
このチュートリアルでは、Colab Enterprise データ サイエンス エージェントで自然言語プロンプトを使用して機械学習(ML)モデルを構築する方法について説明します。
このチュートリアルでは、アイオワ州の酒類小売販売の一般公開データセットを使用して、酒類販売を予測する ML モデルを構築します。AI を活用したエージェントを使用すると、自然言語プロンプトを使用して、ノートブック内で直接コードの作成、説明、トラブルシューティングを行い、データ サイエンス ワークフローを加速できます。
このチュートリアルは、データ使用者を対象としています。
目標
このチュートリアルでは、データ サイエンス エージェントを使用して次のタスクを実行する方法を学習します。
- アイオワ州の酒類小売販売の一般公開データセットの探索的データ分析(EDA)を実行して、データ分布を把握し、欠損値を確認して、データ全体のデータ品質を検証します。
- すべての商品の中で最も多くのアルコールを販売した店舗を見つけます。
- BigQuery ML を使用して、酒類の販売を予測するモデルを構築、トレーニング、評価します。
- 重要な分析情報とモデルのパフォーマンスを生成して要約します。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
- Google Cloud アカウントにログインします。 Google Cloudを初めて使用する場合は、 アカウントを作成して、実際のシナリオでの Google プロダクトのパフォーマンスを評価してください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分を差し上げます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
BigQuery、Gemini for Google Cloud、Dataform、Compute Engine の各 API を有効にします。
API を有効にするために必要なロール
API を有効にするには、
serviceusage.services.enable権限を含む Service Usage 管理者 IAM ロール(roles/serviceusage.serviceUsageAdmin)が必要です。詳しくは、ロールを付与する方法をご覧ください。新しいプロジェクトでは、BigQuery API が自動的に有効になります。
必要なロール
新しいプロジェクトを作成した場合は、このチュートリアルを完了するために必要なすべての権限が付与されています。既存のプロジェクトを使用する場合は、次のロールを付与するよう管理者に依頼してください。
ノートブックを作成して実行する権限
ノートブックの作成と実行に必要な権限を取得するには、プロジェクトに対する BigQuery Studio ユーザー (roles/bigquery.studioUser)IAM ロールを付与するよう管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
ノートブックの作成と実行に必要な権限を確認するには、ノートブックを作成するページのセットアップ手順をご覧ください。
BigQuery Identity and Access Management(IAM)の詳細については、IAM によるアクセス制御をご覧ください。
Colab Enterprise ノートブックを作成してランタイムに接続する
Colab Enterprise ノートブックは、Dataform が提供する BigQuery Studio コードアセットです。ノートブックを使用すると、SQL、Python などの一般的なパッケージと API を使用して、分析と ML ワークフローを完了できます。
新しいノートブックを作成してデフォルトのランタイムに接続する手順は次のとおりです。
[BigQuery] ページに移動します。
左側のペインで、プロジェクトを開き、[ノートブック] をクリックします。
[新しいノートブック>空のノートブック] をクリックします。
[保存] をクリックします。
新しいノートブックを表示するには、[ノートブック] タブをクリックします。[更新] 更新 をクリックしなければならない場合があります。
無題のノートブックで、more_vert [アクションを開く] をクリックし、[名前を変更] を選択します。
[ノートブック名] に「
predict_liquor_sales」と入力し、[名前を変更] をクリックします。[
predict_liquor_sales] タブをクリックします。ノートブックのツールバーで [接続] をクリックして、ノートブックをデフォルトのランタイム環境に接続します。
データ サイエンス エージェントを使用してデータを分析する
データ サイエンス エージェントは、ノートブック内で直接コードの作成、説明、トラブルシューティングを行うことができる Gemini を活用したアシスタントです。探索的データ分析から ML 予測、予測の生成まで、次のようなタスクを支援します。
- プランの生成。データ サイエンスの問題を解決するためのステップバイステップのプランを作成します。
- データの探索とクリーニング。欠損値と外れ値を特定し、分布を可視化します。
- 特徴量エンジニアリング。カテゴリ特徴量を変換して新しい特徴量を作成する。
- モデルのトレーニングと評価。線形回帰やランダム フォレストなどのモデルをトレーニングし、パフォーマンスを比較します。
このチュートリアルでは、データ サイエンス エージェントを使用して、アイオワ州の酒類小売販売の一般公開データセットのデータを分析し、酒類販売を予測するモデルを作成します。
データ サイエンス エージェントを使用してデータを分析する手順は次のとおりです。
predict_liquor_salesノートブックで、Gemini とのチャット ウィンドウが開いていない場合は、spark(Gemini in Colab を切り替える)をクリックして、チャット ダイアログを開きます。チャット インターフェースに次のプロンプトを入力します。
Analyze the liquor sales data from bigquery-public-data.iowa_liquor_sales.sales by performing exploratory data analysis. Find the stores that sold the most gallons of alcohol across all products. Then, create a model that predicts liquor sales by store by using BigQuery ML. Visualize the results, evaluate the model, summarize the model's performance, and provide any key insights.モデルが Gemini 3.0 Flash に設定されていることを確認します。
[送信] をクリックします。
エージェントによって生成されたプランを確認します。プランは次のようになります。
「アイオワ州の酒類販売データのリクエストを分析し、戦略計画を作成しました。データは BigQuery に保存され、BigQuery ML を使用するように指定されているため、データ探索から始め、パフォーマンスの高い店舗を特定してから、売上を予測する回帰モデルを構築します。手順は次のとおりです。
- データ探索とプロファイリング: 「bigquery-public-data.iowa_liquor_sales.sales」テーブルの初期探索を行い、データ分布を把握し、欠損値を確認し、店舗情報、販売量、売上高などのキー列のデータ品質を確認します。
- 販売量で上位の店舗を特定する: すべての商品について、各店舗で販売されたアルコールの合計ガロン数を集計し、パフォーマンスの高い店舗を特定します。
- データ準備: 店舗別の酒類販売額を集計し、予測モデルに関連する特徴量を選択して、トレーニング データを準備します。
- モデル開発: BigQuery ML を使用して回帰モデルをトレーニングし、各店舗の酒類販売額を予測します。
- モデル評価: 標準の回帰指標を使用して、トレーニング済みモデルのパフォーマンスを評価します。
- モデル予測: トレーニング済みモデルを使用して、酒類の販売予測を生成します。
- 可視化: 予測された酒類の売上高と実際の値を比較する散布図を作成し、モデルの精度を視覚的に評価します。
- タスクを完了する: モデルのパフォーマンスを要約し、店舗販売に関する重要な分析情報を提供して、分析を締めくくります。」
プランを確認したら、[承認して実行] をクリックします。エージェントは、データの探索とプロファイリングという最初のサブタスクを生成します。エージェントは、コードを確認して承認するまで一時停止します。エージェントがユーザーの入力を待っている場合、生成されたセルは緑色の背景でレンダリングされます。
生成されたコードセルと、エージェントが提供した推論を確認します。
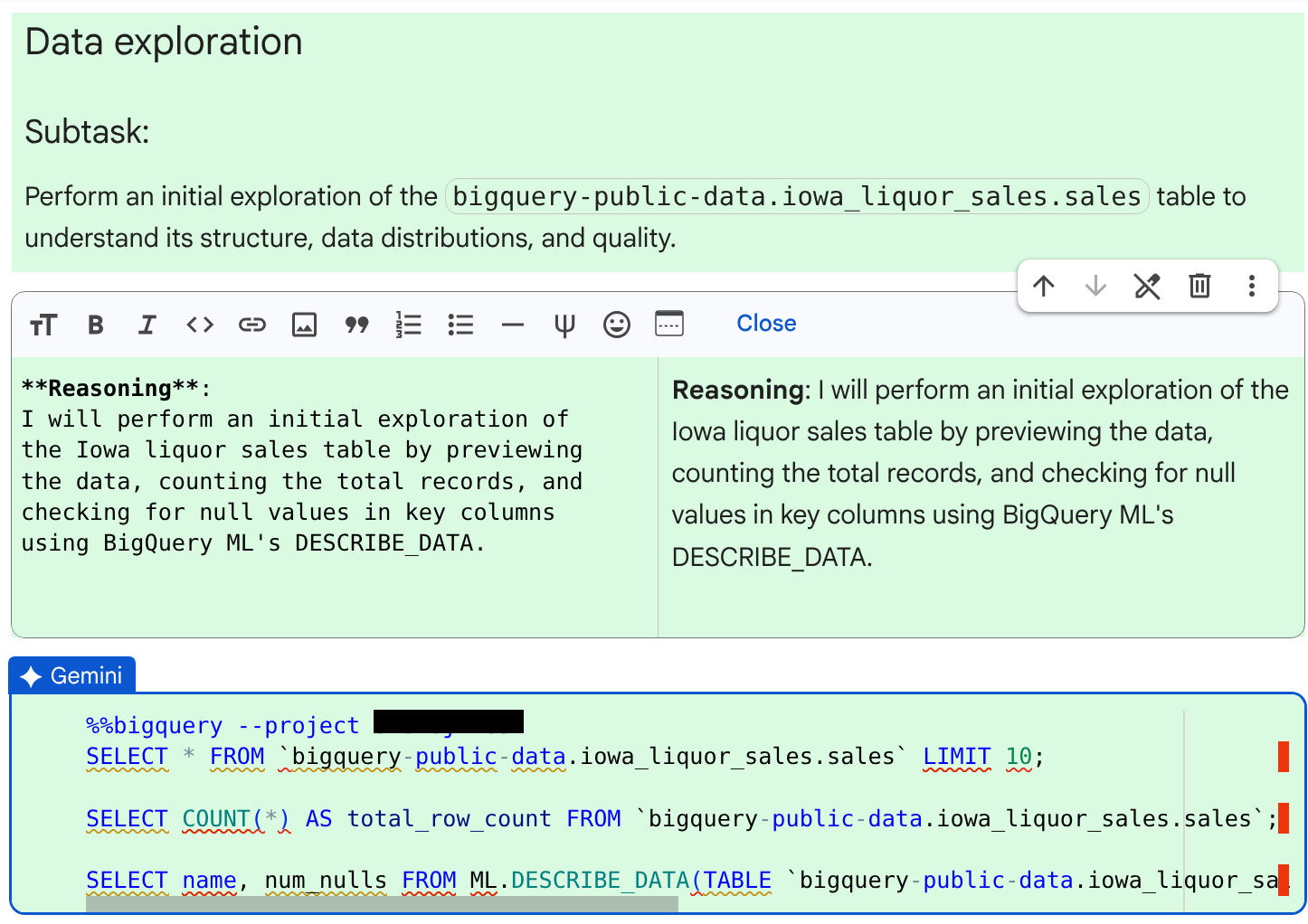
[同意して実行] をクリックします。エージェントがアプローチで問題に遭遇すると、問題の修正方法に関する推論が示され、変更されたコードを受け入れるよう求められます。
コードセルの出力を確認します。
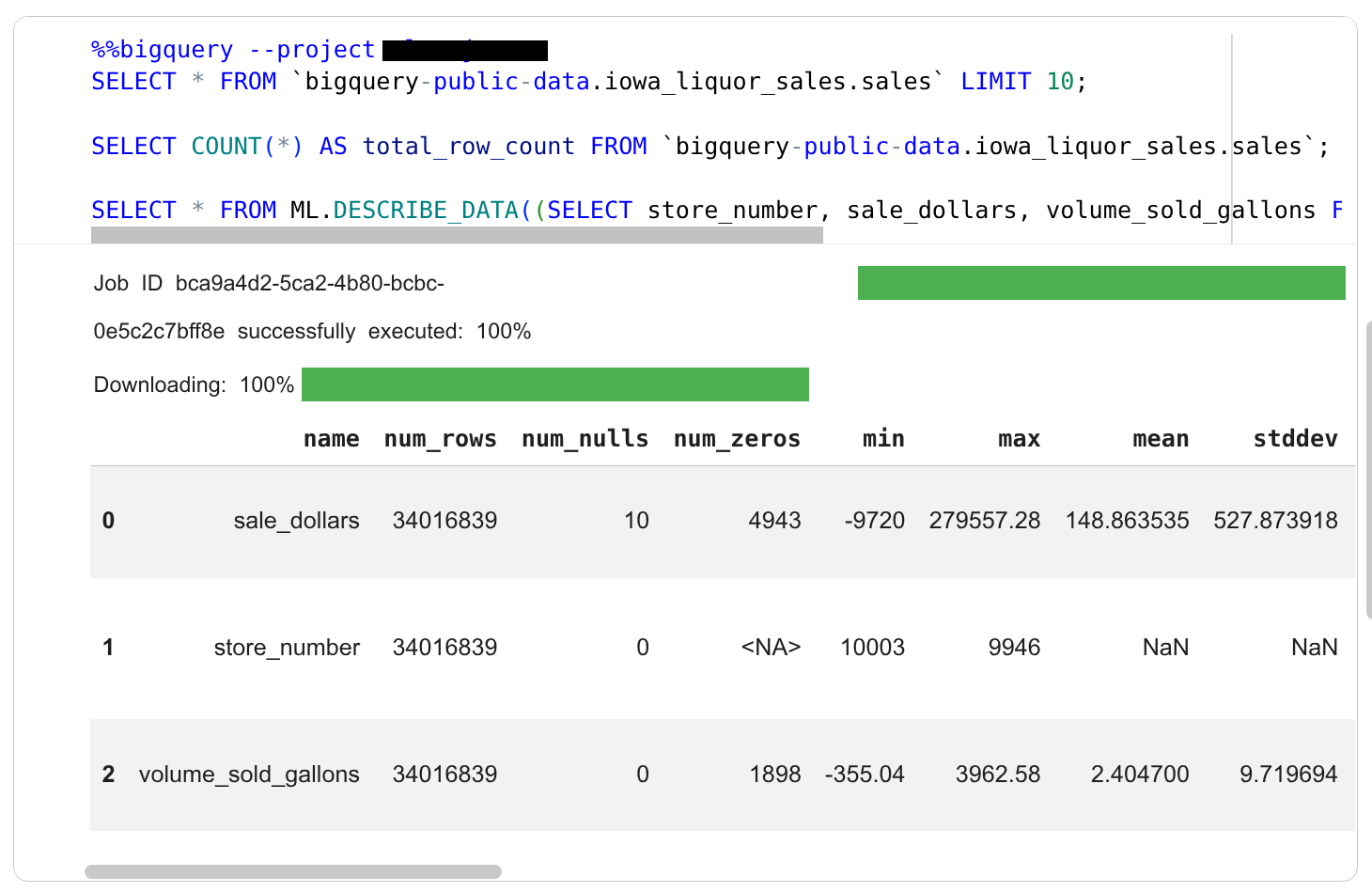
結果の下に、エージェントは新しいセルを作成して、次のサブタスク(酒類の売上が最も高い店舗を見つける)を完了します。
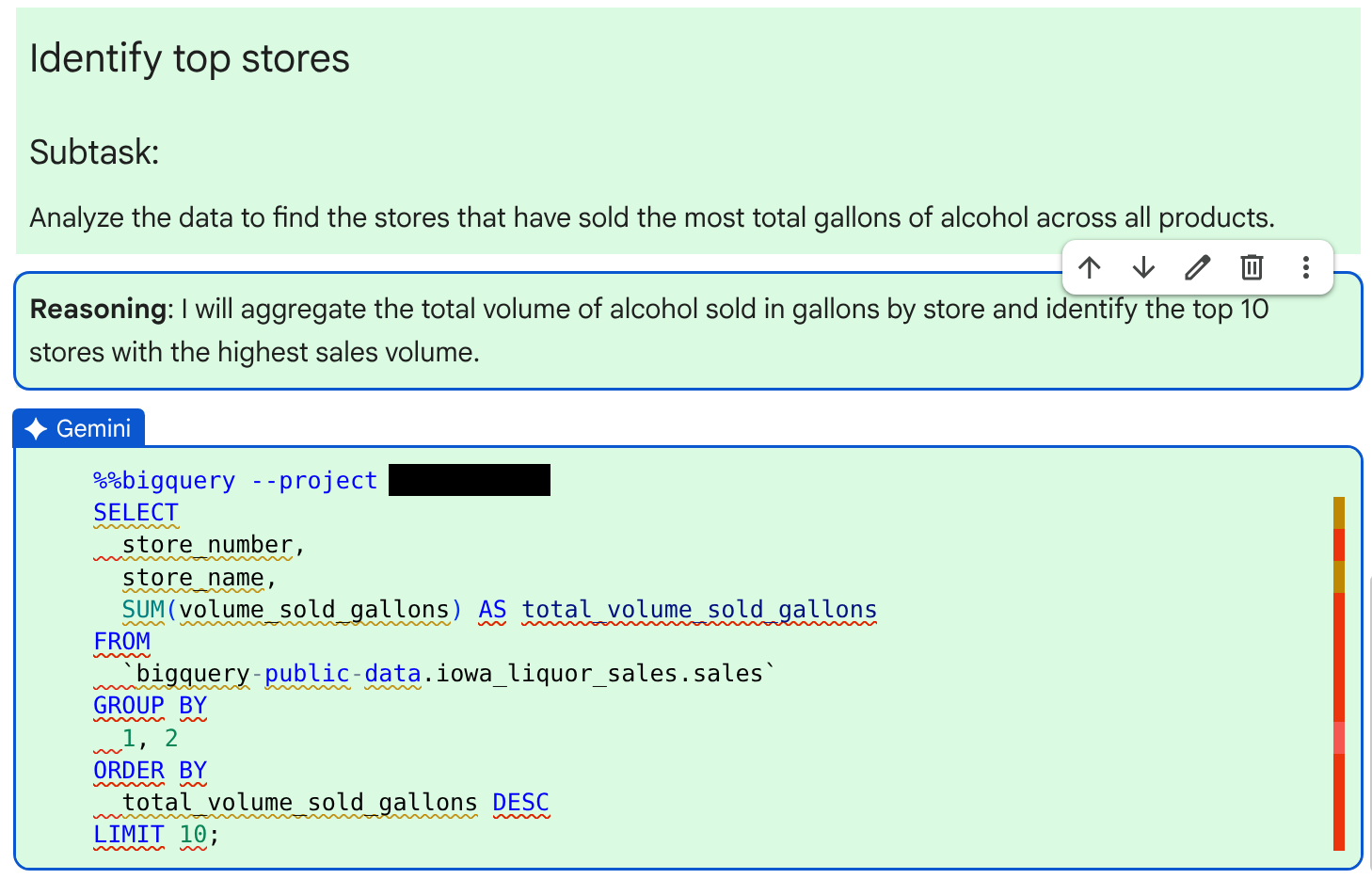
販売されたアルコールのガロン数で上位の店舗のデータをクエリする生成された SQL コードを確認します。エージェントの推論を確認するには、コードの上にある [Reasoning] テキスト セルを表示します。コードが正しいことを確認したら、[承認して実行] をクリックします。
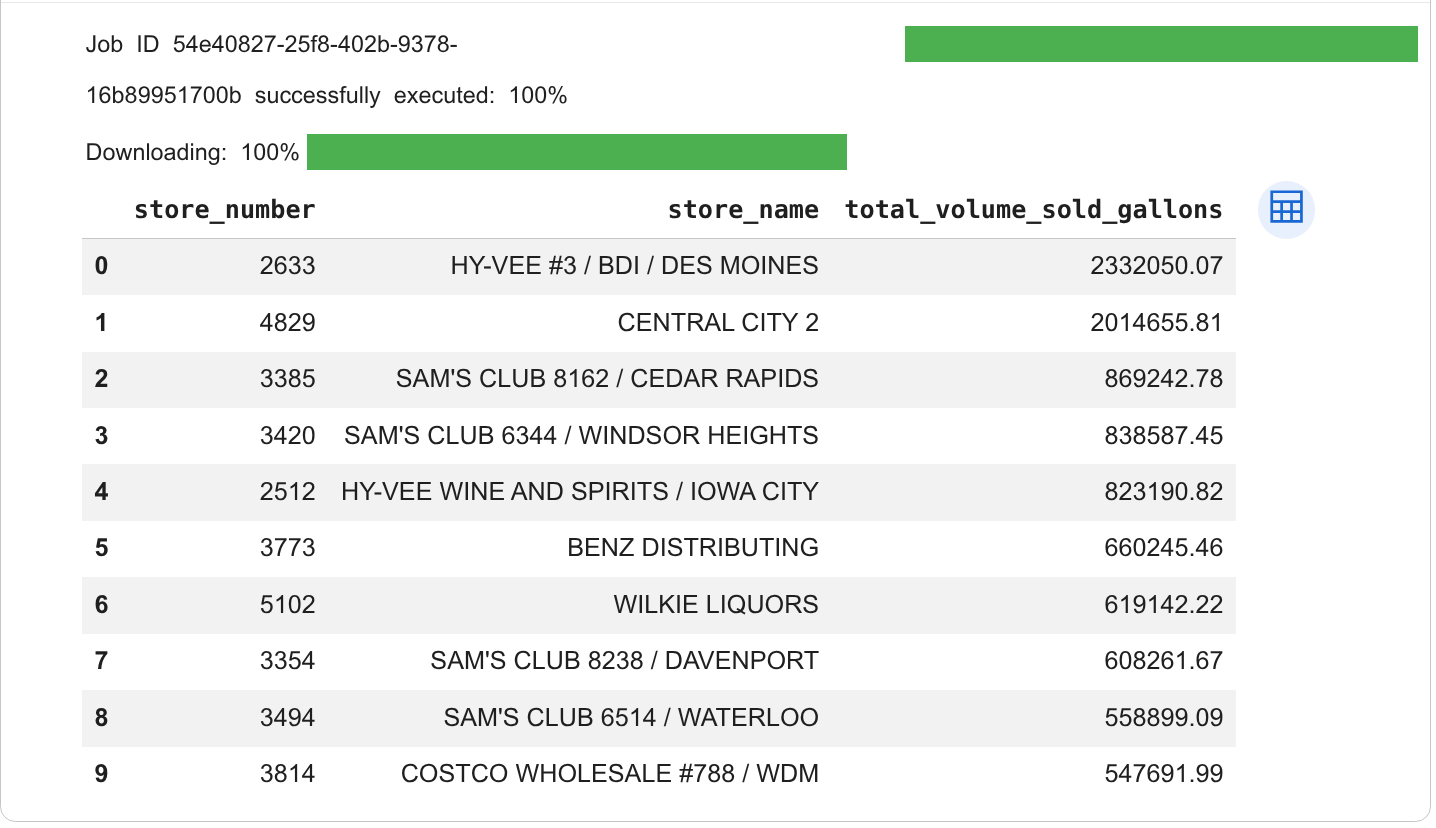
セルの出力でクエリ結果を確認します。結果は次のようになります。
次のサブタスク(モデル トレーニング用のデータの準備)のためにエージェントが生成したコードと推論を確認します。
SQL コードが正しいことを確認したら、[Accept and run] をクリックします。
コードセルの出力を確認します。次のようなメッセージが表示されます。
JOB ID 123456 successfully executed.次のサブタスク(回帰モデルのトレーニング)について、エージェントが生成したコードと推論を確認します。
コードと理由を確認したら、[Accept and run] をクリックします。
コードセルの出力を確認します。次のようなメッセージが表示されます。
JOB ID 123456 successfully executed.エージェントが次のサブタスク(モデル評価)用に生成したコードと推論を確認します。
コードと理由を確認したら、[Accept and run] をクリックします。
コードセルの出力を確認します。
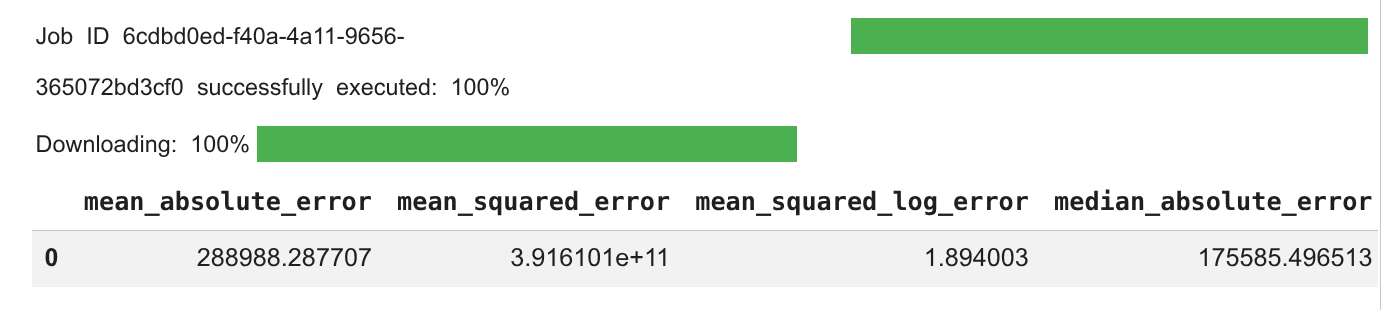
次のサブタスク(予測の生成)について、エージェントによって生成されたコードと推論を確認します。
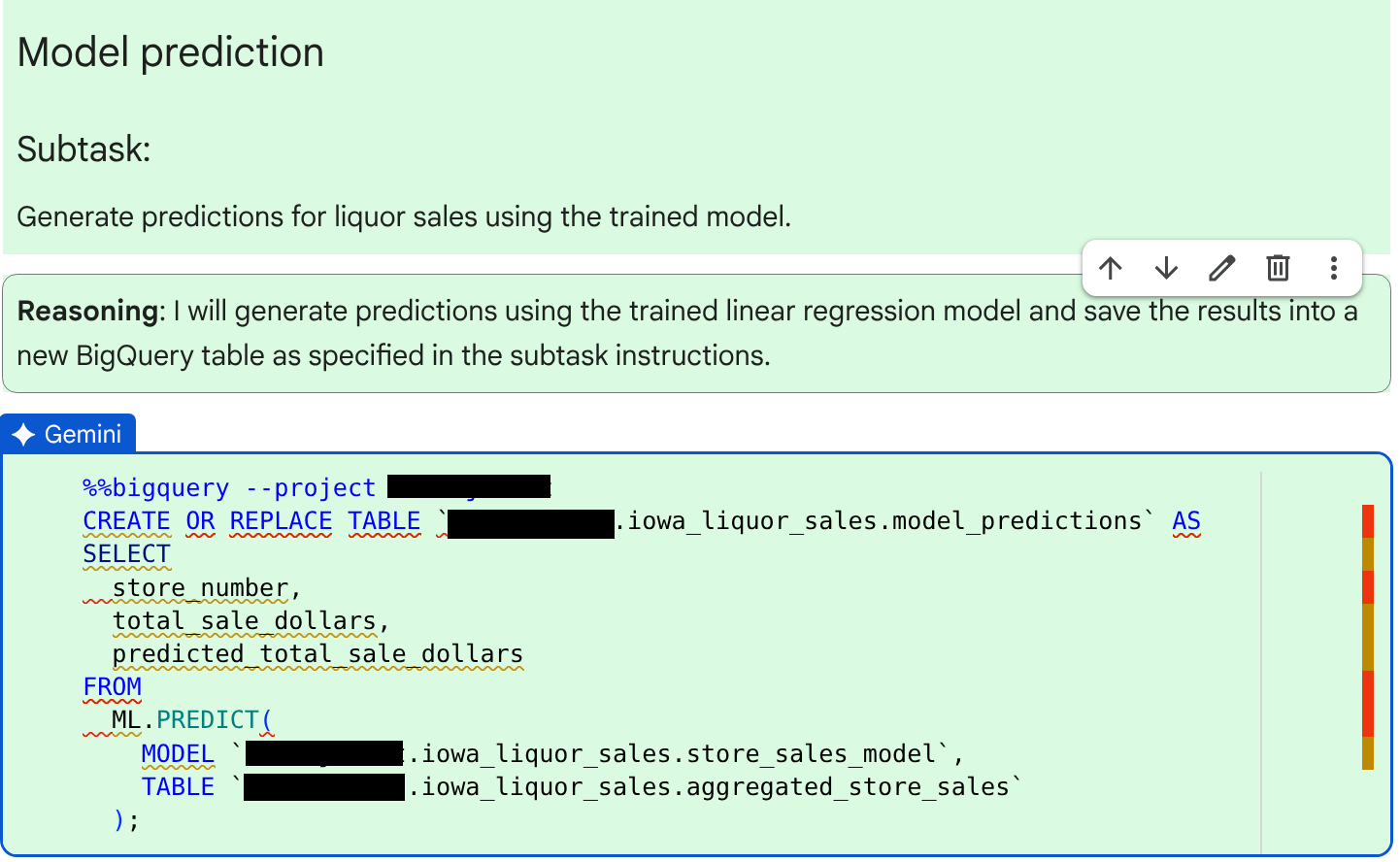
コードと理由を確認したら、[Accept and run] をクリックします。
コードセルの出力を確認します。次のようなメッセージが表示されます。
JOB ID 123456 successfully executed.クエリが実行されると、エージェントは次のサブタスク(データの可視化)のコードセルを作成します。
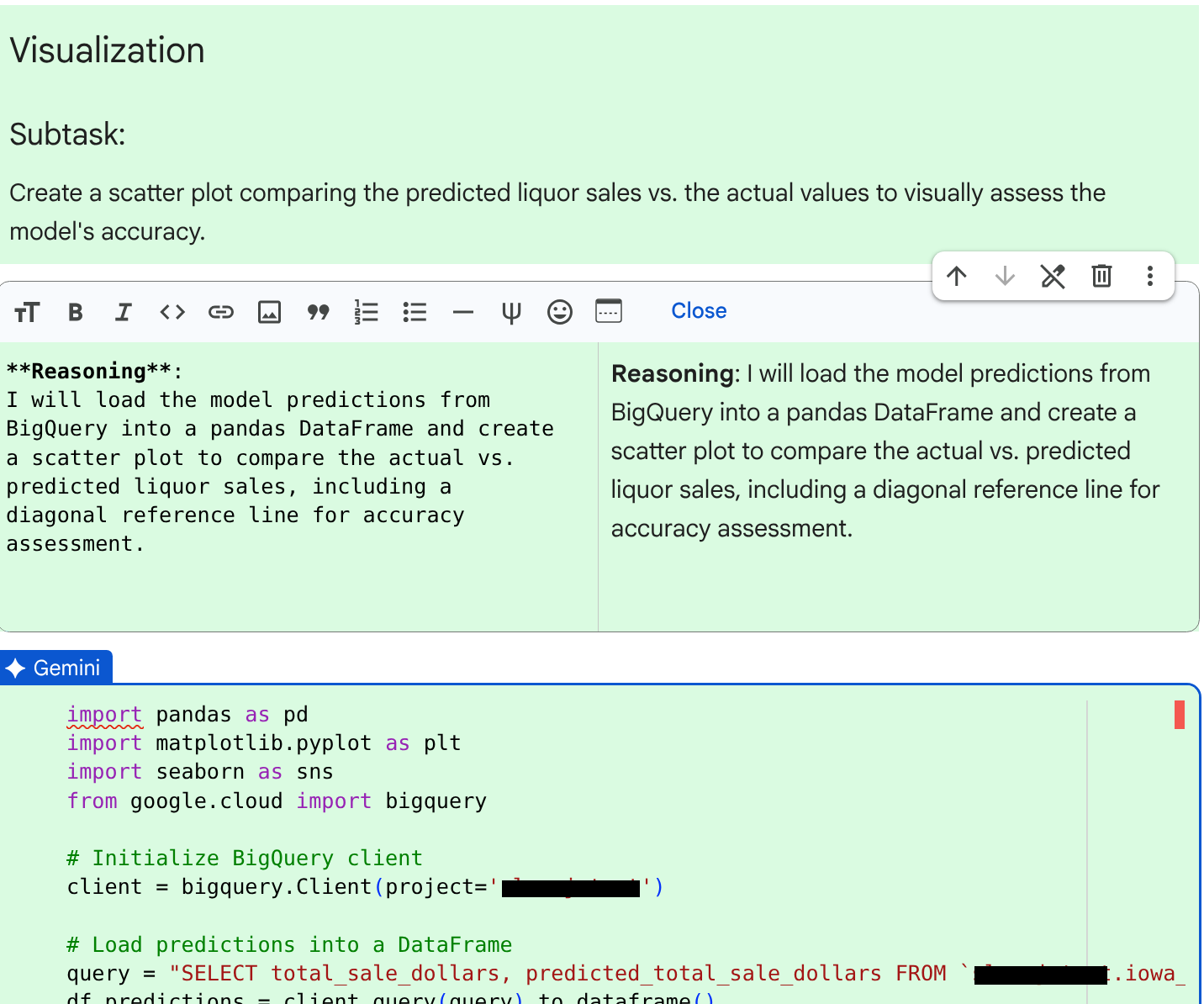
コードと理由を確認したら、[Accept and run] をクリックします。
コードセルの出力を確認します。実際の酒類販売数と予測された酒類販売数をプロットしたグラフが表示されます。グラフは次のようになります。
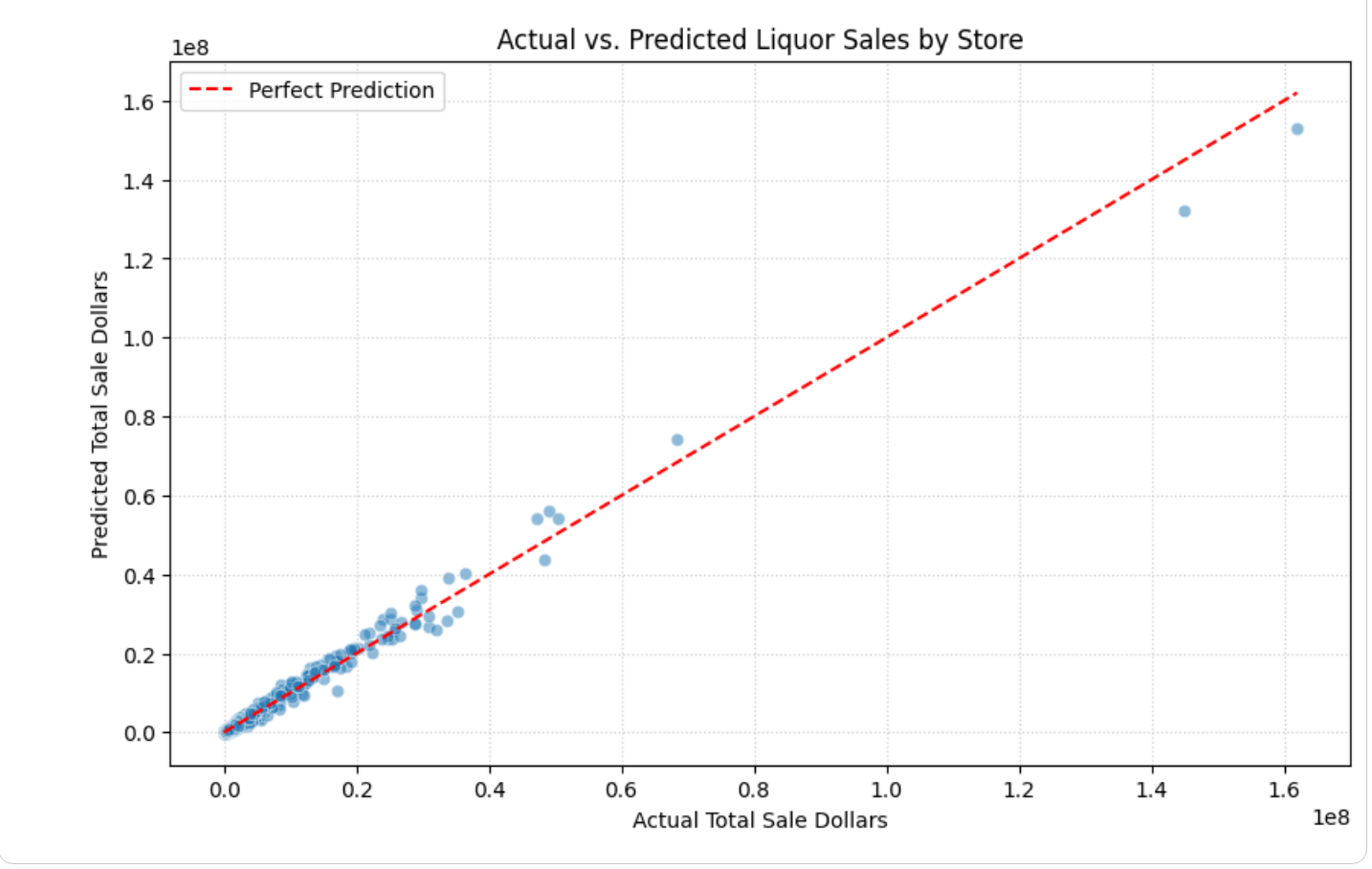
グラフが生成されると、エージェントは主な結果と分析情報を含む結果の概要を生成します。
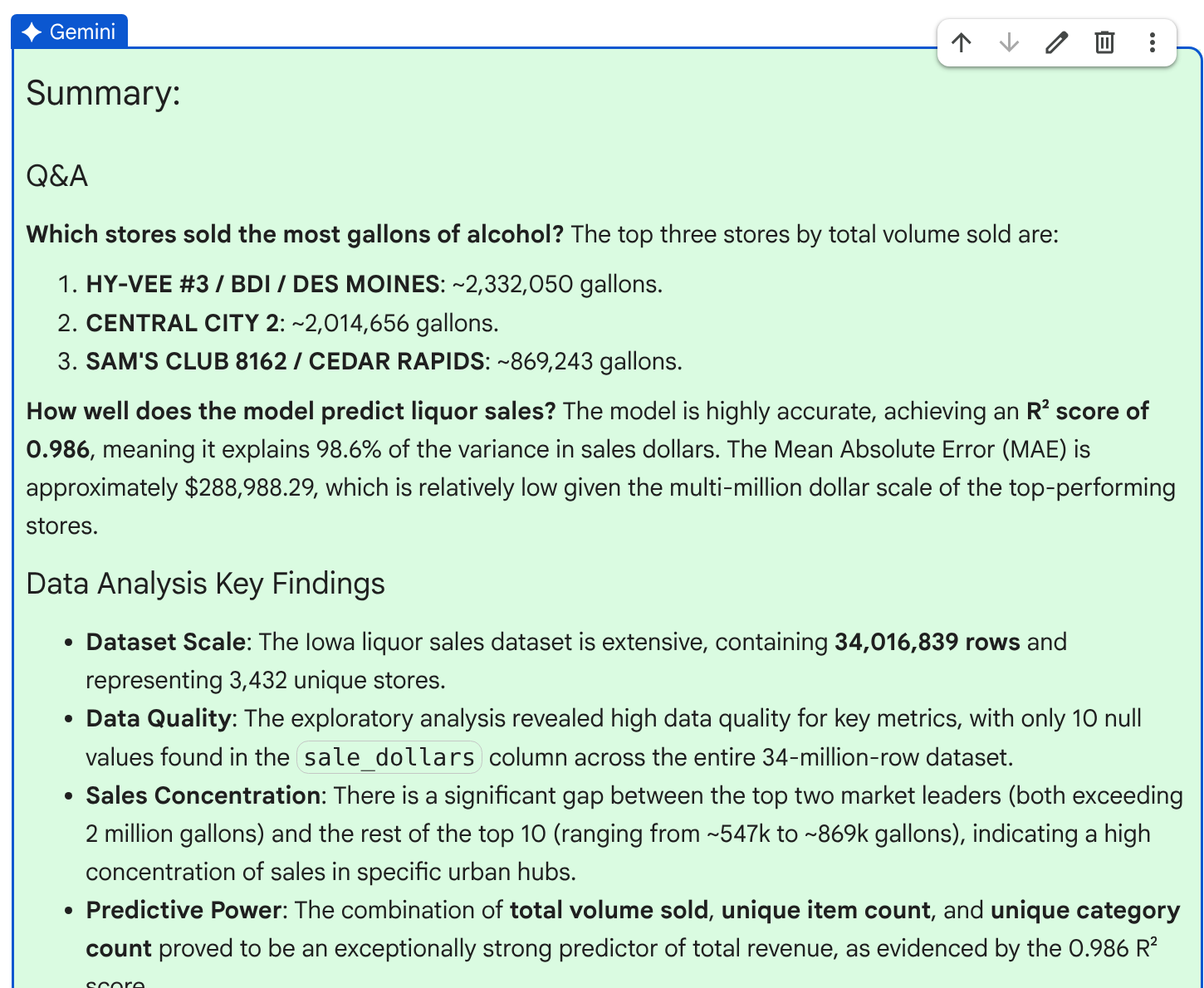
概要を確認したら、[承認] をクリックしてプランを完了します。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
このチュートリアルで使用したリソースについて Google Cloud アカウントに課金されないようにするには、作成したノートブックを削除します。ノートブックを削除する手順は次のとおりです。[BigQuery] ページに移動します。
左側のペインで、プロジェクトを開き、[ノートブック] をクリックします。
predict_liquor_salesノートブックで、more_vert [アクションを開く] をクリックし、[削除] を選択します。[削除] をクリックしてノートブックを削除します。
次のステップ
- データ サイエンス エージェントの機能について学習する。
- BigQuery の Colab Enterprise ノートブックの詳細を確認する。
- Gemini in BigQuery のドキュメントを読む。