
O AlloyDB Omni é um pacote de software de banco de dados para download que permite implantar uma versão simplificada do AlloyDB para PostgreSQL em ambientes de computação gerenciados por você. O AlloyDB Omni e o serviço totalmente gerenciado do AlloyDB no Google Cloud compartilham os mesmos componentes principais. O AlloyDB usa uma camada de armazenamento desagregada nativa da nuvem, enquanto o AlloyDB Omni é implantado no armazenamento de sua escolha.
A portabilidade do AlloyDB Omni permite que ele seja executado em vários ambientes, incluindo:
- Seus data centers particulares
- Qualquer nuvem pública
- Seu laptop
- Instâncias de VM baseadas na nuvem
O AlloyDB Omni oferece várias melhorias, além do PostgreSQL padrão, que oferecem suporte a escalonabilidade, disponibilidade, confiabilidade, desempenho, IA e linguagem natural. Para mais informações, consulte Adições do AlloyDB Omni para o PostgreSQL padrão.
Casos de uso do AlloyDB Omni
O AlloyDB Omni é adequado para os seguintes cenários:
- Você precisa de uma versão escalonável e de alto desempenho do PostgreSQL que precisa ser executada no local devido a requisitos regulatórios ou de soberania de dados.
- Você precisa de um banco de dados que continue funcionando mesmo quando estiver desconectado da Internet.
- Você quer migrar de um banco de dados legado sem se comprometer com um serviço de nuvem totalmente gerenciado, como o AlloyDB para PostgreSQL.
Principais recursos
- Um servidor de banco de dados 100% compatível com PostgreSQL.
- Suporte para a IA do AlloyDB, que ajuda você a criar aplicativos de IA generativa de nível empresarial usando seus dados operacionais.
- Integrações com o Google Cloud ecossistema de IA, incluindo o Vertex AI Model Garden e ferramentas de IA generativa de código aberto.
Suporte para recursos do Autopilot do AlloyDB para PostgreSQL em Google Cloud que permite que o AlloyDB Omni se autogerencie e se ajuste automaticamente.
Por exemplo, o AlloyDB Omni oferece suporte ao gerenciamento automático de memória e ao autovacuum adaptativo de dados desatualizados.
O mecanismo colunar do AlloyDB Omni, que mantém os dados relevantes em um formato colunar na memória para consultas analíticas, relatórios e cargas de trabalho de processamento analítico e transacional híbrido (HTAP) mais rápidos.
Em testes de desempenho, as cargas de trabalho transacionais no AlloyDB Omni são mais de duas vezes mais rápidas, e as consultas analíticas são até 100 vezes mais rápidas do que o PostgreSQL padrão.
Como o AlloyDB Omni funciona
É possível instalar o AlloyDB Omni de uma das seguintes maneiras:
AlloyDB Omni para contêineres: um contêiner de banco de dados independente. Execute o AlloyDB Omni em um sistema Linux com armazenamento SSD e pelo menos 8 GB de memória por CPU.
AlloyDB Omni para Kubernetes: parte de um contêiner em um ambiente do Kubernetes. O operador do AlloyDB Omni no Kubernetes é uma extensão da API Kubernetes que permite executar o AlloyDB Omni na maioria dos ambientes do Kubernetes em compliance com a CNCF.
O operador do AlloyDB Omni simplifica as operações básicas de banco de dados, permitindo automatizar implantações únicas ou de alta disponibilidade (HA) e operações do segundo dia, como backup, restauração, failover e configuração de recuperação de desastres (DR) entre regiões.
AlloyDB Omni para Linux (prévia): um Red Hat Package Manager (RPM) que é executado diretamente em uma VM ou bare metal. O AlloyDB Omni para Linux é executado como um conjunto de componentes de software integrados diretamente no sistema operacional host. Ele usa o sistema de arquivos padrão do Linux para armazenamento, permitindo que você use sua infraestrutura e práticas de gerenciamento de armazenamento atuais.
Seus aplicativos se conectam e se comunicam com o banco de dados do AlloyDB Omni da mesma forma que se conectam e se comunicam com um servidor de banco de dados PostgreSQL padrão. O controle de acesso do usuário também depende dos padrões do PostgreSQL.
Do registro em registros à limpeza e ao mecanismo colunar, é possível configurar o comportamento do banco de dados do AlloyDB Omni usando flags de banco de dados.
Vantagens de executar o AlloyDB Omni como um contêiner
O Google distribui o AlloyDB Omni como um contêiner que pode ser executado com ambientes de execução de contêineres como Docker e Podman. Também é possível implantar contêineres do AlloyDB Omni em um ambiente do Kubernetes com muitas operações básicas automatizadas.
Operacionalmente, os contêineres oferecem as seguintes vantagens:
- Gerenciamento transparente de dependências: todas as dependências necessárias são agrupadas no contêiner e testadas pelo Google para garantir a compatibilidade total com o AlloyDB Omni.
- Portabilidade: o AlloyDB Omni opera de forma consistente em todos os ambientes.
- Isolamento de segurança: você escolhe a que o contêiner do AlloyDB Omni tem acesso na máquina host.
- Gerenciamento de recursos: é possível definir a quantidade de recursos de computação que você quer que o contêiner do AlloyDB Omni use.
- Correções e upgrades sem problemas: para corrigir um contêiner, substitua a imagem atual por uma nova.
Vantagens de executar o AlloyDB Omni em um ambiente RHEL
O AlloyDB Omni para Linux (pré-lançamento) foi projetado para ambientes em que uma implantação de banco de dados não conteinerizada é preferível. Esse modelo de implantação é compatível com servidores bare metal e máquinas virtuais.
É possível instalar o AlloyDB Omni para Linux diretamente em um ambiente Red Hat Enterprise Linux (RHEL) ou compatível com Red Hat usando gerenciadores de pacotes padrão do sistema operacional.
O AlloyDB Omni para Linux é compatível com o RHEL 9 e o Rocky Linux 9.
Backup de dados e recuperação de desastres
O AlloyDB Omni tem um sistema de backup e recuperação contínuos que permite criar um novo cluster de banco de dados com base em qualquer momento dentro de um período de armazenamento ajustável. Isso permite que você se recupere de acidentes de perda de dados.
Além disso, o AlloyDB Omni pode criar e armazenar backups completos dos dados do cluster de banco de dados, sob demanda ou em uma programação regular. A qualquer momento, é possível restaurar um backup para um cluster de banco de dados do AlloyDB Omni que contenha todos os dados do cluster de banco de dados original no momento em que o backup foi criado.
Como outro método de recuperação de desastres, é possível fazer a replicação entre data centers criando clusters de banco de dados secundários em data centers separados. O AlloyDB Omni transmite dados de forma assíncrona de um cluster de banco de dados primário designado para cada um dos clusters secundários. Sempre que necessário, é possível promover um cluster de banco de dados secundário para um cluster de banco de dados primário do AlloyDB Omni.
Componentes do AlloyDB Omni
O AlloyDB Omni consiste em dois conjuntos de componentes de arquitetura: componentes do PostgreSQL com melhorias do AlloyDB e componentes específicos do AlloyDB.
O diagrama a seguir mostra os dois conjuntos de componentes, incluindo a camada de infraestrutura em que eles residem e os recursos de cada um.
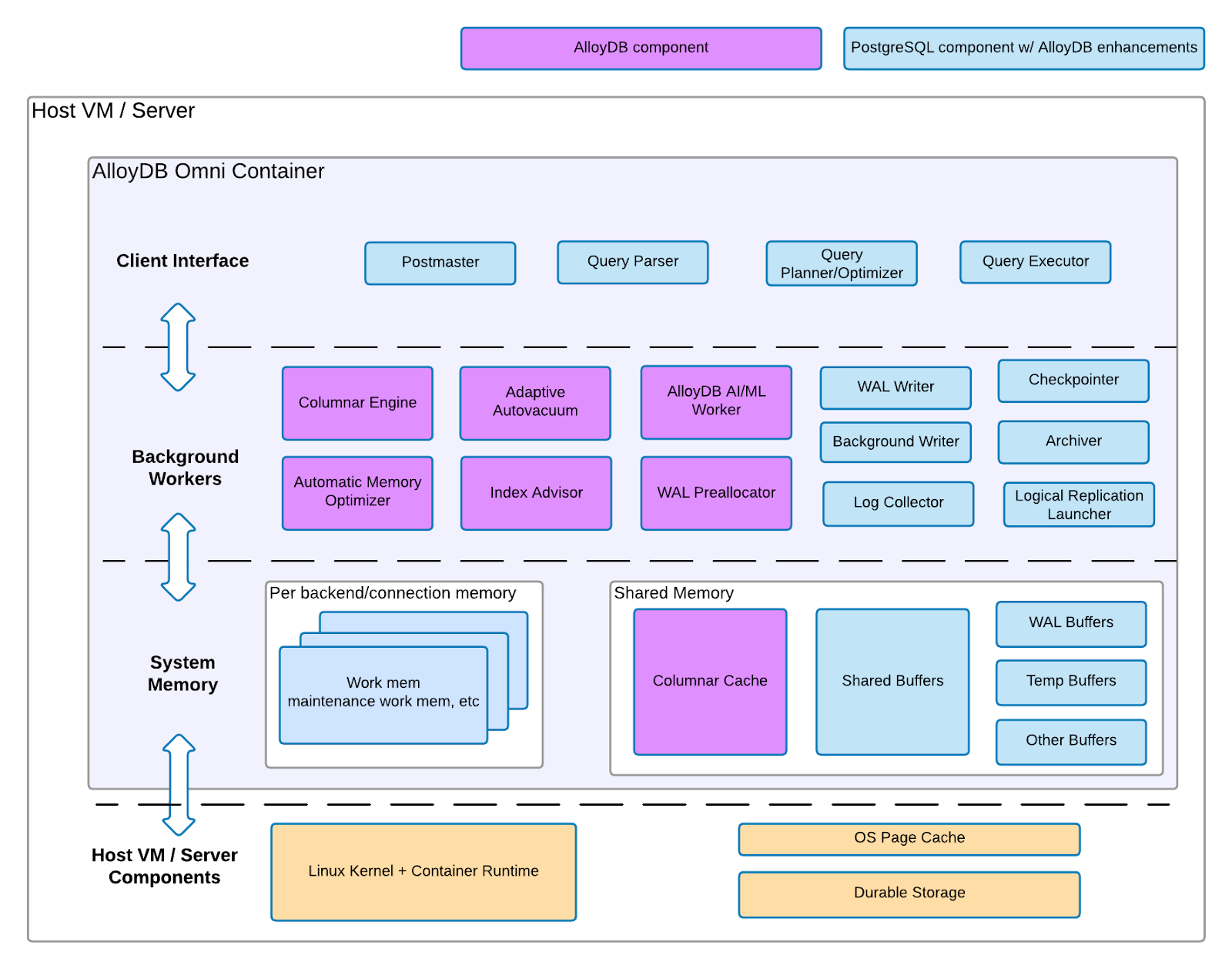
Figura 1. Arquitetura do AlloyDB Omni
Armazenamento de dados
O AlloyDB Omni armazena dados em páginas de tamanho fixo que são armazenadas no sistema de arquivos subjacente. Quando uma consulta precisa acessar dados, o AlloyDB Omni primeiro verifica o pool de buffers. Se as páginas que contêm os dados necessários não forem encontradas no pool de buffers, o AlloyDB Omni vai ler as páginas necessárias do sistema de arquivos.
Acessar dados do pool de buffers é muito mais rápido do que ler do sistema de arquivos. Maximizar o tamanho do pool de buffers para os dados acessados por um aplicativo é um fator importante. Você também pode adicionar uma camada de cache ultrarrápida para melhorar ainda mais o desempenho das consultas.
Gerenciamento de recursos
O AlloyDB Omni usa o gerenciamento automático de memória dinâmica para permitir que o pool de buffer aumente e diminua dinamicamente dentro dos limites configurados, dependendo das demandas de memória do sistema. Portanto, não é necessário ajustar o tamanho do pool de buffers. Ao diagnosticar problemas de performance, considere primeiro métricas como a taxa de acertos do pool de buffer e a taxa de leitura para determinar se o aplicativo está se beneficiando do pool de buffer. Caso contrário, isso indica que o conjunto de dados do aplicativo não cabe no pool de buffers. Considere redimensionar para uma máquina maior com mais memória.
O processo de recuperação, filtragem, agregação, classificação e projeção de dados exige recursos de CPU no servidor de banco de dados. Para reduzir a quantidade de recursos de CPU necessários para esse processo, minimize a quantidade de dados a serem manipulados. Monitore a utilização da CPU no servidor de banco de dados para garantir que a utilização em estado estável seja de cerca de 70%. Esse valor deixa espaço suficiente no servidor para picos de utilização ou mudanças nos padrões de acesso ao longo do tempo. Executar com uma utilização mais próxima de 100% introduz sobrecarga devido ao agendamento de processos e à troca de contexto, além de criar gargalos em outras partes do sistema. A alta utilização da CPU é outra métrica importante a ser usada ao tomar decisões sobre especificações de máquinas.
As operações de entrada/saída por segundo (IOPS) são um fator importante no desempenho de aplicativos de banco de dados, medindo quantas operações de entrada ou saída por segundo o dispositivo de armazenamento subjacente pode fornecer ao banco de dados. Para evitar exceder os limites de IOPS do armazenamento de banco de dados, minimize as leituras e gravações no armazenamento maximizando a quantidade de dados que cabem no pool de buffers ou na camada de cache.
Mecanismo colunar
O mecanismo colunar integrado acelera o processamento de consultas analíticas que normalmente envolvem verificações completas de tabelas, mesclagens complexas e agregações.
Armazenamento de colunas na memória: contém dados de tabela e de visualização materializada para colunas selecionadas em um formato orientado a colunas. Por padrão, o armazenamento de colunas consome 30% da memória disponível. Para mudar a quantidade de memória utilizável pelo repositório de colunas, defina o parâmetro
google_columnar_engine.memory_size_in_mbnopostgresql.confusado pela sua instância do AlloyDB Omni.Planejador de consultas e mecanismo de execução em colunas: oferece suporte ao uso do repositório de colunas em consultas.
Gerenciamento automático de memória
O gerenciador automático de memória monitora e otimiza continuamente o consumo de memória em toda uma instância do AlloyDB Omni. Ao executar as cargas de trabalho, esse módulo ajusta o tamanho do cache de buffer compartilhado com base na pressão da memória.
Por padrão, o gerenciador automático de memória define o limite máximo como 80% da memória do sistema e aloca 10% da memória do sistema para o cache de buffer compartilhado.
Para mudar o limite superior do tamanho do cache de buffer compartilhado, defina o parâmetro shared_buffers no postgresql.conf usado pela sua instância do AlloyDB Omni.
Autovacuum adaptativo
O autovacuum adaptável analisa as operações com base na carga de trabalho do banco de dados e ajusta automaticamente a frequência da limpeza. Esse ajuste automático ajuda o banco de dados a manter o desempenho ideal, mesmo com a mudança da carga de trabalho, sem interferência do processo de limpeza.
O vácuo automático adaptável usa os seguintes fatores para determinar a frequência e a intensidade das operações de vácuo:
- Tamanho do banco de dados
- Número de tuplas inativas no banco de dados
- Idade dos dados no banco de dados
- Número de transações por segundo x velocidade de vácuo estimada
- Uso dos recursos
Profissional de IA/ML
No AlloyDB Omni, o worker em segundo plano de IA/ML oferece os recursos necessários para chamar modelos da Vertex AI diretamente do banco de dados. O worker de IA/ML é executado como um processo chamado omni ml worker.
A seguir
- Escolha um ambiente de implantação do AlloyDB Omni.
- Comece a usar o AlloyDB Omni para contêineres.
- Comece a usar o AlloyDB Omni para Kubernetes.
- Comece a usar o AlloyDB Omni para Linux.