
BigQuery 中的 Apache Iceberg 專用 BigLake 資料表 (以下簡稱「BigQuery 中的 BigLake Iceberg 資料表」) 可做為在 Google Cloud上建構開放格式 lakehouse 的基礎。BigQuery 中的 BigLake Iceberg 資料表提供與標準 BigQuery 資料表相同的全代管體驗,但資料會儲存在客戶擁有的儲存空間 bucket。BigQuery 中的 BigLake Iceberg 資料表支援開放式 Iceberg 資料表格式,可與單一資料副本上的開放原始碼和第三方運算引擎互通。
BigQuery 中的 BigLake Iceberg 資料表支援下列功能:
- 使用 GoogleSQL 資料操縱語言 (DML) 進行資料表變異。
- 透過 BigLake 連接器 (例如 Spark、Dataflow 和其他引擎) 使用 BigQuery Storage Write API,統一處理批次和高輸送量串流。
- 匯出 Iceberg V2 快照並在每個資料表變動時自動重新整理,以便使用開放原始碼和第三方查詢引擎直接查詢。
- 結構定義演變:可新增、捨棄及重新命名資料欄,以符合您的需求。您也可以使用這項功能變更現有資料欄的資料類型和資料欄模式。詳情請參閱型別轉換規則。
- 自動最佳化儲存空間,包括調整檔案大小、自動叢集、垃圾收集和最佳化中繼資料。
- 時間旅行:在 BigQuery 中存取歷來資料。
- 資料欄層級安全防護 和資料遮蓋。
- 多陳述式交易 (預先發布版)。
- 資料表分區 (預先發布版)。
- 在 Dataform 工作流程中建立資料表。
架構
BigQuery 中的 BigLake Iceberg 資料表可讓您輕鬆管理自有雲端 bucket 中的資料表,您可以在這些資料表上使用 BigQuery 和開放原始碼運算引擎,不必將資料移出您控管的 bucket。您必須先設定 Cloud Storage bucket,才能在 BigQuery 中使用 BigLake Iceberg 資料表。
BigQuery 中的 BigLake Iceberg 資料表會使用 BigLake metastore 做為所有 Iceberg 資料的統一執行階段 metastore。BigLake Metastore 提供單一資料來源,可管理多個引擎的中繼資料,並支援引擎互通性。
下圖顯示受管理資料表架構的概略視圖:
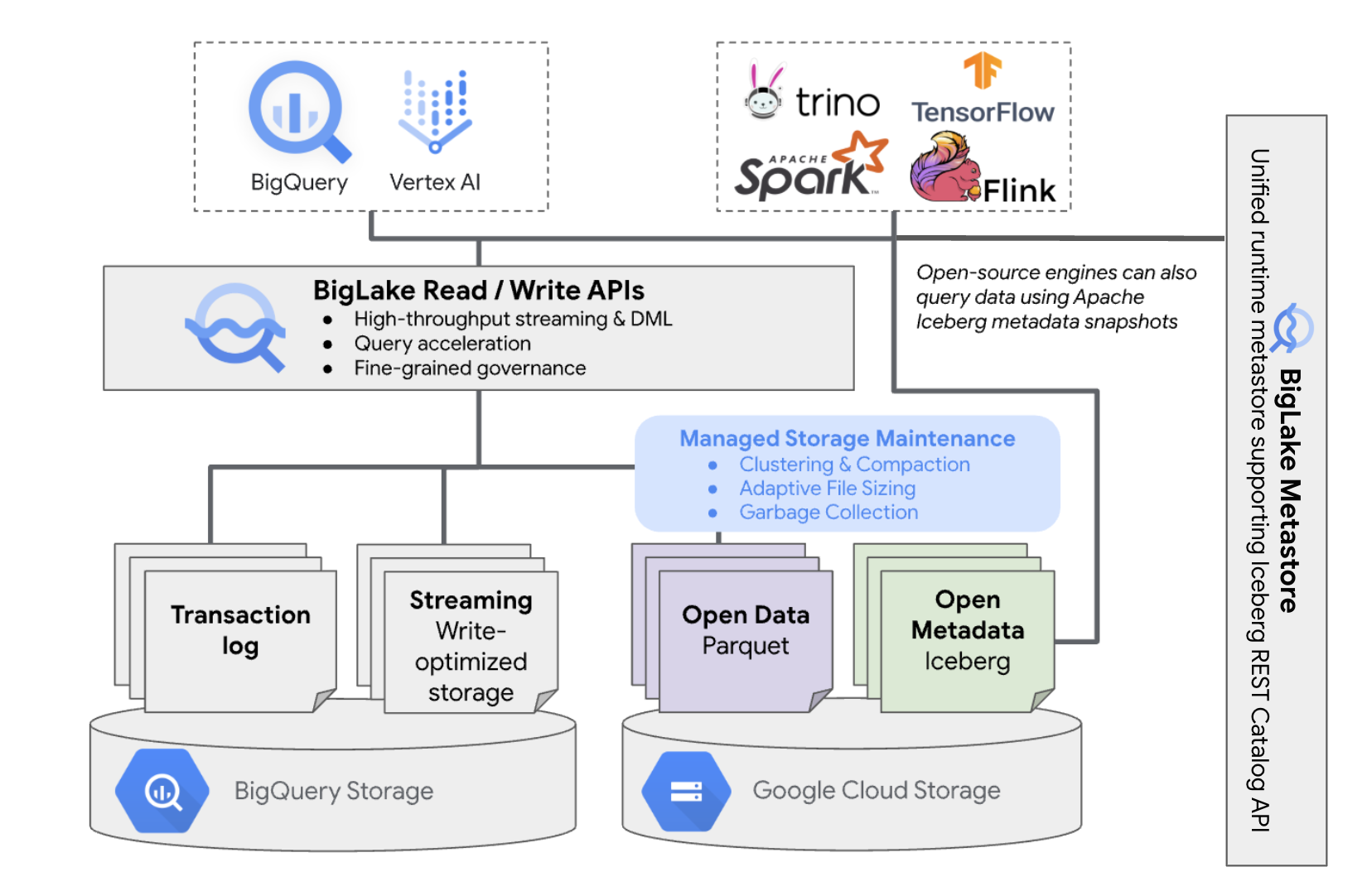
這項資料表管理功能對儲存空間有下列影響:
- BigQuery 會因應寫入要求和背景儲存空間最佳化作業 (例如 DML 陳述式和串流),在值區中建立新的資料檔案。
- 在 BigQuery 中刪除代管資料表時,BigQuery 會在時空旅行時間範圍到期後,清除 Cloud Storage 中相關聯的資料檔案。
在 BigQuery 中建立 BigLake Iceberg 資料表,與建立 BigQuery 資料表類似。由於資料會以開放格式儲存在 Cloud Storage 中,因此您必須執行下列操作:
- 使用
WITH CONNECTION指定 Cloud 資源連線,設定 BigLake 存取 Cloud Storage 的連線憑證。 - 使用
file_format = PARQUET陳述式,將資料儲存的檔案格式指定為PARQUET。 - 使用
table_format = ICEBERG陳述式,將開放原始碼中繼資料表格式指定為ICEBERG。
最佳做法
在 BigQuery 外部直接變更或新增儲存空間中的檔案,可能會導致資料遺失或發生無法復原的錯誤。下表說明可能的情況:
| 作業 | 後果 | 預防措施 |
|---|---|---|
| 在 BigQuery 以外的位置,將新檔案新增至值區。 | 資料遺失:BigQuery 不會追蹤在 BigQuery 外部新增的檔案或物件。背景垃圾收集程序會刪除未追蹤的檔案。 | 只能透過 BigQuery 新增資料。這樣 BigQuery 就能追蹤檔案,並防止檔案遭到垃圾收集。 為避免意外新增資料和資料遺失,建議您限制外部工具對 BigQuery 中含有 BigLake Iceberg 資料表的 bucket 寫入資料。 |
| 在 BigQuery 中,於非空白前置字串建立新的 BigLake Iceberg 資料表。 | 資料遺失:BigQuery 不會追蹤現有資料,因此這些檔案會視為未追蹤,並由背景垃圾收集程序刪除。 | 請只在空白前置字元中,於 BigQuery 建立新的 BigLake Iceberg 資料表。 |
| 修改或取代 BigQuery 資料檔案中的 BigLake Iceberg 資料表。 | 資料遺失:外部修改或更換後,資料表會無法通過一致性檢查,導致無法讀取。針對資料表執行的查詢會失敗。 此時無法自行復原。如要尋求資料復原協助,請與支援團隊聯絡。 |
只能透過 BigQuery 修改資料。這樣 BigQuery 就能追蹤檔案,並防止檔案遭到垃圾收集。 為避免意外新增資料和資料遺失,建議您限制外部工具對 BigQuery 中含有 BigLake Iceberg 資料表的 bucket 寫入資料。 |
| 在 BigQuery 中,於相同或重疊的 URI 上建立兩個 BigLake Iceberg 資料表。 | 資料遺失:BigQuery 不會橋接 BigQuery 中 BigLake Iceberg 資料表的相同 URI 執行個體。每個資料表的背景垃圾收集程序都會將對向資料表的檔案視為未追蹤,並刪除這些檔案,導致資料遺失。 | 請為 BigQuery 中的每個 BigLake Iceberg 資料表使用不重複的 URI。 |
Cloud Storage 值區設定最佳做法
Cloud Storage 儲存空間的設定及其與 BigLake 的連線,會直接影響 BigQuery 中 BigLake Iceberg 資料表的效能、成本、資料完整性、安全性及管理。以下是設定這項功能的最佳做法:
選取的名稱應清楚指出該值區僅適用於 BigQuery 中的 BigLake Iceberg 資料表。
選擇與 BigQuery 資料集位於相同區域的單一區域 Cloud Storage 值區。這項協調作業可避免資料傳輸費用,進而提升效能並降低成本。
根據預設,Cloud Storage 會將資料儲存在 Standard 儲存空間類別中,這類別可提供充足的效能。如要盡量降低資料儲存費用,可以啟用 Autoclass,自動管理儲存空間級別轉換。自動調整級別功能會從 Standard 儲存空間級別開始,將未存取的物件移至存取頻率較低的級別,藉此降低儲存費用。再次讀取物件時,系統會將物件移回 Standard 級別。
確認必要角色已指派給正確的使用者和服務帳戶。
為避免 Cloud Storage bucket 中的 Iceberg 資料遭到意外刪除或毀損,請限制貴機構中大多數使用者的寫入和刪除權限。如要這麼做,請設定儲存空間權限政策,並加入條件,拒絕所有使用者 (您指定的使用者除外) 的
PUT和DELETE要求。啟用稽核記錄,確保作業透明度、進行疑難排解,以及監控資料存取情形。
保留預設的虛刪除政策 (保留 7 天),防止物件遭到意外刪除。不過,如果發現 Iceberg 資料已遭刪除,請與支援團隊聯絡,而非手動還原物件,因為 BigQuery 中繼資料不會追蹤在 BigQuery 外部新增或修改的物件。
系統會自動啟用適應性檔案大小調整、自動叢集和垃圾收集功能,協助您最佳化檔案效能和成本。
請避免使用下列 Cloud Storage 功能,因為 BigQuery 中的 BigLake Iceberg 資料表不支援這些功能:
如要實作這些最佳做法,請使用下列指令建立值區:
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
更改下列內容:
BUCKET_NAME:新 bucket 的名稱PROJECT_ID:專案 IDLOCATION:新值區的位置
BigQuery 工作流程中的 BigLake Iceberg 資料表
下列各節說明如何建立、載入、管理及查詢受管理資料表。
事前準備
在 BigQuery 中建立及使用 BigLake Iceberg 資料表之前,請務必先設定儲存空間 bucket 的雲端資源連線。連線必須具備儲存空間 bucket 的寫入權限,詳情請參閱下方的「必要角色」一節。如要進一步瞭解連線所需的角色和權限,請參閱「管理連線」。
必要的角色
如要取得讓 BigQuery 管理專案中資料表所需的權限,請要求管理員授予您下列 IAM 角色:
-
如要在 BigQuery 中建立 BigLake Iceberg 資料表,請按照下列步驟操作:
-
BigQuery 資料擁有者 (
roles/bigquery.dataOwner) 專案 -
專案的 BigQuery 連線管理員 (
roles/bigquery.connectionAdmin)
-
BigQuery 資料擁有者 (
-
如要在 BigQuery 中查詢 BigLake Iceberg 資料表,請按照下列步驟操作:
-
BigQuery 資料檢視者 (
roles/bigquery.dataViewer) 專案 -
BigQuery 使用者 (
roles/bigquery.user) 專案
-
BigQuery 資料檢視者 (
-
將下列角色授予連線服務帳戶,以便讀取及寫入 Cloud Storage 中的資料:
-
Storage 物件使用者 (
roles/storage.objectUser) (在值區上) -
Storage 舊版值區讀取者 (
roles/storage.legacyBucketReader) 值區
-
Storage 物件使用者 (
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和組織的存取權」。
這些預先定義的角色具備讓 BigQuery 管理專案中資料表所需的權限。如要查看確切的必要權限,請展開「Required permissions」(必要權限) 部分:
所需權限
如要讓 BigQuery 管理專案中的資料表,您必須具備下列權限:
-
bigquery.connections.delegate專案 -
bigquery.jobs.create專案 -
bigquery.readsessions.create專案 -
bigquery.tables.create專案 -
bigquery.tables.get專案 -
bigquery.tables.getData專案 -
storage.buckets.get在 bucket 上 -
storage.objects.create在 bucket 上 -
storage.objects.delete在 bucket 上 -
storage.objects.get在 bucket 上 -
storage.objects.list在 bucket 上
在 BigQuery 中建立 BigLake Iceberg 資料表
如要在 BigQuery 中建立 BigLake Iceberg 資料表,請選取下列其中一種方法:
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
更改下列內容:
- PROJECT_ID:包含資料集的專案。 如果未定義,指令會採用預設專案。
- DATASET_ID:現有資料集。
- TABLE_NAME:您要建立的資料表名稱。
- DATA_TYPE:資料欄所含資訊的資料類型。
- CLUSTER_COLUMN_LIST (選用):以半形逗號分隔的清單,最多包含四個資料欄。必須是頂層的非重複資料欄。
CONNECTION_NAME:連線名稱。例如:
myproject.us.myconnection。如要使用預設連線,請指定
DEFAULT,而非包含 PROJECT_ID.REGION.CONNECTION_ID 的連線字串。STORAGE_URI:完整合格的 Cloud Storage URI。例如:
gs://mybucket/table。
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
更改下列內容:
- PROJECT_ID:包含資料集的專案。 如果未定義,指令會採用預設專案。
- CONNECTION_NAME:連線名稱。例如:
myproject.us.myconnection。 - STORAGE_URI:完整合格的 Cloud Storage URI。例如:
gs://mybucket/table。 - COLUMN_NAME:資料欄名稱。
- DATA_TYPE:資料欄所含資訊的資料類型。
- CLUSTER_COLUMN_LIST (選用):以半形逗號分隔的清單,最多包含四個資料欄。必須是頂層的非重複資料欄。
- DATASET_ID:現有資料集的 ID。
- MANAGED_TABLE_NAME:您要建立的資料表名稱。
API
使用已定義的資料表資源呼叫 tables.insert 方法,類似於下列範例:
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
更改下列內容:
- TABLE_NAME:您要建立的資料表名稱。
- CONNECTION_NAME:連線名稱。例如:
myproject.us.myconnection。 - STORAGE_URI:完整合格的 Cloud Storage URI。您也可以使用萬用字元。例如
gs://mybucket/table。 - COLUMN_NAME:資料欄名稱。
- DATA_TYPE:資料欄所含資訊的資料類型。
將資料匯入 BigQuery 中的 BigLake Iceberg 資料表
以下各節說明如何將各種資料表格式的資料匯入 BigQuery 的 BigLake Iceberg 資料表。
從平面檔案載入標準資料
BigQuery 中的 BigLake Iceberg 資料表會使用 BigQuery 載入工作,將外部檔案載入至 BigQuery 中的 BigLake Iceberg 資料表。如果您在 BigQuery 中有現有的 BigLake Iceberg 資料表,請按照 bq load CLI 指南或 LOAD SQL 指南載入外部資料。載入資料後,新的 Parquet 檔案會寫入 STORAGE_URI/data 資料夾。
如果使用先前的操作說明,但 BigQuery 中沒有現有的 BigLake Iceberg 資料表,系統會改為建立 BigQuery 資料表。
如需將批次資料載入受管理資料表的工具專屬範例,請參閱下列內容:
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
更改下列內容:
- MANAGED_TABLE_NAME:BigQuery 中現有 BigLake Iceberg 資料表的名稱。
- STORAGE_URI:完整的 Cloud Storage URI,或是以逗號分隔的 URI 清單。您也可以使用萬用字元。例如
gs://mybucket/table。 - FILE_FORMAT:來源資料表格式。如要瞭解支援的格式,請參閱
load_option_list的format列。
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
更改下列內容:
- FILE_FORMAT:來源資料表格式。如要瞭解支援的格式,請參閱
load_option_list的format列。 - MANAGED_TABLE_NAME:BigQuery 中現有 BigLake Iceberg 資料表的名稱。
- STORAGE_URI:完整的 Cloud Storage URI,或是以逗號分隔的 URI 清單。您也可以使用萬用字元。例如
gs://mybucket/table。
從 Hive 分區檔案標準載入
您可以使用標準 BigQuery 載入工作,將 Hive 分區檔案載入 BigQuery 的 BigLake Iceberg 資料表。詳情請參閱載入外部分區資料。
從 Pub/Sub 載入串流資料
您可以使用 Pub/Sub BigQuery 訂閱項目,將串流資料載入 BigQuery 的 BigLake Iceberg 資料表。
從 BigQuery 的 BigLake Iceberg 資料表匯出資料
下列各節說明如何將 BigQuery 中 BigLake Iceberg 資料表的資料,匯出為各種資料表格式。
將資料匯出為平面格式
如要將 BigQuery 中的 BigLake Iceberg 資料表匯出為平面格式,請使用 EXPORT DATA 陳述式,並選取目的地格式。詳情請參閱匯出資料。
在 BigQuery 中繼資料快照中建立 BigLake Iceberg 資料表
如要在 BigQuery 中繼資料快照中建立 BigLake Iceberg 資料表,請按照下列步驟操作:
使用
EXPORT TABLE METADATASQL 陳述式,將中繼資料匯出為 Iceberg V2 格式。選用:排定 Iceberg 中繼資料快照重新整理時間。 如要根據設定的時間間隔重新整理 Iceberg 中繼資料快照,請使用排定查詢。
選用:為專案啟用中繼資料自動重新整理功能,在每次資料表變動時,自動更新 Iceberg 資料表的中繼資料快照。如要啟用中繼資料自動重新整理功能,請傳送電子郵件至 bigquery-tables-for-apache-iceberg-help@google.com。 每次重新整理作業都會產生
EXPORT METADATA費用。
下列範例使用 DDL 陳述式 EXPORT TABLE METADATA FROM mydataset.test,建立名為 My Scheduled Snapshot Refresh Query 的排程查詢。DDL 陳述式每 24 小時執行一次。
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
在 BigQuery 中繼資料快照中查看 BigLake Iceberg 資料表
在 BigQuery 中繼資料快照中重新整理 BigLake Iceberg 資料表後,您可以在 BigQuery 中建立 BigLake Iceberg 資料表時使用的 Cloud Storage URI 中找到快照。/data 資料夾包含 Parquet 檔案資料分片,/metadata 資料夾則包含 BigQuery 中繼資料快照中的 BigLake Iceberg 資料表。
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
請注意,mydataset 和 table_name 是實際資料集和資料表的預留位置。
使用 Apache Spark 讀取 BigQuery 中的 BigLake Iceberg 資料表
下列範例會設定環境,以便搭配 Apache Iceberg 使用 Spark SQL,然後執行查詢,從 BigQuery 中指定的 BigLake Iceberg 資料表擷取資料。
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
更改下列內容:
- ICEBERG_VERSION_NUMBER:目前版本的 Apache Spark Iceberg 執行階段。從「Spark Releases」下載最新版本。
- CATALOG_NAME:在 BigQuery 中參照 BigLake Iceberg 資料表的目錄。
- BUCKET_PATH:包含資料表檔案的 bucket 路徑。例如:
gs://mybucket/。 - FOLDER_NAME:包含資料表檔案的資料夾。
例如:
myfolder。
在 BigQuery 中修改 BigLake Iceberg 資料表
如要在 BigQuery 中修改 BigLake Iceberg 資料表,請按照「修改資料表結構定義」一文中的步驟操作。
使用多陳述式交易
如要存取 BigQuery 中 BigLake Iceberg 資料表的多重陳述式交易,請填寫註冊表單。
使用分區
如要存取 BigQuery 中 BigLake Iceberg 資料表的分區功能,請填寫註冊表單。
您可以指定分區資料欄來區隔資料表,藉此將資料表分區。BigQuery 中的 BigLake Iceberg 資料表支援下列資料欄類型:
DATEDATETIMETIMESTAMP
依據 DATE、DATETIME 或 TIMESTAMP 資料欄分區的資料表稱為時間單位資料欄分區。您可以選擇分區的時間間隔為小時、日、月或年。
BigQuery 中的 BigLake Iceberg 資料表也支援叢集,以及合併叢集和分區資料表。
分區限制
- 適用所有 BigQuery 分區資料表限制。
- 不支援
DATE、DATETIME或TIMESTAMP以外的分區資料欄類型。 - 不支援分區到期。
- 不支援分區演進。
在 BigQuery 中建立分區 BigLake Iceberg 資料表
如要在 BigQuery 中建立分區 BigLake Iceberg 資料表,請按照在 BigQuery 中建立標準 BigLake Iceberg 資料表的說明操作,並根據您的環境加入下列其中一項:
在 BigQuery 中修改及查詢分區 BigLake Iceberg 資料表
BigQuery 中已分割的 BigLake Iceberg 資料表,其 BigQuery 資料操縱語言 (DML) 陳述式和查詢,與 BigQuery 中的標準 BigLake Iceberg 資料表相同。BigQuery 會自動將工作範圍限定在正確的分區,類似於 Iceberg 隱藏分區。此外,您新增至資料表的任何新資料都會自動分割。
您也可以在 BigQuery 中查詢分區 BigLake Iceberg 資料表,方法與 BigQuery 中的標準 BigLake Iceberg 資料表相同。建議啟用中繼資料快照,以獲得最佳體驗。
為提升安全性,BigQuery 中 BigLake Iceberg 資料表的分區資訊會與資料路徑分離,並完全由中繼資料層管理。
定價
BigQuery BigLake Iceberg 資料表的價格包括儲存空間、儲存空間最佳化,以及查詢和工作。
儲存空間
BigQuery 中的 BigLake Iceberg 資料表會將所有資料儲存在 Cloud Storage。系統會針對所有儲存的資料收費,包括歷史資料表資料。您可能也需要支付 Cloud Storage 資料處理和移轉費用。透過 BigQuery 或 BigQuery Storage API 處理的作業,可能免除部分 Cloud Storage 作業費用。BigQuery 不會收取儲存費用。詳情請參閱 Cloud Storage 定價。
儲存空間最佳化
BigQuery 中的 BigLake Iceberg 資料表會自動管理資料表,包括壓縮、分群、垃圾收集,以及產生/重新整理 BigQuery 中繼資料,以提升查詢效能並降低儲存空間成本。BigLake 資料表管理功能的運算資源用量會以資料運算單元 (DCU) 為單位,按秒累加計費。詳情請參閱 BigQuery 定價中的 BigLake Iceberg 表格。
透過 Storage Write API 串流時進行的資料匯出作業會計入 Storage Write API 價格,不會以背景維護作業收費。詳情請參閱「資料擷取定價」。
儲存空間最佳化和 EXPORT TABLE METADATA 用量會顯示在 INFORMATION_SCHEMA.JOBS 檢視畫面中。
查詢和工作
與 BigQuery 資料表類似,如果您採用 BigQuery 以量計價方案,系統會根據查詢和讀取的位元組 (每 TiB) 收費;如果您採用 BigQuery 容量運算價格方案,則會根據運算單元耗用量 (每運算單元時數) 收費。
BigQuery 定價也適用於 BigQuery Storage Read API 和 Storage Write API。
載入和匯出作業 (例如 EXPORT METADATA) 會使用企業版即付即用配額。這與 BigQuery 資料表不同,後者不會針對這些作業收費。如果 PIPELINE 保留項目提供 Enterprise 或 Enterprise Plus 配額,載入和匯出作業會優先使用這些保留項目配額。
限制
BigQuery 中的 BigLake Iceberg 資料表有下列限制:
- BigQuery 中的 BigLake Iceberg 資料表不支援重新命名作業或
ALTER TABLE RENAME TO陳述式。 - BigQuery 中的 BigLake Iceberg 資料表不支援資料表副本或
CREATE TABLE COPY陳述式。 - BigQuery 中的 BigLake Iceberg 資料表不支援資料表副本或
CREATE TABLE CLONE陳述式。 - BigQuery 中的 BigLake Iceberg 資料表不支援資料表快照或
CREATE SNAPSHOT TABLE陳述式。 - BigQuery 中的 BigLake Iceberg 資料表不支援下列資料表結構定義:
- BigQuery 中的 BigLake Iceberg 資料表不支援下列結構定義演變案例:
NUMERIC至FLOAT型別強制轉換INT至FLOAT型別強制轉換- 使用 SQL DDL 陳述式,在現有的
RECORD資料欄中新增巢狀欄位
- 透過控制台或 API 查詢時,BigQuery 中的 BigLake Iceberg 資料表會顯示 0 位元組的儲存空間大小。
- BigQuery 中的 BigLake Iceberg 資料表不支援具體化檢視區塊。
- BigQuery 中的 BigLake Iceberg 資料表不支援已授權檢視區塊,但支援資料欄層級的存取控管。
- BigQuery 中的 BigLake Iceberg 資料表不支援變更資料擷取 (CDC) 更新。
- BigQuery 中的 BigLake Iceberg 資料表不支援代管災難復原
- BigQuery 中的 BigLake Iceberg 資料表不支援資料列層級安全防護機制。
- BigQuery 中的 BigLake Iceberg 資料表不支援安全防護時間視窗。
- BigQuery 中的 BigLake Iceberg 資料表不支援擷取作業。
INFORMATION_SCHEMA.TABLE_STORAGE檢視畫面不會顯示 BigQuery 中的 BigLake Iceberg 資料表。- BigQuery 中的 BigLake Iceberg 資料表不支援做為查詢結果目的地。您可以改用
CREATE TABLE陳述式搭配AS query_statement引數,將資料表建立為查詢結果目的地。 CREATE OR REPLACE不支援在 BigQuery 中將標準資料表替換為 BigLake Iceberg 資料表,也不支援將 BigQuery 中的 BigLake Iceberg 資料表替換為標準資料表。- 批次載入和
LOAD DATA陳述式僅支援將資料附加到 BigQuery 中現有的 BigLake Iceberg 資料表。 - 批次載入和
LOAD DATA陳述式不支援結構定義更新。 TRUNCATE TABLE不支援 BigQuery 中的 BigLake Iceberg 資料表。您可以採用以下兩種替代方式:CREATE OR REPLACE TABLE,並使用相同的資料表建立選項。DELETE FROMtableWHEREtrue
APPENDS表格值函式 (TVF) 不支援 BigQuery 中的 BigLake Iceberg 資料表。- Iceberg 中繼資料可能不包含過去 90 分鐘內,透過 Storage Write API 串流至 BigQuery 的資料。
- 使用
tabledata.list進行以記錄為準的分頁存取時,不支援 BigQuery 中的 BigLake Iceberg 資料表。 - 在 BigQuery 中,每個 BigLake Iceberg 資料表只能執行一個並行的變動 DML 陳述式 (
UPDATE、DELETE和MERGE)。其他變動 DML 陳述式會排入佇列。