
最適化された関数を使用すると、より小さく高速なプロキシモデルを使用してほとんどのクエリを処理し、必要に応じてより大きな LLM にフォールバックできます。このアプローチにより、運用コストが削減され、クエリの応答性が向上します。最適化された関数は、行ごとの分類タスクやフィルタリング タスクでの LLM の使用を最小限に抑えます。これらのタスクは、プロキシモデルでより適切に処理できます。
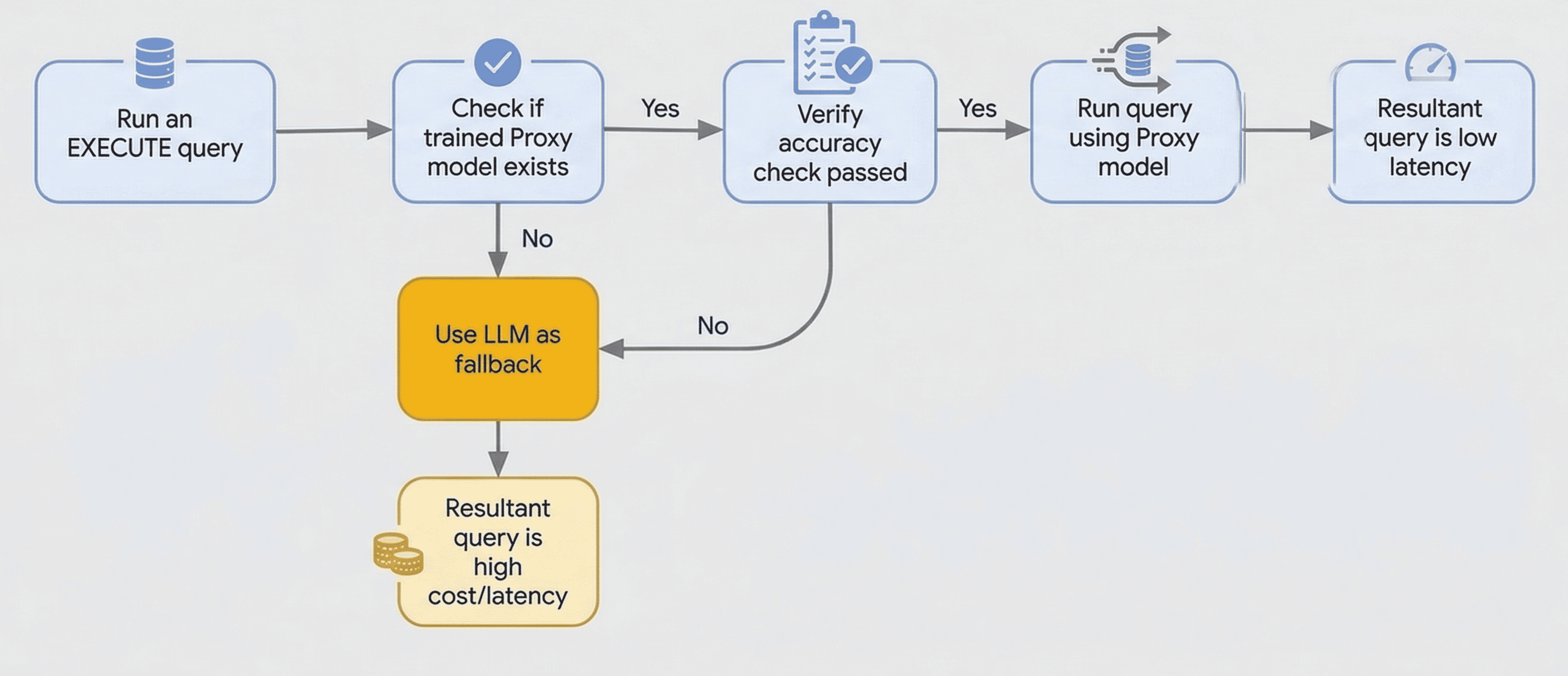
ai.if() などの AlloyDB AI 関数は、大規模言語モデル(LLM)へのリモート呼び出しにより、レイテンシが高くなることがあります。最適化された関数は、小規模でローカルにトレーニングされたプロキシ モデルを使用してクエリを処理することで、このレイテンシの問題に対処します。これらのモデルは、LLM の出力を信頼できる情報源として使用し、データのサンプルでトレーニングされます。
精度チェックは、LLM を使用して行のサンプルに対して実行時に行われます。このチェックを行うため、AlloyDB は LLM を使用してサンプル行のラベルを生成し、それらをプロキシモデルの予測と比較して精度を確認します。精度チェックに失敗すると、クエリは LLM を使用するようにフォールバックします。
最適化された関数を使用すると、AlloyDB は次の処理を行います。
- プロキシモデルをトレーニングする: AlloyDB は、データのサンプルで軽量なプロキシモデルをトレーニングします。これは、
PREPAREステートメントとai.if()関数を使用して、最適化されたクエリのモデルをトレーニングするときにバックグラウンドで発生します。 - クエリを実行する:
EXECUTEステートメントを使用すると、AlloyDB はトレーニング済みのプロキシモデルを使用してクエリをローカルで処理します。 - LLM にフォールバックする: モデルの精度が低い場合や、AlloyDB がモデルを見つけられない場合、AlloyDB は自動的に LLM の使用にフォールバックします。
始める前に
最適化された関数を使用する前に、次の操作を行います。
- psql を使用してデータベースに接続するか、AlloyDB Studio を使用して
postgresユーザーとして、またはデータが存在するテーブルにアクセスできるユーザーとして接続します。 google_ml_integration拡張機能がインストールされ、バージョン 1.5.8 以降で使用可能であることを確認します。SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.8 (1 row)Gemini Enterprise Agent Platform で動作するように AlloyDB を構成します。詳細については、データベースを Agent Platform と統合するをご覧ください。
次のデータベース フラグが有効になっていることを確認します。詳細については、インスタンスのデータベース フラグを構成するをご覧ください。
google_ml_integration.enable_model_supportgoogle_ml_integration.enable_ai_query_enginegoogle_ml_integration.enable_cost_optimized_ai_functions
クエリするテーブルのエンベディングを生成します。詳細については、テーブルの自動エンベディングを生成して管理するをご覧ください。
次の点を考慮してください。
- ソースデータ列の型は
TEXTまたはVARCHARである必要があります。 - 最適化された AI 関数に入力を提供するエンベディング列は、
REAL[]型またはVECTOR型である必要があります。 - 最適化された関数は、Agent Platform の生成モデルが利用可能なリージョンでのみ使用できます。使用可能なリージョンの一覧については、デプロイとエンドポイントをご覧ください。
- ソースデータ列の型は
最適化された関数を使用する
最適化された関数を使用するには、ai.if() 関数で PREPARE ステートメントと EXECUTE ステートメントを使用します。最適化された関数の使用方法の例を次に示します。
restaurant_reviewsテーブルを作成します。ソースデータを保持するreview列の型はTEXTで、クエリに使用されるreview_embedding列の型はVECTOR(768)です。CREATE TABLE restaurant_reviews ( id SERIAL, name VARCHAR(64), city VARCHAR(64), review TEXT, review_embedding VECTOR(768) );ai.if()関数を含むPREPAREステートメントを使用して、クエリで最適化された関数を使用する必要があることを示します。このステートメントは、バックグラウンドでモデルの非同期トレーニングをトリガーします。モデルは、次の条件でのみトレーニングされます。
- クエリに
ai.if()関数が 1 つだけ存在する。 ai.if()がサブクエリ内にない。
PREPARE positive_reviews_query AS SELECT r.name, r.city FROM restaurant_reviews r WHERE ai.if('Is the following a positive review? Review: ' || r.review, r.review_embedding) GROUP BY r.name, r.city HAVING COUNT(*) > 500;- クエリに
EXECUTEステートメントを使用してクエリを実行します。PREPAREステートメントは現在のセッションに固有であるため、同じ接続でEXECUTEステートメントを実行する必要があります。EXECUTE positive_reviews_query;conn2=> SELECT r.name, r.city FROM restaurant_reviews r WHERE ai.if('Is the following a positive review? Review: ' || r.review, r.review_embedding) GROUP BY r.name, r.city HAVING COUNT(*) > 500;次のいずれかの条件が満たされた場合、トレーニング済みのプロキシモデルは使用されません。
ai.if()で参照されているコンテンツ列またはエンベディング列が変更されます。両方の列は同じテーブルに属している必要があります。- コンテンツ列に提供されるプロンプトが変更されます。
- クエリの構造が変更され、異なる
query_idが生成されます。 - クエリの開始時に、クエリが精度チェックのしきい値を満たしていない。
このような場合、クエリは LLM の使用にフォールバックし、AlloyDB は警告を返します。
省略可。モデルのトレーニング中にも精度チェックが実行されるため、データベース環境全体の精度検証チェックを無効にするには、次のコマンドを実行します。
ALTER DATABASE DATABASE_NAME SET google_ml_integration.runtime_accuracy_check = off;DATABASE_NAMEは、データベースの名前に置き換えます。
プロキシモデルを再トレーニングする
基盤となるテーブルデータが大幅に変更された場合は、PREPARE ステートメントを再度実行して、プロキシモデルを再トレーニングできます。クエリを再準備すると、新しいトレーニング リクエストが開始され、既存のプロキシモデルが置き換えられます。
制限事項
ソース コンテンツ列、エンベディング列、または ai.if() 関数に指定されたプロンプトを変更する場合は、新しい PREPARE ステートメントを発行する必要があります。AlloyDB は、プロンプトと入力データの独自の組み合わせの動作を近似するように最適化された関数をトレーニングします。