
借助优化的函数,您可以使用较小、较快的代理模型来处理大多数查询,然后在必要时回退到较大的 LLM。 这种方法可以降低运营费用并提高查询响应速度。 优化的函数可以最大限度地减少 LLM 在逐行分类或过滤任务中的使用,这些任务最好由代理模型处理。
由于对大语言模型 (LLM) 的远程调用,ai.if() 等 AlloyDB AI 函数可能会出现高延迟。优化的函数通过使用较小的本地训练代理模型来处理查询,从而解决了此延迟问题。这些模型使用 LLM 的输出作为真实来源,根据您的数据样本进行训练。
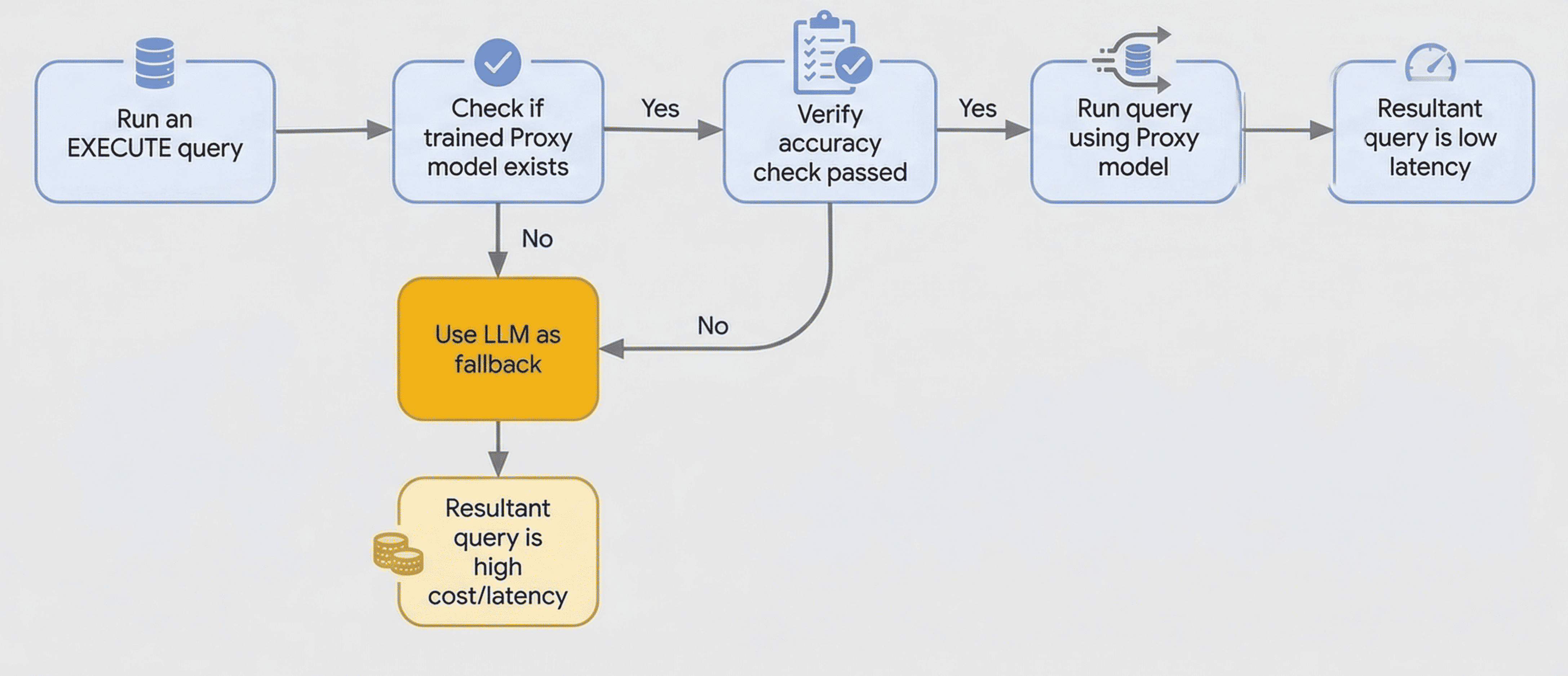
系统会在运行时使用 LLM 对行样本执行准确率检查。 如需执行此检查,AlloyDB 会使用 LLM 为样本行生成标签,并将其与代理模型的预测进行比较,以验证准确率。如果准确率检查失败,查询将回退到使用 LLM。
使用优化的函数时,AlloyDB 会执行以下操作:
- 训练代理模型:AlloyDB 会根据您的数据样本训练轻量级代理模型。当您将
PREPARE语句与ai.if()函数搭配使用,以训练模型来优化查询时,此操作会在后台进行。 - 执行查询:当您使用
EXECUTE语句时,AlloyDB 会使用训练有素的代理模型在本地处理查询。 - 回退到 LLM:如果模型的准确率较低,或者 AlloyDB 找不到模型,AlloyDB 会自动回退到使用 LLM。
准备工作
在使用优化的函数之前,请执行以下操作:
- 使用 psql 或
AlloyDB Studio,以
postgres用户身份或有权访问数据所在表的用户身份连接到数据库。 验证是否已安装
google_ml_integration扩展程序,并且该扩展程序在 1.5.8 或更高版本上可用。SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.8 (1 row)将 AlloyDB 配置为与 Gemini Enterprise Agent Platform 搭配使用。如需了解更多 信息,请参阅将数据库与 Agent Platform集成。
确保已启用以下数据库标志。如需了解详情,请参阅配置实例的数据库标志。
google_ml_integration.enable_model_supportgoogle_ml_integration.enable_ai_query_enginegoogle_ml_integration.enable_cost_optimized_ai_functions
为您要查询的表生成嵌入。如需了解详情, 请参阅为表生成和管理自动嵌入。
请考虑以下事项:
- 源数据列的类型必须为
TEXT或VARCHAR。 - 为优化的 AI 函数提供输入的嵌入列的类型必须为
REAL[]或VECTOR。 - 优化的函数仅在提供 Agent Platform 生成式模型的区域提供。如需查看可用 区域的列表,请参阅部署和端点。
- 源数据列的类型必须为
使用优化的函数
如需使用优化的函数,请将 PREPARE 和 EXECUTE 语句与 ai.if() 函数搭配使用。以下是如何使用优化的函数的示例:
