
AlloyDB Omni è un pacchetto software di database scaricabile che ti consente di eseguire il deployment di una versione semplificata di AlloyDB per PostgreSQL in ambienti di computing gestiti da te. AlloyDB Omni e il servizio AlloyDB completamente gestito su Google Cloud condividono gli stessi componenti principali. AlloyDB utilizza un livello di archiviazione disaggregato nativo del cloud, mentre AlloyDB Omni viene eseguito sul sistema di archiviazione di tua scelta.
La portabilità di AlloyDB Omni ti consente di eseguirlo in molti ambienti, tra cui:
- I tuoi data center privati
- Qualsiasi cloud pubblico
- Il tuo laptop
- Istanze VM basate su cloud
Oltre a PostgreSQL standard, AlloyDB Omni offre diversi miglioramenti che supportano scalabilità, disponibilità, affidabilità, prestazioni, AI e linguaggio naturale. Per saperne di più, consulta la sezione Aggiunte di AlloyDB Omni a PostgreSQL standard.
Casi d'uso di AlloyDB Omni
AlloyDB Omni è adatto ai seguenti scenari:
- Hai bisogno di una versione scalabile e ad alte prestazioni di PostgreSQL che devi eseguire on-premise a causa di requisiti normativi o di sovranità dei dati.
- Hai bisogno di un database che continui a essere eseguito anche quando è disconnesso da internet.
- Vuoi eseguire la migrazione da un database legacy senza impegnarti a utilizzare un servizio cloud completamente gestito come AlloyDB per PostgreSQL.
Funzionalità principali
- Un server di database compatibile al 100% con PostgreSQL.
- Supporto per AlloyDB AI, che ti aiuta a creare applicazioni di AI generativa di livello aziendale utilizzando i tuoi dati operativi.
- Integrazioni con l' Google Cloud ecosistema AI, tra cui Vertex AI Model Garden e strumenti di AI generativa open source.
Supporto per le funzionalità Autopilot di AlloyDB per PostgreSQL in Google Cloud che consentono ad AlloyDB Omni di autogestirsi e autoottimizzarsi.
Ad esempio, AlloyDB Omni supporta la gestione automatica della memoria e l'autovacuum adattivo dei dati obsoleti.
Il motore colonnare AlloyDB Omni, che mantiene i dati pertinenti in un formato colonnare in memoria per query analitiche, report e workload di elaborazione transazionale ibrida e analitica (HTAP) più veloci.
Nei test delle prestazioni, i workload transazionali in AlloyDB Omni sono oltre 2 volte più veloci e le query analitiche sono fino a 100 volte più veloci rispetto a PostgreSQL standard.
Scelte di deployment di AlloyDB Omni
Puoi installare AlloyDB Omni utilizzando una delle seguenti opzioni di deployment:
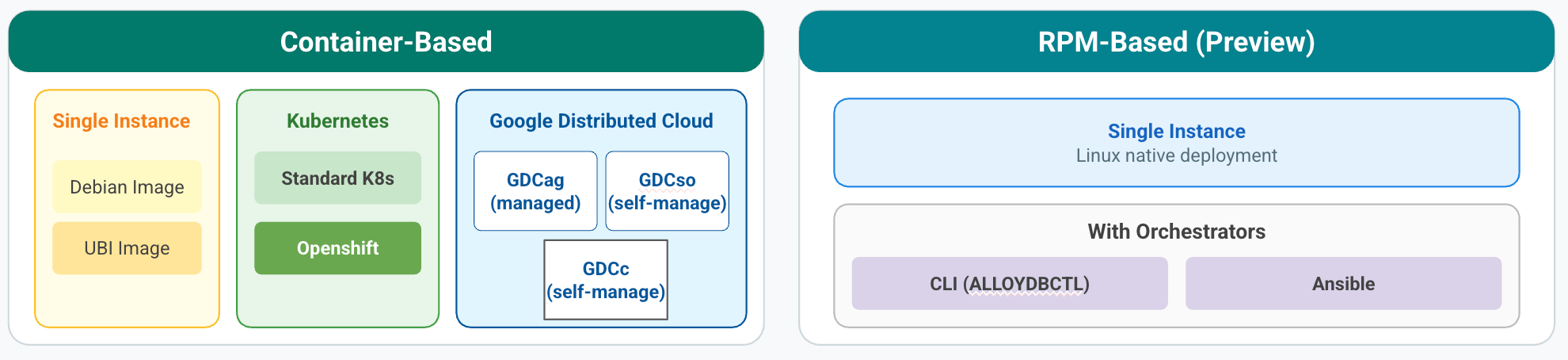
AlloyDB Omni utilizzando i container: un container di database autonomo. Esegui AlloyDB Omni su un sistema Linux con spazio di archiviazione SSD e almeno 8 GB di memoria per CPU.
