

En este documento de implementación, se describe cómo implementar una canalización de Dataflow para procesar archivos de imagen a gran escala con la API de Cloud Vision. Esta canalización almacena los resultados de los archivos procesados en BigQuery. Puedes usar los archivos con fines analíticos o para entrenar modelos de BigQuery ML.
La canalización de Dataflow que creas en esta implementación puede procesar millones de imágenes por día. El único límite es tu cuota de la API de Vision. Puedes aumentar tu cuota de la API de Vision según los requisitos de escalamiento.
Estas instrucciones están dirigidas a ingenieros y científicos de datos. En este documento, se supone que tienes conocimientos básicos sobre la compilación de canalizaciones de Dataflow mediante el SDK de Java de Apache Beam, GoogleSQL para BigQuery y secuencias de comandos de shell básicas. También se supone que estás familiarizado con la API de Vision.
Arquitectura
En el siguiente diagrama, se ilustra el flujo del sistema para compilar una solución de análisis de visión de AA.

En el diagrama anterior, la información fluye a través de la arquitectura de la siguiente manera:
- Un cliente sube archivos de imagen a un bucket de Cloud Storage.
- Cloud Storage envía un mensaje sobre la carga de datos a Pub/Sub.
- Pub/Sub notifica a Dataflow sobre la carga.
- La canalización de Dataflow envía las imágenes a la API de Vision.
- La API de Vision procesa las imágenes y, luego, muestra las anotaciones.
- La canalización envía los archivos anotados a BigQuery para que los analices.
Objetivos
- Crear una canalización de Apache Beam para el análisis de imágenes de las imágenes cargadas en Cloud Storage
- Usar el ejecutor portátil de Dataflow para ejecutar la canalización de Apache Beam en modo de transmisión para analizar las imágenes en cuanto se suban.
- Utilizar la API de Vision para analizar imágenes en un conjunto de tipos de características
- Analizar anotaciones con BigQuery
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto,
usa la calculadora de precios.
Cuando termines de compilar la aplicación de ejemplo, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
- Accede a tu Google Cloud cuenta. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
En la Google Cloud consola, activa Cloud Shell.
En la parte inferior de la Google Cloud consola, se inicia una sesión de Cloud Shell en la que se muestra una ventana de línea de comandos. Cloud Shell es un entorno de shell con Google Cloud CLI ya instalada y con valores ya establecidos para el proyecto actual. La sesión puede tardar unos segundos en inicializarse.
- Clona el repositorio de GitHub que contiene el código fuente de la canalización de Dataflow:
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - Ve a la carpeta raíz del repositorio:
cd dataflow-vision-analytics - Sigue las instrucciones de la
sección Introducción
del repositorio dataflow-vision-analytics en GitHub para
realizar las siguientes tareas:
- Habilita varias APIs.
- Crear un bucket de Cloud Storage
- Crear un tema y una suscripción de Pub/Sub.
- Crear un conjunto de datos de BigQuery
- Configurar varias variables de entorno para esta implementación
Ejecuta la canalización de Dataflow para todas las funciones implementadas de la API de Vision
La canalización de Dataflow solicita y procesa un conjunto específico de funciones y atributos de la API de Vision dentro de los archivos anotados.
Los parámetros enumerados en la siguiente tabla son específicos de la canalización de Dataflow en esta implementación. Para obtener la lista completa de los parámetros de ejecución de Dataflow estándar, consulta Configura las opciones de canalización de Dataflow.
| Nombre del parámetro | Descripción |
|---|---|
|
La cantidad de imágenes que se incluirán en una solicitud a la API de Vision. El valor predeterminado es 1. Puedes aumentar este valor hasta un máximo de 16. |
|
El nombre del conjunto de datos de BigQuery de salida. |
|
Una lista de características de procesamiento de imágenes. La canalización admite las funciones de etiqueta, punto de referencia, logotipo, rostro, sugerencia de recorte y propiedades de la imagen. |
|
El parámetro que define la cantidad máxima de llamadas paralelas a la API de Vision. El valor predeterminado es 1. |
|
Parámetros de string con nombres de tablas para varias anotaciones. Se proporcionan los valores predeterminados para cada tabla, por ejemplo, label_annotation. |
|
El período de espera antes de procesar imágenes cuando hay un lote incompleto de imágenes. La configuración predeterminada es 30 segundos. |
|
El ID de la suscripción a Pub/Sub que recibe notificaciones de entrada de Cloud Storage. |
|
El ID del proyecto que se usará para la API de Vision. |
En Cloud Shell, ejecuta el siguiente comando a fin de procesar imágenes para todos los tipos de funciones compatibles con la canalización de Dataflow:
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"La cuenta de servicio dedicada debe tener acceso de lectura al bucket que contiene las imágenes. En otras palabras, esa cuenta debe tener el rol
roles/storage.objectViewerotorgada en ese bucket.Para obtener más información sobre el uso de una cuenta de servicio dedicada, consulta Seguridad y permisos de Dataflow.
Abre la URL que se muestra en una nueva pestaña del navegador o ve a la página Trabajos de Dataflow y selecciona la canalización test-vision-analytics.
Después de unos segundos, aparecerá el grafo del trabajo de Dataflow:
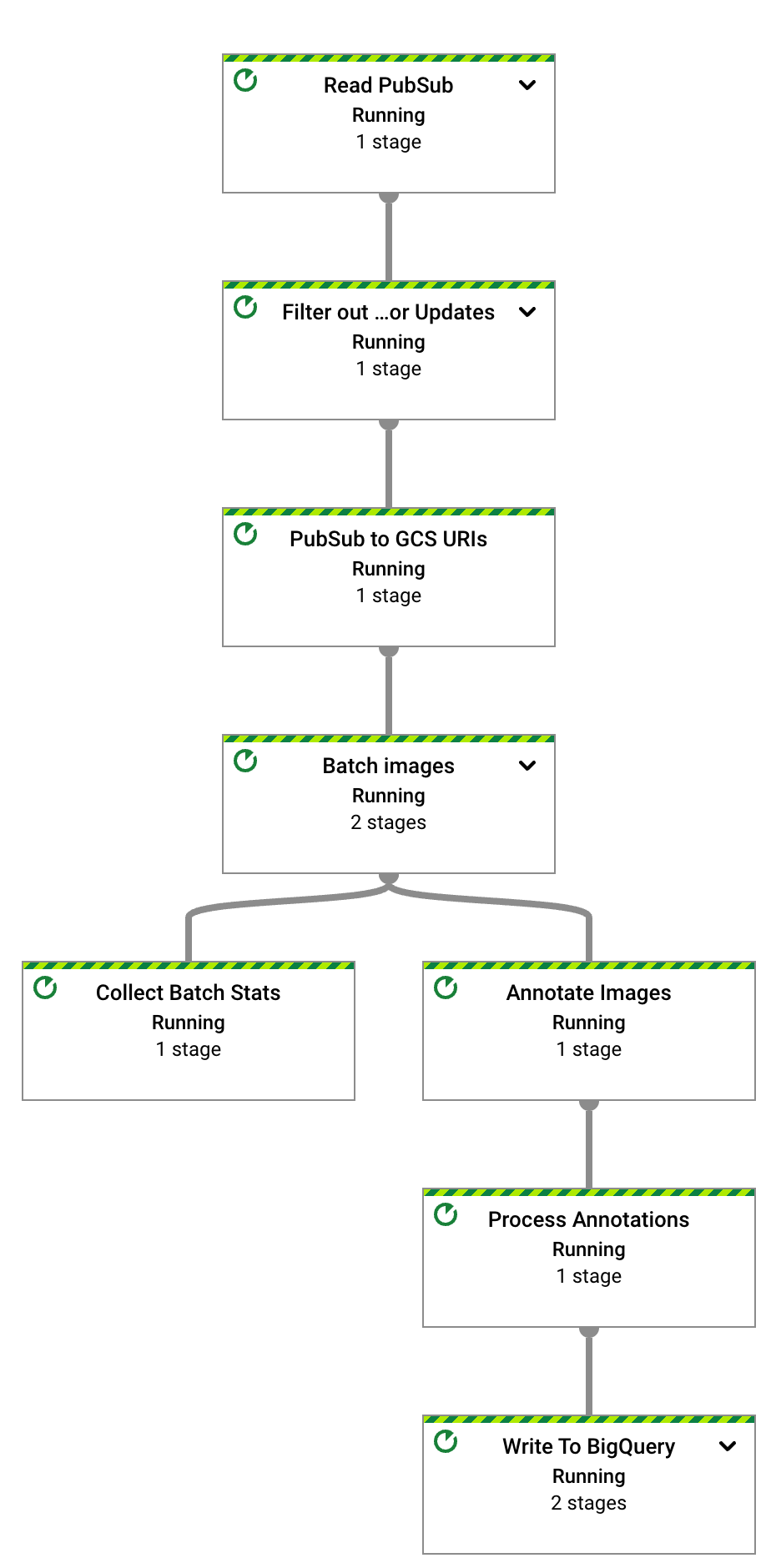
La canalización de Dataflow ahora se ejecuta y espera recibir las notificaciones de entrada de la suscripción a Pub/Sub.
Para activar el procesamiento de imágenes de Dataflow, sube los seis archivos de muestra al bucket de entrada:
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}En la Google Cloud consola, busca el panel Contadores personalizados y usa lo para revisar los contadores personalizados en Dataflow y verificar que Dataflow haya procesado las seis imágenes. Puedes usar la funcionalidad de filtro del panel para navegar a las métricas correctas. Para mostrar solo los contadores, comienza con el prefijo
numberOfy escribenumberOfen el filtro.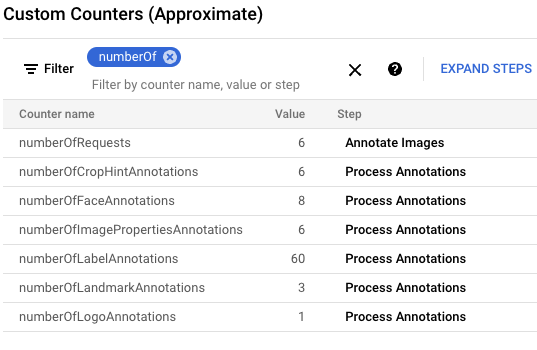
En Cloud Shell, verifica que las tablas se hayan creado de forma automática:
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"El resultado es el siguiente:
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
Visualiza el esquema de la tabla
landmark_annotation. La funciónLANDMARK_DETECTIONcaptura los atributos que muestra la llamada a la API.bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotationEl resultado es el siguiente:
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]Para ver los datos de anotación que produce la API, ejecuta los siguientes comandos
bq querypara ver todos los puntos de referencia que se encuentran en estas seis imágenes ordenados por la puntuación más probable:bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"El resultado es similar al siguiente:
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
Para obtener descripciones detalladas de todas las columnas que son específicas de las anotaciones, consulta
AnnotateImageResponse.Para detener la canalización de transmisión, ejecuta el siguiente comando. La canalización continúa ejecutándose, aunque no haya más notificaciones de Pub/Sub para procesar.
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")La siguiente sección contiene más consultas de muestra que analizan diferentes funciones de imagen de las imágenes.
Analiza un conjunto de datos Flickr30K
En esta sección, detectarás etiquetas y puntos de referencia en el conjunto de datos de imágenes públicas Flickr30k alojado en Kaggle.
En Cloud Shell, cambia los parámetros de canalización de Dataflow a fin de que estén optimizados para un conjunto de datos grande. Para permitir una mayor capacidad de procesamiento, también aumenta los valores
batchSizeykeyRange. Dataflow escalará la cantidad de trabajadores según sea necesario:./gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"Debido a que el conjunto de datos es grande, no puedes usar Cloud Shell para recuperar las imágenes de Kaggle y enviarlas al bucket de Cloud Storage. Para ello, debes usar una VM con un tamaño de disco más grande.
Para recuperar imágenes basadas en Kaggle y enviarlas al bucket de Cloud Storage, sigue las instrucciones de la sección Simula la carga de imágenes en el bucket de almacenamiento del repositorio de GitHub.
Para observar el progreso del proceso de copia mirando las métricas personalizadas disponibles en la IU de Dataflow, navega a la página Trabajos de Dataflow y selecciona la
vision-analytics-flickrcanalización. Los contadores de clientes deben cambiar periódicamente hasta que la canalización de Dataflow procese todos los archivos.El resultado es similar al de la siguiente captura de pantalla del panel Contadores personalizados. Uno de los archivos del conjunto de datos es del tipo incorrecto, y el contador
rejectedFileslo refleja. Estos valores de contador son aproximados. Es posible que veas números más altos. Además, es muy probable que la cantidad de anotaciones cambie debido a la mayor precisión del procesamiento de la API de Vision.
Para determinar si te acercas o superas los recursos disponibles, consulta la página de cuota de la API de Vision.
En nuestro ejemplo, la canalización de Dataflow usó solo aproximadamente el 50% de su cuota. Según el porcentaje de la cuota que uses, puedes decidir aumentar el paralelismo de la canalización aumentando el valor del parámetro
keyRange.Cierra la canalización:
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"
Analiza anotaciones en BigQuery
En esta implementación, procesaste más de 30,000 imágenes para la anotación de etiquetas y puntos de referencia. En esta sección, recopilarás estadísticas sobre esos archivos. Puedes ejecutar estas consultas en el espacio de trabajo de GoogleSQL para BigQuery o usar la herramienta de línea de comandos de bq.
Ten en cuenta que los números que ves pueden variar de los resultados de la consulta de muestra en esta implementación. La API de Vision mejora constantemente la precisión de su análisis; puede producir resultados más enriquecidos analizando la misma imagen después de que pruebes la solución inicialmente.
En la Google Cloud consola, ve a la página Editor de consultas de BigQuery y ejecuta el siguiente comando para ver las 20 etiquetas principales del conjunto de datos:
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20El resultado es similar al siguiente:
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
Determina qué otras etiquetas están presentes en una imagen con una etiqueta en particular, clasificadas por frecuencia:
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;El resultado es el siguiente. Para la etiqueta Plucked string instruments que se usa en el comando anterior, deberías ver lo siguiente:
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
Consulta los 10 puntos de referencia principales detectados:
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10El resultado es el siguiente:
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
Determina las imágenes que probablemente contengan cascadas:
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10El resultado es el siguiente:
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
Busca imágenes de puntos de referencia en un radio de 3 kilómetros del Coliseo en Roma (la función
ST_GEOPOINTusa la longitud y la latitud del Coliseo):WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100Cuando ejecutes la consulta, verás que hay varias imágenes del Coliseo, pero también imágenes del Arco de Constantino, el monte Palatino y otros lugares fotografiados con frecuencia.
Puedes visualizar los datos en BigQuery Geo Viz si pegas en la consulta anterior. Selecciona un punto en el mapa para ver sus detalles. El atributo
Image_urlcontiene un vínculo al archivo de imagen.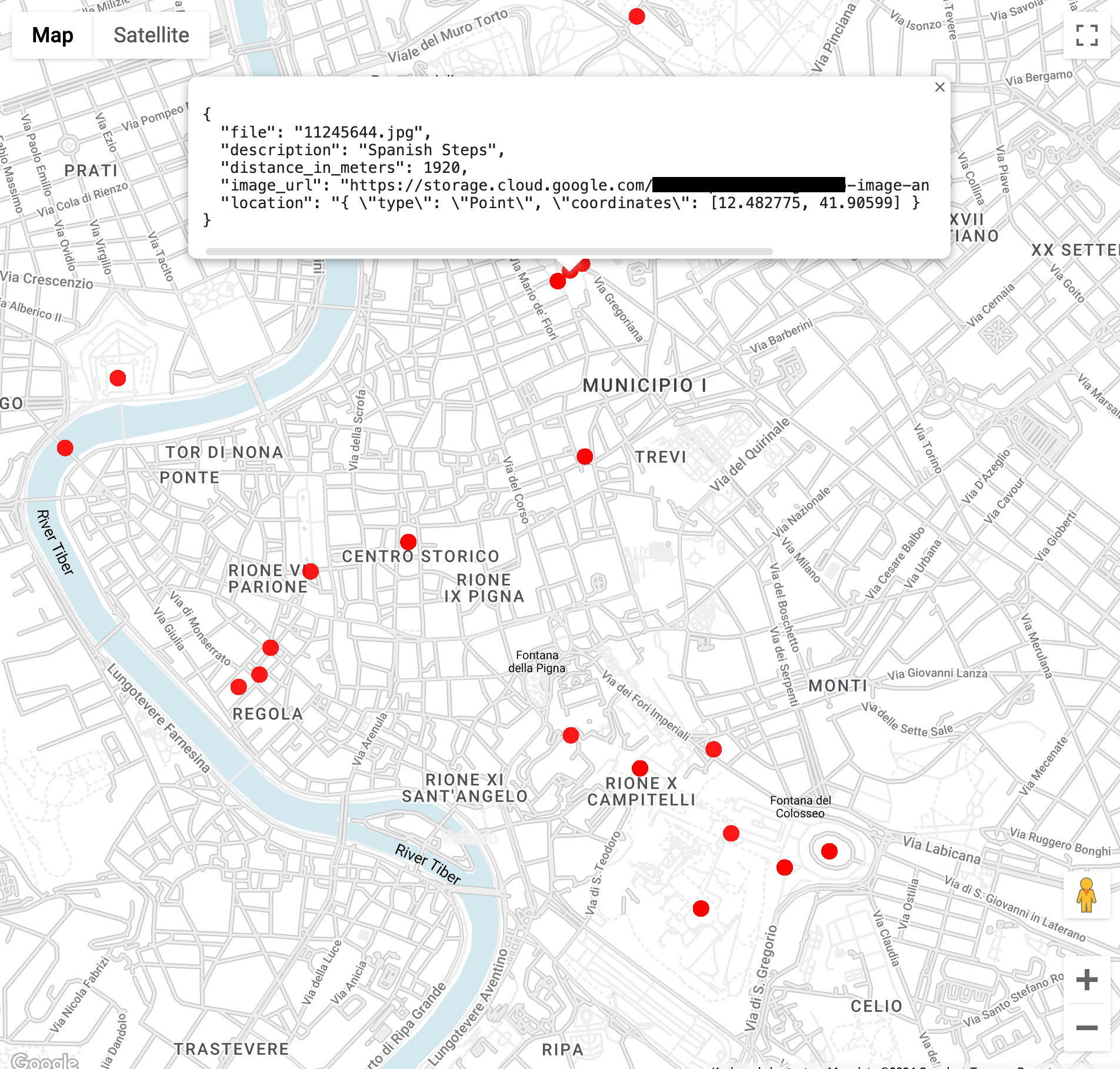
Una nota sobre los resultados de la consulta. Por lo general, los puntos de referencia incluyen información de ubicación. La misma imagen puede contener varias ubicaciones del mismo punto de referencia.
Esta funcionalidad se describe en el
AnnotateImageResponse
tipo.
Debido a que una ubicación puede indicar la ubicación de la escena en la imagen, pueden haber varios elementos LocationInfo. Otra ubicación puede indicar dónde se tomó la imagen.
Limpia
Para evitar que se apliquen cargos a tu Google Cloud cuenta por los recursos usados en esta guía, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el Google Cloud proyecto
La manera más fácil de eliminar la facturación es borrar el Google Cloud proyecto que creaste para el instructivo.
- En la Google Cloud consola, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
Si decides borrar recursos de forma individual, sigue los pasos de la Limpiar sección del repositorio de GitHub.
¿Qué sigue?
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.
Colaboradores
Autores:
- Masud Hasan | Administrador de Ingeniería de Confiabilidad de Sitios
- Sergei Lilicherko | Arquitecto de Soluciones
- Lakshmanan Sethu | Administrador técnico de cuentas
Otros colaboradores:
- Jiyeon Kang | Ingeniero de Atención al cliente
- Sunil Kumar Jang Bahadur | Ingeniero de Atención al cliente