 函数费用
本文档介绍了如何在 BigQuery 中使用 托管 AI
函数的优化模式。与标准的逐行 LLM 推理相比,您可以使用优化模式处理包含数千甚至数十亿行的大规模数据集,同时显著减少大语言模型 (LLM) 词元消耗和查询延迟时间。此优化仅适用于 AI.IF 和 AI.CLASSIFY 函数。
为了更好地了解词元消耗情况,您可以在控制台中查看查询使用的词元数。Google Cloud 如需在运行查询之前估算此用量,请使用
AI.COUNT_TOKENS 函数。
以下示例演示了如何使用 AI.IF 函数
和优化模式来识别有关自然灾害的新闻报道,并使用 text-embedding-005
作为嵌入模型:
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
optimization_mode => 'MINIMIZE_COST' 实参可启用优化
模式。这是提供嵌入时的默认设置,因此您可以省略此实参。
在此示例中,嵌入是即时生成的。在实践中,我们 建议您实现嵌入,以便重复使用。
优化模式的工作原理
托管 AI 函数 AI.IF 和 AI.CLASSIFY 通常会针对数据集中的每一行调用
远程 LLM。当您使用优化模式时,BigQuery 会在查询执行期间自动训练轻量级蒸馏模型。
该过程的工作原理如下:
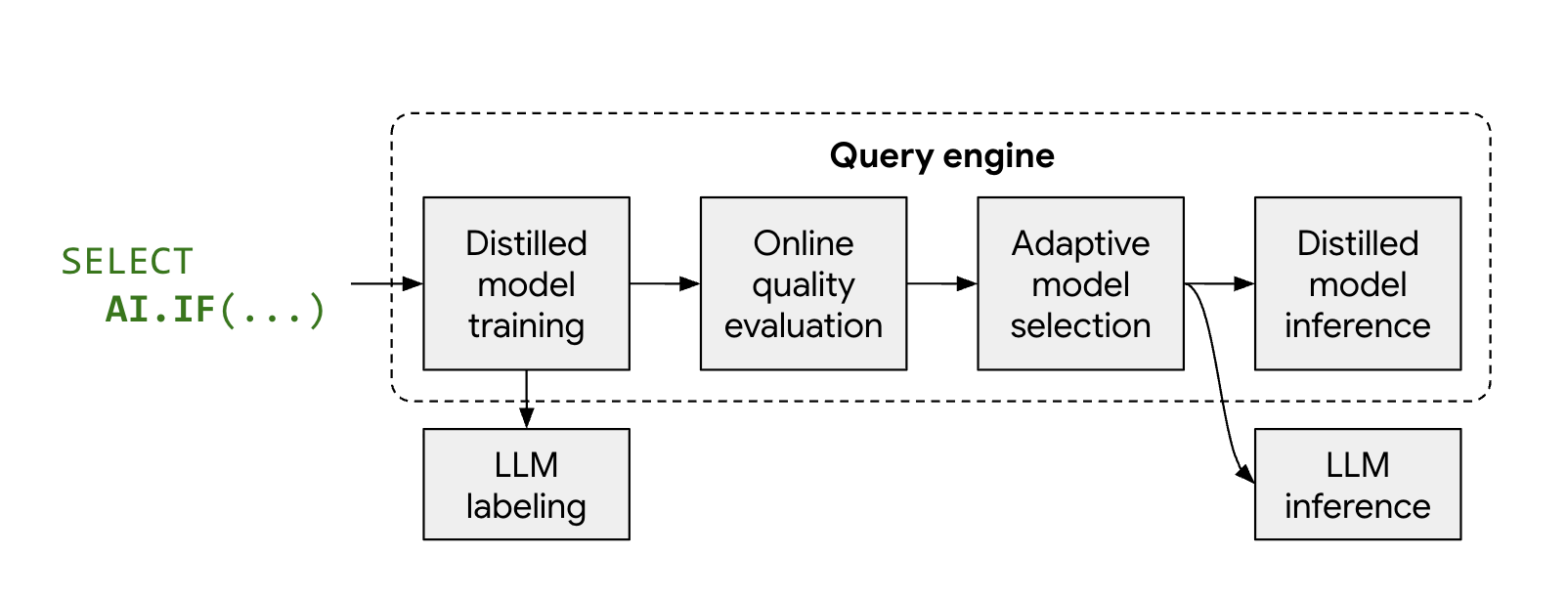
- 抽样和标签:BigQuery 会选择一小部分 代表性样本数据,并调用 Gemini 来提供 标签。
- 蒸馏模型训练:使用 LLM 标签和数据嵌入作为特征,及时训练本地蒸馏模型。
- 质量检查:BigQuery 会根据 LLM 的结果评估蒸馏模型的 准确率。默认情况下,如果蒸馏模型未能达到所需的质量阈值,查询将失败,并显示一条错误消息,说明模型被舍弃的原因。如果模型的质量可接受,BigQuery 仍可能会针对特定行回退到远程 LLM,以保持质量一致性,或者针对缺少有效嵌入的行回退到远程 LLM。
- 推理:蒸馏模型会处理大部分行, 从而显著减少 Gemini 调用次数。
限制
优化模式具有以下限制:
- 最少行数:AI 函数的输入必须包含 大约 3,000 行,以确保有足够的数据用于模型训练。
- 数据类型:对于引用多个列的提示,只有字符串 列支持优化。
- 多标签分类:优化模式不支持使用
output_mode => 'multi'的AI.CLASSIFY。 - 函数支持:只有
AI.IF和AI.CLASSIFY函数支持 优化模式;但是,如果将优化模式与AI.CLASSIFY搭配使用,当蒸馏模型质量不足时,查询可能会失败。 - 错误率:优化模式不支持
max_error_ratio实参。
准备工作
如需获得在 BigQuery 中运行托管 AI 函数所需的权限,请参阅为调用 Gemini Enterprise Agent Platform LLM 的生成式 AI 函数设置权限。
选择嵌入模型
如需使用优化模式,您必须计算 嵌入数据的嵌入,并将其提供给 AI 函数。如需让输入列具有关联的嵌入,所有行都必须具有一致的嵌入维度,并且由同一嵌入模型生成。
为了获得最佳的费用-质量和可伸缩性,我们建议您使用嵌入模型(例如
text-embedding-005或 Gemini 嵌入
,用于英语或多语言任务)计算
您数据的嵌入。对于多模态数据(文本和图片),请使用多模态嵌入模型,例如
multimodalembedding@001。
生成嵌入
您可以使用由 BigQuery 管理的自主生成功能计算数据的嵌入,也可以手动创建嵌入列。
以下部分介绍了如何将这两种方法与 AI.CLASSIFY 和 AI.IF 函数搭配使用。
自主嵌入生成
如果您使用 自主嵌入生成功能,
BigQuery 会在调用 AI.IF 或
AI.CLASSIFY 时自动使用嵌入。这是推荐的方法,但每张表只能有一个嵌入列。
以下示例使用 text-embedding-005 作为嵌入模型,创建一个具有自主生成的嵌入列的表,然后使用 AI.CLASSIFY 函数对数据进行分类:
