
AlloyDB Omni es un paquete de software de base de datos descargable que te permite implementar una versión optimizada de AlloyDB para PostgreSQL en entornos informáticos que gestionas. AlloyDB Omni y el servicio AlloyDB totalmente gestionado en Google Cloud comparten los mismos componentes principales. AlloyDB usa una capa de almacenamiento desagregada nativa de la nube, mientras que AlloyDB Omni se implementa en el almacenamiento que elijas.
La portabilidad de AlloyDB Omni te permite ejecutarlo en muchos entornos, incluidos los siguientes:
- Tus centros de datos privados
- Cualquier nube pública
- Tu portátil
- Instancias de VM basadas en la nube
AlloyDB Omni ofrece varias mejoras, además de PostgreSQL estándar, que admiten la escalabilidad, la disponibilidad, la fiabilidad, el rendimiento, la IA y el lenguaje natural. Para obtener más información, consulta Adiciones de AlloyDB Omni a PostgreSQL estándar.
Casos prácticos de AlloyDB Omni
AlloyDB Omni es una solución adecuada para los siguientes casos:
- Necesitas una versión escalable y de alto rendimiento de PostgreSQL que debas ejecutar de forma local debido a requisitos normativos o de soberanía de datos.
- Necesitas una base de datos que siga funcionando aunque no tenga conexión a Internet.
- Quieres migrar de una base de datos antigua sin comprometerte con un servicio en la nube totalmente gestionado como AlloyDB para PostgreSQL.
Características principales
- Un servidor de base de datos 100% compatible con PostgreSQL.
- Compatibilidad con AlloyDB AI, que te ayuda a crear aplicaciones de IA generativa de nivel empresarial con tus datos operativos.
- Integraciones con el ecosistema de IA, incluido Vertex AI Model Garden y herramientas de IA generativa de software libre. Google Cloud
Compatibilidad con las funciones de piloto automático de AlloyDB para PostgreSQL, que permite que AlloyDB Omni se gestione y se ajuste automáticamente.Google Cloud
Por ejemplo, AlloyDB Omni admite la gestión automática de la memoria y el autovacuum adaptativo de los datos obsoletos.
El motor de columnas de AlloyDB Omni, que mantiene los datos relevantes en un formato de columna en memoria para agilizar las consultas analíticas, los informes y las cargas de trabajo de procesamiento analítico y transaccional híbrido (HTAP).
En las pruebas de rendimiento, las cargas de trabajo transaccionales de AlloyDB Omni son más del doble de rápidas y las consultas analíticas son hasta 100 veces más rápidas que las del estándar PostgreSQL.
Cómo funciona AlloyDB Omni
Puedes instalar AlloyDB Omni de una de las siguientes formas:
AlloyDB Omni para contenedores: un contenedor de base de datos independiente. Ejecuta AlloyDB Omni en un sistema Linux con almacenamiento SSD y al menos 8 GB de memoria por CPU.
AlloyDB Omni para Kubernetes: parte de un contenedor en un entorno de Kubernetes. El operador de AlloyDB Omni Kubernetes es una extensión de la API de Kubernetes que te permite ejecutar AlloyDB Omni en la mayoría de los entornos de Kubernetes que cumplen con la norma CNCF.
El operador de AlloyDB Omni simplifica las operaciones básicas de la base de datos, lo que te permite automatizar las implementaciones de alta disponibilidad (HA) o de una sola instancia y las operaciones del día 2, como la creación de copias de seguridad, la restauración, la conmutación por error y la configuración de la recuperación tras fallos multirregional.
AlloyDB Omni para Linux (vista previa): un gestor de paquetes Red Hat (RPM) que se ejecuta directamente en una VM o en hardware desnudo. AlloyDB Omni para Linux se ejecuta como un conjunto de componentes de software integrados directamente en el sistema operativo host. Utiliza el sistema de archivos estándar de Linux para el almacenamiento, lo que te permite usar tu infraestructura de almacenamiento y tus prácticas de gestión.
Tus aplicaciones se conectan a tu base de datos AlloyDB Omni y se comunican con ella de la misma forma que lo harían con un servidor de base de datos PostgreSQL estándar. El control de acceso de los usuarios también se basa en los estándares de PostgreSQL.
Desde el registro hasta el motor columnar, pasando por el proceso de limpieza, puedes configurar el comportamiento de la base de datos de AlloyDB Omni mediante marcas de base de datos.
Ventajas de ejecutar AlloyDB Omni como contenedor
Google distribuye AlloyDB Omni como un contenedor que puedes ejecutar con entornos de ejecución de contenedores como Docker y Podman. También puedes desplegar contenedores de AlloyDB Omni en un entorno de Kubernetes con muchas operaciones básicas automatizadas.
Desde el punto de vista operativo, los contenedores ofrecen las siguientes ventajas:
- Gestión de dependencias transparente: todas las dependencias necesarias se incluyen en el contenedor y Google las prueba para asegurarse de que sean totalmente compatibles con AlloyDB Omni.
- Portabilidad: AlloyDB Omni funciona de forma coherente en todos los entornos.
- Aislamiento de seguridad: tú eliges a qué puede acceder el contenedor de AlloyDB Omni en la máquina host.
- Gestión de recursos: puedes definir la cantidad de recursos de computación que quieres que use el contenedor de AlloyDB Omni.
- Actualizaciones y parches sin interrupciones: para aplicar un parche a un contenedor, sustituye la imagen actual por una nueva.
Ventajas de ejecutar AlloyDB Omni en un entorno RHEL
AlloyDB Omni para Linux (vista previa) se ha diseñado para entornos en los que se prefiere una implementación de base de datos no contenerizada. Este modelo de implementación admite servidores físicos y máquinas virtuales.
Puedes instalar AlloyDB Omni para Linux directamente en un entorno Red Hat Enterprise Linux (RHEL) o compatible con Red Hat mediante gestores de paquetes de sistemas operativos estándar.
AlloyDB Omni para Linux es compatible con RHEL 9 y Rocky Linux 9.
Copias de seguridad de datos y recuperación en caso de desastre.
AlloyDB Omni incluye un sistema de copia de seguridad y recuperación continuas que te permite crear un nuevo clúster de base de datos basado en cualquier momento dado dentro de un periodo de conservación ajustable. De esta forma, puedes recuperarte de accidentes que provoquen la pérdida de datos.
Además, AlloyDB Omni puede crear y almacenar copias de seguridad completas de los datos de tu clúster de base de datos, ya sea bajo demanda o de forma periódica. En cualquier momento, puedes restaurar una copia de seguridad en un clúster de base de datos de AlloyDB Omni que contenga todos los datos del clúster de base de datos original en el momento en que se creó la copia de seguridad.
Como método adicional de recuperación tras desastres, puedes conseguir la replicación entre centros de datos creando clústeres de bases de datos secundarios en centros de datos independientes. AlloyDB Omni transmite datos de forma asíncrona desde un clúster de base de datos principal designado a cada uno de sus clústeres secundarios. Cuando sea necesario, puedes convertir un clúster de base de datos secundario en un clúster de base de datos principal de AlloyDB Omni.
Componentes de AlloyDB Omni
AlloyDB Omni consta de dos conjuntos de componentes de arquitectura: componentes de PostgreSQL con mejoras de AlloyDB y componentes específicos de AlloyDB.
En el siguiente diagrama se muestran ambos conjuntos de componentes, incluida la capa de infraestructura en la que residen los componentes y las funciones de cada componente.
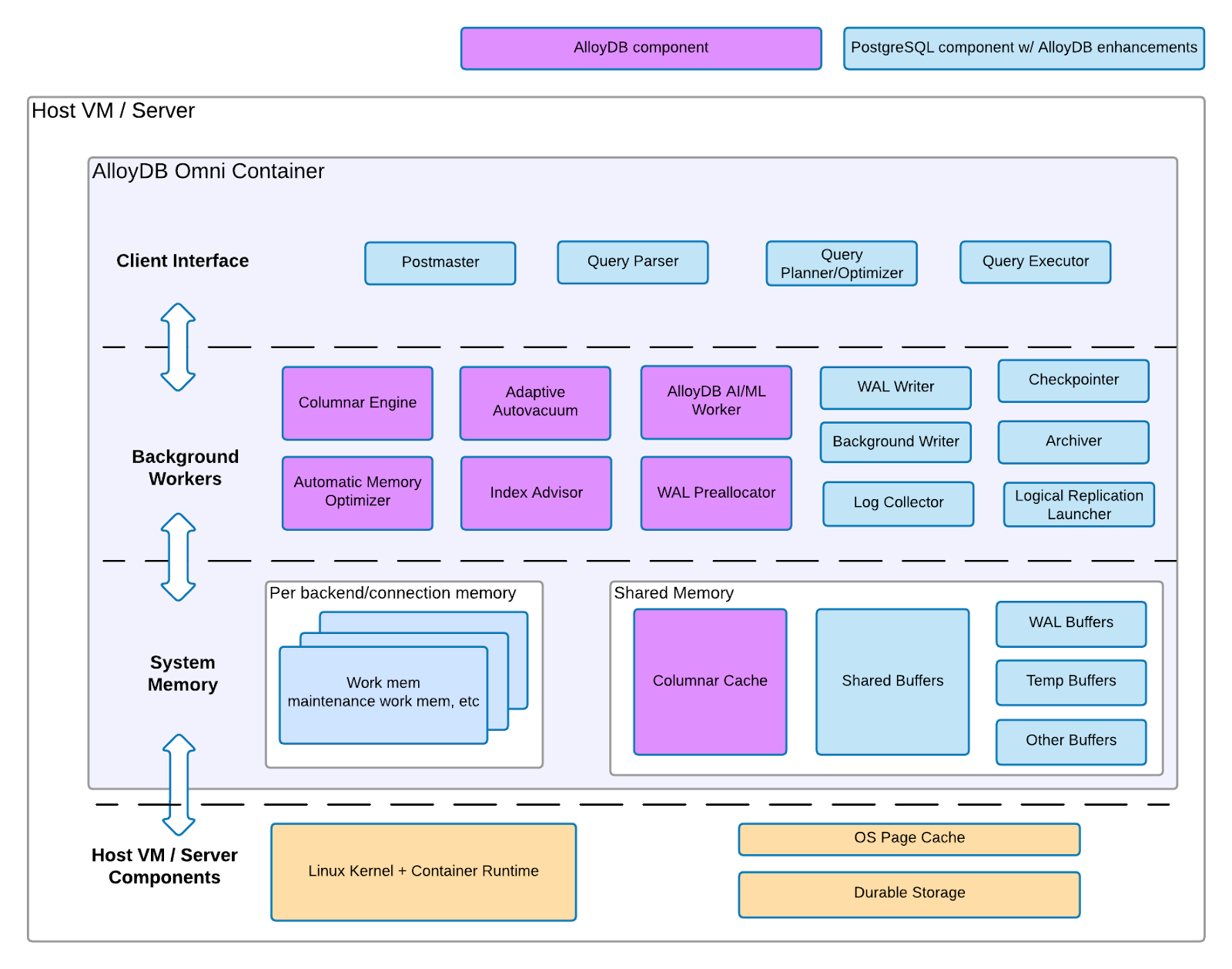
Imagen 1. Arquitectura de AlloyDB Omni
Almacenamiento de datos
AlloyDB Omni almacena los datos en páginas de tamaño fijo que se almacenan en el sistema de archivos subyacente. Cuando una consulta necesita acceder a los datos, AlloyDB Omni primero comprueba el grupo de búferes. Si las páginas que contienen los datos necesarios no se encuentran en el grupo de búferes, AlloyDB Omni las lee del sistema de archivos.
Acceder a los datos del grupo de búferes es mucho más rápido que leerlos del sistema de archivos. Maximizar el tamaño del grupo de búferes de los datos a los que accede una aplicación es un factor importante. También puedes añadir una capa de caché ultrarrápida para mejorar aún más el rendimiento de las consultas.
Gestión de recursos
AlloyDB Omni usa la gestión dinámica automática de la memoria para permitir que el grupo de búferes aumente y se reduzca dinámicamente dentro de los límites configurados en función de las demandas de memoria del sistema. Por lo tanto, no es necesario ajustar el tamaño del grupo de búferes. Cuando diagnostiques problemas de rendimiento, primero ten en cuenta métricas como la tasa de aciertos del grupo de búferes y la tasa de lectura para determinar si tu aplicación se beneficia del grupo de búferes. Si no es así, significa que el conjunto de datos de la aplicación no cabe en el grupo de búferes, por lo que deberías cambiar el tamaño a una máquina más grande con más memoria.
El proceso de recuperar, filtrar, agregar, ordenar y proyectar datos requiere recursos de CPU en el servidor de la base de datos. Para reducir la cantidad de recursos de CPU que requiere este proceso, minimiza la cantidad de datos que se van a manipular. Monitoriza el uso de la CPU en el servidor de la base de datos para asegurarte de que el uso en estado estable sea de aproximadamente el 70%. Esta cantidad deja suficiente margen en el servidor para picos de utilización o cambios en los patrones de acceso a lo largo del tiempo. Si se acerca al 100% de utilización, se introduce una sobrecarga debido a la programación de procesos y al cambio de contexto, lo que puede crear cuellos de botella en otras partes del sistema. El uso elevado de la CPU es otra métrica clave que debes tener en cuenta a la hora de tomar decisiones sobre las especificaciones de las máquinas.
Las operaciones de entrada/salida por segundo (IOPS) son un factor importante en el rendimiento de las aplicaciones de bases de datos, ya que miden cuántas operaciones de entrada o salida por segundo puede ofrecer el dispositivo de almacenamiento subyacente a la base de datos. Para evitar superar los límites de IOPS del almacenamiento de bases de datos, minimiza las lecturas y escrituras en el almacenamiento maximizando la cantidad de datos que caben en el grupo de búferes o en la capa de caché.
Motor en columnas
El motor de columnas integrado acelera el procesamiento de consultas analíticas que suelen implicar análisis de tablas completas, uniones complejas y agregaciones.
Almacén de columnas en memoria: contiene datos de tablas y vistas materializadas de columnas seleccionadas en un formato orientado a columnas. De forma predeterminada, el almacén de columnas consume el 30% de la memoria disponible. Para cambiar la cantidad de memoria que puede usar el almacén de columnas, define el parámetro
google_columnar_engine.memory_size_in_mben elpostgresql.confque usa tu instancia de AlloyDB Omni.Planificador de consultas y motor de ejecución en columnas: admite el uso del almacén de columnas en las consultas.
Gestión automática de la memoria
El gestor de memoria automático monitoriza y optimiza continuamente el consumo de memoria en toda una instancia de AlloyDB Omni. Cuando ejecutas tus cargas de trabajo, este módulo ajusta el tamaño de la caché de búfer compartida en función de la presión de la memoria.
De forma predeterminada, el gestor de memoria automático establece el límite superior en el 80 % de la memoria del sistema y asigna el 10% de la memoria del sistema a la caché de búfer compartida.
Para cambiar el límite superior del tamaño de la caché de búfer compartida, define el parámetro shared_buffers en el postgresql.conf que utilice tu instancia de AlloyDB Omni.
Autovacuum adaptativo
El vaciado automático adaptativo analiza las operaciones en función de la carga de trabajo de la base de datos y ajusta automáticamente la frecuencia del vaciado. Este ajuste automático ayuda a la base de datos a mantener un rendimiento óptimo, incluso cuando cambia la carga de trabajo, sin que el proceso de vacío interfiera.
La función de autovacuum adaptativo usa los siguientes factores para determinar la frecuencia y la intensidad de las operaciones de vacío:
- Tamaño de la base de datos
- Número de tuplas inactivas en la base de datos.
- Antigüedad de los datos de la base de datos
- Número de transacciones por segundo frente a la velocidad de vacío estimada
- Uso de recursos
Trabajador de IA y aprendizaje automático
En AlloyDB Omni, el trabajador en segundo plano de IA o aprendizaje automático proporciona las funciones necesarias para llamar a modelos de Vertex AI directamente desde la base de datos. El trabajador de IA/ML se ejecuta como un proceso llamado omni ml worker.
Siguientes pasos
- Elige un entorno de implementación de AlloyDB Omni.
- Empieza a usar AlloyDB Omni para contenedores.
- Empieza a usar AlloyDB Omni para Kubernetes.
- Empieza a usar AlloyDB Omni para Linux.