AlloyDB Omni utilizzando l'orchestratore di container: parte di un container in un ambiente Kubernetes. L'operatore di AlloyDB Omni Kubernetes è un'estensione dell'API Kubernetes che ti consente di eseguire AlloyDB Omni nella maggior parte degli ambienti Kubernetes conformi a CNCF.
L'operatore di AlloyDB Omni semplifica le operazioni di base del database, consentendoti di automatizzare i deployment singoli o ad alta affidabilità (HA) e le operazioni del giorno 2, come backup, ripristino, failover e configurazione del ripristino di emergenza (RE) tra regioni.
AlloyDB Omni utilizzando RPM: un pacchetto autonomo che viene eseguito direttamente in una VM o in un server bare metal. AlloyDB Omni utilizzando RPM viene eseguito come un insieme di componenti software integrati direttamente sul sistema operativo host. Utilizza il file system Linux standard per l'archiviazione, consentendoti di utilizzare l'infrastruttura di archiviazione e le pratiche di gestione esistenti.
AlloyDB Omni utilizzando l'orchestratore RPM (anteprima): un deployment di Red Hat Package Manager (RPM) per VM o server bare metal. Questa opzione include una piattaforma di orchestrazione che automatizza il deployment e la gestione in ambienti non Kubernetes. Estende la flessibilità simile al cloud all'infrastruttura di tua scelta, senza richiedere livelli di containerizzazione come Docker.
Le tue applicazioni si connettono e comunicano con il database AlloyDB Omni, proprio come le applicazioni si connettono e comunicano con un server di database PostgreSQL standard. Anche il controllo dell'accesso degli utenti si basa sugli standard PostgreSQL.
Puoi configurare il comportamento del database AlloyDB Omni utilizzando i flag del database, inclusi logging, vacuum e motore colonnare. Per saperne di più, consulta la sezione Opzioni di download e installazione di AlloyDB Omni disponibili.
AlloyDB Omni come container
Google distribuisce AlloyDB Omni come container che puoi eseguire con runtime di container come Docker e Podman. Puoi anche eseguire il deployment dei container AlloyDB Omni in un ambiente Kubernetes con molte operazioni di base automatizzate.
A livello operativo, i container offrono i seguenti vantaggi:
- Gestione trasparente delle dipendenze: tutte le dipendenze necessarie sono raggruppate nel container e testate da Google per garantire la piena compatibilità con AlloyDB Omni.
- Portabilità: puoi aspettarti che AlloyDB Omni funzioni in modo coerente in tutti gli ambienti.
- Isolamento della sicurezza: scegli a cosa può accedere il container AlloyDB Omni sulla macchina host.
- Gestione delle risorse: puoi definire la quantità di risorse di calcolo che vuoi che il container AlloyDB Omni utilizzi.
- Applicazione di patch e upgrade senza interruzioni: per applicare una patch a un container, sostituisci l'immagine esistente con una nuova.
AlloyDB Omni in un ambiente RHEL
AlloyDB Omni offre due opzioni di deployment per un ambiente RHEL, che dipendono dai requisiti di automazione e scalabilità.
AlloyDB Omni utilizzando RPM
L'opzione di deployment RPM è un'installazione autonoma di Red Hat Package Manager (RPM) progettata per gli ambienti in cui vuoi un database AlloyDB Omni non containerizzato. Questa opzione supporta RHEL 9 e Rocky Linux 9.
- Integrazione diretta del sistema operativo: viene eseguito come un insieme di componenti software integrati direttamente sul sistema operativo host.