创建
restaurant_reviews表。包含review源数据的 列的类型为TEXT,而用于 查询的review_embedding列的类型为VECTOR(768)。CREATE TABLE restaurant_reviews ( id SERIAL, name VARCHAR(64), city VARCHAR(64), review TEXT, review_embedding VECTOR(768) );将
PREPARE语句与ai.if()函数搭配使用,以表明查询必须使用优化的函数。此语句会在后台触发模型的异步训练。仅在满足以下条件时,才会训练模型:
- 查询中正好有一个
ai.if()函数。 ai.if()不在子查询中。
PREPARE positive_reviews_query AS SELECT r.name, r.city FROM restaurant_reviews r WHERE ai.if('Is the following a positive review? Review: ' || r.review, r.review_embedding) GROUP BY r.name, r.city HAVING COUNT(*) > 500;- 查询中正好有一个
使用
EXECUTE语句运行查询。由于PREPARE语句特定于当前会话,因此您必须在同一连接上运行EXECUTE语句:EXECUTE positive_reviews_query;conn2=> SELECT r.name, r.city FROM restaurant_reviews r WHERE ai.if('Is the following a positive review? Review: ' || r.review, r.review_embedding) GROUP BY r.name, r.city HAVING COUNT(*) > 500;如果满足以下任一条件,则不会使用训练有素的代理模型:
ai.if()中引用的内容或嵌入列发生更改。这两个列必须属于同一表。- 提供给内容列的提示发生更改。
- 查询的结构发生更改,导致
query_id不同。 - 查询在开始时未能达到准确率检查阈值。
在这些情况下,查询将回退到使用 LLM,并且 AlloyDB 会返回警告。
可选。如需为整个数据库环境停用准确率验证检查(这是必需的,因为模型训练期间也会执行准确率检查),请运行以下命令。
ALTER DATABASE DATABASE_NAME SET google_ml_integration.runtime_accuracy_check = off;将
DATABASE_NAME替换为您的数据库的名称。
重新训练代理模型
如果底层表数据发生显著变化,您可以再次运行 PREPARE 语句来重新训练代理模型。重新准备查询会通过发起新的训练请求来替换现有代理模型。
限制
如果您更改了源内容列、嵌入列或提供给 ai.if() 函数的提示,则必须发出新的 PREPARE 语句。
AlloyDB 会训练优化的函数,以近似于提示和输入数据的独特组合的行为。