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
手动列规范
如果您有现有的嵌入列,请在 AI.IF 或 AI.CLASSIFY 的 embeddings 实参中指定该列。您可以使用
AI.EMBED函数生成此列。
以下示例演示了如何使用 text-embedding-005 作为嵌入模型,创建一个具有嵌入列的表,然后在 AI.CLASSIFY 查询中使用该列:
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
如果您的提示引用了多个列,请在 embeddings 实参中提供列名称列表及其对应的嵌入。例如:
embeddings => [('body', body_embedding), ('title', title_embedding)]。
监控查询优化
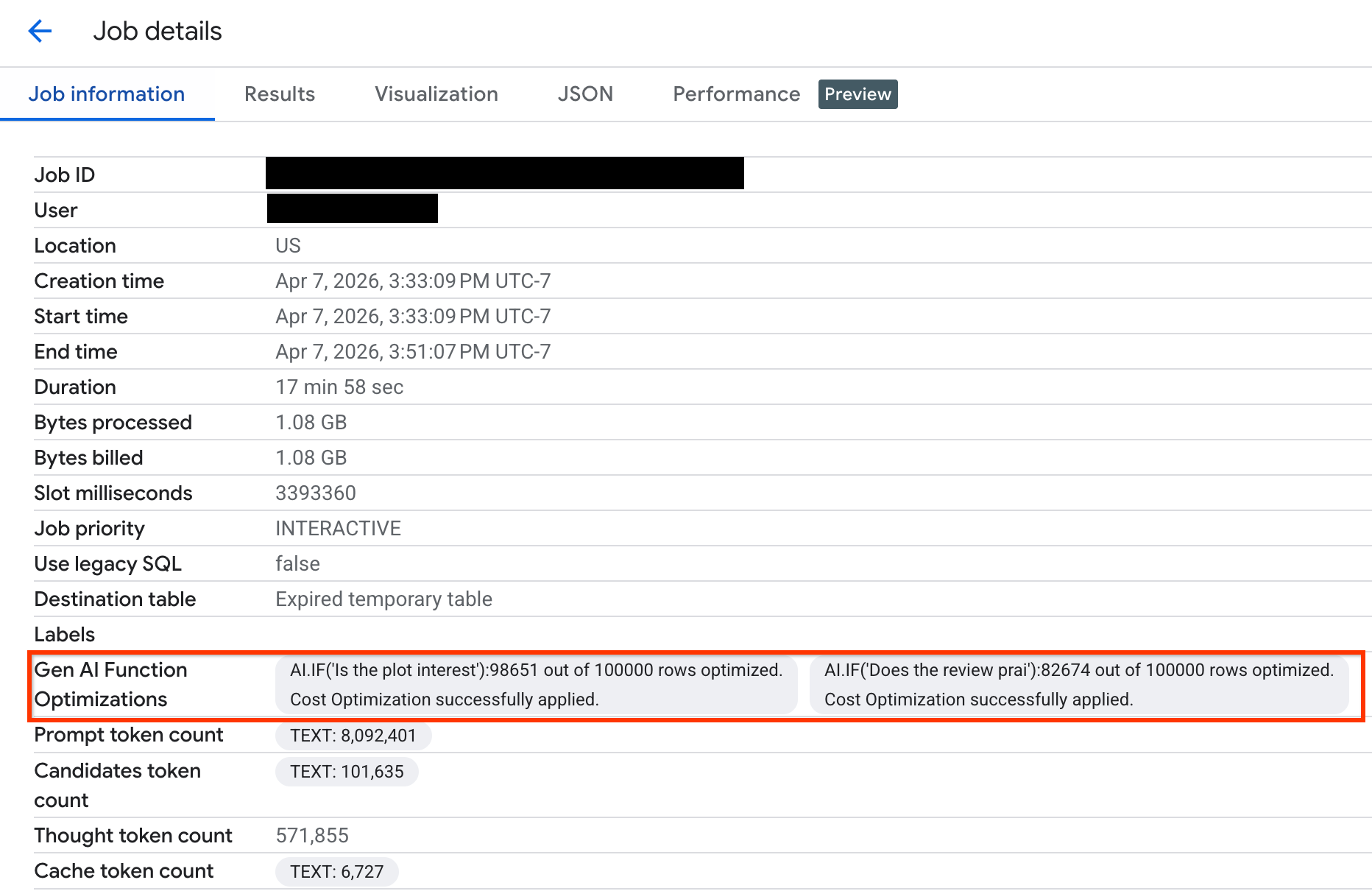
如需验证在查询执行期间优化了多少行,您可以在 控制台中或通过 API 查看执行统计信息: Google Cloud
控制台
如需查看优化了多少行,以及查看有关优化状态的系统消息,请执行以下操作:
在 Google Cloud 控制台中,前往 BigQuery 页面。
在导航菜单中,点击作业探索器 。
点击作业 ID 以查看作业详情 窗格。
点击作业信息 标签页,然后在 Gen AI 函数优化 字段中查看指标和状态。
API
检查作业元数据的 GenAIFunctionStats 对象中的 FunctionGenAiCostOptimizationStats。此对象包含通过优化后的工作流推理的行数,以及提供有关优化状态的洞见的系统生成的消息。
问题排查
以下部分介绍了如何诊断和解决使用优化模式时的常见问题。
数据大小过小
问题:数据不足,无法进行模型训练。您可能会看到以下
错误消息:Fail to apply cost optimization because the data size is too
small.
解决方案:将输入大小增加到大约 3,000 行,并验证 是否已为所有行正确生成有效的嵌入。
某些类别的样本很少或没有样本
问题:在
抽样阶段,某些类别的样本数量不足,导致无法进行模型训练。您可能会看到以下
错误消息:Fail to apply cost optimization because some classes have
few or no samples.
解决方案:
- 从
AI.CLASSIFY函数调用中移除稀有或空类别。 - 将稀有类别分组到更广泛的类别中,以增加样本大小。您可以使用
OTHER类别对未包含在更具体类别中的项进行分组。但是,如果您的类别列表已完整,请勿添加OTHER,因为此术语含义模糊,可能会造成混淆。
嵌入的维度不一致
问题:各行之间的嵌入维度不一致。您
可能会看到以下错误消息:Fail to apply cost optimization
because the embeddings have inconsistent dimensions.
解决方案:验证嵌入是否由同一模型生成,并且 具有相同的嵌入向量长度。您可以使用类似于以下内容的 SQL 查询来检查列中的嵌入是否具有相同的长度:
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
提示的复杂性过高
问题:蒸馏模型无法达到较高的准确率阈值。您
可能会看到以下错误消息:Fail to apply cost optimization
because the prompt complexity is too high.
解决方案:
使用一组构成一个分区的类别。确保类别之间的重叠最少,并涵盖所有可能的输入。
- 避免重叠类别,即输入可能同时属于多个类别。例如,避免使用
['terrible', 'bad', 'okay', 'good', 'excellent']等类别。 - 避免出现没有类别适用的情况。例如,类别列表
不涵盖表达
赞扬的评价。
['bad', 'average'] 提供类别说明,以指导 LLM 解决类别之间的歧义。例如:
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- 避免重叠类别,即输入可能同时属于多个类别。例如,避免使用
尝试使用更高级的嵌入模型,例如
text-embedding-005或multimodalembedding。如需获得更多调试帮助,请与 bqml-feedback@google.com 联系。
LLM 处理的行数超出预期
问题:查询执行统计信息显示,远程 LLM 处理的行数超出预期,而不是蒸馏模型处理的行数。这可能是由于以下原因造成的:
- 蒸馏模型已成功训练,但某些行缺少嵌入。这些行由远程 LLM 处理。
- 蒸馏模型无法应用于每一行,必须回退到远程 LLM 以保持质量一致性。
解决方案:验证是否已为数据中的所有 行正确生成有效的嵌入。如果问题仍然存在,请与 bqml-feedback@google.com 联系以进行调试。
未检测到自主嵌入列
问题:BigQuery 无法检测到自主嵌入 列。如果您的脚本使用临时表,并且对原始表的引用丢失,则可能会发生这种情况。
解决方案:使用 embeddings 参数显式传递自主
嵌入列(例如 embeddings => content_embedding.result),这会
触发费用优化。
后续步骤
- 详细了解 BigQuery 中的生成式 AI。
- 参阅
AI.IF函数 文档。 - 参阅
AI.CLASSIFY函数 文档。