
AlloyDB Omni ist ein herunterladbares Datenbanksoftwarepaket, mit dem Sie eine optimierte Version von AlloyDB for PostgreSQL in von Ihnen verwalteten Computerumgebungen bereitstellen können. AlloyDB Omni und der vollständig verwaltete AlloyDB-Dienst auf Google Cloud verwenden dieselben Kernkomponenten. AlloyDB verwendet eine cloudnative, disaggregierte Speicherebene, während AlloyDB Omni auf dem von Ihnen ausgewählten Speicher bereitgestellt wird.
Dank der Portabilität von AlloyDB Omni können Sie es in vielen Umgebungen ausführen, darunter:
- Ihre privaten Rechenzentren
- Jede öffentliche Cloud
- Ihr Laptop
- Cloudbasierte VM-Instanzen
AlloyDB Omni bietet zusätzlich zu Standard-PostgreSQL mehrere Verbesserungen, die Skalierbarkeit, Verfügbarkeit, Zuverlässigkeit, Leistung, KI und natürliche Sprache unterstützen. Weitere Informationen finden Sie unter AlloyDB Omni-Ergänzungen für Standard-PostgreSQL.
Anwendungsfälle für AlloyDB Omni
AlloyDB Omni eignet sich gut für die folgenden Szenarien:
- Sie benötigen eine skalierbare, leistungsstarke Version von PostgreSQL, die Sie aufgrund von gesetzlichen oder Datenhoheitsanforderungen lokal ausführen müssen.
- Sie benötigen eine Datenbank, die auch dann weiter ausgeführt wird, wenn sie nicht mit dem Internet verbunden ist.
- Sie möchten von einer Legacy-Datenbank migrieren, ohne sich für einen vollständig verwalteten Clouddienst wie AlloyDB for PostgreSQL zu entscheiden.
Wichtige Features
- Ein 100% PostgreSQL-kompatibler Datenbankserver.
- Unterstützung für AlloyDB AI, mit dem Sie generative KI-Anwendungen auf Unternehmensniveau mit Ihren Betriebsdaten erstellen können.
- Integrationen mit dem Google Cloud KI-Ökosystem, einschließlich Vertex AI Model Garden und Open-Source-Tools für generative KI.
Unterstützung für Autopilot-Funktionen von AlloyDB for PostgreSQL, mit Google Cloud denen AlloyDB Omni selbst verwaltet und optimiert werden kann.
AlloyDB Omni unterstützt beispielsweise die automatische Speicherverwaltung und die adaptive automatische Bereinigung veralteter Daten.
Die spaltenbasierte Engine von AlloyDB Omni, die relevante Daten in einem speicherinternen Spaltenformat speichert, um die Leistung von Analyseabfragen, Berichten sowie Arbeitslasten von hybriden transaktionsorientierten und analytischen Verarbeitungen (HTAP) zu verbessern.
In Leistungstests sind transaktionsorientierte Arbeitslasten in AlloyDB Omni mehr als doppelt so schnell und Analyseabfragen bis zu 100-mal schneller als in Standard-PostgreSQL.
Bereitstellungsoptionen für AlloyDB Omni
Sie können AlloyDB Omni mit einer der folgenden Bereitstellungsoptionen installieren:
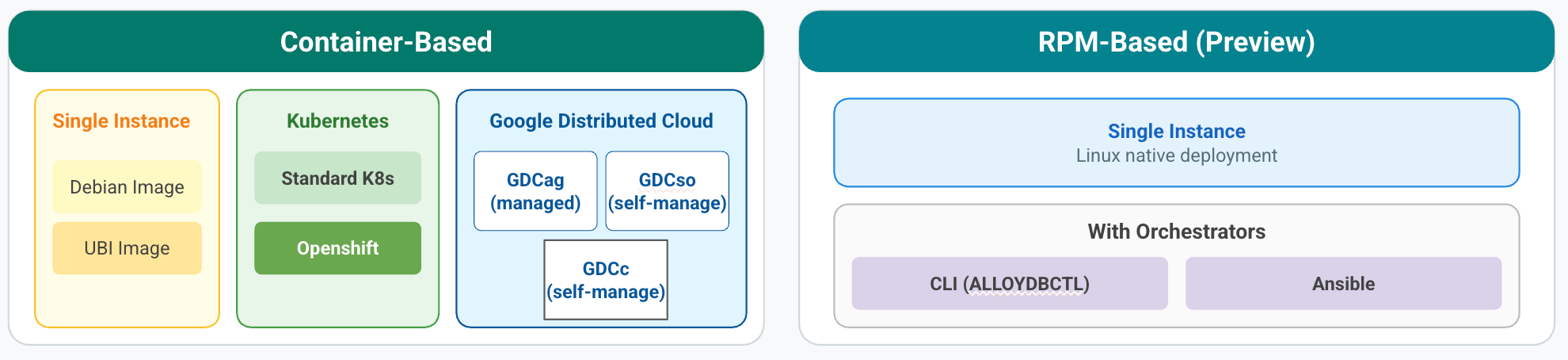
AlloyDB Omni mit Containern: ein eigenständiger Datenbankcontainer. Führen Sie AlloyDB Omni auf einem Linux-System mit SSD-Speicher und mindestens 8 GB Arbeitsspeicher pro CPU aus.
AlloyDB Omni mit dem Container-Orchestrator: Teil eines Containers in einer Kubernetes-Umgebung. Der AlloyDB Omni Kubernetes-Operator ist eine Erweiterung der Kubernetes API, mit der Sie AlloyDB Omni in den meisten CNCF-kompatiblen Kubernetes-Umgebungen ausführen können.
Der AlloyDB Omni-Operator vereinfacht grundlegende Datenbankvorgänge. So können Sie Bereitstellungen mit einzelner Instanz oder mit Hochverfügbarkeit (HA) sowie Vorgänge am zweiten Tag wie Sicherung, Wiederherstellung, Failover und Einrichtung der regionsübergreifenden Notfallwiederherstellung (DR) automatisieren.
AlloyDB Omni mit dem RPM-Orchestrator (Vorschau): eine Bereitstellung mit Red Hat Package Manager (RPM) für VMs oder Bare-Metal-Server. Diese Option umfasst eine Orchestrierungsplattform, die die Bereitstellung und Verwaltung in Nicht-Kubernetes-Umgebungen automatisiert. Sie bietet cloudähnliche Flexibilität für die von Ihnen gewählte Infrastruktur, ohne dass Containerisierungsebenen wie Docker erforderlich sind.
AlloyDB Omni mit RPM (Vorschau): ein eigenständiges Paket das direkt in einer VM oder auf einem Bare-Metal-Server ausgeführt wird. AlloyDB Omni mit RPM wird als eine Reihe integrierter Softwarekomponenten direkt auf dem Hostbetriebssystem ausgeführt. Es verwendet das Standard-Linux-Dateisystem für die Speicherung, sodass Sie Ihre vorhandene Speicherinfrastruktur und Ihre Verwaltungspraktiken nutzen können.
Ihre Anwendungen stellen eine Verbindung zu Ihrer AlloyDB Omni-Datenbank her und kommunizieren mit ihr, so wie Anwendungen eine Verbindung zu einem Standard-PostgreSQL-Datenbankserver herstellen und mit ihm kommunizieren. Die Nutzerzugriffssteuerung basiert ebenfalls auf PostgreSQL-Standards.
Sie können das Verhalten der AlloyDB Omni-Datenbank mit Datenbank-Flags konfigurieren, einschließlich Logging, Bereinigung und spaltenbasierter Engine. Weitere Informationen finden Sie unter Verfügbare Download- und Installationsoptionen für AlloyDB Omni.
AlloyDB Omni als Container
Google stellt AlloyDB Omni als Container bereit, den Sie mit Container-Laufzeiten wie Docker und Podman ausführen können. Sie können AlloyDB Omni-Container auch in einer Kubernetes-Umgebung bereitstellen, wobei viele grundlegende Vorgänge automatisiert werden.
Im Betrieb bieten Container die folgenden Vorteile:
- Transparente Abhängigkeitsverwaltung: Alle erforderlichen Abhängigkeiten sind im Container gebündelt und werden von Google getestet, um sicherzustellen, dass sie vollständig mit AlloyDB Omni kompatibel sind.
- Portabilität: Sie können davon ausgehen, dass AlloyDB Omni in allen Umgebungen konsistent funktioniert.
- Sicherheitsisolation: Sie wählen aus, auf was der AlloyDB Omni-Container auf dem Hostcomputer zugreifen kann.
- Ressourcenverwaltung: Sie können die Menge der Rechenressourcen definieren, die der AlloyDB Omni-Container verwenden soll.
- Nahtloses Patchen und Aktualisieren: Wenn Sie einen Container patchen möchten, ersetzen Sie das vorhandene Image durch ein neues.
AlloyDB Omni in einer RHEL-Umgebung
AlloyDB Omni bietet zwei Bereitstellungsoptionen für eine RHEL-Umgebung, die von Ihren Automatisierungs- und Skalierungsanforderungen abhängen.
AlloyDB Omni mit RPM
Die RPM-Bereitstellungsoption (Vorschau) ist eine eigenständige Red Hat Package Manager-Installation (RPM), die für Umgebungen entwickelt wurde, in denen Sie eine nicht containerisierte AlloyDB Omni-Datenbank benötigen. Diese Option unterstützt RHEL 9 und Rocky Linux 9.
- Direkte Betriebssystemintegration: Wird als eine Reihe integrierter Softwarekomponenten direkt auf dem Hostbetriebssystem ausgeführt.
- Vorhandener Speicher: Verwendet das Standard-Linux-Dateisystem (ext4 und xfs), das die vorhandene Speicherinfrastruktur und die Verwaltungspraktiken unterstützt.
- Einfachheit: Gut geeignet für Setups mit einer einzelnen Instanz, bei denen eine enge Integration mit dem Hostbetriebssystem ohne zusätzliche Orchestrierungsebenen erforderlich ist.
Der RPM-Orchestrator
Die Bereitstellungsoption mit dem RPM-Orchestrator (Vorschau) verwendet dieselben RPM-Pakete wie AlloyDB Omni mit RPM, fügt aber eine Orchestrierungs plattform hinzu, um die Verwaltung in Nicht-Kubernetes Umgebungen zu automatisieren.
- Cloudähnliche Flexibilität: Erweitert die Automatisierung auf die lokale Infrastruktur und übernimmt das Bootstrapping, Failover und die Lebenszyklusverwaltung.
- Automatisierungsframeworks: Lässt sich in beliebte Tools wie Ansible einbinden, sodass Teams vorhandene Kenntnisse nutzen können. Sie können auch speziell entwickelte Befehlszeilentools verwenden.
- Unternehmensfunktionen: Speziell entwickelt, um Hochverfügbarkeit (HA) und Notfallwiederherstellung (DR) über einen zentralen Cluster-Manager zu unterstützen.
Datensicherung und Wiederherstellung im Notfall
AlloyDB Omni bietet ein System für kontinuierliche Sicherung und Wiederherstellung, mit dem Sie einen neuen Datenbankcluster basierend auf einem beliebigen Zeitpunkt innerhalb eines anpassbaren Aufbewahrungszeitraums erstellen können. So können Sie sich von Datenverlusten erholen.
Außerdem kann AlloyDB Omni vollständige Sicherungen der Daten Ihres Datenbankclusters erstellen und speichern, entweder auf Anfrage oder nach einem regelmäßigen Zeitplan. Sie können jederzeit eine Wiederherstellung aus einer Sicherung in einen AlloyDB Omni-Datenbankcluster durchführen, der alle Daten aus dem ursprünglichen Datenbankcluster zum Zeitpunkt der Erstellung der Sicherung enthält.
Als weitere Methode zur Notfallwiederherstellung können Sie die Replikation über Rechenzentren hinweg erreichen, indem Sie sekundäre Datenbankcluster in separaten Rechenzentren erstellen. AlloyDB Omni streamt Daten asynchron von einem festgelegten primären Datenbankcluster zu jedem seiner sekundären Cluster. Bei Bedarf können Sie einen sekundären Datenbankcluster zu einem primären AlloyDB Omni-Datenbankcluster hochstufen.
AlloyDB Omni-Komponenten
AlloyDB Omni besteht aus zwei Gruppen von Architekturkomponenten: PostgreSQL-Komponenten mit AlloyDB Omni-Erweiterungen und AlloyDB Omni-spezifischen Komponenten.
Das folgende Diagramm zeigt beide Gruppen von Komponenten, einschließlich der Infrastrukturebene, auf der sich die Komponenten befinden, und Funktionen für jede Komponente.
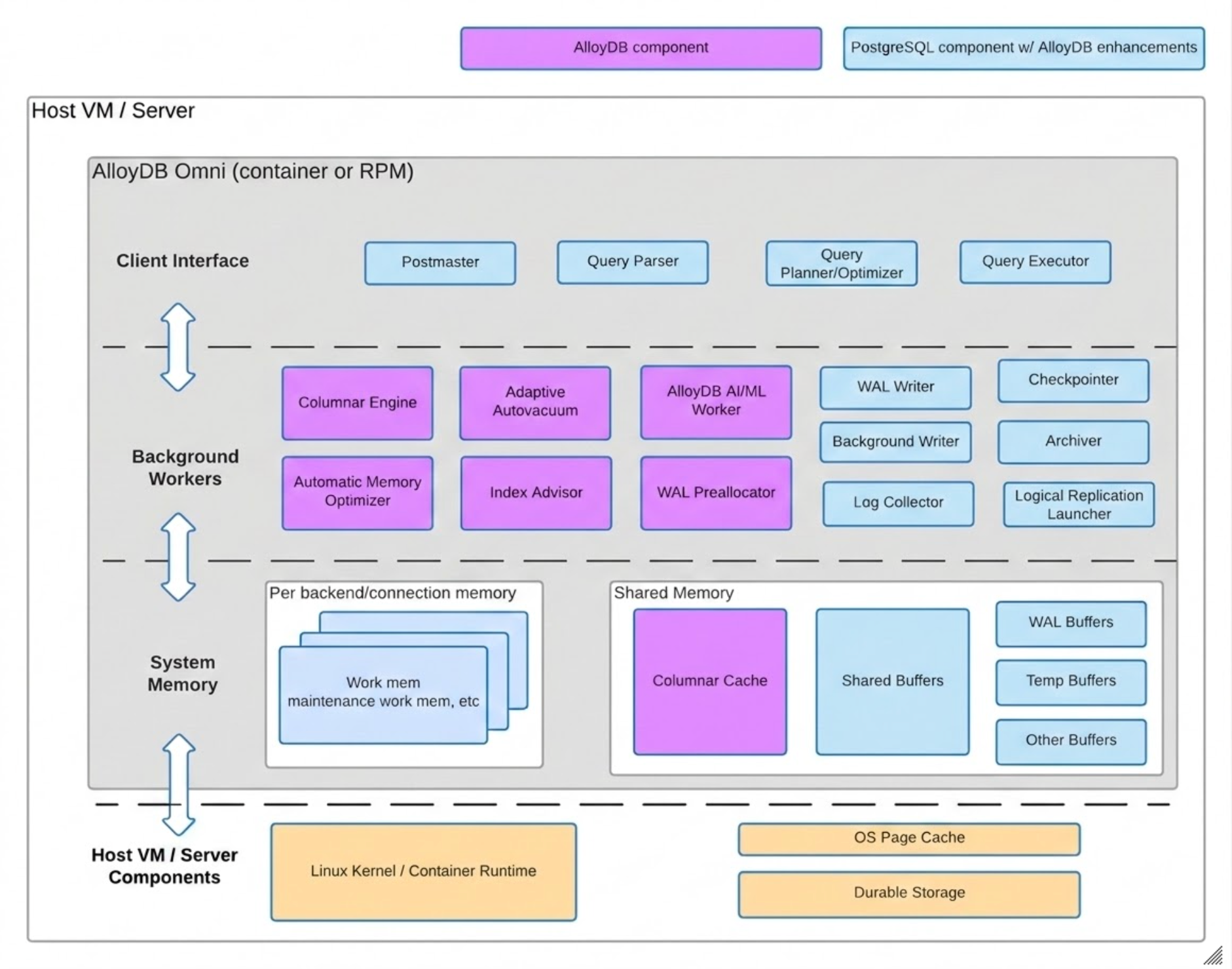
Datenspeicher
AlloyDB Omni speichert Daten auf Seiten mit fester Größe, die im zugrunde liegenden Dateisystem gespeichert sind. Wenn eine Abfrage auf Daten zugreifen muss, prüft AlloyDB Omni zuerst den Zwischenspeicherpool. Wenn die Seiten mit den erforderlichen Daten nicht im Zwischenspeicherpool gefunden werden, liest AlloyDB Omni die erforderlichen Seiten aus dem Dateisystem.
Der Zugriff auf Daten aus dem Zwischenspeicherpool ist deutlich schneller als das Lesen aus dem Dateisystem. Die Maximierung der Größe des Zwischenspeicherpools für die Daten, auf die eine Anwendung zugreift, ist ein wichtiger Faktor. Optional können Sie eine ultraschnelle Cache-Ebene hinzufügen, um die Abfrageleistung weiter zu verbessern.
Ressourcenverwaltung
AlloyDB Omni verwendet die automatische dynamische Speicherverwaltung, damit der Zwischenspeicherpool je nach Speicherbedarf des Systems innerhalb der konfigurierten Grenzen dynamisch wachsen und schrumpfen kann. Daher ist keine Optimierung der Größe des Zwischenspeicherpools erforderlich. Wenn Sie Leistungsprobleme diagnostizieren, sollten Sie zuerst Messwerte wie die Trefferrate des Zwischenspeicherpools und die Leserate berücksichtigen, um festzustellen, ob Ihre Anwendung vom Zwischenspeicherpool profitiert. Wenn nicht, bedeutet das, dass das Dataset der Anwendung nicht in den Zwischenspeicherpool passt. Sie sollten dann in Erwägung ziehen, die Größe auf eine größere Maschine mit mehr Speicher zu ändern.
Für das Abrufen, Filtern, Aggregieren, Sortieren und Projizieren von Daten sind CPU-Ressourcen auf dem Datenbankserver erforderlich. Um die für diesen Vorgang erforderliche Menge an CPU-Ressourcen zu reduzieren, minimieren Sie die Menge der zu bearbeitenden Daten. Beobachten Sie die CPU-Auslastung auf dem Datenbankserver, um sicherzustellen, dass die Auslastung im Normalzustand bei etwa 70 % liegt. Dieser Wert lässt ausreichend Spielraum auf dem Server für Spitzen bei der Auslastung oder Änderungen bei den Zugriffsmustern im Laufe der Zeit. Eine Auslastung von fast 100% führt zu Mehraufwand aufgrund der Prozessplanung und des Kontextwechsels und kann zu Engpässen in anderen Teilen des Systems führen. Eine hohe CPU-Auslastung ist ein weiterer wichtiger Messwert, der bei Entscheidungen zu den Maschinenspezifikationen berücksichtigt werden sollte.
Die Eingabe-/Ausgabevorgänge pro Sekunde (IOPS) sind ein wichtiger Faktor für die Leistung von Datenbankanwendungen. Sie messen, wie viele Eingabe- oder Ausgabevorgänge pro Sekunde das zugrunde liegende Speichergerät an die Datenbank liefern kann. Um die IOPS-Limits des Datenbankspeichers nicht zu überschreiten, minimieren Sie Lese- und Schreibvorgänge im Speicher. Maximieren Sie die Datenmenge, die in den Zwischenspeicherpool oder in die Cache-Ebene passt.
Spaltenbasierte Engine
Die integrierte spaltenbasierte Engine beschleunigt die Verarbeitung von Analyseabfragen, die in der Regel vollständige Tabellenscans, komplexe Joins und Aggregate umfassen.
Speicherinterner Spaltenspeicher: Enthält Tabellendaten und Daten in der materialisierten Ansicht für ausgewählte Spalten in einem spaltenorientierten Format. Standardmäßig belegt der Spaltenspeicher 30% des verfügbaren Arbeitsspeichers. Wenn Sie die Menge des vom Spaltenspeicher verwendbaren Arbeitsspeichers ändern möchten, legen Sie den Parameter
google_columnar_engine.memory_size_in_mbin derpostgresql.conffest, die von Ihrer AlloyDB Omni-Instanz verwendet wird.Spaltenbasierter Abfrageplaner und spaltenbasierte Ausführungs-Engine: Unterstützt die Verwendung des Spaltenspeichers in Abfragen.
Weitere Informationen finden Sie unter Spaltenbasierte Engine von AlloyDB for PostgreSQL.
Automatische Speicherverwaltung
Die automatische Speicherverwaltung überwacht und optimiert kontinuierlich den Speicherverbrauch in einer gesamten AlloyDB Omni-Instanz. Wenn Sie Ihre Arbeitslasten ausführen, passt dieses Modul die Größe des gemeinsamen Zwischenspeichers basierend auf dem Speicherbedarf an.
Standardmäßig legt die automatische Speicherverwaltung die Obergrenze auf 80 % des Systemspeichers fest und weist 10% des Systemspeichers für den gemeinsamen Zwischenspeicher zu.
Wenn Sie die Obergrenze für die Größe des gemeinsamen Zwischenspeichers ändern möchten, legen Sie den Parameter shared_buffers in der postgresql.conf fest, die von Ihrer AlloyDB Omni-Instanz verwendet wird.
Adaptives Autovacuum
Das adaptive Autovacuum analysiert Vorgänge basierend auf der Datenbankarbeitslast und passt die Häufigkeit der Bereinigung automatisch an. Diese automatische Anpassung trägt dazu bei, dass die Datenbank auch bei Änderungen der Arbeitslast eine optimale Leistung beibehält, ohne dass der Bereinigungsprozess stört.
Das adaptive Autovacuum verwendet die folgenden Faktoren, um die Häufigkeit und Intensität der Bereinigungsvorgänge zu bestimmen:
- Größe der Datenbank
- Anzahl der fehlerhaften Tupel in der Datenbank
- Alter der Daten in der Datenbank
- Anzahl der Transaktionen pro Sekunde im Vergleich zur geschätzten Bereinigungsgeschwindigkeit
- Ressourcennutzung
KI/ML-Worker
In AlloyDB Omni bietet der KI/ML-Hintergrundworker die Funktionen, die zum Aufrufen von Vertex AI-Modellen direkt aus der Datenbank erforderlich sind. Der KI/ML-Worker wird als Prozess mit dem Namen omni ml worker ausgeführt.
Orchestrator-Steuerungsebene
Die Bereitstellungsoption mit dem RPM-Orchestrator verwendet einen zentralen Cluster-Manager, um clusterweite Vorgänge zu automatisieren, einschließlich Bootstrapping und Failover.
Verwaltungsoberflächen
Die Bereitstellungsoption mit dem RPM-Orchestrator bietet sowohl ein Befehlszeilenprogramm (alloydbctl) als auch Ansible-Rollen für die Verwaltung eines oder mehrerer Cluster im großen Maßstab.
Leistungsoptimierung
Die Bereitstellungsoption mit dem RPM-Orchestrator bietet integrierte Unterstützung für PgBouncer für das Verbindungspooling und HAProxy für den Lastenausgleich zwischen Lese-/Schreib- und Nur-Lese-Endpunkten.
Nächste Schritte
Erste Schritte mit den folgenden Bereitstellungsoptionen für AlloyDB Omni: