
モデル蒸留で AI 関数の費用を最適化する
このドキュメントでは、BigQuery のマネージド AI
関数の最適化モードを使用する方法について説明します。最適化モードを使用すると、標準の行ごとの LLM 推論と比較して、大規模言語モデル(LLM)のトークン消費量とクエリ レイテンシを大幅に削減して、数千行、さらには数十億行を含む大規模なデータセットを処理できます。この最適化は、AI.IF 関数と AI.CLASSIFY 関数にのみ適用されます。
トークンの消費量を把握するには、コンソールでクエリで使用されたトークンの数を確認します。Google Cloud クエリを実行する前にこの使用量を推定するには、
AI.COUNT_TOKENS 関数を使用します。
次の例は、最適化モードで AI.IF 関数
を使用して、自然災害に関するニュース記事を特定する方法を示しています。text-embedding-005
SELECT
title,
body,
AI.IF(
('The following news story is about a natural disaster: ', body),
embeddings => AI.EMBED(body, endpoint => 'text-embedding-005', task_type => 'CLASSIFICATION').result,
-- Optional, 'MINIMIZE_COST' is the default when embeddings are provided.
optimization_mode => 'MINIMIZE_COST'
) AS is_natural_disaster
FROM
`bigquery-public-data.bbc_news.fulltext`;
optimization_mode => 'MINIMIZE_COST' 引数を指定すると、最適化
モードが有効になります。エンベディングが指定されている場合、これはデフォルトの設定であるため、この引数は省略できます。
この例では、エンベディングはオンザフライで生成されます。実際には、エンベディングをマテリアライズして再利用できるようにすることをおすすめします。
最適化モードの仕組み
マネージド AI 関数 AI.IF と AI.CLASSIFY は通常、データセットの各行に対して
リモート LLM を呼び出します。最適化モードを使用すると、BigQuery はクエリの実行中に軽量の蒸留モデルを自動的にトレーニングします。
このプロセスは次のように動作します。
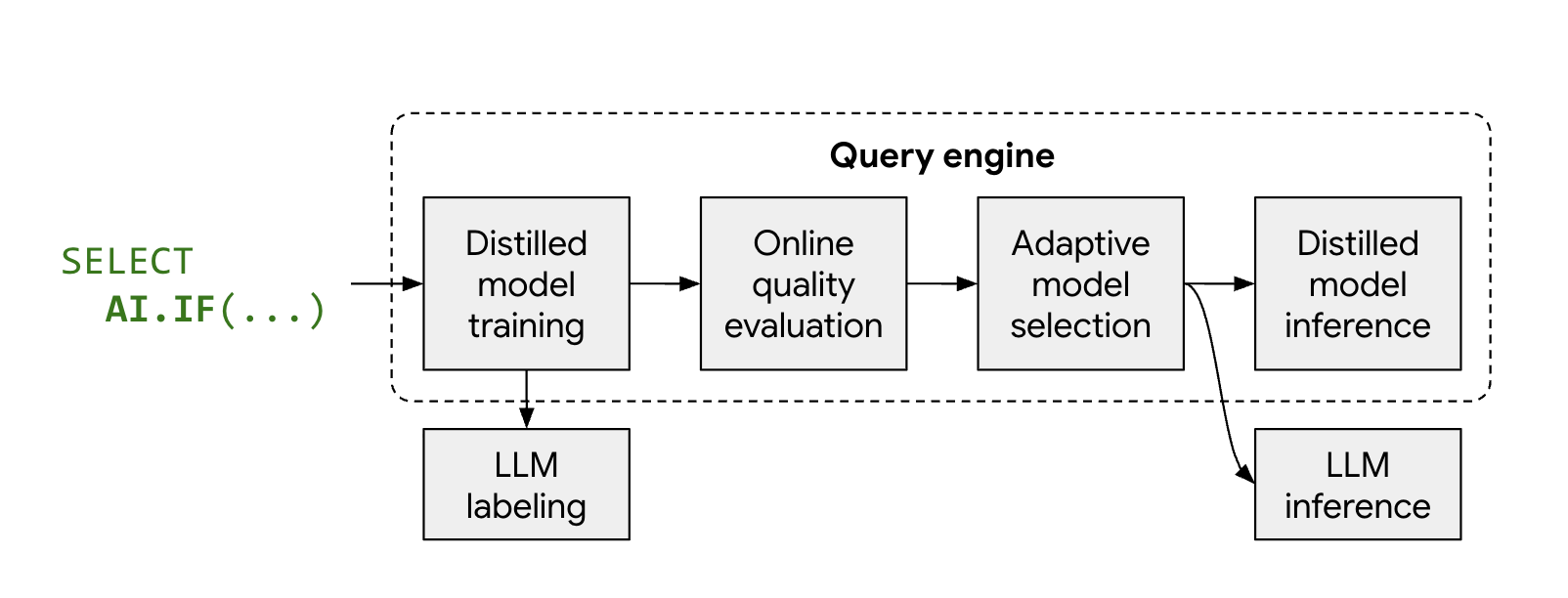
- サンプリングとラベリング: BigQuery はデータの代表的なサンプルをいくつか選択し、Gemini を呼び出してラベルを提供します。
- 蒸留モデルのトレーニング: LLM ラベルとデータ エンベディングを特徴として使用して、ローカルの蒸留モデルがジャストインタイムでトレーニングされます。
- 品質チェック: BigQuery は、蒸留モデルの 精度を LLM の結果と比較して評価します。デフォルトでは、蒸留モデルが必要な品質しきい値を満たしていない場合、モデルが破棄された理由を示すエラーでクエリが失敗します。モデルの品質が許容できる場合でも、BigQuery は、一貫した品質を維持するため、または有効なエンベディングがない行に対して、特定のリモート LLM にフォールバックすることがあります。
- 推論: 蒸留モデルはほとんどの行を処理するため、 Gemini の呼び出し回数が大幅に削減されます。
制限事項
最適化モードには次の制限があります。
- 最小行数: モデルのトレーニングに十分なデータを確保するには、AI 関数への入力に 約 3,000 行を含める必要があります。
- データ型: 複数の列を参照するプロンプトの場合、最適化でサポートされるのは文字列 列のみです。
- マルチラベル分類:
AI.CLASSIFYとoutput_mode => 'multi'は最適化モードではサポートされていません。 - 関数のサポート: 最適化モードをサポートしているのは
AI.IF関数とAI.CLASSIFY関数のみです。ただし、AI.CLASSIFYで最適化モードを使用する場合、蒸留モデルの品質が不十分だとクエリが失敗する可能性があります。 - エラー率:
max_error_ratio引数は 最適化モードではサポートされていません。
始める前に
BigQuery でマネージド AI 関数を実行するために必要な権限を取得するには、Gemini Enterprise Agent Platform LLM を呼び出す生成 AI 関数の権限を設定するをご覧ください。
エンベディング モデルを選択する
最適化モードを使用するには、データの エンベディングを計算して AI 関数に提供する必要があります 。入力列に関連付けられたエンベディングを使用するには、すべての行のエンベディング ディメンションが同じで、同じエンベディング モデルで生成されている必要があります。
費用対効果とスケーラビリティを最大限に高めるには、
エンベディング モデルを使用してデータのエンベディングを計算することをおすすめします。たとえば、
text-embedding-005 や英語または多言語タスク用の Gemini エンベディングなどです。
マルチモーダル データ(テキストと画像)の場合は、
などの
マルチモーダル エンベディング モデルを使用します。multimodalembedding@001
エンベディングを生成する
データのエンベディングは、BigQuery で管理される自律型生成を使用して計算することも、エンベディング列を手動で作成することもできます。
以降のセクションでは、AI.CLASSIFY 関数と AI.IF 関数で両方の方法を使用する方法について説明します。
自律型エンベディング生成
自律型エンベディング生成を使用する場合、
または
が呼び出されると、BigQuery はエンベディングを自動的に使用します。AI.IFAI.CLASSIFYこの方法をおすすめしますが、テーブルごとに 1 つのエンベディング列に制限されます。
次の例では、text-embedding-005 をエンベディング モデルとして使用して、自律的に生成されたエンベディング列を含むテーブルを作成し、AI.CLASSIFY 関数を使用してデータを分類します。
-- Create a table with an autonomously generated embedding column
CREATE TABLE my_dataset.bbc_news (
title STRING,
body STRING,
body_embedding STRUCT<result ARRAY<FLOAT64>, status STRING>
GENERATED ALWAYS AS (
AI.EMBED(
body,
connection_id => '<my_connection_id>',
task_type => 'CLASSIFICATION',
endpoint => 'text-embedding-005')
) STORED
OPTIONS(asynchronous = TRUE)
);
-- Insert data into the table
INSERT INTO my_dataset.bbc_news (title, body)
SELECT title, body FROM `bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query.
-- Wait for the background job to finish generating embeddings before running.
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other']
) AS category
FROM
my_dataset.bbc_news;
列を手動で指定する
既存のエンベディング列がある場合は、AI.IF または AI.CLASSIFY の embeddings 引数で指定します。これは、
AI.EMBED 関数を使用して生成できます。
次の例は、text-embedding-005 をエンベディング モデルとして使用してエンベディング列を含むテーブルを作成し、その列を AI.CLASSIFY クエリで使用する方法を示しています。
-- Create a table with an embedding column
CREATE TABLE my_dataset.bbc_news AS
SELECT
title,
body,
AI.EMBED(
body,
endpoint => 'text-embedding-005',
task_type => 'CLASSIFICATION'
).result AS body_embedding
FROM
`bigquery-public-data.bbc_news.fulltext`;
-- Run the optimized query
SELECT
title,
body,
AI.CLASSIFY(
body,
categories => ['tech', 'sport', 'business', 'other'],
embeddings => body_embedding,
) AS category
FROM
my_dataset.bbc_news;
プロンプトが複数の列を参照する場合は、embeddings 引数に列名とその対応するエンベディングのリストを指定します。例:
embeddings => [('body', body_embedding), ('title', title_embedding)]。
クエリの最適化をモニタリングする
クエリの実行中に最適化された行数を確認するには、 コンソールまたは API で Google Cloud 実行統計情報を確認します。
コンソール
最適化された行数と最適化ステータスに関するシステム メッセージを確認するには、次の操作を行います。
コンソールで、[BigQuery] ページに移動します。 Google Cloud
ナビゲーション メニューで [ジョブ エクスプローラ] をクリックします。
ジョブ ID をクリックして、[ジョブの詳細] パネルを表示します。
[ジョブ情報] タブをクリックし、[Gen AI 関数の最適化] フィールドの指標とステータスを表示します。
![[求人情報] タブの [生成 AI 関数の最適化] フィールド](https://docs.cloud.google.com/static/bigquery/images/gen-ai-function-optimizations-field.png?hl=ja)
API
ジョブ メタデータの GenAIFunctionStats オブジェクトで FunctionGenAiCostOptimizationStats を確認します。このオブジェクトには、最適化されたワークフローで推論された行数と、最適化の状態に関する分析情報を提供するシステム生成メッセージが含まれています。
トラブルシューティング
以降のセクションでは、最適化モードの使用に関する一般的な問題を診断して解決する方法について説明します。
データサイズが小さすぎる
問題: モデルのトレーニングに十分なデータがありません。次の
エラー メッセージが表示されることがあります: Fail to apply cost optimization because the data size is too
small.
解決策: 入力のサイズを約 3,000 行に増やし、 すべての行に対して有効なエンベディングが適切に生成されていることを確認します。
一部のクラスのサンプルが少ないか、ない
問題: サンプリング フェーズで特定のカテゴリのサンプル数が不足しているため、モデルのトレーニングができません。次の
エラー メッセージが表示されることがあります: Fail to apply cost optimization because some classes have
few or no samples.
ソリューション:
AI.CLASSIFY関数呼び出しから、まれなカテゴリまたは空のカテゴリを削除します。- まれなカテゴリをより広範なカテゴリにグループ化して、サンプルサイズを増やします。
OTHERカテゴリを使用して、より具体的なカテゴリでカバーされていないアイテムをグループ化できます。ただし、カテゴリのリストがすでに完成している場合は、OTHERを追加しないでください。この用語は曖昧で、混乱を招く可能性があります。
エンベディングのディメンションが一貫していない
問題: 行間でエンベディング ディメンションに不整合があります。You
might see the following error message: Fail to apply cost optimization
because the embeddings have inconsistent dimensions. というエラー メッセージが表示されることがあります。
ソリューション: エンベディングが同じモデルで生成され、 エンベディング ベクトルの長さが同じであることを確認します。次のような SQL クエリを使用して、列のエンベディングの長さが同じであることを確認できます。
SELECT ARRAY_LENGTH(body_embedding.result), COUNT(*)
FROM `PROJECT_ID.DATASET.TABLE_NAME`
GROUP BY 1;
プロンプトの複雑さが高すぎる
問題: 蒸留モデルが高い精度しきい値を達成できません。You
might see the following error message: Fail to apply cost optimization
because the prompt complexity is too high. というエラー メッセージが表示されることがあります。
ソリューション:
パーティションを形成するカテゴリのセットを使用します。カテゴリの重複を最小限に抑え、考えられるすべての入力をカバーするようにします。
- 入力が複数のカテゴリに同時に属する可能性があるカテゴリの重複は避けてください。たとえば、
['terrible', 'bad', 'okay', 'good', 'excellent']のようなカテゴリは避けてください。 - カテゴリが適用されないギャップは避けてください。たとえば、
カテゴリ
['bad', 'average']のリストは、 称賛を表すレビューをカバーしていません。 カテゴリの説明を提供して、LLM がカテゴリ間の曖昧さを解消できるようにします。次に例を示します。
AI.CLASSIFY( review, categories => [ ('terrible', 'Review where customer was not happy and the message indicates they will never try this product again'), ('bad', 'Review where customer was not happy but suggested improvements to the product'), ('okay', 'Review where customer was neutral about the product. Short reviews qualify for this category'), ('good', 'Review where customers were happy using this product but had minor critiques'), ('excellent', 'Review where customers were very happy using this product and will recommend others to try it too')], embeddings => review_embeddings)
- 入力が複数のカテゴリに同時に属する可能性があるカテゴリの重複は避けてください。たとえば、
text-embedding-005やmultimodalembeddingなどの高度なエンベディング モデルを試してください。デバッグのサポートが必要な場合は、bqml-feedback@google.com まで お問い合わせください。
LLM で処理される行数が想定外に多い
問題: クエリ実行統計情報に、蒸留モデルではなくリモート LLM によって処理された行数が想定外に多いことが示されています。これは、次の理由が考えられます。
- 蒸留モデルは正常にトレーニングされましたが、一部の行でエンベディングが欠落していました。これらの行はリモート LLM によって処理されます。
- 蒸留モデルを各行に適用できず、一貫した品質を維持するためにリモート LLM にフォールバックする必要がありました。
解決策: エンベディングが適切に生成され、データのすべての 行で有効であることを確認します。問題が解決しない場合は、デバッグについて bqml-feedback@google.comまでお問い合わせください。
自律型エンベディング列が検出されない
問題: BigQuery が自律型エンベディング 列を検出できません。これは、スクリプトで一時テーブルを使用し、元のテーブルへの参照が失われた場合に発生する可能性があります。
ソリューション: embeddings パラメータを使用して、自律型エンベディング列を明示的に渡します(embeddings => content_embedding.result など)。これにより、費用の最適化がトリガーされます。
次のステップ
- BigQuery の生成 AI の詳細を確認する。
AI.IF関数 のドキュメントを参照する。AI.CLASSIFY関数のドキュメントを参照する。