- Spazio di archiviazione esistente: utilizza il file system Linux standard (ext4 e xfs), che supporta l'infrastruttura di archiviazione e le pratiche di gestione esistenti.
- Semplicità: è adatto per configurazioni a istanza singola in cui è richiesta un'integrazione approfondita con il sistema operativo host, senza livelli di orchestrazione aggiuntivi.
L'orchestratore RPM
L'opzione di deployment dell'orchestratore RPM (anteprima) utilizza gli stessi pacchetti RPM di AlloyDB Omni utilizzando RPM, ma aggiunge una piattaforma di orchestrazione per automatizzare la gestione in ambienti non Kubernetes
- Flessibilità simile al cloud: estende l'automazione all'infrastruttura on-premise, gestendo il bootstrapping, il failover e la gestione del ciclo di vita.
- Framework di Automation: si integra con strumenti comuni come Ansible, consentendo ai team di utilizzare le competenze esistenti. Puoi anche utilizzare strumenti della riga di comando appositamente creati.
- Funzionalità Enterprise: progettate specificamente per supportare l'alta affidabilità (HA) e il ripristino di emergenza (RE) tramite un gestore di cluster centralizzato.
Backup dati e ripristino di emergenza
AlloyDB Omni include un sistema di backup e ripristino continui che ti consente di creare un nuovo cluster di database basato su qualsiasi momento all'interno di un periodo di conservazione regolabile. In questo modo puoi recuperare i dati in caso di incidenti di perdita di dati.
Inoltre, AlloyDB Omni può creare e archiviare backup completi dei dati del cluster di database, on demand o in base a una pianificazione regolare. In qualsiasi momento, puoi eseguire il ripristino da un backup a un cluster di database AlloyDB Omni che contiene tutti i dati del cluster di database originale al momento della creazione del backup.
Come ulteriore metodo di ripristino di emergenza, puoi ottenere la replica tra data center creando cluster di database secondari in data center separati. AlloyDB Omni esegue lo streaming asincrono dei dati da un cluster di database primario designato a ciascuno dei suoi cluster secondari. Se necessario, puoi promuovere un cluster di database secondario a cluster di database AlloyDB Omni primario.
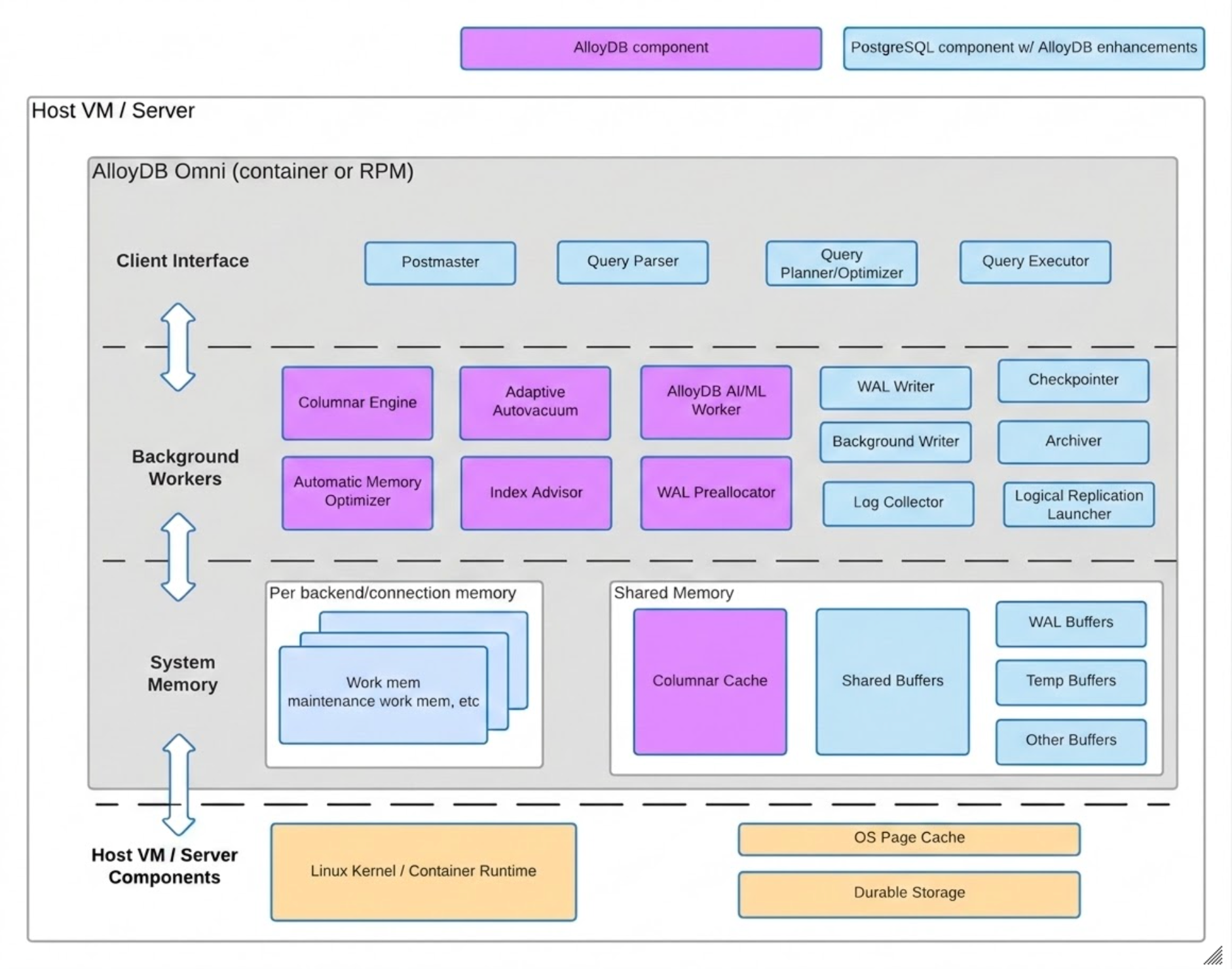
Componenti di AlloyDB Omni
AlloyDB Omni è costituito da due insiemi di componenti dell'architettura: componenti PostgreSQL con miglioramenti di AlloyDB Omni e componenti specifici di AlloyDB Omni.
Il seguente diagramma mostra entrambi gli insiemi di componenti, incluso il livello di infrastruttura in cui risiedono i componenti e le funzionalità di ogni componente.
Archiviazione dei dati
AlloyDB Omni archivia i dati in pagine di dimensioni fisse che vengono archiviate nel file system sottostante. Quando una query deve accedere ai dati, AlloyDB Omni controlla prima il pool di buffer. Se le pagine che contengono i dati richiesti non vengono trovate nel pool di buffer, AlloyDB Omni legge le pagine richieste dal file system.
L'accesso ai dati dal pool di buffer è notevolmente più veloce rispetto alla lettura dal file system. Massimizzare le dimensioni del pool di buffer per i dati a cui accede un'applicazione è un fattore importante. Facoltativamente, puoi aggiungere un livello di cache ultraveloce per migliorare ulteriormente le prestazioni delle query.
Gestione delle risorse
AlloyDB Omni utilizza la gestione automatica della memoria dinamica per consentire al pool di buffer di aumentare e diminuire dinamicamente entro i limiti configurati, a seconda delle esigenze di memoria del sistema. Pertanto, non è necessario ottimizzare le dimensioni del pool di buffer. Quando diagnostichi problemi di prestazioni, considera innanzitutto metriche come la frequenza di riscontri del pool di buffer e la frequenza di lettura per determinare se la tua applicazione sta sfruttando il pool di buffer. In caso contrario, significa che il set di dati dell'applicazione non rientra nel pool di buffer e potresti prendere in considerazione la possibilità di ridimensionare a una macchina più grande con più memoria.
Il processo di recupero, filtro, aggregazione, ordinamento e proiezione dei dati richiede risorse della CPU sul server del database. Per ridurre la quantità di risorse della CPU richieste per questo processo, riduci al minimo la quantità di dati da manipolare. Monitora l'utilizzo della CPU sul server del database per assicurarti che l'utilizzo in stato stazionario sia intorno al 70%. Questa quantità lascia spazio sufficiente sul server per picchi di utilizzo o modifiche ai pattern di accesso nel tempo. L'esecuzione con un utilizzo più vicino al 100% introduce un overhead dovuto alla pianificazione dei processi e al cambio di contesto e potrebbe creare colli di bottiglia in altre parti del sistema. L'utilizzo elevato della CPU è un'altra metrica chiave da utilizzare quando prendi decisioni sulle specifiche della macchina.
Le operazioni di input/output al secondo (IOPS) sono un fattore importante per le prestazioni delle applicazioni di database, in quanto misurano il numero di operazioni di input o output al secondo che il dispositivo di archiviazione sottostante può fornire al database. Per evitare di superare i limiti IOPS dello spazio di archiviazione del database, riduci al minimo le operazioni di lettura e scrittura nello spazio di archiviazione. Massimizza la quantità di dati che rientrano nel pool di buffer o nel livello di cache.
Motore colonnare
Il motore colonnare integrato accelera l'elaborazione delle query analitiche che in genere comportano scansioni complete delle tabelle, join complesse e aggregazioni.
Spazio di archiviazione a colonne in memoria: contiene i dati di tabelle e viste materializzate per le colonne selezionate in un formato orientato alle colonne. Per impostazione predefinita, lo spazio di archiviazione a colonne utilizza il 30% della memoria disponibile. Per modificare la quantità di memoria utilizzabile dallo spazio di archiviazione a colonne, imposta il parametro
google_columnar_engine.memory_size_in_mbnel filepostgresql.confutilizzato dall'istanza AlloyDB Omni.Pianificatore di query colonnari e motore di esecuzione: supporta l'utilizzo dello spazio di archiviazione a colonne nelle query.
Per saperne di più, consulta la sezione Informazioni sul motore colonnare di AlloyDB per PostgreSQL.
Gestione automatica della memoria
Il gestore automatico della memoria monitora e ottimizza continuamente il consumo di memoria in un'intera istanza AlloyDB Omni. Quando esegui i workload, questo modulo regola le dimensioni della cache del buffer condiviso in base alla pressione della memoria.
Per impostazione predefinita, il gestore automatico della memoria imposta il limite massimo all'80% della memoria di sistema e alloca il 10% della memoria di sistema per la cache del buffer condiviso.
Per modificare il limite massimo per le dimensioni della cache del buffer condiviso, imposta il parametro shared_buffers nel file postgresql.conf utilizzato dall'istanza AlloyDB Omni.
Autovacuum adattivo
L'autovacuum adattivo analizza le operazioni in base al workload del database e regola automaticamente la frequenza di vacuum. Questa regolazione automatica aiuta il database a mantenere prestazioni ottimali, anche quando il workload cambia, senza interferenze con il processo di vacuum.
L'autovacuum adattivo utilizza i seguenti fattori per determinare la frequenza e l'intensità delle operazioni di vacuum:
- Dimensioni del database
- Numero di tuple non attive nel database
- Età dei dati nel database
- Numero di transazioni al secondo rispetto alla velocità di vacuum stimata
- Utilizzo delle risorse
Worker AI/ML
In AlloyDB Omni, il worker in background AI/ML fornisce le funzionalità necessarie per chiamare i modelli Vertex AI direttamente dal database. Il worker AI/ML viene eseguito come un processo denominato omni ml worker.
Piano di controllo dell'orchestratore
L'opzione di deployment dell'orchestratore RPM utilizza un gestore di cluster centralizzato per automatizzare le operazioni a livello di cluster, inclusi bootstrapping e failover.
Interfacce di gestione
L'opzione di deployment dell'orchestratore RPM fornisce sia un'utilità della riga di comando (alloydbctl) sia i ruoli Ansible per la gestione di uno o più cluster su larga scala.
Ottimizzazione delle prestazioni
L'opzione di deployment dell'orchestratore RPM include il supporto integrato per PgBouncer per il pool di connessioni e HAProxy per il bilanciamento del carico tra gli endpoint di lettura/scrittura e di sola lettura.
Passaggi successivi
Inizia a utilizzare le seguenti opzioni di deployment di AlloyDB Omni: